この記事は一休.com Advent Calendar 2025 10日目の記事です。
はじめに
一休の江口です。主に決済などのマイクロサービス開発を行っています。
今回はBigQueryとスプレッドシートを利用したGoogle Cloudコストの差分モニタリング方法について紹介します。
背景
私が所属するチームでは、複数の一休サービスで利用する共通マイクロサービスをいくつか開発しています。
運用していく中で、以下のような理由でコストが増加するリスクがあります。
- 設定変更の戻し忘れ
- 不要なリソース削除漏れ
- 想定外のリクエスト増加
Cloud Billingコンソールでもある程度の確認はできますが、マイクロサービス単位で細かく把握するには不向きでした。
そこで月に一度、過去3か月分のコスト推移をモニタリングして異常を早期発見できる仕組みを構築しました。
前提条件
この記事では、Cloud Billing データを BigQuery にエクスポートする設定が既にされている前提で進めます。
設定方法については公式ドキュメントをご参照ください。
また、本記事では同一プロジェクト内で複数マイクロサービスを運用しているケースを想定しています。マイクロサービスを識別するためのラベルを事前に設定しておく必要があります。
コスト集計クエリ
クエリの考え方
以下のような粒度でコストを集計しています:
- マイクロサービス単位: ラベルやリソース名で判別
- 環境単位: プロジェクトID(prd/stg/dev)で判別
- Google Cloudサービス単位: Cloud Run、Cloud SQL、GCSなど
クエリ例
以下のようなイメージで同一プロジェクトにいくつか存在するマイクロサービスごと、環境ごと、利用しているGoogle Cloudのサービスごとのコストを集計しています。
- CTEで対象データを絞り込み: パーティションフィルタで過去3か月分のみ取得
- マイクロサービスごとにSELECT: ラベルやリソース名で各サービスを判別
- UNION ALLで結合: 複数マイクロサービスの結果を1つのテーブルに
各マイクロサービスの判別はEXISTS(SELECT 1 FROM UNNEST(labels) WHERE key = 'cloudrun_app_name' AND value LIKE '%service-a%')のように予め設定したラベルによって可能です。
GCSのバケット名であればglobal_name LIKE '%service-a%'のような指定もできます。
クエリの具体例
DECLARE TODAY DATE DEFAULT CURRENT_DATE();
WITH filtered_costs AS (
SELECT
DATE_TRUNC(DATE(usage_start_time), MONTH) AS year_month,
project.id AS project_id,
service.description AS service,
resource.global_name AS global_name,
labels,
cost
FROM `your-project.billing_dataset.gcp_billing_export_resource_v1_XXXXXX_XXXXXX_XXXXXX`
WHERE DATE(_PARTITIONTIME) >= DATE_SUB(DATE_TRUNC(TODAY, MONTH), INTERVAL 3 MONTH)
AND DATE(_PARTITIONTIME) < DATE_TRUNC(TODAY, MONTH) + INTERVAL 3 DAY
AND DATE(usage_start_time) >= DATE_SUB(DATE_TRUNC(TODAY, MONTH), INTERVAL 3 MONTH)
AND DATE(usage_start_time) < DATE_TRUNC(TODAY, MONTH)
AND project.id IN ('your-project-prd', 'your-project-stg', 'your-project-dev')
)
-- マイクロサービスA
SELECT
FORMAT_DATE('%Y/%m', year_month) AS `年月`,
'service-a' AS `マイクロサービス`,
CASE project_id
WHEN 'your-project-prd' THEN 'prd'
WHEN 'your-project-stg' THEN 'stg'
WHEN 'your-project-dev' THEN 'dev'
END AS `環境`,
SUM(CASE WHEN service = 'Cloud Run' THEN cost ELSE 0 END) AS `Cloud Run`,
SUM(CASE WHEN service = 'Cloud SQL' THEN cost ELSE 0 END) AS `Cloud SQL`,
SUM(CASE WHEN service = 'Cloud Storage' THEN cost ELSE 0 END) AS `Cloud Storage`
FROM filtered_costs
WHERE
(service = 'Cloud Run'
AND EXISTS(SELECT 1 FROM UNNEST(labels) WHERE key = 'cloudrun_app_name' AND value LIKE '%service-a%'))
OR
(service = 'Cloud SQL'
AND EXISTS(SELECT 1 FROM UNNEST(labels) WHERE key = 'service' AND value = 'service-a'))
OR
(service = 'Cloud Storage'
AND global_name LIKE '%service-a%')
GROUP BY `年月`, `マイクロサービス`, `環境`
UNION ALL
-- マイクロサービスB
SELECT
FORMAT_DATE('%Y/%m', year_month) AS `年月`,
'service-b' AS `マイクロサービス`,
CASE project_id
WHEN 'your-project-prd' THEN 'prd'
WHEN 'your-project-stg' THEN 'stg'
WHEN 'your-project-dev' THEN 'dev'
END AS `環境`,
SUM(CASE WHEN service = 'Cloud Run' THEN cost ELSE 0 END) AS `Cloud Run`,
SUM(CASE WHEN service = 'Cloud SQL' THEN cost ELSE 0 END) AS `Cloud SQL`,
SUM(CASE WHEN service = 'Cloud Storage' THEN cost ELSE 0 END) AS `Cloud Storage`
FROM filtered_costs
WHERE
(service = 'Cloud Run'
AND EXISTS(SELECT 1 FROM UNNEST(labels) WHERE key = 'cloudrun_app_name' AND value LIKE '%service-b%'))
OR
(service = 'Cloud SQL'
AND EXISTS(SELECT 1 FROM UNNEST(labels) WHERE key = 'service' AND value = 'service-b'))
OR
(service = 'Cloud Storage'
AND global_name LIKE '%service-b%')
GROUP BY `年月`, `マイクロサービス`, `環境`
ORDER BY `年月` ASC, `マイクロサービス`, `環境`
※実際に集計される場合はご利用のプロジェクトIDやラベルの値に置き換えてください
※ご利用の環境によってテーブル名が異なる場合があります
パーティションフィルターでコスト削減
基本的にBigQueryはスキャンしたデータ量に応じた課金のため、パーティションフィルタの利用が重要です。
-- パーティション列でフィルタ(スキャン範囲を物理的に制限)
DATE(_PARTITIONTIME) >= DATE_SUB(DATE_TRUNC(TODAY, MONTH), INTERVAL 3 MONTH)
AND DATE(_PARTITIONTIME) < DATE_TRUNC(TODAY, MONTH) + INTERVAL 3 DAY
-- 実際のデータでもフィルタ(正確な期間に絞り込み)
DATE(usage_start_time) >= DATE_SUB(DATE_TRUNC(TODAY, MONTH), INTERVAL 3 MONTH)
AND DATE(usage_start_time) < DATE_TRUNC(TODAY, MONTH)
_PARTITIONTIMEだけでなくusage_start_timeでもフィルタしているのは、
請求データ遅延によってパーティションと実際の利用日のズレを考慮するためです。
※上記例では_PARTITIONTIMEを3日分多く取っています
スプレッドシート連携
コネクテッドシートの活用
BigQueryの集計結果から「コネクテッドシート」でスプレッドシートにデータ連携ができます。
連携したデータ(接続シート)を元に直接グラフを作ることもできますが、
その場合は各グラフから再集計が実行でき、意図せずBigQueryのコストがかさんでしまう恐れがあるため、
以下の2段階アプローチにしています。
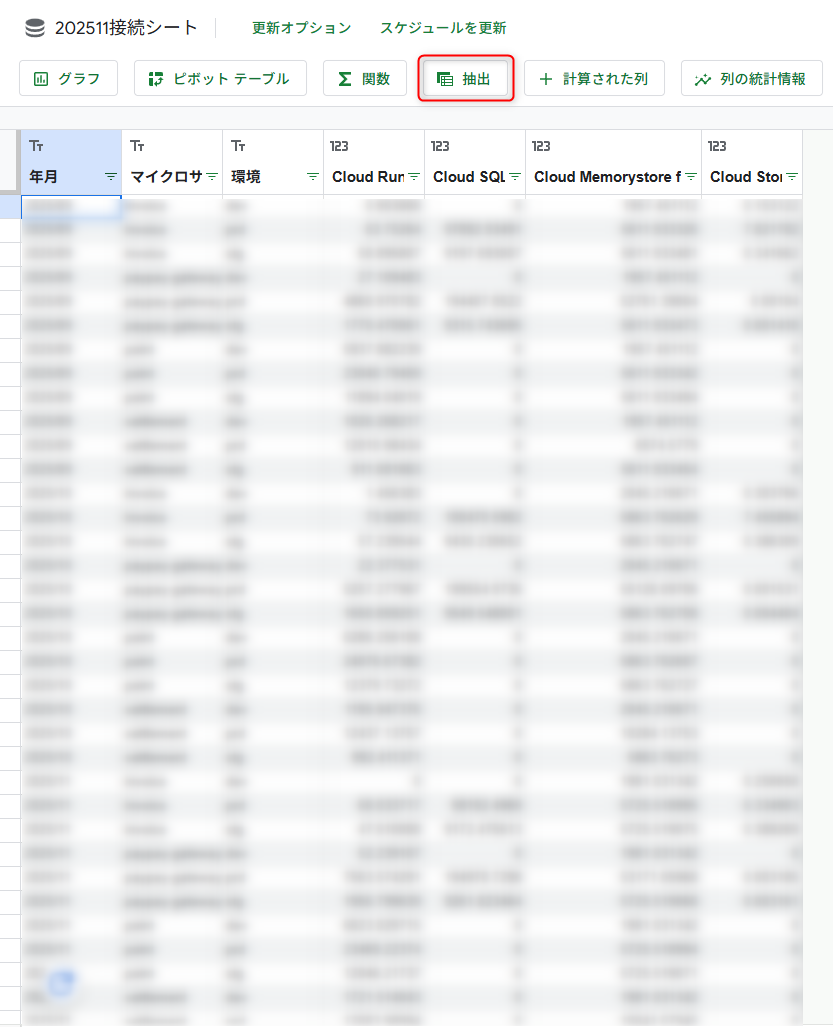
- コネクテッドシート(BigQueryへの接続)
- 「抽出」から別シートへデータをコピー ← このシートからグラフ作成
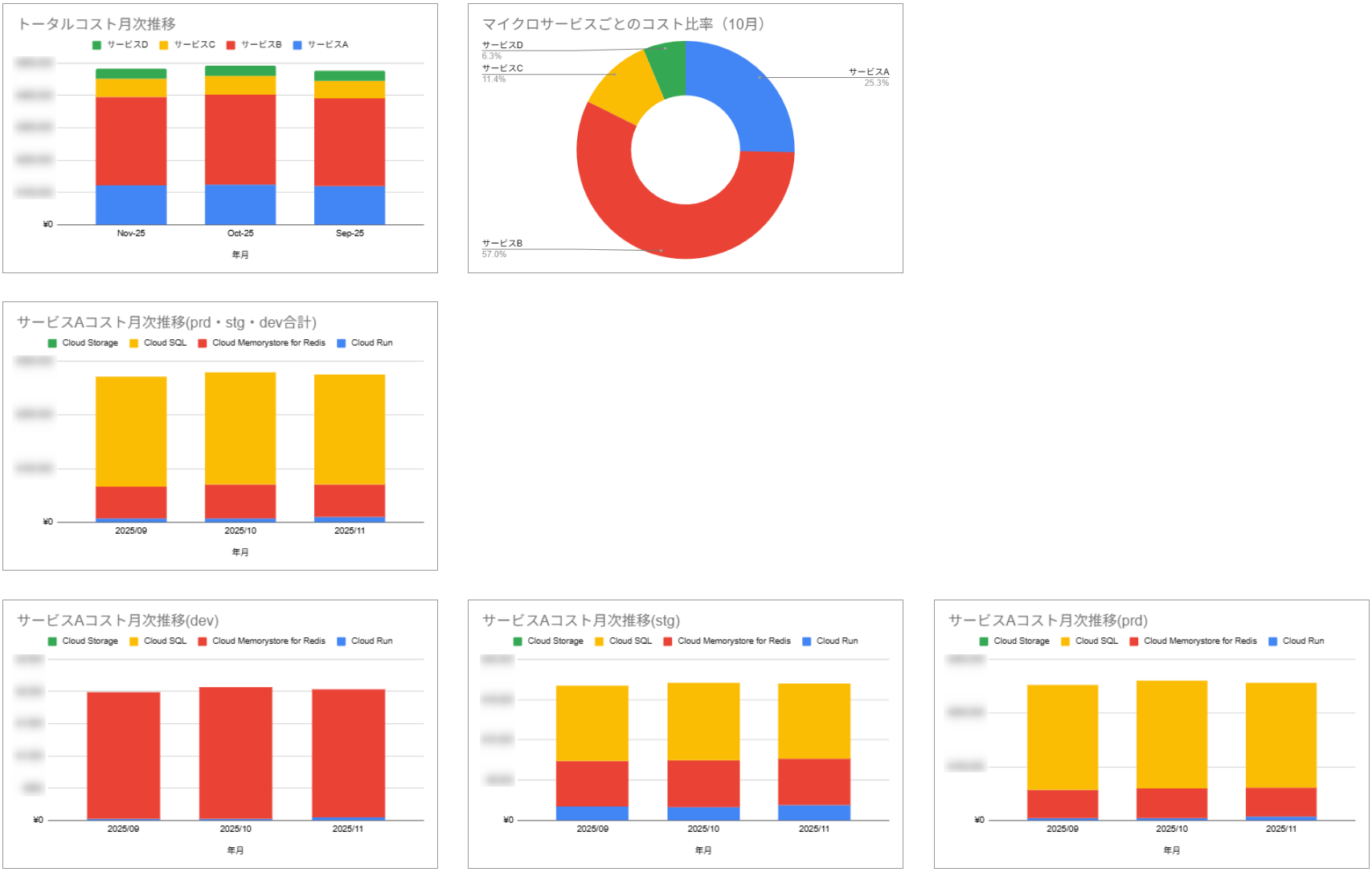
グラフの作成例
抽出したデータを元に、以下のようなグラフを作成し、コスト分析に活用しています。
メンテナンス
更新方法
抽出したシートの「更新」ボタンを押すだけで最新のコストが確認できます。

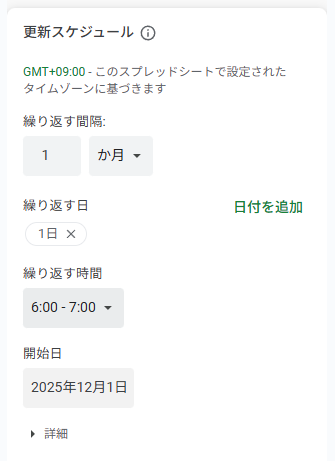
更新スケジュールの設定
更新スケジュールの設定も可能です。
おわりに
BigQueryとスプレッドシートを組み合わせることで、モニタリング自体にほとんどコストをかけずに、きめ細かいコスト分析が実現できました。
まだ大きなコスト異常の発見には至っていませんが、コストが可視化されたことでチームメンバーがコストを意識しやすくなったのは良い変化だと感じています。
同じような課題を抱えている方の参考になれば幸いです。
ここまで読んでいただきありがとうございました。