Go 言語+Elasticsearch で簡易求人サイトバックエンド構築
この記事は、マイナビ Advent Calendar 2021 9 日目の記事です。
今回の記事のソースコードは、GitHubで公開しています。
フォルダ構成は以下のようになります。
.
├── README.md
├── batch
│ ├── LoadData.go
│ ├── go.mod
│ ├── go.sum
│ └── test_data.xml
├── docker-compose.yml
├── es
│ ├── dic
│ │ └── test_dic.csv
│ ├── Dockerfile
│ ├── script
│ │ └── es_init.sh
│ └── sudachi
│ └── sudachi.json
├── search_api
│ ├── Dockerfile
│ ├── go.mod
│ ├── go.sum
│ ├── hr_api
│ ├── internal
│ │ ├── connect_es.go
│ │ ├── hr_query.go
│ │ └── hr_search.go
│ └── main.go
はじめに
Go 言語と Elasticsearch で簡易求人サイトバックエンドを構築してみます。
Docker コンテナ上で検索エンジン(Elasticsearch)を動かし、Go 製 Web サーバー(echo)から単語検索クエリを投げます。
単語検索したら、求人が JSON で出力されるような簡易求人検索バックエンドを構築します。
検索する場合は、以下のようなクエリを投げると想定して構築します。
#東京都の"カフェ"の求人を検索する
http://localhost:5000/search?keyword=カフェ&state=東京都
#東京都の"Go言語"の求人を検索する
http://localhost:5000/search?keyword=Go言語&state=東京都
#神奈川県の"アルバイト・パート"の求人を検索する
http://localhost:5000/search?keyword=アルバイト・パート&state=神奈川県
#求人のユニークidから検索する
http://localhost:5000/search?id=test
keywordは検索ワードを、stateは場所を、idは求人のユニークな番号指定するクエリパラメータとします。
Elasticsearch のダッシュボードとして、Kibana を使用します。
Kibana で、Elasticsearch のデータを確認すると以下のようになります。
また、大量の xml データを json 形式に直して、ElasicSearch に投入するバッチも作成します。
本番の想定だと、一日一回動かして求人データの更新を行います。
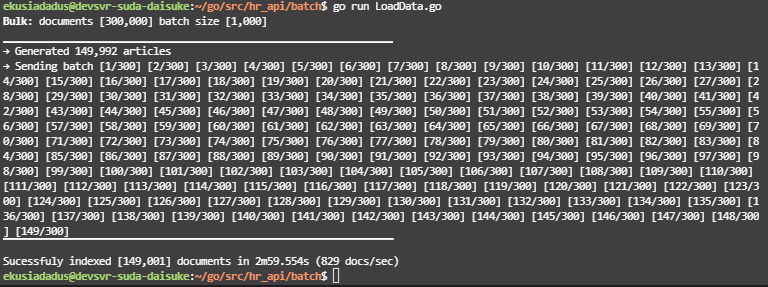
今回は、簡単に Go 言語で ElasicSearch に 10 万件程度のデータを BulkInsert していきます。
動作 OS は、Ubuntu 20.04 です。
以下、ツールのバージョンです。
| ツール | バージョン |
|---|---|
| Go 言語 | 1.17.2 |
| Docker | 1.41 |
| docker-compose | 1.29.2 |
| Elasticsearch | 7.8.1 |
| Kibana | 7.8.1 |
以下作成するときの手順です。
覚えている範囲で書き下したので、多少前後しますが、参考にしていただければ幸いです。
1. Elasticsearch を構築する
まず、Elasic Search を構築します。
Elasticsearch 公式を見てみると、バージョンがいくつかあります。
2021/12/7 時点では、7.14.2が、最新でした。
7.8.1 を選んだ理由はいくつかあります。
最も大きな理由は、Sudachiを Elasticsearch の辞書として使用したいからです。
WorksApplication 様のリポジトリでは、7.4 まで対応されていたので、7.4.1 を採用しました。
辞書にこだわらなければ、他のバージョンでも動作すると思います。
Sudachi を採用した Elasticsearch の Dockerfile は、最終的にこのようになりました。
あまり、Docker コンテナの最適な作成に詳しくはないので参考にならないかもしれません。
コンテナのイメージサイズを減らせるかなぁと試行錯誤していますが、結局あまり変化しなくて悩んでます。
ARG ELASTIC_VER=7.8.1
ARG SUDACHI_PLUGIN_VER=2.0.3
FROM ibmjava:8-jre-alpine as dict_builder
ARG ELASTIC_VER
ARG SUDACHI_PLUGIN_VER
WORKDIR /home
RUN wget https://github.com/WorksApplications/Elasticsearch-sudachi/releases/download/v${ELASTIC_VER}-${SUDACHI_PLUGIN_VER}/analysis-sudachi-${ELASTIC_VER}-${SUDACHI_PLUGIN_VER}.zip && \
unzip analysis-sudachi-${ELASTIC_VER}-${SUDACHI_PLUGIN_VER}.zip && \
wget http://sudachi.s3-website-ap-northeast-1.amazonaws.com/sudachidict/sudachi-dictionary-20210802-core.zip && \
unzip sudachi-dictionary-20210802-core.zip && \
mkdir -p /usr/share/Elasticsearch/config/sudachi/ && \
mv sudachi-dictionary-20210802/system_core.dic /usr/share/Elasticsearch/config/sudachi/ && \
rm -rf sudachi-dictionary-20210802-core.zip sudachi-dictionary-20210802/
FROM docker.elastic.co/Elasticsearch/Elasticsearch:${ELASTIC_VER}
ARG ELASTIC_VER
ARG SUDACHI_PLUGIN_VER
COPY es/sudachi/sudachi.json /usr/share/Elasticsearch/config/sudachi/
COPY --from=dict_builder /home/analysis-sudachi-${ELASTIC_VER}-${SUDACHI_PLUGIN_VER}.zip /usr/share/Elasticsearch/
docker-compose.yml の、Elasticsearch 部分を抽出するとこんな感じです。
詳しくは、今回の記事のソースコードGitHubを確認いただけますと幸いです。
Elasticsearch:
build:
context: .
dockerfile: es/dockerfile
container_name: Elasticsearch
volumes:
- es-data:/usr/share/Elasticsearch/data
networks:
- Elasticsearch
ports:
- 9200:9200
environment:
- discovery.type=single-node
- node.name=Elasticsearch
- cluster.name=go-Elasticsearch-docker-cluster
- bootstrap.memory_lock=true
- ES_JAVA_OPTS=-Xms256m -Xmx256m
ulimits:
{ nofile: { soft: 65535, hard: 65535 }, memlock: { soft: -1, hard: -1 } }
healthcheck:
test: curl --head --max-time 120 --retry 120 --retry-delay 1 --show-error --silent http://localhost:9200
docker-compose.yml で注意したのは、後からバックエンドサーバーから検索できるようにすることであったり、メモリリミット周りです。
後から少し触れますが BulkInsert するときに少し躓きました。
詳しくは公式ドキュメントを参考にしてください。
2. Kibana を構築する
Kibana の構築は、公式ドキュメント通りに構築したら動作してくれたので、悩むことがなかったです。
最終的に、docker-compose.yml は以下のようになりました。
kibana:
container_name: kibana
image: docker.elastic.co/kibana/kibana:7.8.1
depends_on: ["Elasticsearch"]
networks:
- Elasticsearch
ports:
- 5601:5601
environment:
- Elasticsearch_HOSTS=http://Elasticsearch:9200
- KIBANA_LOGGING_QUIET=true
healthcheck:
test: curl --max-time 120 --retry 120 --retry-delay 1 --show-error --silent http://localhost:5601
3. Elasticsearch にデータを投入する
ここから、Go で Elasticsearch とどのように通信するかで悩みました。
まず、どのパッケージを使用するかで悩みました。
基本的には、以下の 2 つのパッケージの使用が多いと思います。
1 は、スター数が一番多い Go の Elasticsearch クライアントパッケージになります。
非常に使い勝手が良くて、ドキュメントも豊富です。
一番最初はこれで構築しようと考えていました。
2 は Elastic 公式のパッケージなので今回は 2 を使用して作成しようと決めました。
ドキュメントがあまり存在していなくて、GitHub 公式の_exampleを参考にして作成しました。
結構最初は、骨が折れる作業だったのですがなれるとめちゃくちゃ便利な機能がたくさんありました。
慣れるには、時間がかかるパッケージです。
BulkInsert
Elasticsearch に今回は、30 万件数の求人データを投入する想定で作成していたので、BulkInsert(go-Elasticsearch では、BulkIndex と呼んでいるらしい)は必須だと考えていました。
まず最初は、普通の Insert で作成しました。
Go 言語のコードを抜粋するとこんな感じです。
req := esapi.IndexRequest{
Index: "baito",
DocumentID: string(j.Referencenumber),
Body: strings.NewReader(string(jobbody)),
Refresh: "true",
}
公式の GitHubを参考にして作成したのですが、10 万件程度の挿入に 1 時間 30 分程度かかりました。(計測写真が紛失しました)
大抵の場合、すべての挿入に耐えられず途中で timeout してしまうので、普通の insert で 30 万件は実用的でないと思います。
そこで、BulkInsertを参考にしたのですが、よくわらん...(*´-ω・)ン? (。´-_・)ン? (´・ω・`)モキュ?
結局、このドキュメントの理解(と xml パーサドキュメント)に 3 日を費やしました。
最終的に出来上がった Go 言語のコードは以下のようになりました。
package main
import (
"bytes"
"encoding/json"
"encoding/xml"
"flag"
"fmt"
"io"
"log"
"math/rand"
"os"
"strings"
"time"
"github.com/dustin/go-humanize"
"github.com/elastic/go-Elasticsearch/v7"
"github.com/elastic/go-Elasticsearch/v7/esapi"
"github.com/joho/godotenv"
)
type Job struct {
Referencenumber string `xml:"referencenumber" json:"referencenumber,string"`
Date string `xml:"date" json:"date,string"`
Url string `xml:"url" json:"url,string"`
Title string `xml:"title" json:"title,string"`
Description string `xml:"description" json:"description,string"`
State string `xml:"state" json:"state,string"`
City string `xml:"city" json:"city,string"`
Country string `xml:"country" json:"country,string"`
Station string `xml:"station" json:"station,string"`
Jobtype string `xml:"jobtype" json:"jobtype,string"`
Salary string `xml:"salary" json:"salary,string"`
Category string `xml:"category" json:"category,string"`
ImageUrls string `xml:"imageUrls" json:"imageurls,string"`
Timeshift string `xml:"timeshift" json:"timeshift,string"`
Subwayaccess string `xml:"subwayaccess" json:"subwayaccess,string"`
Keywords string `xml:"keywords" json:"keywords,string"`
}
var (
_ = fmt.Print
count int
batch int
)
func init() {
flag.IntVar(&count, "count", 300000, "Number of documents to generate")
flag.IntVar(&batch, "batch", 1000, "Number of documents to send in one batch")
flag.Parse()
rand.Seed(time.Now().UnixNano())
}
func main() {
log.SetFlags(0)
type bulkResponse struct {
Errors bool `json:"errors"`
Items []struct {
Index struct {
ID string `json:"_id"`
Result string `json:"result"`
Status int `json:"status"`
Error struct {
Type string `json:"type"`
Reason string `json:"reason"`
Cause struct {
Type string `json:"type"`
Reason string `json:"reason"`
} `json:"caused_by"`
} `json:"error"`
} `json:"index"`
} `json:"items"`
}
var (
buf bytes.Buffer
res *esapi.Response
err error
raw map[string]interface{}
blk *bulkResponse
jobs []*Job
indexName = "baito"
numItems int
numErrors int
numIndexed int
numBatches int
currBatch int
)
log.Printf(
"\x1b[1mBulk\x1b[0m: documents [%s] batch size [%s]",
humanize.Comma(int64(count)), humanize.Comma(int64(batch)))
log.Println(strings.Repeat("▁", 65))
// Create the Elasticsearch client
//
es, err := Elasticsearch.NewDefaultClient()
if err != nil {
log.Fatalf("Error creating the client: %s", err)
}
err = godotenv.Load(".env")
if err != nil {
log.Fatal("Error loading .env file")
}
xml_path := os.Getenv("BAITO_XML_PATH")
f, err := os.Open(xml_path)
if err != nil {
log.Fatal(err)
}
defer f.Close()
d := xml.NewDecoder(f)
for i := 1; i < count+1; i++ {
t, tokenErr := d.Token()
if tokenErr != nil {
if tokenErr == io.EOF {
break
}
// handle error somehow
log.Fatalf("Error decoding token: %s", tokenErr)
}
switch ty := t.(type) {
case xml.StartElement:
if ty.Name.Local == "job" {
// If this is a start element named "location", parse this element
// fully.
var job Job
if err = d.DecodeElement(&job, &ty); err != nil {
log.Fatalf("Error decoding item: %s", err)
} else {
jobs = append(jobs, &job)
}
}
default:
}
// fmt.Println("count =", count)
}
log.Printf("→ Generated %s articles", humanize.Comma(int64(len(jobs))))
fmt.Print("→ Sending batch ")
// Re-create the index
//
if res, err = es.Indices.Delete([]string{indexName}); err != nil {
log.Fatalf("Cannot delete index: %s", err)
}
res, err = es.Indices.Create(indexName)
if err != nil {
log.Fatalf("Cannot create index: %s", err)
}
if res.IsError() {
log.Fatalf("Cannot create index: %s", res)
}
if count%batch == 0 {
numBatches = (count / batch)
} else {
numBatches = (count / batch) + 1
}
start := time.Now().UTC()
// Loop over the collection
//
for i, a := range jobs {
numItems++
currBatch = i / batch
if i == count-1 {
currBatch++
}
// Prepare the metadata payload
//
meta := []byte(fmt.Sprintf(`{ "index" : { "_id" : "%d" } }%s`, a.Referencenumber, "\n"))
// fmt.Printf("%s", meta) // <-- Uncomment to see the payload
// Prepare the data payload: encode article to JSON
//
data, err := json.Marshal(a)
if err != nil {
log.Fatalf("Cannot encode article %d: %s", a.Referencenumber, err)
}
// Append newline to the data payload
//
data = append(data, "\n"...) // <-- Comment out to trigger failure for batch
// fmt.Printf("%s", data) // <-- Uncomment to see the payload
// // Uncomment next block to trigger indexing errors -->
// if a.ID == 11 || a.ID == 101 {
// data = []byte(`{"published" : "INCORRECT"}` + "\n")
// }
// // <--------------------------------------------------
// Append payloads to the buffer (ignoring write errors)
//
buf.Grow(len(meta) + len(data))
buf.Write(meta)
buf.Write(data)
// When a threshold is reached, execute the Bulk() request with body from buffer
//
if i > 0 && i%batch == 0 || i == count-1 {
fmt.Printf("[%d/%d] ", currBatch, numBatches)
res, err = es.Bulk(bytes.NewReader(buf.Bytes()), es.Bulk.WithIndex(indexName))
if err != nil {
log.Fatalf("Failure indexing batch %d: %s", currBatch, err)
}
// If the whole request failed, print error and mark all documents as failed
//
if res.IsError() {
numErrors += numItems
if err := json.NewDecoder(res.Body).Decode(&raw); err != nil {
log.Fatalf("Failure to to parse response body: %s", err)
} else {
log.Printf(" Error: [%d] %s: %s",
res.StatusCode,
raw["error"].(map[string]interface{})["type"],
raw["error"].(map[string]interface{})["reason"],
)
}
// A successful response might still contain errors for particular documents...
//
} else {
if err := json.NewDecoder(res.Body).Decode(&blk); err != nil {
log.Fatalf("Failure to to parse response body: %s", err)
} else {
for _, d := range blk.Items {
// ... so for any HTTP status above 201 ...
//
if d.Index.Status > 201 {
// ... increment the error counter ...
//
numErrors++
// ... and print the response status and error information ...
log.Printf(" Error: [%d]: %s: %s: %s: %s",
d.Index.Status,
d.Index.Error.Type,
d.Index.Error.Reason,
d.Index.Error.Cause.Type,
d.Index.Error.Cause.Reason,
)
} else {
// ... otherwise increase the success counter.
//
numIndexed++
}
}
}
}
// Close the response body, to prevent reaching the limit for goroutines or file handles
//
res.Body.Close()
// Reset the buffer and items counter
//
buf.Reset()
numItems = 0
}
}
// Report the results: number of indexed docs, number of errors, duration, indexing rate
//
fmt.Print("\n")
log.Println(strings.Repeat("▔", 65))
dur := time.Since(start)
if numErrors > 0 {
log.Fatalf(
"Indexed [%s] documents with [%s] errors in %s (%s docs/sec)",
humanize.Comma(int64(numIndexed)),
humanize.Comma(int64(numErrors)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(numIndexed))),
)
} else {
log.Printf(
"Sucessfuly indexed [%s] documents in %s (%s docs/sec)",
humanize.Comma(int64(numIndexed)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(numIndexed))),
)
}
}
BulkInsertの公式のサンプルとにらめっこして作成しました。
あと、PC のスペックもそんなに高くない(メモリ 4GB、CPU 2 コア)なので XML パーサも省メモリで行わなければなりませんでした。
ちなみに、この Go 言語のコードを書く前に Python のコードを参考にしていて途中から Go 言語をあきらめようかと思うほどでした。
抜粋するとこんな感じです。
for job in jobs:
index = job.as_dict()
if job.description == "" or job.description == null:
continue
bulk_file += json.dumps(
{"index": {"_index": index_name, "_type": "_doc", "_id": id}}
)
# The optional_document portion of the bulk file
bulk_file += "\n" + json.dumps(index) + "\n"
if id % 1000 == 0:
response = client.bulk(bulk_file)
bulk_file = ""
id += 1
continue
id += 1
if bulk_file != "":
response = client.bulk(bulk_file)
Go 言語のコードも、Python コードも 1000 件づつ BulkInsert を行うようにしています。
Go 言語のコードだと、14 万件程度のデータを約 3 分で、Elasticsearch に投入することができました。
4. Go バックエンドサーバーを作成する
次に、Go の Web サーバーから Elasticsearch に検索をかける箇所の作成をしました。
(BulkInsert を途中で、あきらめてこっち先にやりました)
Go の Web サーバーはいくつかありますが、単純にechoを採用しました。
ドキュメントも豊富で、簡潔に書くことができました。
フォルダ構成は、以下のようになります。
.
├── search_api
│ ├── Dockerfile
│ ├── go.mod
│ ├── go.sum
│ ├── hr_api
│ ├── internal
│ │ ├── connect_es.go
│ │ ├── hr_query.go
│ │ └── hr_search.go
│ └── main.go
main.go は、簡潔で echo で Web サーバーを立ちあげるだけです。
package main
import (
internal "hr_api/internal"
"github.com/labstack/echo"
"github.com/labstack/echo/middleware"
)
func main() {
e := echo.New()
e.Use(middleware.Logger())
e.Use(middleware.Recover())
e.Use(middleware.CORS())
e.GET("/search", internal.HRSearch)
e.Logger.Fatal(e.Start(":5000"))
}
internal 配下は、結構悩んで作成しました。
具体的には構造体をどう持つか(結局、全部 string にしていました;;;)、Elasticsearch との通信をどのように行うか等です。
package internal
import (
"bytes"
"context"
"encoding/json"
"fmt"
"net/http"
"github.com/labstack/echo"
)
type Query struct {
Keyword string `query:"keyword"`
State string `query:"state"`
Id string `query:"id"`
}
type Result struct {
Referencenumber string `xml:"referencenumber" json:"referencenumber,string"`
Date string `xml:"date" json:"date,string"`
Url string `xml:"url" json:"url,string"`
Title string `xml:"title" json:"title,string"`
Description string `xml:"description" json:"description,string"`
State string `xml:"state" json:"state,string"`
City string `xml:"city" json:"city,string"`
Country string `xml:"country" json:"country,string"`
Station string `xml:"station" json:"station,string"`
Jobtype string `xml:"jobtype" json:"jobtype,string"`
Salary string `xml:"salary" json:"salary,string"`
Category string `xml:"category" json:"category,string"`
ImageUrls string `xml:"imageUrls" json:"imageurls,string"`
Timeshift string `xml:"timeshift" json:"timeshift,string"`
Subwayaccess string `xml:"subwayaccess" json:"subwayaccess,string"`
Keywords string `xml:"keywords" json:"keywords,string"`
}
type Response struct {
Message string `json:"message"`
Results []Result
}
func HRSearch(c echo.Context) (err error) {
// クライアントからのパラメーターを取得
q := new(Query)
if err = c.Bind(q); err != nil {
return
}
res := new(Response)
var (
b map[string]interface{}
buf bytes.Buffer
)
// Elasticsearch へのクエリを作成
query := CreateQuery(q)
json.NewEncoder(&buf).Encode(query)
fmt.Printf(buf.String())
// Elasticsearch へ接続
es, err := ConnectElasticsearch()
if err != nil {
c.Error(err)
}
// Elasticsearch へクエリ
r, err := es.Search(
es.Search.WithContext(context.Background()),
es.Search.WithIndex("baito"),
es.Search.WithBody(&buf),
es.Search.WithTrackTotalHits(true),
es.Search.WithPretty(),
)
if err != nil {
c.Error(err)
}
defer r.Body.Close()
if err := json.NewDecoder(r.Body).Decode(&b); err != nil {
c.Error(err)
}
// クエリの結果を Responce.Results に格納
for _, hit := range b["hits"].(map[string]interface{})["hits"].([]interface{}) {
result := new(Result)
doc := hit.(map[string]interface{})
fmt.Printf(result.Title)
result.Referencenumber = doc["_source"].(map[string]interface{})["referencenumber"].(string)
result.Date = doc["_source"].(map[string]interface{})["date"].(string)
result.Url = doc["_source"].(map[string]interface{})["url"].(string)
result.Title = doc["_source"].(map[string]interface{})["title"].(string)
result.State = doc["_source"].(map[string]interface{})["state"].(string)
result.Category = doc["_source"].(map[string]interface{})["category"].(string)
result.Description = doc["_source"].(map[string]interface{})["description"].(string)
result.City = doc["_source"].(map[string]interface{})["city"].(string)
result.Country = doc["_source"].(map[string]interface{})["country"].(string)
result.Station = doc["_source"].(map[string]interface{})["station"].(string)
result.Jobtype = doc["_source"].(map[string]interface{})["jobtype"].(string)
result.Salary = doc["_source"].(map[string]interface{})["salary"].(string)
result.ImageUrls = doc["_source"].(map[string]interface{})["imageurls"].(string)
result.Timeshift = doc["_source"].(map[string]interface{})["timeshift"].(string)
result.Subwayaccess = doc["_source"].(map[string]interface{})["subwayaccess"].(string)
result.Keywords = doc["_source"].(map[string]interface{})["keywords"].(string)
res.Results = append(res.Results, *result)
}
res.Message = "検索に成功しました。"
return c.JSON(http.StatusOK, res)
}
hr_query.go は、本当であれば一番考えなければいけない箇所だと思います。
検索に重みづけをして、UX を大幅に改善できる箇所だと思います。
package internal
func CreateQuery(q *Query) map[string]interface{} {
query := map[string]interface{}{}
if q.Id != "" {
query = map[string]interface{}{
"query": map[string]interface{}{
"bool": map[string]interface{}{
"must": []map[string]interface{}{
{
"match": map[string]interface{}{
"referencenumber": q.Id,
},
},
},
},
},
}
} else if q.Keyword != "" && q.State != "" {
query = map[string]interface{}{
"query": map[string]interface{}{
"bool": map[string]interface{}{
"must": []map[string]interface{}{
{
"bool": map[string]interface{}{
"should": []map[string]interface{}{
{
"match": map[string]interface{}{
"title": map[string]interface{}{
"query": q.Keyword,
"boost": 3,
},
},
},
{
"match": map[string]interface{}{
"description": map[string]interface{}{
"query": q.Keyword,
"boost": 2,
},
},
},
{
"match": map[string]interface{}{
"category": map[string]interface{}{
"query": q.Keyword,
"boost": 1,
},
},
},
},
"minimum_should_match": 1,
},
},
{
"bool": map[string]interface{}{
"must": []map[string]interface{}{
{
"match": map[string]interface{}{
"state": q.State,
},
},
},
},
},
},
},
},
}
} else if q.Keyword != "" && q.State == "" {
query = map[string]interface{}{
"query": map[string]interface{}{
"bool": map[string]interface{}{
"should": []map[string]interface{}{
{
"match": map[string]interface{}{
"title": map[string]interface{}{
"query": q.Keyword,
"boost": 3,
},
},
},
{
"match": map[string]interface{}{
"description": map[string]interface{}{
"query": q.Keyword,
"boost": 2,
},
},
},
{
"match": map[string]interface{}{
"category": map[string]interface{}{
"query": q.Keyword,
"boost": 1,
},
},
},
},
"minimum_should_match": 1,
},
},
}
} else if q.Keyword == "" && q.State != "" {
query = map[string]interface{}{
"query": map[string]interface{}{
"bool": map[string]interface{}{
"must": []map[string]interface{}{
{
"match": map[string]interface{}{
"state": q.State,
},
},
},
},
},
}
}
return query
}
Elasticsearch に接続して通信する部分です。ここは、Qiita 等に上がっている記事を参考にさせていただいたと思います,,,が記事の URL が見つからなくなってしまいました。。。
package internal
import (
"os"
Elasticsearch "github.com/elastic/go-Elasticsearch/v7"
)
func ConnectElasticsearch() (*Elasticsearch.Client, error) {
// 環境変数 ES_ADDRESS がある場合は記述されているアドレスに接続
// ない場合は、 http://localhost:9200 に接続
var addr string
if os.Getenv("ES_ADDRESS") != "" {
addr = os.Getenv("ES_ADDRESS")
} else {
addr = "http://localhost:9200"
}
cfg := Elasticsearch.Config{
Addresses: []string{
addr,
},
}
es, err := Elasticsearch.NewClient(cfg)
return es, err
}
5. ブラウザで確認してみる
これで、やっと動くようになります。
docker-compose up を行って、go run main.goとすると、ブラウザから確認できると思います。
VSCode で、行うとわかりやすいと思います。
Remote SSH で開発環境用のサーバーで行っている場合は、上司の note 等参考にしていただけますと嬉しです。
こんな感じで、ブラウザから確認できます。
http://localhost:5000/search?keyword=カフェ&state=東京都
{
"message": "検索に成功しました。",
"Results": [
{
"referencenumber": "test",
"date": "2222-11-01",
"url": "test",
"title": "おしゃれカフェ・店舗スタッフ/ブック&カフェ/アルバイト・パート/おしゃれカフェ",
"description": "【省略】",
"state": "東京都",
"city": "渋谷区",
"country": "日本",
"station": "山手線渋谷駅 徒歩700分",
"jobtype": "アルバイト・パート",
"salary": "test円",
"category": "飲食・フード×おしゃれカフェ",
"imageurls": "test",
"timeshift": "週3日以上/1日3時間以上",
"subwayaccess": "山手線渋谷駅徒歩700分",
"keywords": "test"
},
6. 最後に
マイナビでは、求人サイトを多く運営しているます。
Go 言語で簡易的求人サイトを作成することで、技術的な背景を再勉強することができました。
興味がある方は、是非作成してみてください!