kaggleにチャレンジした経緯
AI・機械学習・DeepLearningにあこがれてもうそろそろ1年経とうしているが、理論の勉強ばっかりやっててそろそろ飽きたので、どれほど実力が付いたのかkaggleをチャレンジしてみようと思いました
kaggleを最初にチャレンジするには、タイタニックの練習問題をすればよいとどこかのサイトを見たので、さっそくチャレンジ♪
https://www.kaggle.com/c/titanic
やってみてどうだったか?(結論)
理論ばっかりやても、全然歯が立ちませんでした。スコアも精度74%から上げることができず。。。
想定読者
とりあえず、pythonは何となく触れ、基本的なライブラリ(numpyとか)はgoogle先生に聞けばわかるぜ♪ってレベルを想定
個人的なメモのレベルを抜け出してはいないので、間違え・アドバイスがあればください!
タイタニックってなに?
あれは確か私が中学生のころはやった映画で、主人公のレオr)y
ではなく、与えらえた乗客情報からそいつが生き残るか死ぬかを予想しやがれ!
っていうお題です
とりあえず手を動かしてみようず
1. 学習データとテストデータをkaggleからGET
まずはタイタニックのページに上記のリンクからジャンプしてください。その後データタブをクリックすると、train.csvとtest.csvの2つが提供されていることがわかりますね?
もうちょっとスクロースすると、ダウンロードする画面がありますので、データをgetすべし。なお、gender~.csvはあとから説明しいます
| ファイル名 | 説明 |
|---|---|
| train.csv | このデータを使ってトレーニングしてみてね♪ |
| test.csv | このデータの情報をもとに結果を予測してね♪ |
2. データを読み込みましょう
トレーニングデータとテストデータを読み込みましょう。読み込みはpandasを利用しました。
import pandas as pd
dfS = pd.read_csv("train.csv")
dfT = pd.read_csv("test.csv")
3. データの中身を見てみましょう
本当はpythonを使ってやったほうがカッコいいのは知っていますが、今回は世界のExcelを活用させていただきました
train.csv
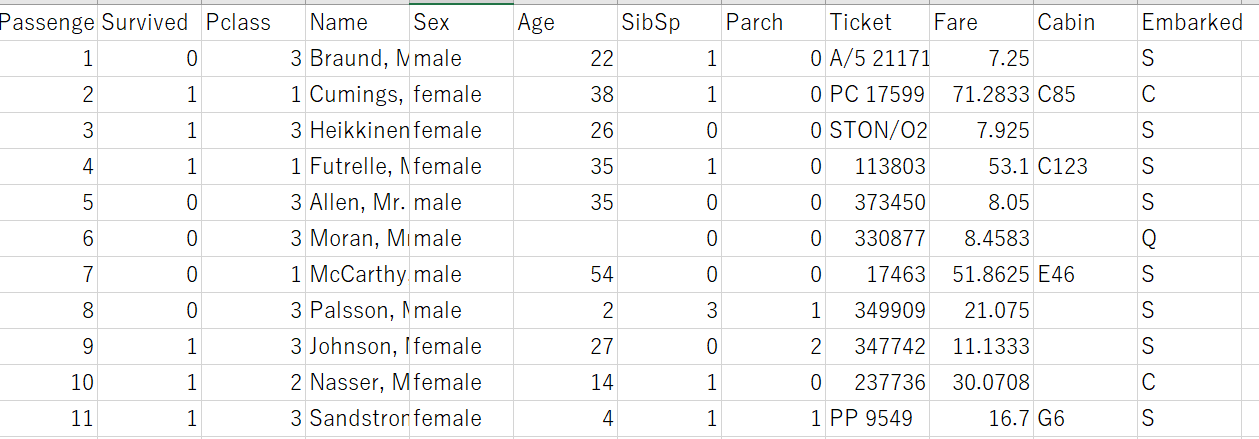
名前があって、年齢があって、直感的にわかりそうな感じですね
test.csv
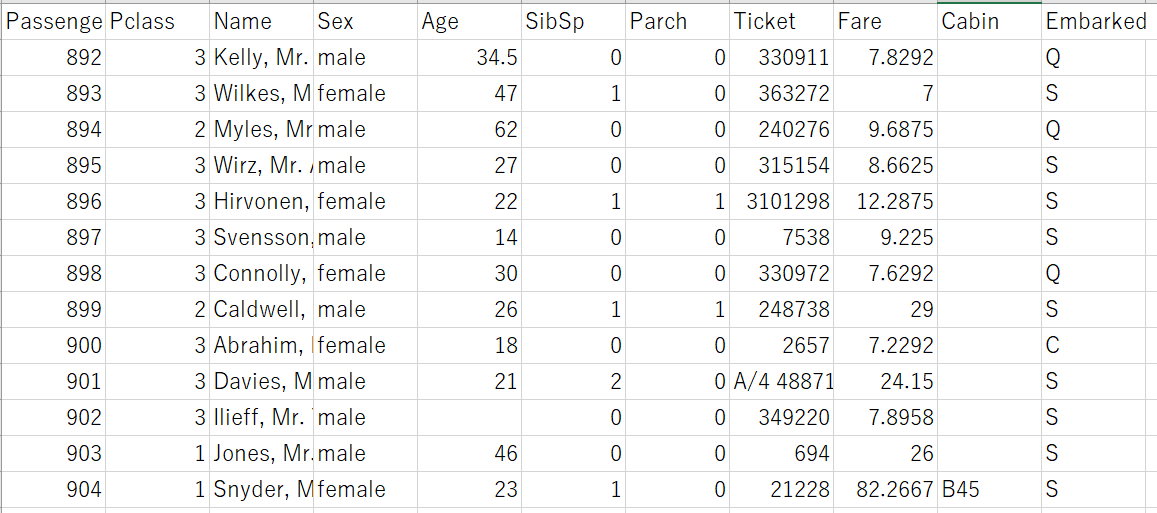
こっちも同じか?と思いきや、よーく見るとSurvived 列がtest.csvにはありませんね。そうです我々が予想しなければならないのはSurvived だ!ってことがここからわかりますね。
実際どんなデータが入っとるねん!っていうのはもちろんkaggleに英語 で書いてあるのでgoogle先生に聞きながら、ほんにゃくこんきゃくしてみてください。
4. データを眺めて仮説を立ててみよう
データを眺めて、なんなとなく生死には、年齢(Age)、男か女(Sex)、客室等級(Pclass)の3つが効いているのではないかと仮設を立てました。
ので、ここからはこの3つに対して前処理をしていきます。
5. 前処理
さて続いては前処理です。情報系の仕事をしている人は肌感覚でわかると思いますが、データがキレイな形で提供されることは滅多にありません。今回はトレーニング用ということもあり整った形で来ていますが、欠損値がないか、外れ値がないかは要確認です
年齢カラムの確認
まずは、nullの件数が何件あるか確認です
dfS['Age'].isnull().values.sum()
177
無視できるレベルかどうかはこれだけではわからないので、全体件数に占める割合を見てみましょう
dfS['Age'].isnull().values.sum() / len(dfS['Age']) * 100
19.865319865319865
19%。。。これは少し多い気が。。。何かしらの値で埋めたいですね
次に外れ値がないかチェックをします。ヒストグラムで見てみましょう
plt.hist(dfS['Age'].dropna(),bins=20)
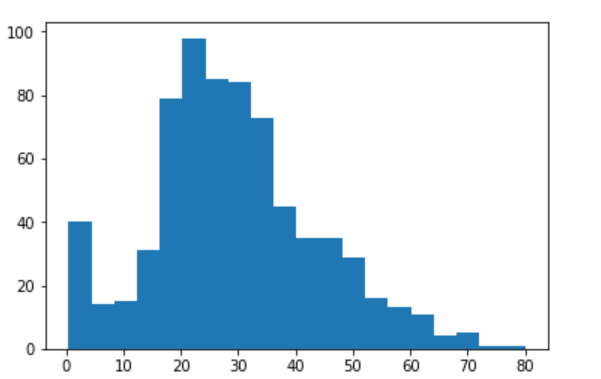
極端に外れているものはないことは確認できました。ので、今回はNULLに平均値を突っ込んでおきましょう
import numpy as np
mean = np.mean(dfS['Age'])
dfS['Age'] = dfS['Age'].fillna(mean)
男か女か(Sex)
CSVファイルを見たときに文字列で表現されていたので、扱いやすいように数字に置き換えましょう。今回は、female->2 、male->1としましょう。※置き換える前に他の文字列が入っていないかはチェックしてね♪
dfS['Sex'] = dfS['Sex'].str.replace('female','2')
dfS['Sex'] = dfS['Sex'].str.replace('male','1')
客室等級
kaggleの説明によると1~3の数字が入っているらしいので、本当かどうかはCSVを開いてチェックしてみてね。問題なかったので、前処理不要!
6. 学習させてみましょう
の前に、どのアルゴリズムを採用するか決めないといけません。ライブラリはsklearnを使ってやろうと思っていますので、事前にインスコお願いします。
本題に戻り、採用するアルゴリズムを決めないといけません。sklearnにフローチャートがあるので、それをもとに採用するアルゴリズムを決定します。
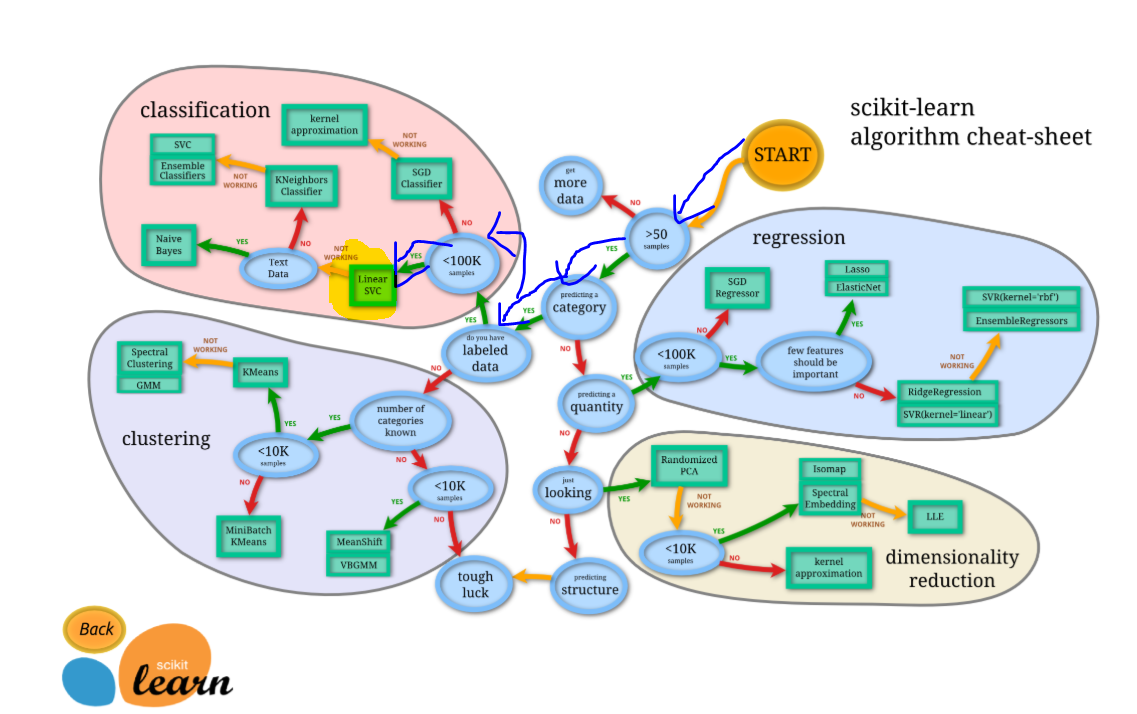
出所:http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
このチャートによると、SVCを進めてきています。のでおとなしくそれを使って学習しましょう
まずは、学習の事前準備として変数を抽出して、学習用と検証用にデータ分割します
# sklearnで使いそうなモノを読み込んでおきます
from sklearn.svm import SVC
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
# トレーニングデータを説明変数(X)と目的変数(y)に分割
X = pd.DataFrame({ 'Pclass':dfS['Pclass'],
'Sex':dfS['Sex'],
'Age':dfS['Age']})
y = pd.DataFrame({'Survived':dfS['Survived']})
# 学習用データと検証用データに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=None )
いよいよ学習!
ここまで長かった。。。。やっと学習させます。これぞ機械学習の醍醐味!いざ!
model = SVC(kernel='linear', random_state=None,C=0.1)
model.fit(X_train, y_train)
終わりです。ちょっと簡単すぎですね。。。
7. 検証をしてみましょう
さて学習はしてくれた見たいので、どの程度の精度が出ているのか確認をしてみましょう
model.score(X_test,y_test)
0.753731343283582
75%程度の精度で人の生き死にを判別できてるみたいです。最初だしこんなものかーということにして、次に進みます
8. testデータで予想をしてみてましょう
kaggle大魔神から与えられたtestデータで予想をしてみましょう。前処理はtrain.csvに施した内容をそのままトレースしちゃいます。
(よい子のみんなは、中身を確認してから前処理してね)
### テストデータの前処理
mean = np.mean(dfT['Age'])
dfT['Age'] = dfT['Age'].fillna(mean)
dfT['Sex'] = dfT['Sex'].str.replace('female','2')
dfT['Sex'] = dfT['Sex'].str.replace('male','1')
Xtest = pd.DataFrame({ 'Pclass':dfT['Pclass'],
'Sex':dfT['Sex'],
'Age':dfT['Age']})
予想!
model.predict(Xtest)
array([0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0,
1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1,
1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1,
1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1,
0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1,
1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1,
0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0,
1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1,
0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0,
0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0,
1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0,
0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0,
1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1,
0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0],
dtype=int64)
どうやらできているようです。
9. kaggleに提出しましょう
提出形式を確認すると、このファイルのように提出してね♪とありますので、そのファイルを確認してみましょう
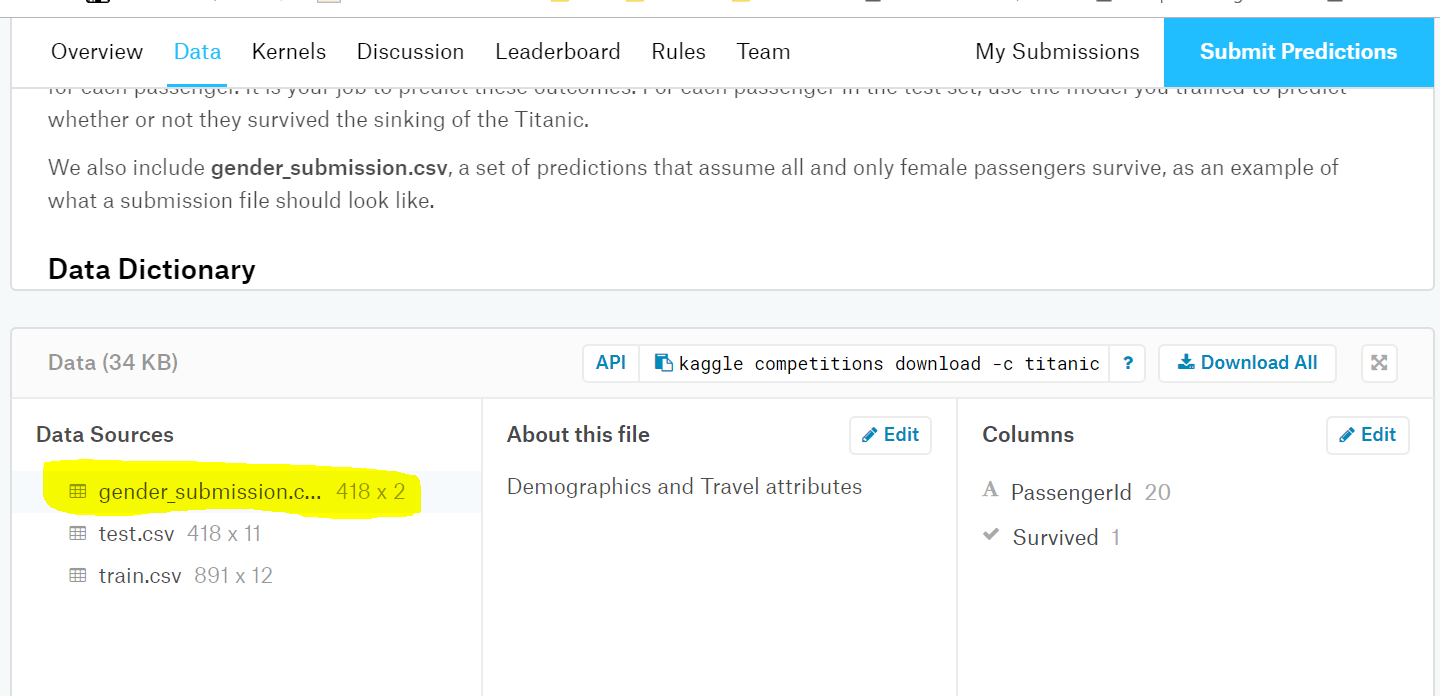
gender_submission.csv
というわけで、上記にあるような形に整形してCSVファイルを作成しましょう
# データの整形
submitPre = pd.DataFrame({
'PassengerId':dfT['PassengerId'],
'Survived':model.predict(Xtest)
})
# CSV出力
submitPre.to_csv("gender_submission.csv",index=False)
最後にkaggleへアップロードしてsubmitすれば終了です!

結果はいかに!?

0.76なので76%の精度で当たっているようです。順位的には7000番台ですねw 上には上がいらっしゃるんですね。。。。
おわりに
アルゴリズムの選定やパラーメータの最適化など、できることはたくさんあるでしょうが、今回はここまで。
kaggleに挑戦してみて思ったのは、理論がわかること=実装できることではない、ってこと。理論の勉強と実装の勉強は並行してやらないと現場では使い物にならないんだろうなぁ
実装(テクニック)を学ぶために、昔受講した以下講座を受けなおそうと思います。
じゃーの。
今回のソースコード全文
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
############################################################
# CSVフィルの読み込み
############################################################
dfS = pd.read_csv("train.csv")
dfT = pd.read_csv("test.csv")
############################################################
# 前処理
############################################################
# 年齢
## データ状態の確認
dfS['Age'].isnull().values.sum()
dfS['Age'].isnull().values.sum() / len(dfS['Age']) * 100
plt.hist(dfS['Age'].dropna(),bins=20)
## 平均値で穴埋め
mean = np.mean(dfS['Age'])
dfS['Age'] = dfS['Age'].fillna(mean)
# 性別
dfS['Sex'] = dfS['Sex'].str.replace('female','2')
dfS['Sex'] = dfS['Sex'].str.replace('male','1')
############################################################
# トレーニングデータを説明変数(X)と目的変数(y)に分割
############################################################
X = pd.DataFrame({ 'Pclass':dfS['Pclass'],
'Sex':dfS['Sex'],
'Age':dfS['Age']})
y = pd.DataFrame({'Survived':dfS['Survived']})
############################################################
# 学習用データと検証用データに分割
############################################################
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=None )
############################################################
# 学習&検証
############################################################
model = SVC(kernel='linear', random_state=None,C=0.1)
model.fit(X_train, y_train)
model.score(X_test,y_test)
############################################################
# テストデータの前処理
############################################################
mean = np.mean(dfT['Age'])
dfT['Age'] = dfT['Age'].fillna(mean)
dfT['Sex'] = dfT['Sex'].str.replace('female','2')
dfT['Sex'] = dfT['Sex'].str.replace('male','1')
Xtest = pd.DataFrame({ 'Pclass':dfT['Pclass'],
'Sex':dfT['Sex'],
'Age':dfT['Age']})
model.predict(Xtest)
############################################################
# データの整形&CSV化
############################################################
# 整形
submitPre = pd.DataFrame({
'PassengerId':dfT['PassengerId'],
'Survived':model.predict(Xtest)
})
# CSV出力
submitPre.to_csv("gender_submission.csv",index=False)