はじめに
DCGAN-tensorflowを用いてLINEスタンプの自動生成を試みました。各パラメータについて、簡単に説明をまとめたうえ、実際にパラメータを変化させて学習を実行して得られた結果について紹介します。
最新作の紹介
現時点での最新の自動生成LINEスタンプはこちらになります。抽象画としてLINE STOREで公開すれば、高貴なる価値観を持った方たちが独自の解釈をして買ってくれそうな予感…!

目次
- はじめに
- 最新作の紹介
- DCGAN-tensorflowにて設定するパラメータ
- 学習処理のコンソールの見方について
- 学習の様子
- 所感
DCGAN-tensorflowにて設定するパラメータ
設定するパラメータについてそれぞれ簡単にまとめます。
epoch: 25
エポックは訓練データを使い切った回数に対応する。例えば、訓練データが10,000枚あり、バッチサイズが100のとき、1エポックでは100回の学習処理を繰り返す。エポックを重ねるごとに学習時間も増加する。
learning_rate: 0.0002
一回の訓練でどれだけ学習すべきか、勾配降下法においてどれだけパラメータを更新するかを決める学習率のこと。
beta1: 0.5
Adam法では、Momentum法とAdaGrad法を融合して効率的にパラメータ探索を行う。beta1は物理で言うところの運動量(Momentum)において、摩擦や空気抵抗として速度vにかかる定数のイメージ。
train_size: np.inf
訓練用のデータの数を決める、np.infで無限大を指定し、フォルダ内のすべての画像を入力とする。
batch_size: 64
データセットからランダムに選出するミニバッチの数を指定する。すべてのデータを対象に損失関数を計算するのは現実的ではないため、一部のデータを全体の近似として利用する。最終的に出力される画像はバッチサイズが64の場合、8枚×8枚を結合したものになる。
input_height: 224, input_width:259
訓練用の入力画像の横サイズのこと。
output_height: 64, output_width: 74
出力サイズを指定する。実験では64×74を指定したため、出力画像の合計サイズは592 x 512(8枚 x 8枚 = 64枚の合計)となる。出力サイズを大きくすると処理時間が急激に増加する。
data_dir: "./data", dataset: "AI-st"
data_dirではデータセット保存のルートディレクトリを指定し、datasetでは訓練用画像データを保存したフォルダの名前"AI-st"を指定する。
input_frame_pattern: "*.png"
入力データのglobの形式(ファイル名称のワイルドカードパターン)を指定する。
checkpoint_dir, sample_dir: "samples"
checkpoint_dirではチェックポイントを保存するディレクトリを指定し、sample_dirには、出力したイメージサンプルを保存するディレクトリを指定する。
train, crop
フラグを立てるとそれぞれ学習(train)、テスト(crop)を実行する。
visualization: option=1
optionを0〜4で指定することで、GIF生成など異なるテスト出力が得られる。
generate_test_images: 100
テストで生成する画像数を指定する。
学習処理のコンソールの見方について
$python main.py --dataset AI-st --input_height=224 --input_fname_pattern="*.png" --train --crop
: :
[*] Reading checkpoints...
[*] Success to read DCGAN.model-xxxxx
[*] Load SUCCESS
Epoch: [ 0/10] [ 0/ 404] time: 25.3513, d_loss: 2.45527697, g_loss: 0.13828892
Epoch: [ 0/10] [ 1/ 404] time: 45.9107, d_loss: 1.74161887, g_loss: 0.27818328
Epoch: [ 0/10] [ 2/ 404] time: 65.4222, d_loss: 1.32668591, g_loss: 0.71411240
Epoch: [ 0/10] [ 3/ 404] time: 86.1863, d_loss: 1.22418356, g_loss: 0.65934539
Epoch: [ 0/10] [ 4/ 404] time: 106.3118, d_loss: 1.29150105, g_loss: 0.43891436
: :
標準出力の画面では学習を実行中のエポック(上記例では10回中何回目)およびそのエポック内での反復回数を表示します。
データセットの数(25856) = バッチサイズ(64) × 反復回数(404)
学習の様子
画像数やエポックなど変化させていった際の学習の様子を掲載します。
(画像数を増やす際、学習のチェックポイントは継続して利用しています。)
画像数:500 エポック:25

画像数:1,000 エポック:25

画像数:1,500 エポック:25

まるで、胎児の成長をエコー写真で見ているようですね…。
パパはゆっくりと優しく見守っているからすくすく育っておくれ。
画像数:3,000 エポック:25

画像数:8,000 エポック:25

画像数:26,000 エポック:5

この辺りからLINEスタンプの雰囲気が出てきたような気がします!
キャラクター(?)が居てその周りにうじゃうじゃと文字らしきものが描かれています。
画像数:26,000 エポック:25
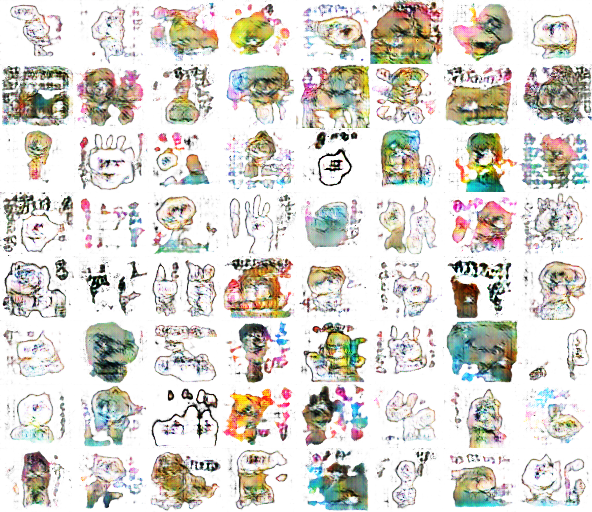
画像:26,000 エポック:35
現時点ではここまででになりますが、味のあるスタンプが生まれつつあります。
所感
なかなかおもしろい結果が得られつつあります。生成したスタンプの背景は透過されているので、LINEの背景に貼り付けると以下のように見えます。

今のところ、一枚の出力サイズを64×74に指定しているので画質の粗さが目立ちますね。
しかし、画像出力サイズを大きく(224×259)することを考えると、更に学習に膨大な時間がかかりそうです。流石に、私のマシン(MacbookAir)の限界を感じてきています。
今後は、Google ColaboratoryやAWSなどパブリッククラウドの利用、キャラクターを限定した学習等を試していきます。
…Part3はここまで。
Part4へ続きます。