はじめに
ラスベガスで開催中のAWS最大級のカンファレンス AWS re:Invent 2025 に参加しています! 今回は、"[CMP338] Protect privacy in GenAI applications using AWS confidential computing" の参加レポートをお届けします。

生成AIの活用が進む中、「モデルの保護」や「プライバシー」は避けて通れない課題です。本記事では、セッションで学んだなぜその課題に機密コンピューティングの技術必要なのか?という背景と、実際に手を動かして構築した管理者すら入れないモデル環境の自分の理解を記します。
なぜ機密コンピューティングの技術が必要なのか?
生成AIにおける「信頼のジレンマ」
生成AI(LLM)のビジネス活用には、立場の異なる2つのプレイヤーが存在し、互いに完全には信頼しきれないという課題があります。

-
Model Consumer(利用者): 社外秘のプロンプトやRAG用のドキュメントを外部に渡したくない。「データが学習に使われないか?」「漏洩しないか?」が心配。
-
Model Owner(提供者):巨額の投資をして開発したLLMの「重み(Weights)」=知的財産を盗まれたくない。

この両者の要望を同時に満たすには、「モデルの中身は見せない(暗号化)」 ことと、「利用者のデータも外に出さない(隔離)」 ことを両立させる必要があります。
これを実現するために、誰から守る必要があるのか? 外部の攻撃者はもちろんですが、実はクラウド事業者や自社の管理者からもデータを隠す必要があります。
つまり本当に誰からもみられるようにすることができないようにする必要があるということですね。

3つのデータ保護
セキュリティの世界では、データの保護は3つの状態に分類されます。
-
Data at REST: 保存中のデータ(ディスク暗号化などで保護)
-
Data in TRANSIT: 移動中のデータ(TLS通信などで保護)
-
Data in USE: 利用中(メモリ上)のデータ

これまでの技術では、データを処理する瞬間(CPUやメモリで計算する時)には、どうしても復号して平文にする必要がありました。 今回のテーマである Confidential Computing(機密コンピューティング) は、この最後の砦である Data in USEを保護するための技術です。
Data in Use 保護のための4つの要件
Data in Use を守るための「必須要件」
では、「使用中のデータ」を守るためには、具体的にどのようなシステムが必要なのでしょうか? セッションでは、機密コンピューティング環境に求められる 4つの要件 が提示されました。
No unauthorized access(不正アクセスの完全排除)
外部からの攻撃はもちろん、クラウド事業者や自社の管理者であっても、処理中の生データにはアクセスできないこと。
Trusted code execution(信頼されたコード実行)
「今動いているプログラムは、バックドアが仕込まれていない正規のものか?」を証明できること。これが今回のワークショップで体験した Attestation(構成証明) の核心です。
Reduce attack surface(攻撃対象領域の縮小)
OSの機能を最小限にし、SSHポートすら閉じることで、攻撃者が入り込む隙間(Surface)を物理的に極小化すること。これが ZOA (Zero Operator Access) の思想です。
Flexibility with resources(リソースの柔軟性)
特別なハードウェア専用ではなく、通常のEC2(CPUやGPUインスタンス)上で柔軟に構成できること。
そして、"All this while keeping it easy"という言葉通り、AWS NitroTPM や KMS といった既存のマネージドサービスを組み合わせることで、これほど高度なセキュリティ要件を実装できる点にはさすがだなの一言でした。

キーワードの整理
地味に難しい・新しいキーワードが多いので、ここで一旦整理します。
機密コンピューティング(Confidential Computing)
今回のワークショップのメインテーマである Confidential Computing(機密コンピューティング) とは、一言で言えば 「データを使用中(処理中)の状態でも暗号化・保護する技術」 のことです。
AWS NitroTPM (Trusted Platform Module)
EC2インスタンスに搭載されたセキュリティチップ(TPM 2.0)。システムが正しく起動しているかをハードウェアレベルで測定し、暗号機能を提供します。
PCR (Platform Configuration Registers)
システムの「指紋」のようなものです。BIOS、ブートローダー、カーネルの状態をハッシュ値としてTPM内に記録します。
構成が1ビットでも変わるとハッシュ値が変化するため、「改ざん検知」の決定的な証拠となります。
Attestation (構成証明)
「私は改ざんされていない正しいサーバーです」ということを、TPMのデジタル署名付きで証明するプロセスです。
これにより、Trusted code execution(信頼されたコード実行) を保証します。
Zero Operator Access (ZOA)
SSHポート(22番)すら開いておらず、管理者であってもログインできない環境のことです。
ログ閲覧やメモリダンプも不可能なため、No unauthorized access(不正アクセスの排除) と Reduce attack surface(攻撃対象領域の縮小) を物理的に実現する究極の構成です。
実際にWorkshopを用いて試してみる
ここからの内容は『[CMP338] Protect privacy in GenAI applications using AWS Confidential computing』の内容を触っていきます。
(もう公開されているかはわかりませんが、本Workshopは公開されるはずなので気になる方は調べてみてください。)
構築するアーキテクチャ
この課題を解決するためにワークショップで実装したのが、以下のアーキテクチャです。
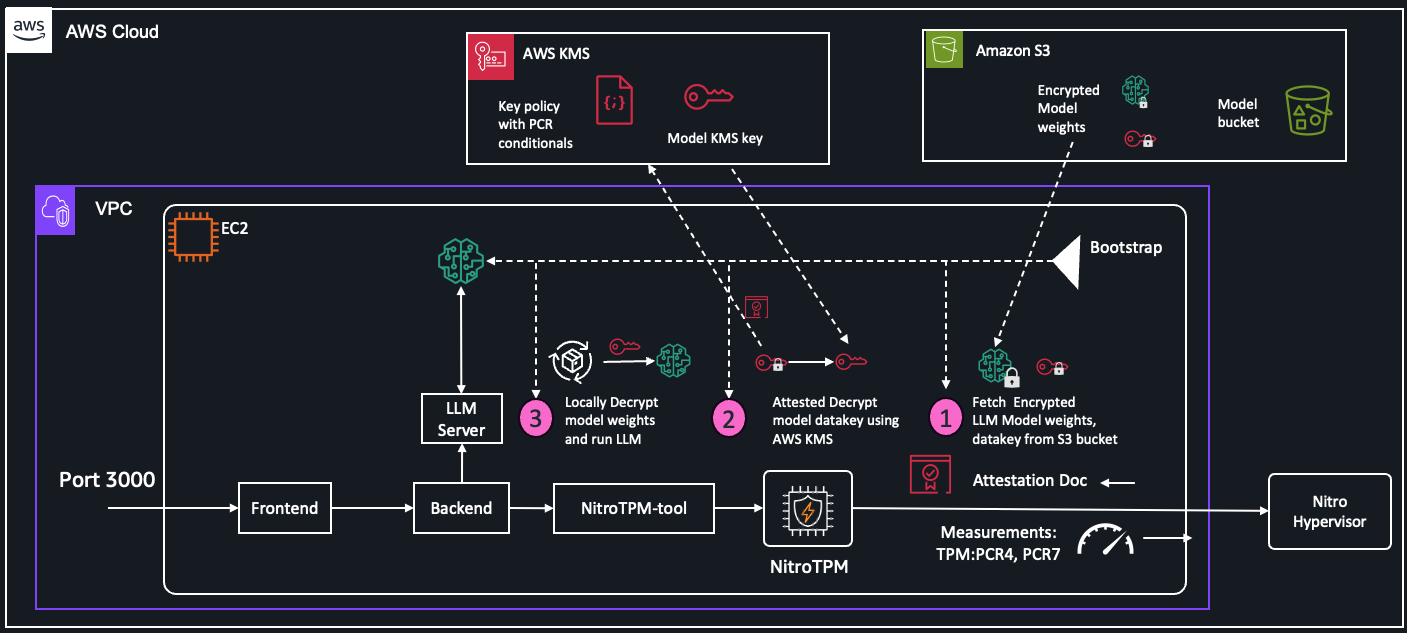
非常に複雑に見えますが、核となる技術は以下の3つです。
① Envelope Encryption(エンベロープ暗号化)
巨大なLLMモデルを直接暗号化するのではなく、データキーを使って暗号化し、そのキーをAWS KMSで守る構成です。
② Cryptographic Sealing(暗号学的封印)
ここが今回のハイライトです。 KMSのキーポリシーに、「特定のハードウェア構成(PCR値)でのみ復号を許可する」 という条件を追加します。
これにより、「たとえ鍵(IAM権限)を持っていても、正規のOSイメージで起動した正規のインスタンスでなければ、絶対にモデルを復号できない」 という状態を作り出します。
③ Attestation(構成証明)
インスタンス起動時に、搭載されたセキュリティチップ(AWS NitroTPM)が「私は改ざんされていない正しいサーバーです」という署名付き証明書を発行します。これをKMSが検証することで、初めて暗号化キーが渡されます。
サンプルアプリケーションの構成と脅威モデル
今回のワークショップで使用したサンプルアプリケーション(Sample LLM Application pattern-1)は、単純なチャットボットのように見えて、背後で 2つの重大な脅威を解決するように設計されていました。
守るべき2つの境界線
LLMを利用したマルチパーティ(複数企業間)のコラボレーションでは、以下の脅威が存在します。
サプライチェーン攻撃 (Supply Chain Threat):
Model Ownerの視点: 「Model Consumer(利用者)にモデルを渡すが、中身(知的財産)は盗まれたくない」
対策: モデルを暗号化し、正規の環境でしか復号できないように封印する。
機密情報の漏洩 (Sensitive Info Disclosure):
Model Consumerの視点: 「プロンプト(機密データ)を自社のAWSアカウントの境界線(Boundary)から出したくない」
対策: 外部通信を遮断したZOA環境でモデルを動かし、Owner側へのデータ流出を防ぐ。
アプリケーションの全体像
この課題を解決するため、サンプルアプリは以下のような構成で動作しています。
-
Frontend (React): ユーザーインターフェース。
-
Backend (Python): KMSやTPMと連携し、構成証明(Attestation)を行う中核。
-
Ollama: LLM(GGUF形式)をホストする推論エンジン。
-
AWS NitroTPM: すべての信頼の基点(Root of Trust)となるハードウェアチップ。
これらが連携し、「Model Consumerは中身を見られないが利用できる」「Model Ownerはデータを見られないがモデルを提供できる」 という、相互不信(Zero Trust)の中での安全なコラボレーションを実現しています。
Model Owner としての保護
まず最初に行ったのは、Model Owner(モデル提供者) の立場になり、守るべき資産である「LLMモデルの重みデータ」を暗号化する工程です。
Step 1: エンベロープ暗号化の実装
LLMのモデルファイルは数GB〜数十GBと非常に巨大です。これを AWS KMS(Key Management Service)で直接暗号化しようとすると、サイズ制限やパフォーマンスの壁にぶつかります。
そこで「エンベロープ暗号化(Envelope Encryption)」 という手法を使います。
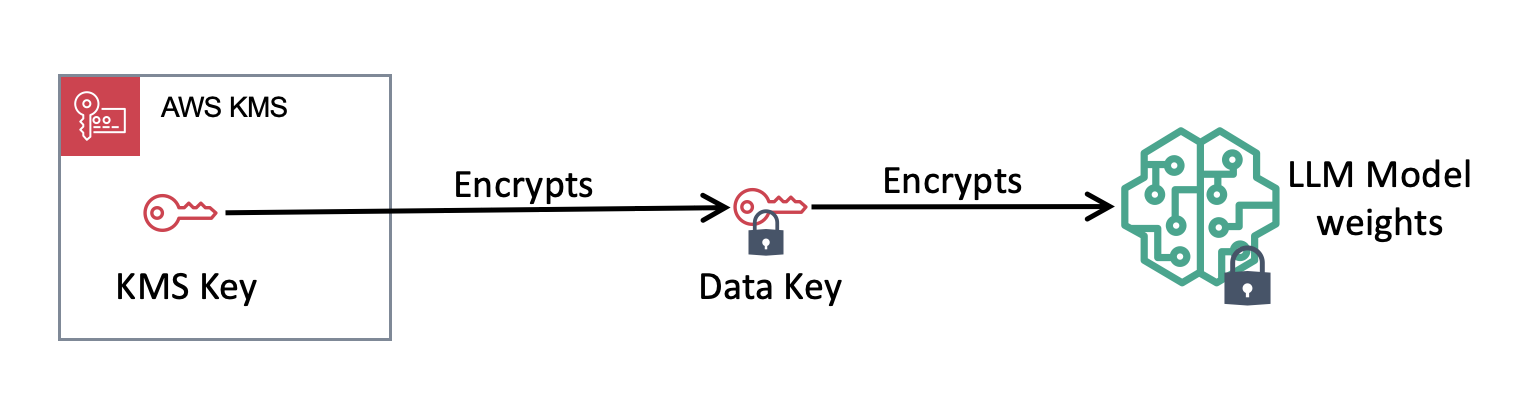
仕組みは以下の通りです。
-
データキーの生成: KMSを使って、その場限りの共通鍵(Data Key)を生成します。
-
モデルの暗号化: そのデータキーを使って、巨大なモデルファイルをローカル(メモリ上)で高速に暗号化します。
-
キーの暗号化: 使用したデータキー自体を、KMSのマスターキーで暗号化します。
-
アップロード: 「暗号化されたモデル」と「暗号化されたデータキー」をセットで S3 に保存します。
実際のアプリ操作
サンプルアプリの「Model Manager」タブから、KMS Key ID と S3 バケットを指定して "PROCESS MODEL" ボタンを押しました。
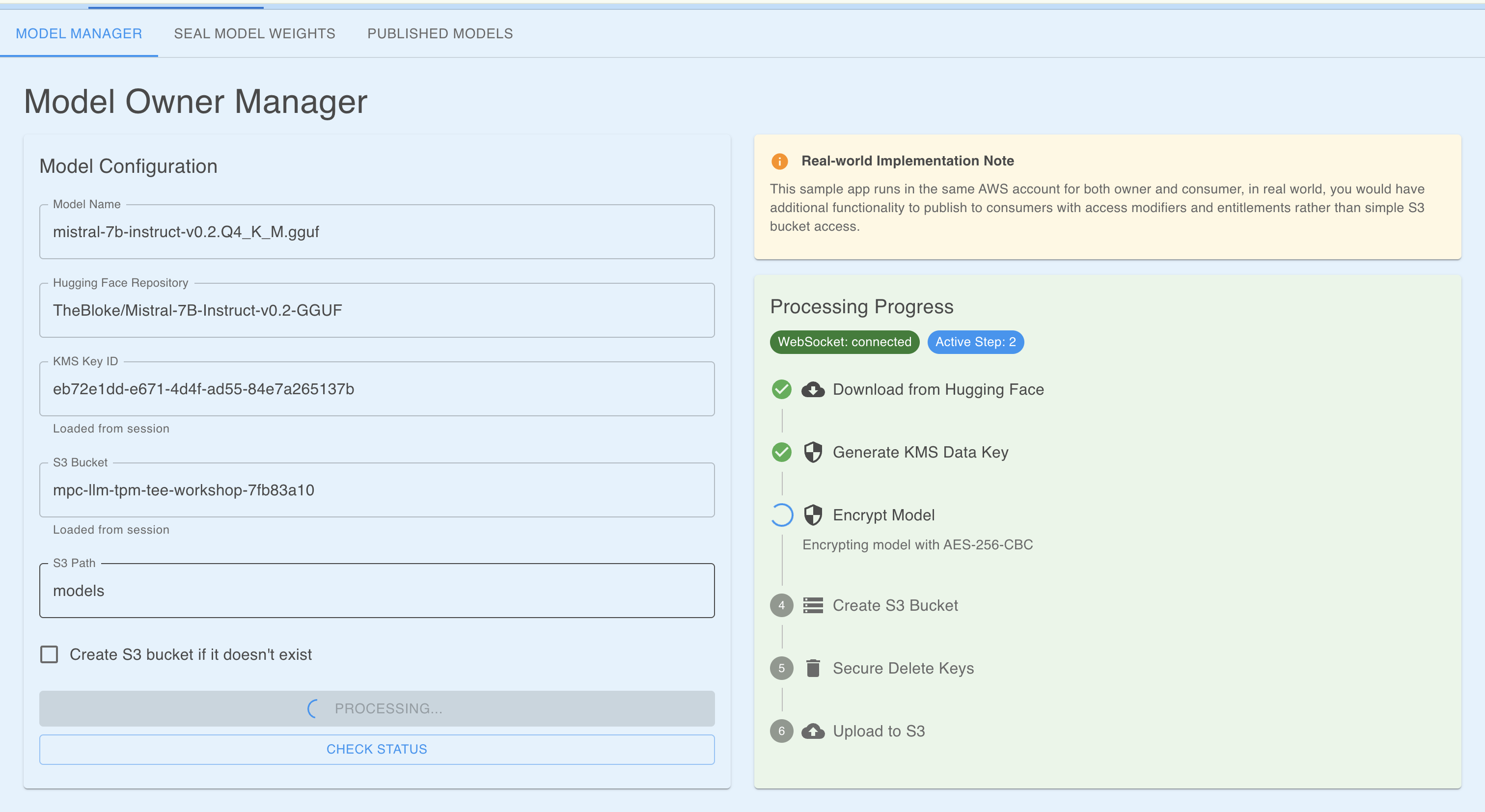
裏側で走っている Python コード(model_owner_manager.py)を確認すると、セキュリティへの細かい配慮が見て取れました。
-
AES-256-GCM: 暗号化モードには、機密性だけでなく「改ざん検知(整合性)」もできる GCM モードを使用。
-
メモリ効率: 巨大なファイルを一度に読み込まず、8KB チャンクごとに分割して暗号化。
-
安全な削除: 使い終わった平文のデータキーは、単に削除するだけでなく、ランダムデータで上書き(shred)してから削除するという徹底ぶりでした。
実行結果
処理が完了すると、S3 バケット上に暗号化されたファイル(.enc)と、暗号化されたキー(.datakey.enc)が生成されました。
これで、「モデルの中身は見えない(Data at Rest の保護)」 状態までは完了しました。 しかし、このままでは「KMSのアクセス権(IAMロール)」を持つ人なら誰でも復号できてしまいます。
そこで次のステップとして、「特定のPCでしか復号できないようにする(封印)」 作業へと進みます。
KMSポリシーによる「封印 (Sealing)」
エンベロープ暗号化によってモデルは暗号化されましたが、まだ「IAM権限があれば誰でも復号できる」状態です。これを「特定のハードウェア環境でしか復号できない」ように制限をかけます。これが Sealing(封印)というようです。
KMSキーポリシーの変更
Model Ownerとして、KMSのキーポリシーに以下の条件(Condition)を追加しました。
PCR 4: ブートローダーとカーネルの測定値(OSが正規のものか?)
PCR 7: セキュアブートの状態(署名が正しいか?)
PCR 12: カーネルコマンドライン引数(デバッグモードなどで起動していないか?)

これにより、AWS上での設定(IAM)と、物理的なハードウェアの状態(PCR)が合致しない限り、kms:Decrypt アクションが拒否されるようになります。まさに 「デジタルな封印」 です。s
それぞれのPCRについてのまとめ

証明に基づく「開封とロード (Unseal & Load)」
次は Model Consumer(利用者)側の視点です。 封印されたモデルをロードしようとした時、裏側では非常に高度な認証プロセス(Attestation Flow)が自動的に実行されます。
ワークショップのコードで実装されていた 「Attestation-Based Decryption」 の流れは以下の通りです。
技術的な裏側のフロー
-
一時的な鍵ペアの生成:アプリがその場限りのRSA鍵ペア(公開鍵・秘密鍵)を生成します。
-
構成証明書 (Attestation Document) の取得:アプリが nitro-tpm-attest コマンドを実行し、TPMから「構成証明書」を取得します。(この時、最初に作った公開鍵 を証明書の中に埋め込みます)
-
KMSへの復号リクエスト:アプリは「暗号化されたデータキー」と「構成証明書」をセットにしてKMSに送ります。通常のIAM認証に加え、Attestationによる検証が行われます。
-
KMSによる検証と再暗号化:KMSは証明書の署名を検証し、PCR 4, 7, 12 の値がポリシーと一致するか を確認します。一致した場合、KMSはデータキーを復号しますが、そのまま平文では返しません。証明書に含まれていた公開鍵で再暗号化(CMS Envelope) して返します。
-
ローカルでの復号とロード:アプリは自分の秘密鍵を使って、KMSから返ってきたデータキーを取り出します。そのデータキーを使ってモデル本体(.gguf)を復号し、Ollamaサーバーにロードします。
-
PCR 15 による監査ログ (Audit Trail):モデルのロード完了後、アプリは tpm2_pcrextend コマンドを実行し、ロードしたモデルのハッシュ値を PCR 15 に記録 していました。これにより、「正規のOSで起動した」だけでなく、「正規のモデルを読み込んだ」ことまでTPMに記録され、後から改ざん不可能な監査ログとして機能します。
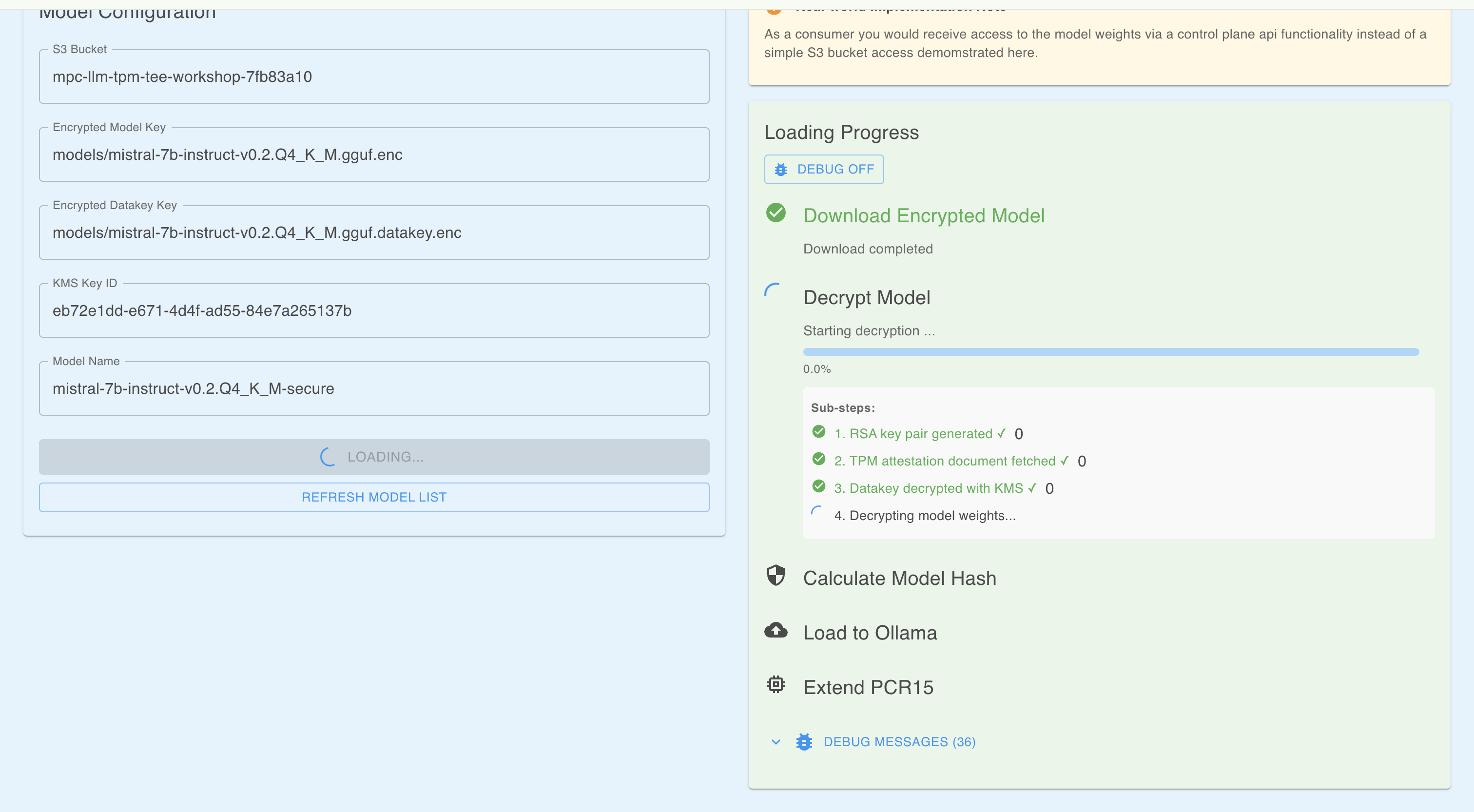
実際に動かす
これら全ての検証をパスして初めて、チャット画面(Frontend)が利用可能になります。
(スクショ撮り忘れた)
試しに「空はなぜ青いの?」と質問を投げると、Ollama上のMistralモデルからスムーズに回答が返ってきました。 このレスポンスは、「AWSの管理者ですらアクセスできないメモリ空間」 で生成されたものです。入力したプロンプトが外部に漏れる心配がありませんね!
ZOA (Zero Operator Access)の構築
暗号化と認証の仕組み(ソフト面)は整いました。最後に、それを稼働させるハード面を構築します。
今回の要件は「管理者であっても生データを見られないこと」です。つまり、SSHでログインできてはいけません。 これを実現するために、ZOA (Zero Operator Access) と呼ばれる構成が使われます。
1. Kiwi-ng によるビルド
通常のEC2インスタンス(Amazon Linuxなど)をそのまま使うのではなく、OSイメージ作成ツール Kiwi-ng を使って、独自のAMI(Amazon Machine Image)をビルドしました。
ここでは、単にアプリをインストールするだけでなく、以下の処理が行われています。
-
最小構成化: 不要なパッケージやサービスを徹底的に削除し、攻撃対象領域(Attack Surface)を減らす。
-
Read-Only化: ルートファイルシステムを読み取り専用にし、マルウェアの永続化や改ざんを防ぐ。
-
PCR値の確定: このビルドプロセスによって、OSのカーネルやブートローダーの構成が固定されます。つまり、S封印に使われるPCRは、このビルドの瞬間に決まります。
(ビルドには約25分かかりました。その間にセッションの時間が終わってしまいました、、なのでここからは実際に起動できたらの話すになります)
サーバーの起動
ビルドが完了したAMIを使って、いよいよ本番インスタンスを起動しました。 このインスタンスのセキュリティグループ設定が以下のようになります。
-
インバウンドルール: TCP 3000 (Webアプリ) のみ許可
-
SSH (22): 許可なし
-
キーペア: 設定なし
3. 動作確認
起動したインスタンスに対して、ブラウザからアクセスします。 Webアプリは正常に表示され、裏側ではTPMによるAttestationが成功してモデルがロードされるようになります。
ターミナルから SSH コマンドを打っても繋がりません。 「動いているのに、中に入れない」。 これこそが、内部犯行すら物理的に不可能にする ZOA 環境です。
もしアプリにバグがあったら?
ログはどう見る? → 「中に入って直す」という発想を捨て、修正した新しいイメージをビルドし直す(Immutable Infrastructure) という運用思想への転換も必要みたいで運用の効率性とセキュリティのトレードオフが発生するなと思いました。
まとめ
今回のワークショップを通じて、「モデルの中身も見せない、利用者のデータも見せない」という、相互不信(Zero Trust)を前提としたコラボレーションが、技術の力で実現できることを体験しました。
最後に、このセッションを通して得られた重要な学びを振り返ります。
1. 「人を信頼する」から「技術を信頼する」へ
これまでのセキュリティは「管理者を信頼する(IAM権限を適切に絞る)」ことが前提でした。しかし、今回構築した環境では、「管理権限を持っていても、物理的なハードウェア構成(PCR値)が合わなければデータに触れない」 という世界観でした。 人の善意や運用ルールではなく、数学的・物理的な証明(Attestation)によって信頼を担保する Confidential Computing の真髄を肌で感じることができました。
2. 運用思想の転換 (Immutable Infrastructure)
ZOA環境の構築で感じたのは、「SSHで入ってログを見る」「手動でパッチを当てる」といった従来の運用が通用しないことです。 バグがあればOSイメージごと作り直すというImmutable Infrastructureの徹底が求められます。セキュリティ強度は最強ですが、その分、高度なCI/CDパイプラインや自動化が必須となり、開発者には高いスキルが要求されると感じました。
3. 生成AI活用のラストワンマイル
金融、医療、公共、人事といった極めて機密性の高いデータを扱う業界で独自のモデルを構築していくことは、セキュリティへの懸念が生成AI導入と普及、そしてサービスの色を出していくことへの壁になっています。 しかし、今回のように AWS NitroTPM と KMS というマネージドサービスを組み合わせることで、これほど高度な保護機能が(以前よりは)手軽に実装できるようになっていることを感じました。
4. AIに限らず言える話へ
今回のワークショップは「GenAI(生成AI)」という文脈でしたが、この「ZOA (Zero Operator Access) + Attestation(構成証明)」というアーキテクチャは、AIモデルの保護以外にも広く応用できる汎用的なセキュリティパターンだと強く感じました。(あまりこの辺りは詳しくないので話の流れ的には逆かもしれませんが、、)
おわり
本記事はAIとともに書きました!