daskとは
daskは、Pythonのnumpy arrayやPandas DataFrameのいろいろな処理を並列処理できるようにしてくれるパッケージです。
Dask: Scalable analytics in Python
結論
daskのファイル出力系メソッドは、通常compute()不要です!
おそらく入力系メソッドもcompute()不要です。(read_csv()のみ確認)
普通の使い方
基本的にdaskはやりたい処理に対してcompute()を実行することで処理を行います。
(例)
import pandas as pd
import dask.dataframe as dd
"""
(dask_0.csv)
A,B
1.1,1.2
2.1,2.2
3.1,3.2
"""
ddf = dd.read_csv("dask_*.csv")
sum_order = ddf.sum()
sum_order.compute()
"""
>>> df
A B
0 1.2 1.2
1 2.1 2.2
2 3.1 3.2
>>> ddf
Dask DataFrame Structure:
A B
npartitions=1
float64 float64
... ...
Dask Name: from-delayed, 3 tasks
>>>
>>> ddf.compute()
A B
0 1.1 1.2
1 2.1 2.2
2 3.1 3.2
>>> sum_order
Dask Series Structure:
npartitions=1
A float64
B ...
dtype: float64
Dask Name: dataframe-sum-agg, 5 tasks
>>> sum_order.compute()
A 6.4
B 6.6
dtype: float64
"""
ファイル入出力の場合
CSVに出力するメソッドto_csv()を例にとってみます。
予想した動作
いままで通り、処理を定義してからcompute()で実行させるものだと思っていました。
csv_order = ddf.to_csv("dask_*.csv", index=False)
for order in csv_order:
order.compute()
"""
>>> csv_order
[Delayed('_to_csv_chunk-c09f9b22-c7b9-4d07-b228-094a480438e7')]
>>> for x in csv_order:
... x.compute()
# dask_0.csvが出力される
"""
実際の動作
1行目のcsv_order = ddf.to_csv("dask_*.csv", index=False)を呼び出した時点で、compute()を実行しない段階でCSVファイルが出力されます。
(他の出力系メソッドto_hdf()、to_text_files()、to_parquet()でも同じような結果になります。)
(入力系メソッドも、おそらく同様です。)
csv_order = ddf.to_csv("dask_*.csv", index=False)
for order in csv_order:
order.compute()
"""
>>> csv_order = ddf.to_csv("dask_*.csv", index=False)
# dask_0.csvが出力される
>>> csv_order
['dask_0.csv']
>>> for x in csv_order:
... x.compute()
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
AttributeError: 'str' object has no attribute 'compute'
"""
原因
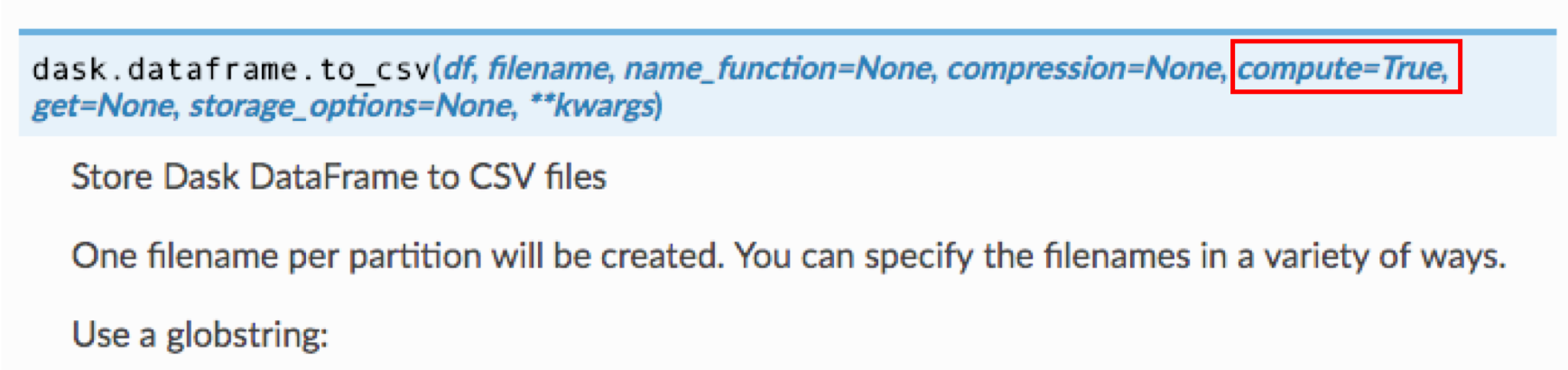
to_csv()の定義を見てみると、
def to_csv(df, filename, name_function=None, compression=None, compute=True,
get=None, storage_options=None, **kwargs):
となっていて、compute=Trueという属性がありました。ここから、デフォルトではcompute()も同時に実行していることが推測されます。
もしcomputeを独立して実行させたい場合は、
csv_order = ddf.to_csv("dask_*.csv", index=False, compute=False)
for order in csv_order:
order.compute()
とすれば、予想した動作の実行結果が得られます。
ハマった原因
まず、daskといえばcompute()を実行する必要があると思い込んでいた、、、(慢心、ダメ、絶対)
また、dask.dataframe.to_csvのドキュメントを読んでもはっきりとは書いていないし、Parametersを見てもcomputeなんて書いていないし、、、、(2018年3月28日現在)
(これってプルリク送って直してもらった方が良いのかな…?)



実はメソッドの定義にしれっと書いてあったんだけどね。。
あとがき
daskはなんでもかんでもcompute()するわけではないと知れて勉強になりました。