初めに
Dify のワークフロー機能を使えば、PDF の各ページを画像にして、LLM に読み込ませ、自然言語で質問・回答する VQA(Visual Question Answering) をノーコードで実現できます。
今回は「PDF → 画像に変換 → LLM 解説 → 回答出力」までの最短構成をご紹介します。
✅ 完成イメージ

🛠 事前準備(Dify の外部公開ポート設定)
Docker Compose で Dify を起動している場合、PDF 内の画像を外部から取得するための URL が必要です。
docker-compose.override.yaml と .env を修正してポートを公開しておきましょう。
cd dify/docker
# .env
FILES_URL=http://xxx.xxx.xxx.xxx:5001
# docker-compose.override.yaml
services:
api:
ports:
- '${DIFY_PORT:-5001}:${DIFY_PORT:-5001}'
🧩 ステップ 1:開始ノードを作成
- 新規ワークフローを作成
- 開始ノードはデフォルトのまま
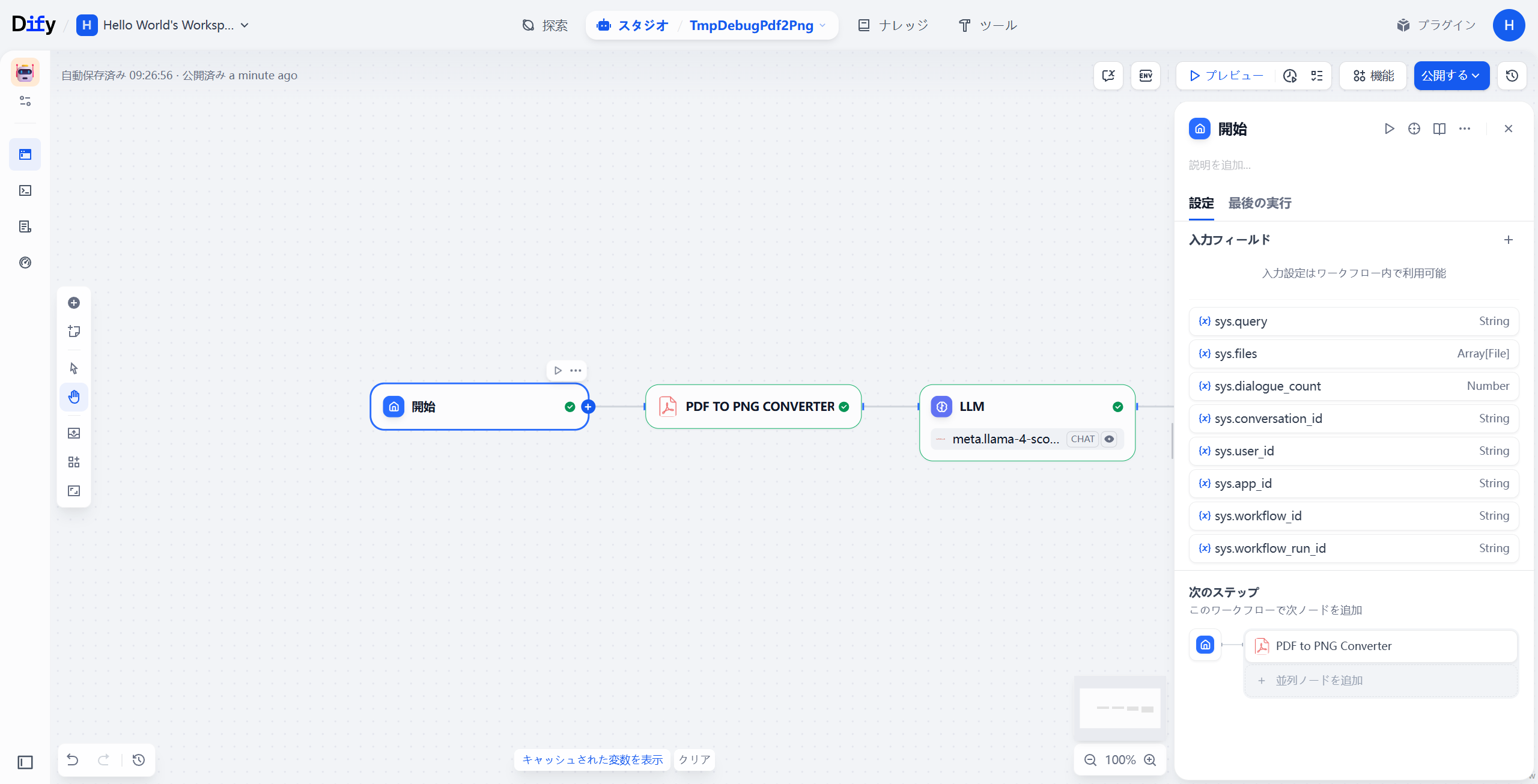
🧩 ステップ 2:PDF → PNG 変換ノード
- PDF to PNG Converter ノードを追加
- パラメータを以下のように設定
| パラメータ | 値 |
|---|---|
| PDF Content | 開始/sys.Files |
| Zoom Factor |
2(高解像度化) |

補足
このノードは PDF の 各ページを PNG に変換 し、画像ファイルとして後続ノードに渡します。
現状の制約として、最後の 1 枚だけが LLM に処理される 動作になっています。(別記事で複数画像を処理すること掲載する予定です)
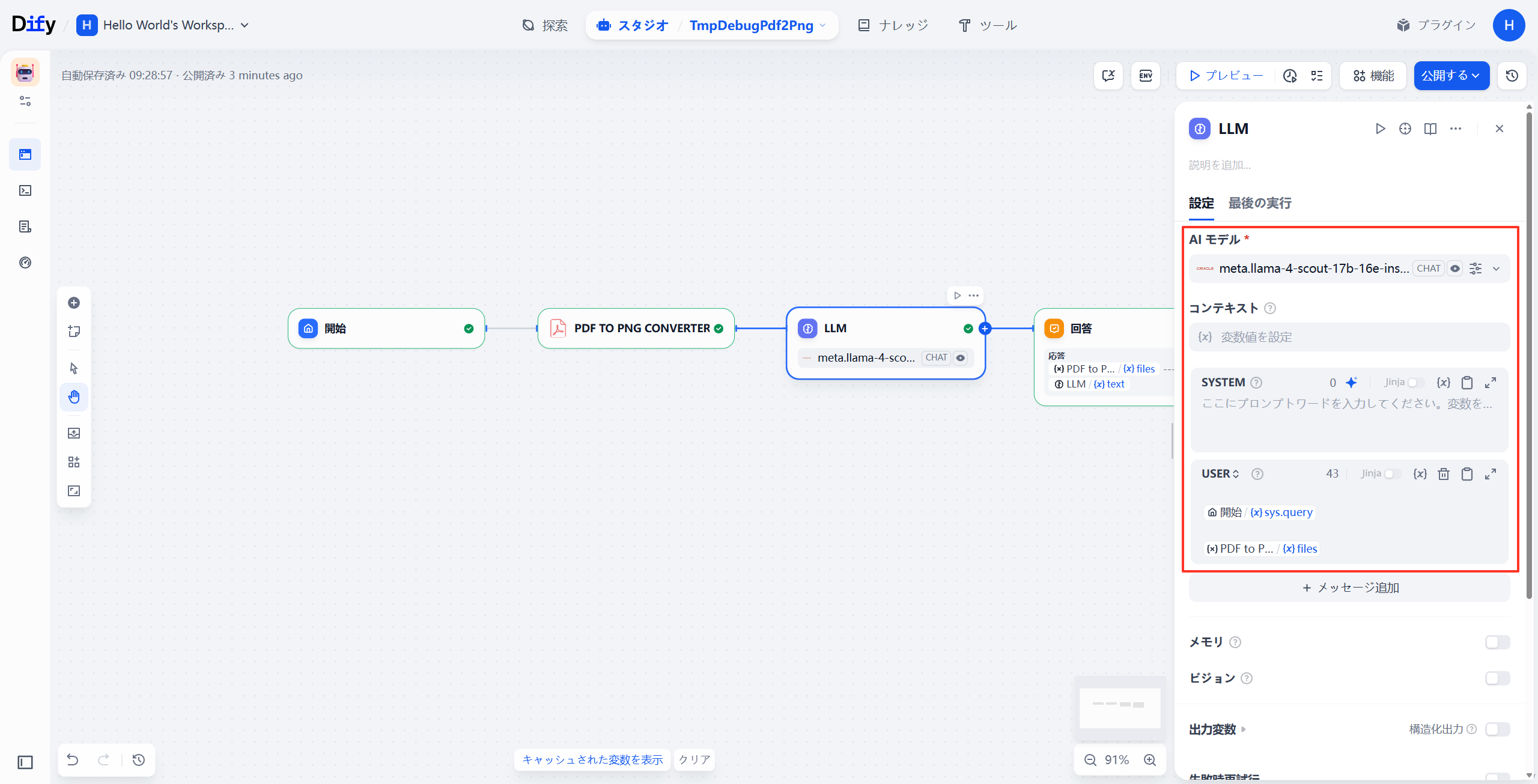
🧩 ステップ 3:LLM ノードで画像を読み込ませる
- LLM ノードを追加
- モデルは VQA に対応したもの(例:
llama-4-scout)を選択 - プロンプト例
画像の内容を日本語で説明してください
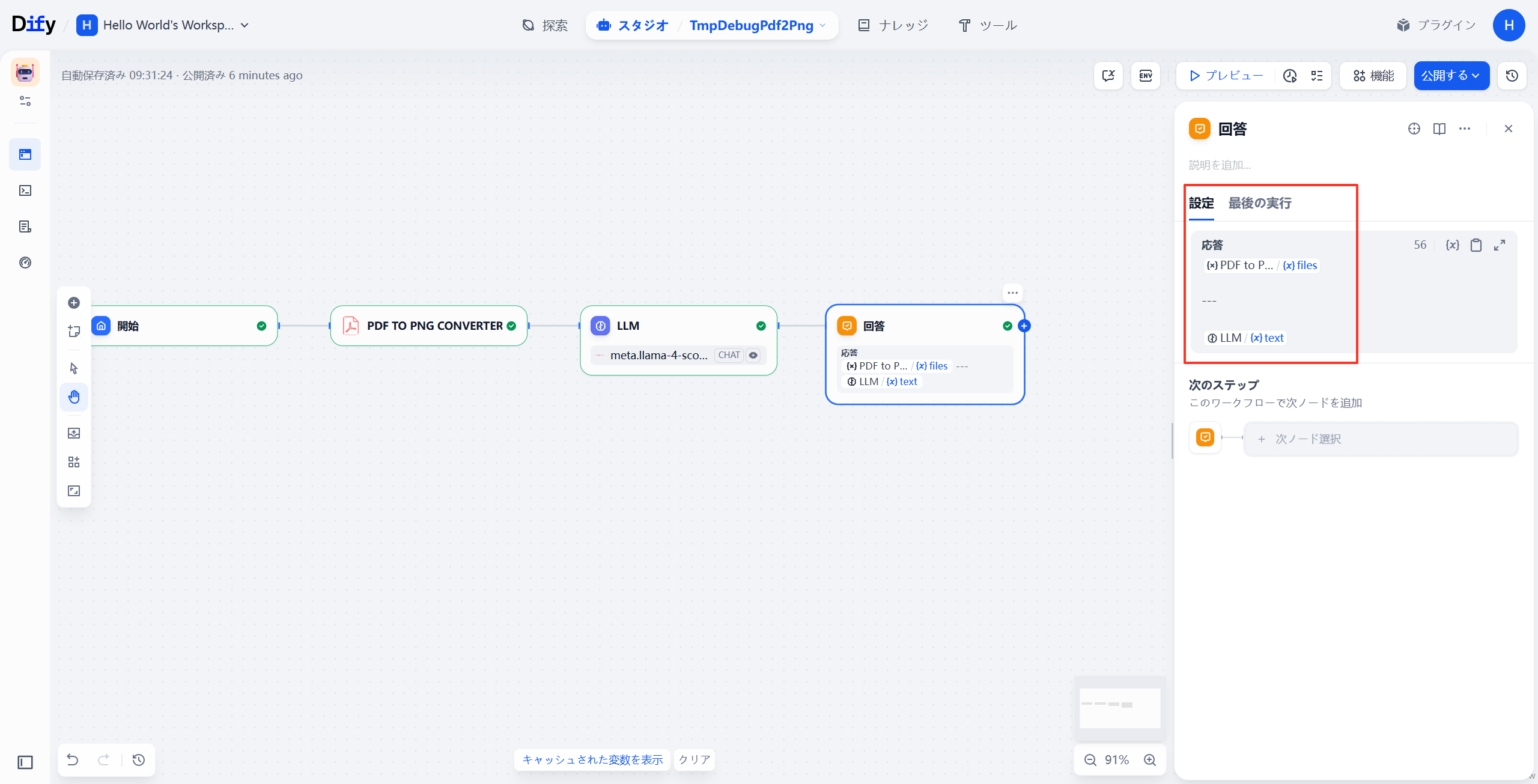
🧩 ステップ 4:回答ノードで結果を出力
- 回答 ノードを追加
- 入力を LLM の
textに設定
🧪 テスト実行
-
ファイル:任意の PDF(例:
5090_32GB.pdf) -
クエリ:
画像の内容を日本語で説明してください
実行すると、PDF の最終ページの画像が LLM に渡され、日本語で解説されたテキストが返却されます。
📝 まとめ
| 項目 | 内容 |
|---|---|
| 所要時間 | 約 5 分 |
| ノード数 | 開始・変換・LLM・回答 の 4 つ |
| 現状の注意点 | 最後の 1 枚のみ LLM に処理される |