はじめに
前回、 はじめてのタイタニックに書いた通り、pythonのスキルがあまりにもないなぁと思い、pythonを動かしながら機械学習のお作法が学べるモノがないかと探していたところ、Pythonで機械学習:scikit-learnで学ぶ識別入門を発見!
講座内容や対象者も割と自分向きだなぁと思い受けてみようかと思います。以下、udemyの公式サイトからの転記です
出所:https://qiita.com/ejama/items/32d31fcc5e350ec5ea5f
講座内容
このコースでは,機械学習における識別(分類・認識)の基礎をPythonを用いて学びます.このコースの目標は,機械学習でデータを識別するための一連の流れ(データの準備・前処理・識別器・評価など)を理解することです.Pythonの機械学習ライブラリscikit-learnとインタラクティブなプログラミング環境jupyter notebook (ipython notebook)を使って,実際>にpythonコードを実行しながら学びます.
こんな方におすすめ
・機械学習という言葉は知っているが,中身を知らない人
・プログラミングが嫌いではない人(Pythonプログラミングをします)
・Pythonプログラミング環境を用意できる人
・具体的に機械学習を適用したいデータがある人
どうやって進めるか?
受講する ⇒ 手を動かす ⇒ Qiitaにまとめる、というサイクルで進めようと思います。上記講座を受ける人の参考になればと思います!
講座内容(セクション別のまとめ)
1.機械学習とは
識別の機械学習の例として、
・迷惑メールフィルタ
・ガン認識
・表情分類 など
あらかじめ分類を用意し与えられた問題に対して機械学習しながら識別をしていく(pythonやsklearnを用いて)のだと思います
2.Jupyter notebookの設定(Pythonプログラミングの環境設定)
タイトルの通り、pythonで学習をするにあたっての環境設定です。OSはlinux、windows、Mac全部のやり方を説明しています。また、Dockerでの動かし方やクラウド上でやる場合も紹介しています。クラウドはSageMathCloudを紹介していますが、最近では、GUIが使えるgoogle colabも有名ですね
3.最初の例題:学習から識別まで
まずは、sklearnでできるいろんな識別器を紹介
# KNN
from sklearn import neighbors
clf = neighbors.KNeighborsClassifier(n_neighbors=1)
# 単純な線形モデル
from sklearn import linear_model
clf = linear_model.LogisticRegression()
# SVM 線形モデル
from sklearn import svm
clf = svm.SVC(kernel='linear')
次にsklearnにあるデータセット(ガン良性/悪性とアヤメ)を用いて、機械学習をさせてみた。ちなみに、ガンデータとアヤメデータの取得方法は以下の通り
# ガンデータを準備
from sklearn.datasets import load_breast_cancer
# アヤメデータ
from sklearn.datasets import load_iris
取得したデータが昇順や降順になっているとそのまま学習しても意味がないので、シャッフルさせます
# シャッフルオブジェクトを作成
from sklearn.model_selection import ShuffleSplit
ss = ShuffleSplit(n_splits=1,
train_size = 0.5,
test_size = 0.5,
random_state=0)
# indexをシャッフルしてスプリットする
train_idx, test_idx = next(ss.split(X))
最後にトレーニングサイズを動的に変更しながら、トレーニングサイズの適切値を見極めまし、こんな感じで可視化
import matplotlib.pyplot as plt
plt.plot(train_sizes, all_means)
plt.ylim(0.70,1) # yの表示範囲指定
plt.xlim(0,1) # xの表示範囲指定
plt.errorbar(train_sizes, all_means,yerr=all_stds) # エラーバーをつける
plt.title('Average') # グラフタイトル
plt.xlabel('Train Data Size %') # x軸のタイトル
plt.ylabel('accuracy rate %') # y軸のタイトル
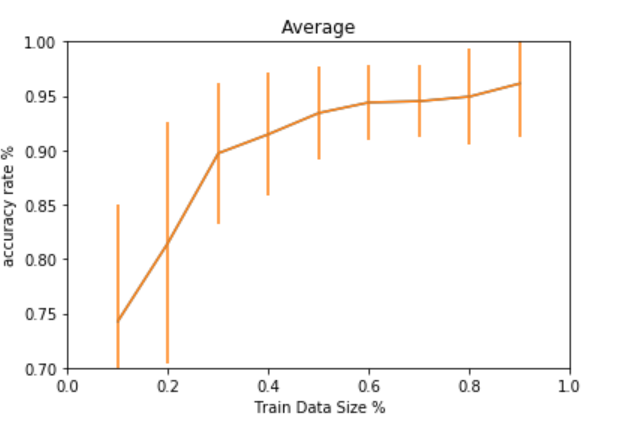
4.学習データとテストデータの準備
まずは学習データと検証データとテストデータの考え方。全データで学習しちゃダメよ。サンプル数によって、採用するデータ分割方法は考える必要があるとのこと。
データ分割において分類の割合が、学習データと検証データ間で偏ると、学習結果を正しく検証できない事態に陥ります。
そこで、sklearn.model_selectionにあるStratifiedShuffleSplitを利用します。使い方は以下の通り。
## ガンのデータでStratifiedShuffleSplitを使ってみる
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
X = data.data
y = data.target
from sklearn.model_selection import StratifiedShuffleSplit
ss = ShuffleSplit(n_splits=100
,train_size=0.95
,test_size =0.05)
train_idx, test_idx = next(ss.split(X,y))
# yの割合を確認する
print(np.unique(y, return_counts=True))
print(np.unique(y, return_counts=True)[1] / y.shape)
print(np.unique(y[train_idx], return_counts=True)[1] / train_idx.shape)
print(np.unique(y[test_idx], return_counts=True)[1] / test_idx.shape)
(array([0, 1]), array([212, 357], dtype=int64))
[0.37258348 0.62741652]
[0.37222222 0.62777778]
[0.37931034 0.62068966]
K-Fold CVの説明
次はK-Fold CVを使っての実装.やり方はいたってシンプル
from sklearn.model_selection import KFold
ss = KFold(n_splits=10, shuffle=True)
ただし、これだとyの分布が偏ってしまうので、K_foldのStratifiedを利用します
from sklearn.model_selection import StratifiedKFold
ss = KFold(n_splits=10, shuffle=True)
Leave on outについても解説ありましたが、基本はKFoldと同じのため省略
何のためにバリデーションテストをするのか?
最適なパラメータを探すため。基本はtrainデータの中でパラーメータを変えながら、一番いい値を探していくそうです。以下、ロジスティック回帰においてCの最適なパラメータを探すためのコード
from sklearn import linear_model
clf = linear_model.LogisticRegression()
C_range_exp = np.linspace(start=-15, stop=20,num=36)
C_range = 10 ** C_range_exp
all_score_mean = []
all_score_std = []
for C in C_range:
clf.C = C
score = cross_val_score(clf, X_train,y_train, cv=10)
all_score_mean.append(score.mean())
all_score_std.append(score.std())
# グラフ表示
import matplotlib.pyplot as plt
plt.plot(C_range_exp, all_score_mean)
plt.errorbar(C_range_exp, all_score_mean,yerr=all_score_std)
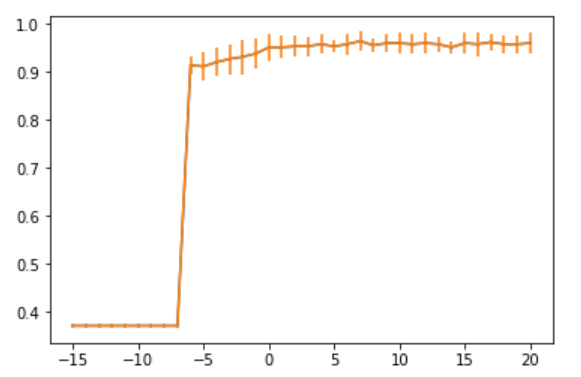
とあるポイントで急に最適化されたことがかわります。このように、パラメータを探すためにクロスバリデーションをすることがわかりました。きっとこの先、特徴量を抽出するときにも使うんだろうなぁ。。
5.データから特徴量へ
データ取得から識別までに以下のプロセスで進めるそうです。
1.データ取得
2.特徴量抽出
3.特徴選択
4.特徴変換
5.正規化
6.識別
プロセス多いなぁ。。。とはいえ、前にタイタニック をやったとには4.や5.のステップは踏んでいなかったなぁと。。。 さすが実践的な講座!
欠損値の処理(1.データ取得)
NaNのデータを取り除けばよい。(サンプル数が減るので平均値や中央値で埋めるとかやり方はイロイロあります)numpy にあるisnan関数を用いてNaNを取り除きます.やっていることはいたってシンプルで、X[:,0]とX[:,1]にNaNが1つであればそれを除外する。ちなみに"~"は否定(Not)です
# NaNを除外してX1, y1変数に代入をする
X1 = X[~np.isnan(X[:,0]) & ~np.isnan(X[:,1])]
y1 = y[~np.isnan(X[:,0]) & ~np.isnan(X[:,1])]
外れ値の処理(1.データ取得)
ここでは絶対値(abs)10以下であればTrue(つまり外れ値ではない)とします.以下の式で絶対値が10以上の値が削除されてX2, y2に代入されます。
X2 = X1[(abs(X1[:,0]) < 10) & (abs(X1[:,1]) < 10)]
y2 = y1[(abs(X1[:,0]) < 10) & (abs(X1[:,1]) < 10)]
2.特徴量抽出
テキストの単語の出現頻度をベクトル化するやり方の説明です。これもsklearnのライブラリを使うことで簡単にできます. どこかで使うことがあるかなぁ。。。
# テキスト用の特徴量抽出ライブラリ(単語頻度の抽出)
from sklearn.feature_extraction.text import CountVectorizer
txt_vec = CountVectorizer(input='filename')
txt_vec.fit(['allice.txt']) # 単語の種類を学習
allice_vec = txt_vec.transform(['allice.txt']) # 単語数を取得
おまけ
画像の特徴量抽出例を紹介していました。RGBを度数をヒストグラム化して横方向に結合をして特徴量としていました。
ちなみにこのやり方はあまりfitしないので、実社会では採用されていないそうです。あくまでも参考までって感じですね
3.特徴選択
有効な特徴量を抽出するために、sklearnのライブラリを取得して実施します
# 特徴量を抽出
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
skb = SelectKBest(chi2, k=20)
skb.fit(X_train, y_train)
X_train_new = skb.transform(X_train)
ちなみに、一番いいkを探すためのコードはこんな感じです。抜粋なので、そのままでは動きませんが。。
# 有効な次元数を取得する
from sklearn import linear_model
clf = linear_model.LogisticRegression()
from sklearn.model_selection import StratifiedKFold
k_range = np.arange(1,31)
scores = []
std = []
for k in k_range:
ss = StratifiedKFold(n_splits=10,
shuffle=True,
random_state=2)
score=[]
for train_idx , vel_idx in ss.split(X_train,y_train):
X_train_tmp , y_train_tmp =X[train_idx], y[train_idx]
X_val , y_val =X[vel_idx], y[vel_idx]
skb = SelectKBest(chi2,k = k)
skb.fit(X_train_tmp, y_train_tmp)
X_new_train_tmp = skb.transform(X_train_tmp)
X_new_val = skb.transform(X_val)
clf.fit(X_new_train_tmp, y_train_tmp)
score.append(clf.score(X_new_val, y_val))
scores.append(np.array(score).mean())
std.append(np.array(score).std())
4.特徴抽出(PCA編)
線形変換、それぞれの特徴量に対して重みを足す。
まずは、10個取り出してそれぞれ対で相関関係を確認する。ちなみにdataにはsklearnのガンデータが入っています
import pandas as pd
from pandas.tools.plotting import scatter_matrix
df = pd.DataFrame(data.data[:,0:10] ,columns=data.feature_names[0:10])
scatter_matrix(df, figsize=(10,10))
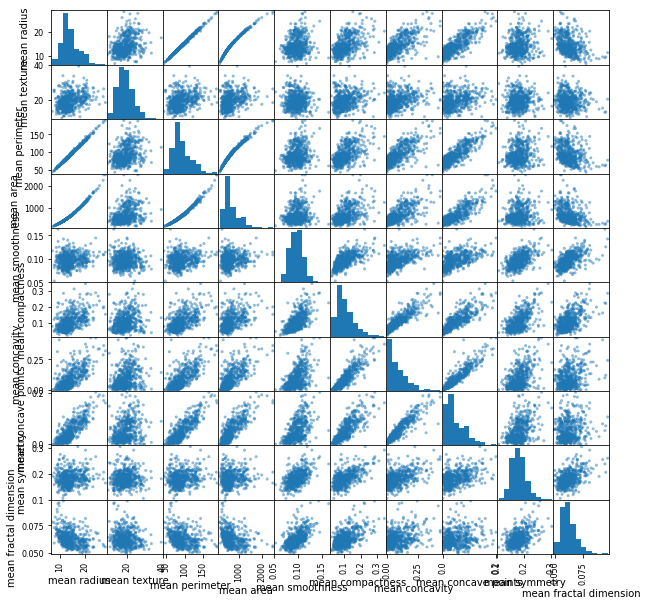
PCAは特徴量を合成する?って理解でいいのかな?サンプルコードは以下の通り
# まずはそのままのデータでプロット
X = data.data[:,[0,2]]
y = data.target
names = data.feature_names[[0,2]]
plt.scatter(X[:,0],X[:,1])
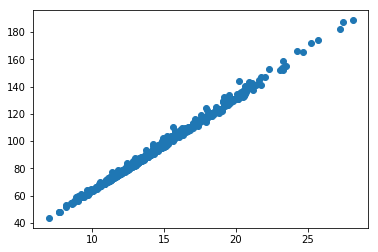
この状況から、y軸報告に次元削減をする
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(X)
X_new = pca.transform(X)
plt.scatter(X_new[:,0], X_new[:,1])
plt.ylim(-10,10 )

【飽きたのでいったんここで終了】
sklearnが非常に便利なライブラリであることがわかりました。
便利が故、それぞれの中身がどうなっているのかわからないままになってしまうことに少しストレスを感じてしまいました。
初めて機械学習をやってみてるっていう人には、このコースのコードを写経すると何をやっているのかが一通りわかっていいのかも。
ただ、私のように一回数学的なアプローチを試みたうえで(今挫折中)このコースに来ると中身がわからないイライラが募ってきます。。。
ので、ちょっとここでこのコースは中断して違う勉強に移ろうと思います