はじめに
Red Hat OpenShift AIというソリューションの主要な機能を見るべく、サンプルデモを実施してみましたので、この記事はデモ手順をなぞる形でご紹介します。サンプルデモはRed Hat社の提供するクレジットカード決済に関する不正検知デモを参考にしています。大筋の流れはこちら通りです。
IBM Cloudでは、Red Hat OpenShift AIをRed Hat OpenShift on IBM Cloud(通称ROKS)のクラスターのアドオンとして使うことができます。
(ご参考:Red Hat OpenShift AI)
準備したリソース
- Red Hat OpenShift クラスター :
"RedHatOpenShiftAI_wayday"- クラスターバージョン:OpenShift 4.17
- ワーカーノード:
gx3.24x120.l40s(NVIDIA L40sを搭載)2台 - アドオン:OpenShift AI (Add-on) バージョン416
- IBM Cloud Object Storage (S3互換のストレージバケット)
- インスタンス名
"Cloud Object Storage-kensyo" - Bucket:
"fraud-detection-kensyo" - Storage Class: Smart Tier
- Resiliency: Regional
- Location: jp-tok
- インスタンス名
手順
- ROKSクラスターの準備
- OpenShift AIのコンソール操作
- Connectionの作成
- パイプラインの実現
- ワークベンチの作成
- 不正検知モデルのトレーニング(notebook
"1_experiment_train.ipynb") - 不正検知モデルの保存(notebook
"2_save_model.ipynb") - モデルサーバーへのデプロイ
- パイプラインの実装
1. ROKSクラスターの準備
OpenShift AIアドオンを使用するには、クラスタが以下の要件を満たしている必要があります。
- クラスタのバージョンは 4.16 以降でなければなりません。
- クラスタには少なくとも2つのワーカーノードが必要です。
- 各ワーカーノードは 8vCPU、 32GBメモリとGPUを持たなければならない。
- ワーカーノードはRed Hat Enterprise Linux CoreOS (RHCOS)オペレーティングシステムを使用する必要があります。
(ご参考:IBM Cloud Docs 最小要件)
今回使用したクラスタはバージョンがOpenShift 4.17で、NVIDIA L40sを搭載したワーカーノード(gx3.24x120.l40s) 2台で構成しました。
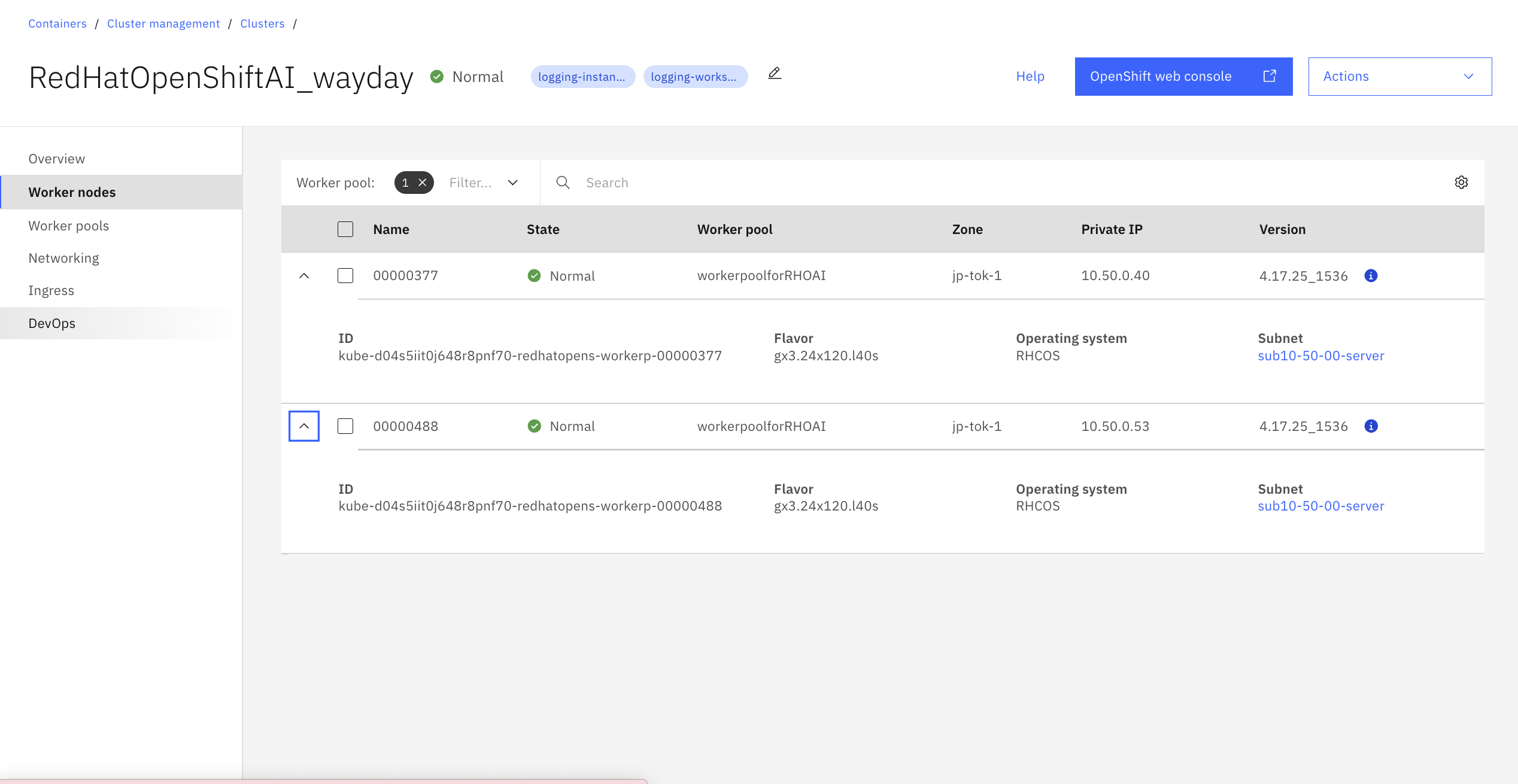
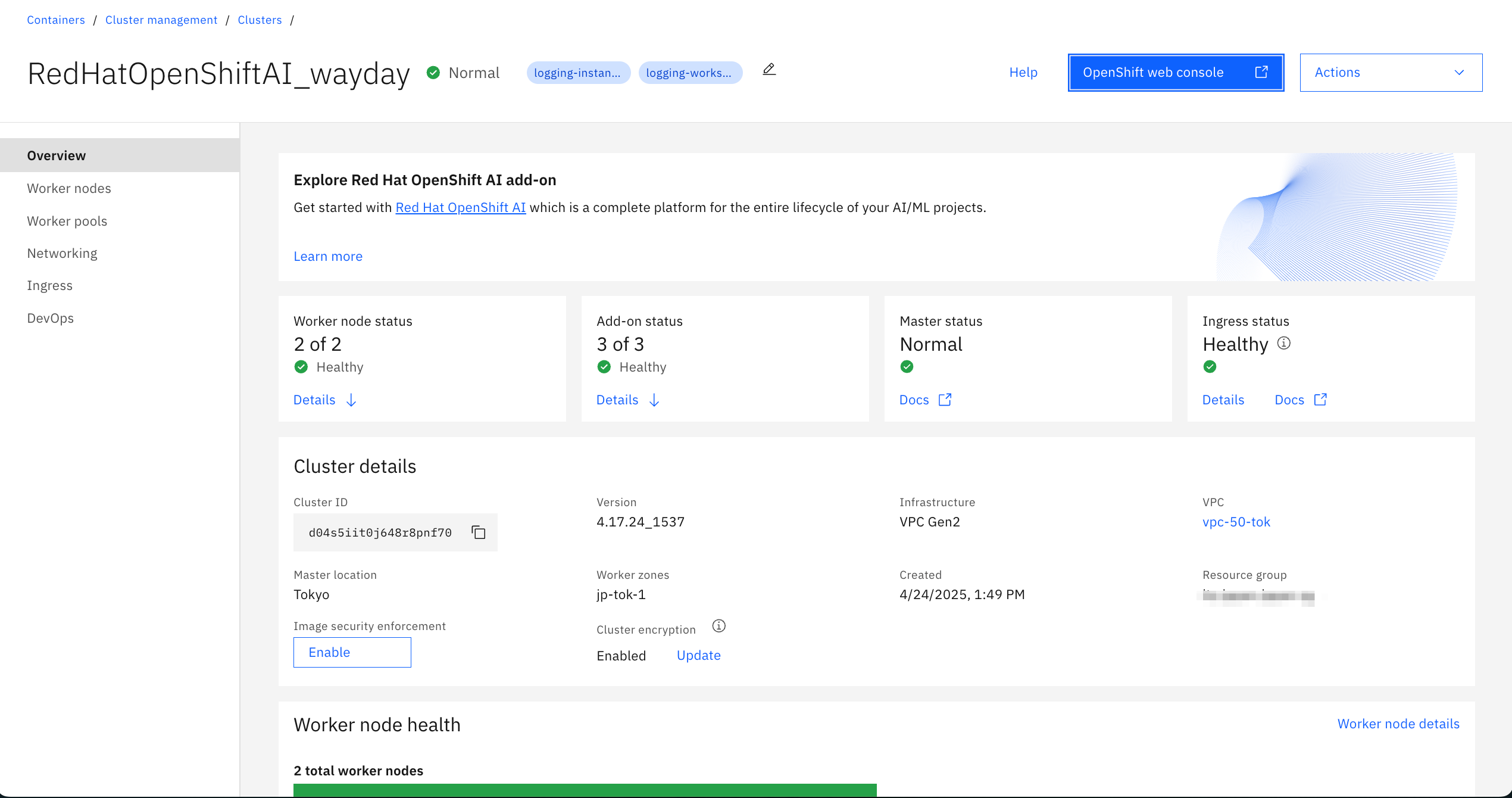
アドオンのインストールはクラスターの"Overview"画面から実施できます。
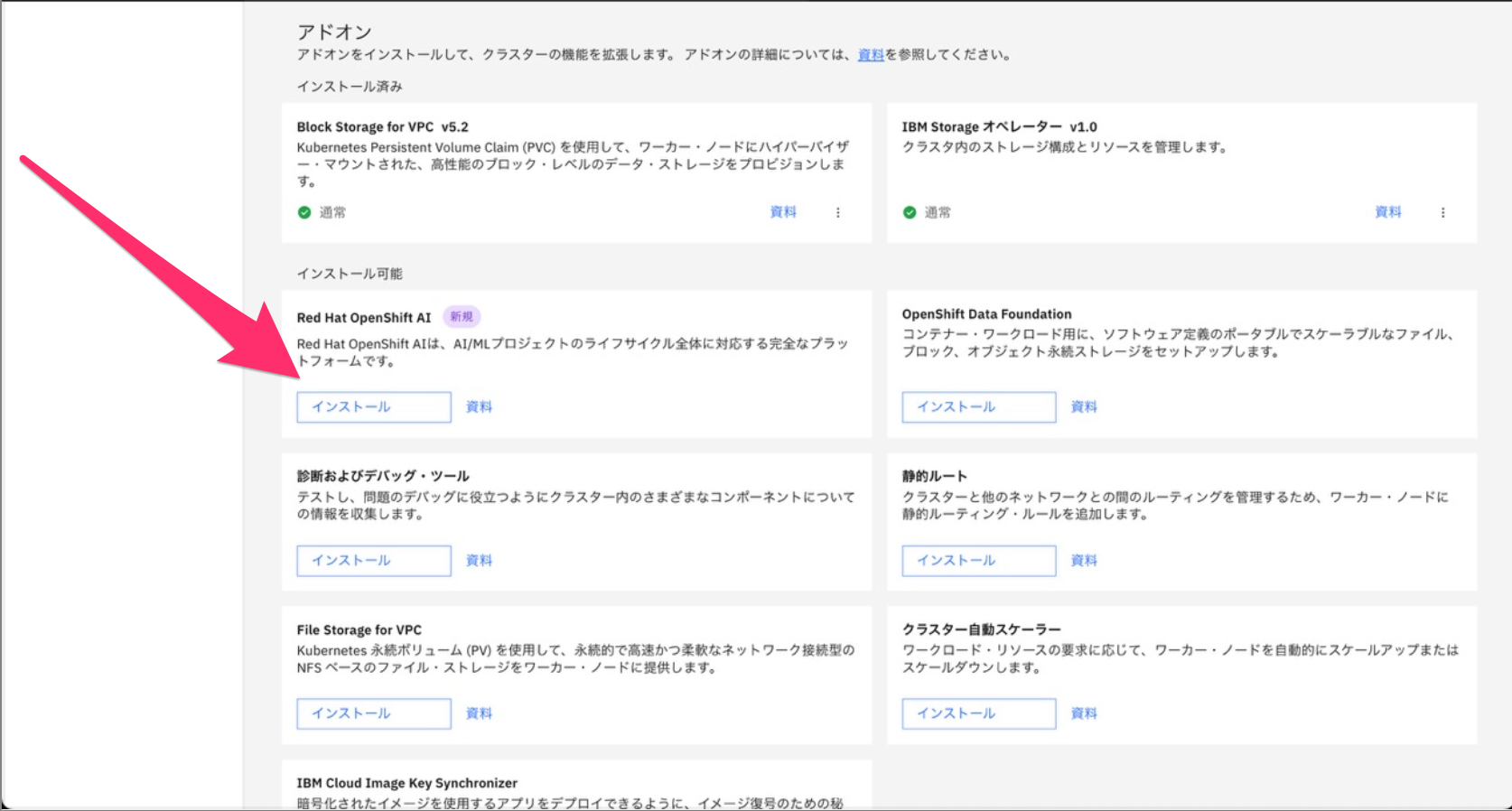
今回は ROKS 上に導入できる OpenShift AI Add-on バージョン 416 を利用しましたが、Red Hat OpenShift AI 2.16.2 に相当するものでした。
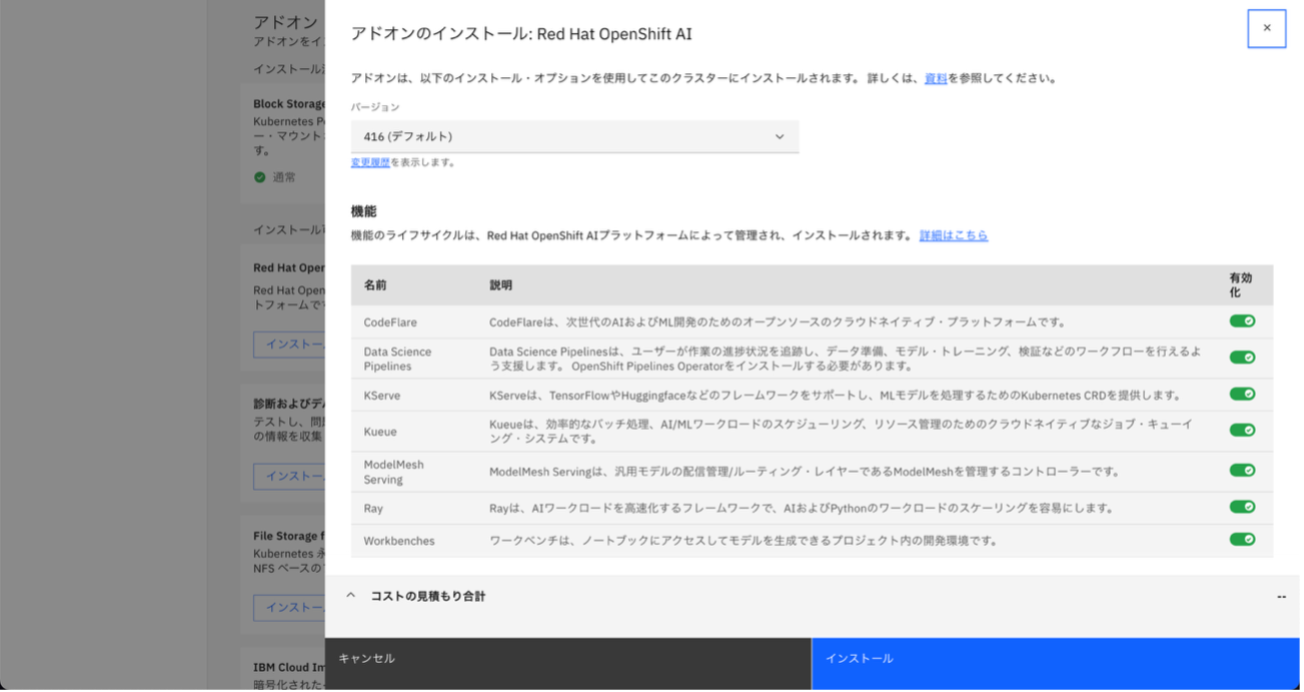
OpenShift AIのアドオンをインストールしたら準備完了です。
右上の"OpenShift web console"を開きます。
2. OpenShift AIのコンソール操作
こちらがOpenShift web console画面です。
右上の"Red Hat OpenShift AI"をクリックします。
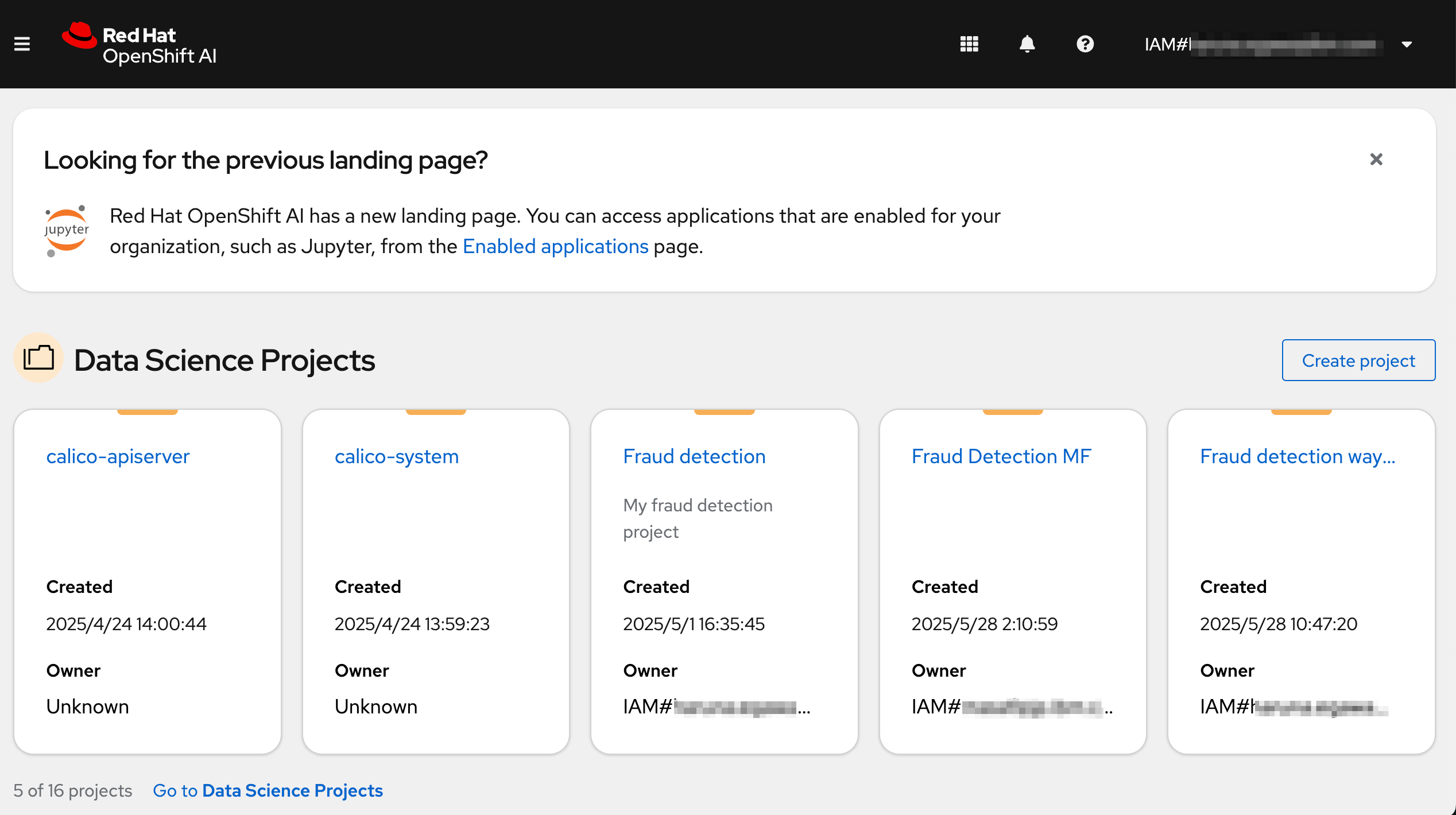
こちらがOpenShift AIのHome画面です。
不正検知のデモを稼働させるため、Data Science Project(KubernetesでいうNamespace)を作成します。"Create Project"をクリックします。
Project"Fraud detection Qiita"を作成しました。
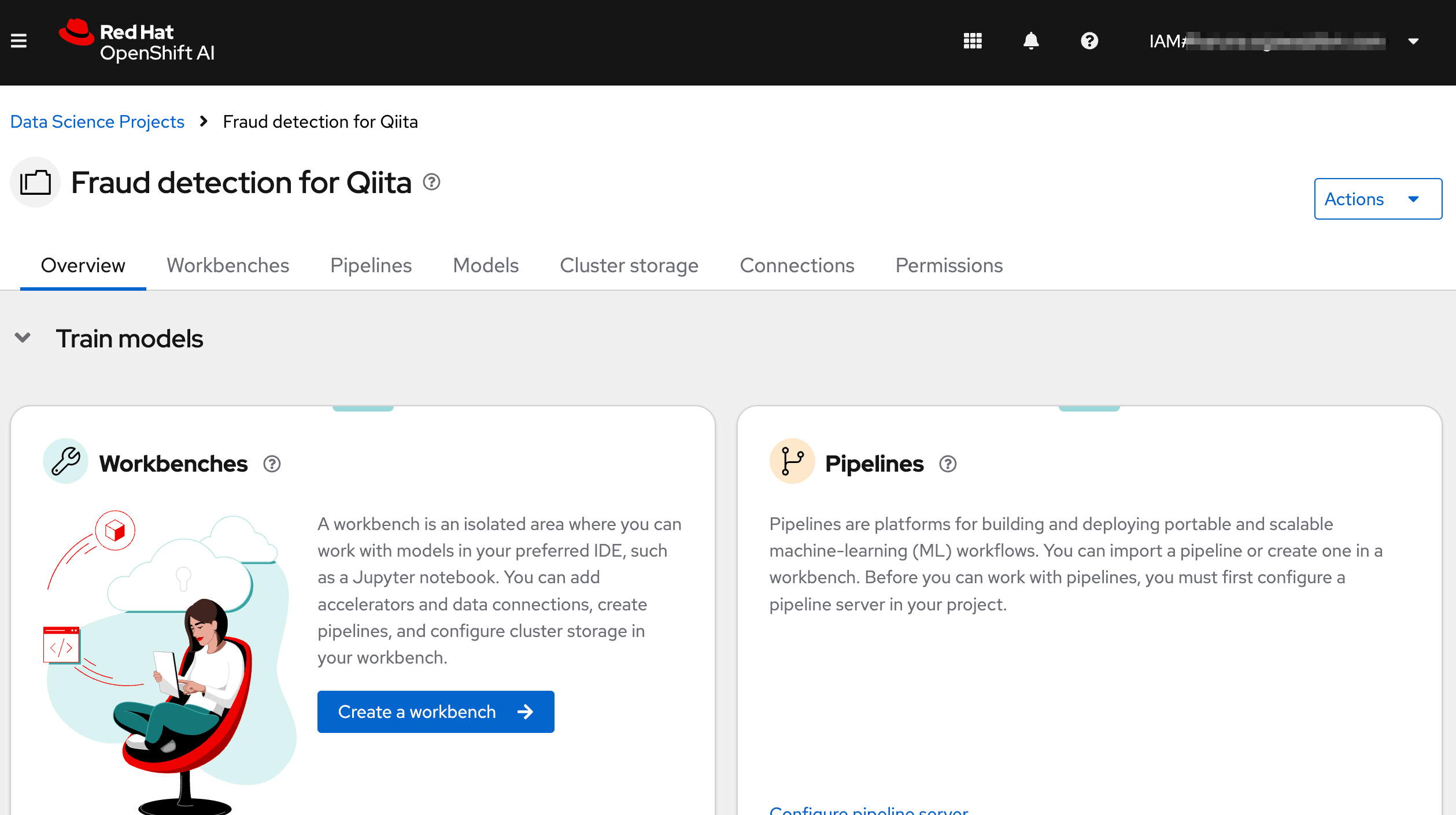
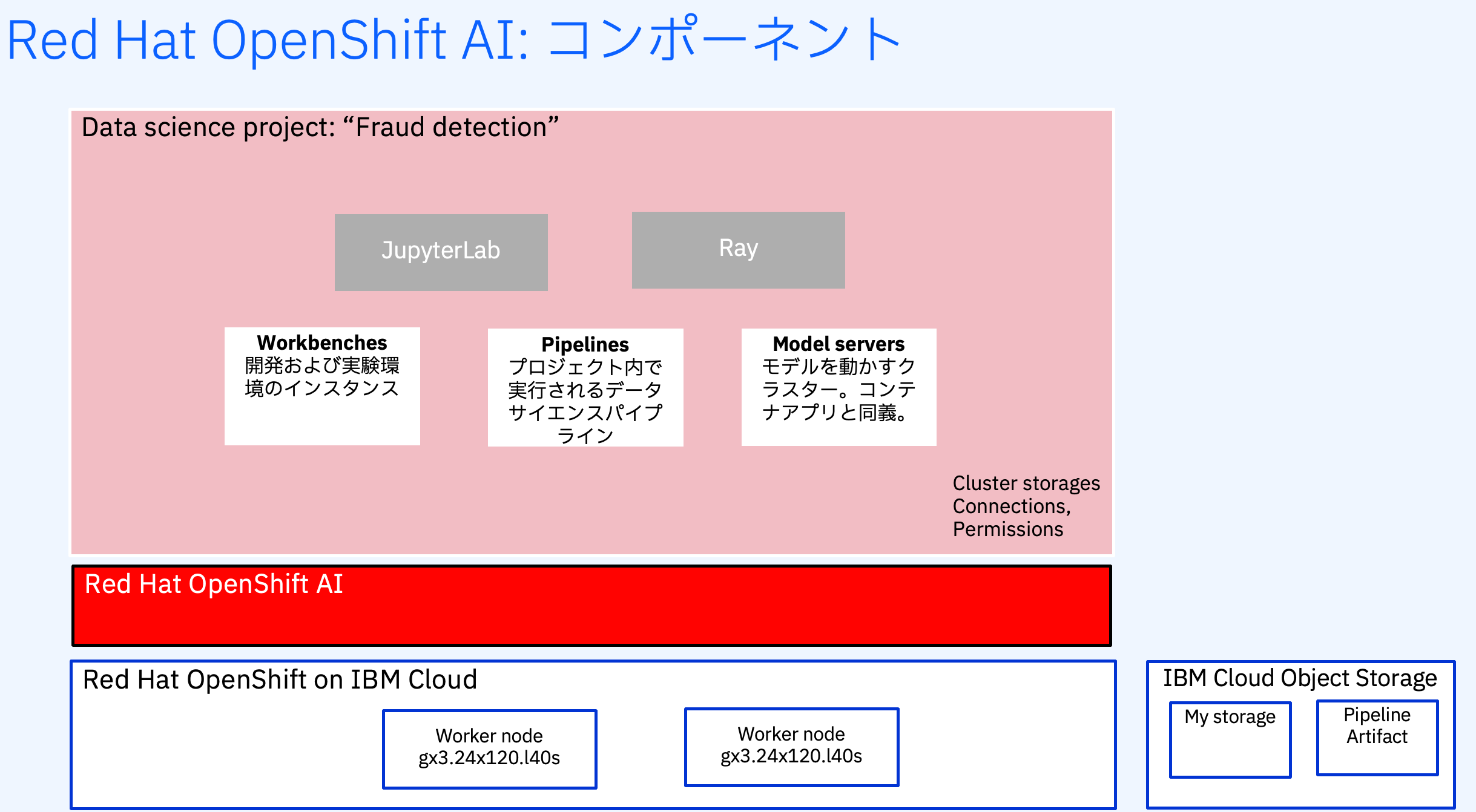
コンポーネントの説明
- Workbench : 開発環境および実験環境のインスタンスです。通常、これらには、JupyterLab、RStudio、Visual Studio Code などの IDE が含まれています。
パイプライン には、プロジェクト内で実行されるデータサイエンスパイプラインが含まれています。 - Model : リアルタイム推論用にトレーニング済みモデルを迅速に提供できます。データサイエンスプロジェクトごとに複数のモデルサーバーを使用できます。1 つのモデルサーバーで複数のモデルをホストできます。
- Cluster Storage : ワークベンチ内で作業中のファイルとデータを保持する永続ボリュームです。ワークベンチは 1 つ以上のクラスターストレージインスタンスにアクセスできます。
- Connection : S3 オブジェクトバケットなどのデータソースに接続するために必要な設定パラメーターが含まれています。
- Permission : プロジェクトにアクセスできるユーザーとグループを定義します。
3. Connectionの作成
(デモガイド2.3.2. 独自の S3 互換オブジェクトストレージへの接続の作成 )
Connectionでは、モデルデータを保存するストレージへの接続に必要なパラメーターを設定します。
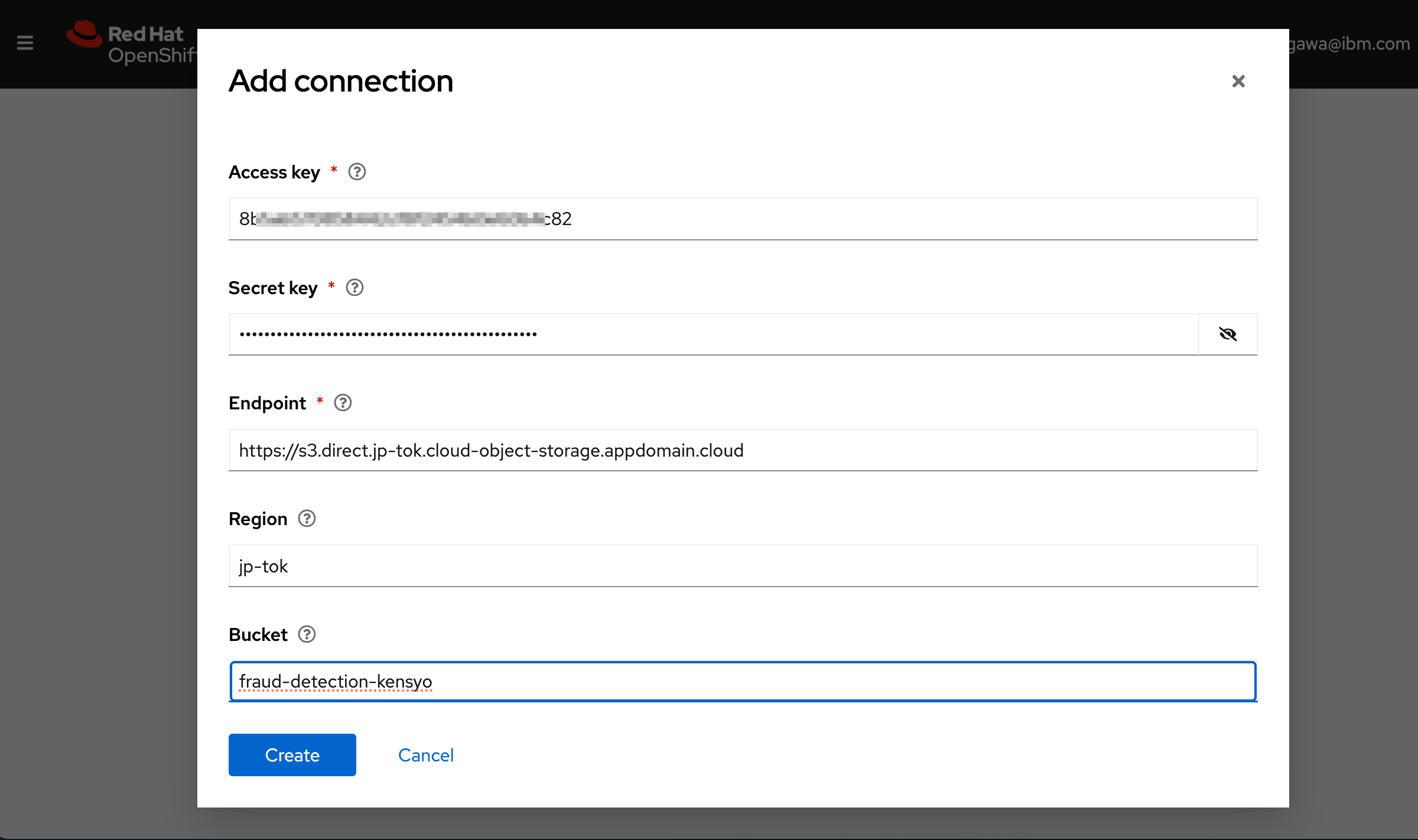
IBM Cloud Portalにて、準備しておいたIBM Cloud Object Storageのインスタンス"Cloud Object Storage-kensyo"のサービス資格情報のうち“access_key_id”と“secret_access_key”、エンドポイントのURLのうち"ダイレクト"の値をメモしておきます。
OpenShift AIのコンソールに戻り、Connectionを用途別に2つ作成します。
- My Storage : モデルデータの保存用
- Pipeline Artifacts : Pipelineデータの保存用。パイプラインサーバーを作成する場合はこちらが必要です。
Connectionタブから"Create Connection"をクリックします。
以下の項目を記入します。
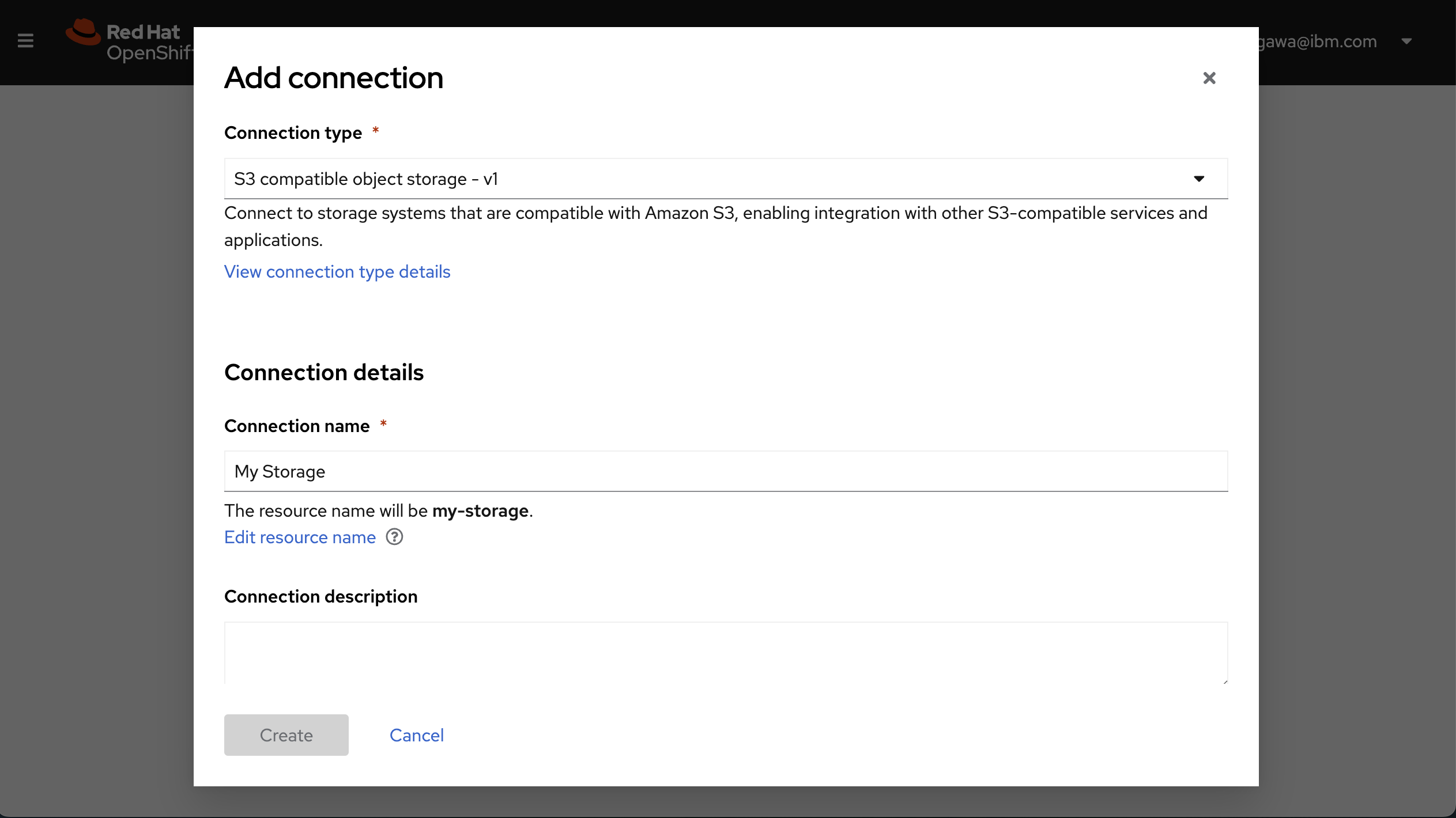
メモしておいたシークレット情報とEndpoint。Endpointの冒頭には"https://"をつけてください
同じ手順で、Pipeline Artifactsも作成しました。(今回は1つのバケットで兼ねていますが、用途別に作るのがベターだそうです)
4. パイプラインの実現
(デモガイド2.4. データサイエンスパイプラインの実現)
のちほどパイプライン実行できるように、Pipeline serverの設定を行います。
"Configure Pipeline Server"をクリックすると、以下の画面が出ます。
矢印のところから先程設定したPipeline Artifactsを選択すると、パイプラインデータ保存用のストレージへの接続情報が自動入力されます。
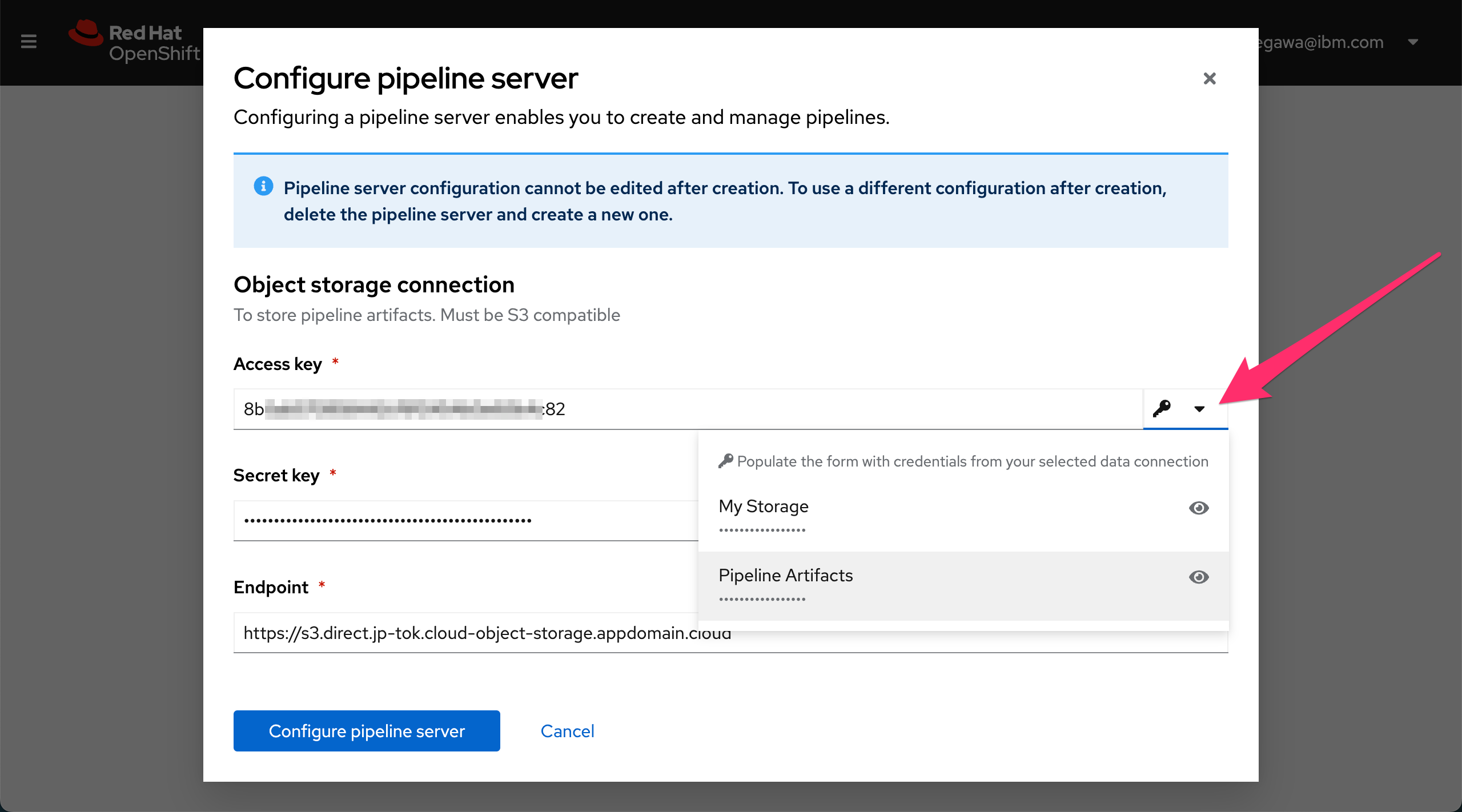
"Configure Pipeline Server"をクリックします。
数分待ってみて、"Import Pipeline"に変わればPipeline Serverの準備は完了です。
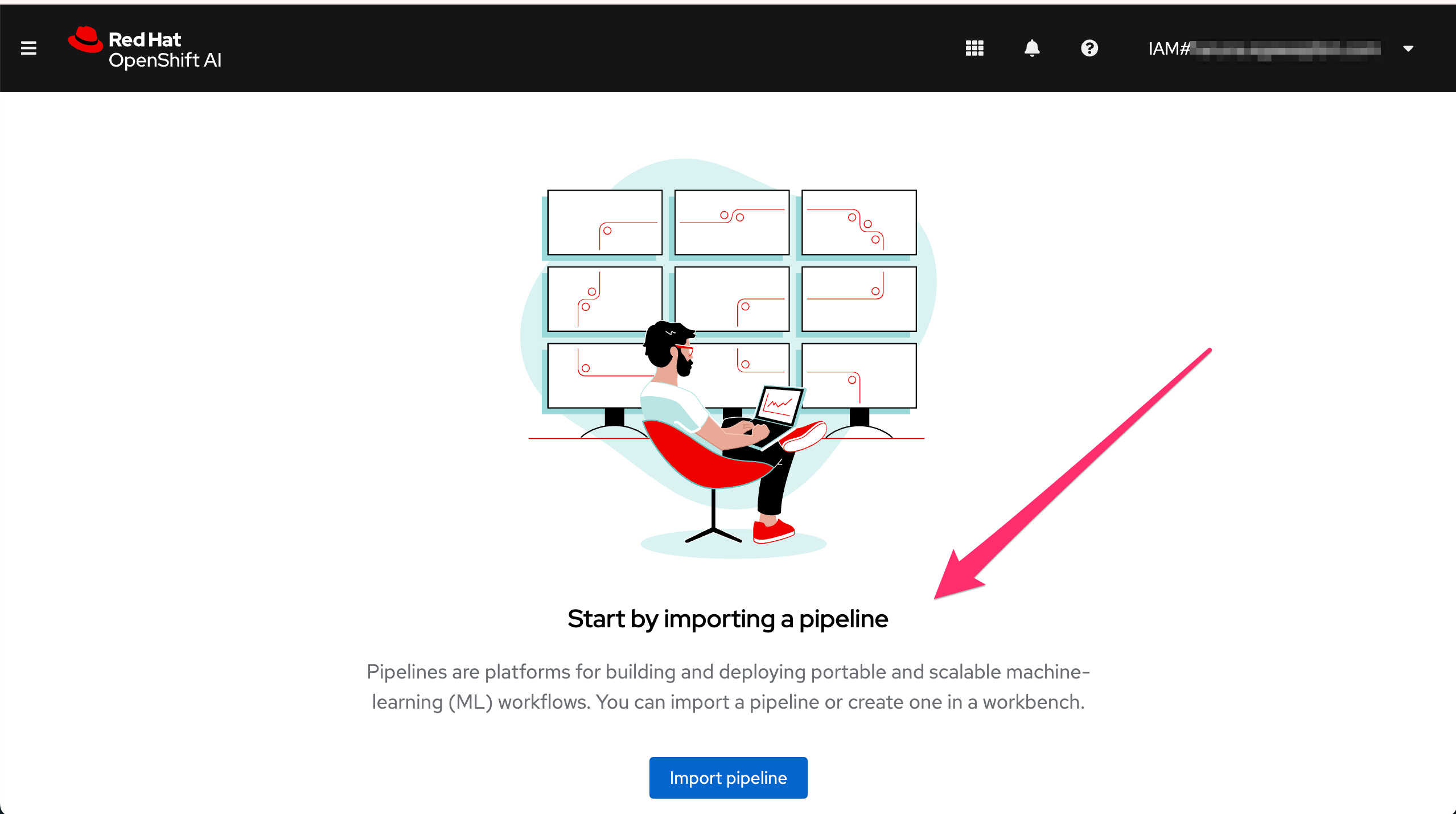
Pipeline ServerのConfigureに失敗した場合は、パイプラインデータ保存用のストレージ(今回は"Pipeline Artifacts")の接続情報が間違っていないか確認してください。
5. ワークベンチの作成
(デモガイド3.1. ワークベンチの作成とワークベンチイメージの選択)
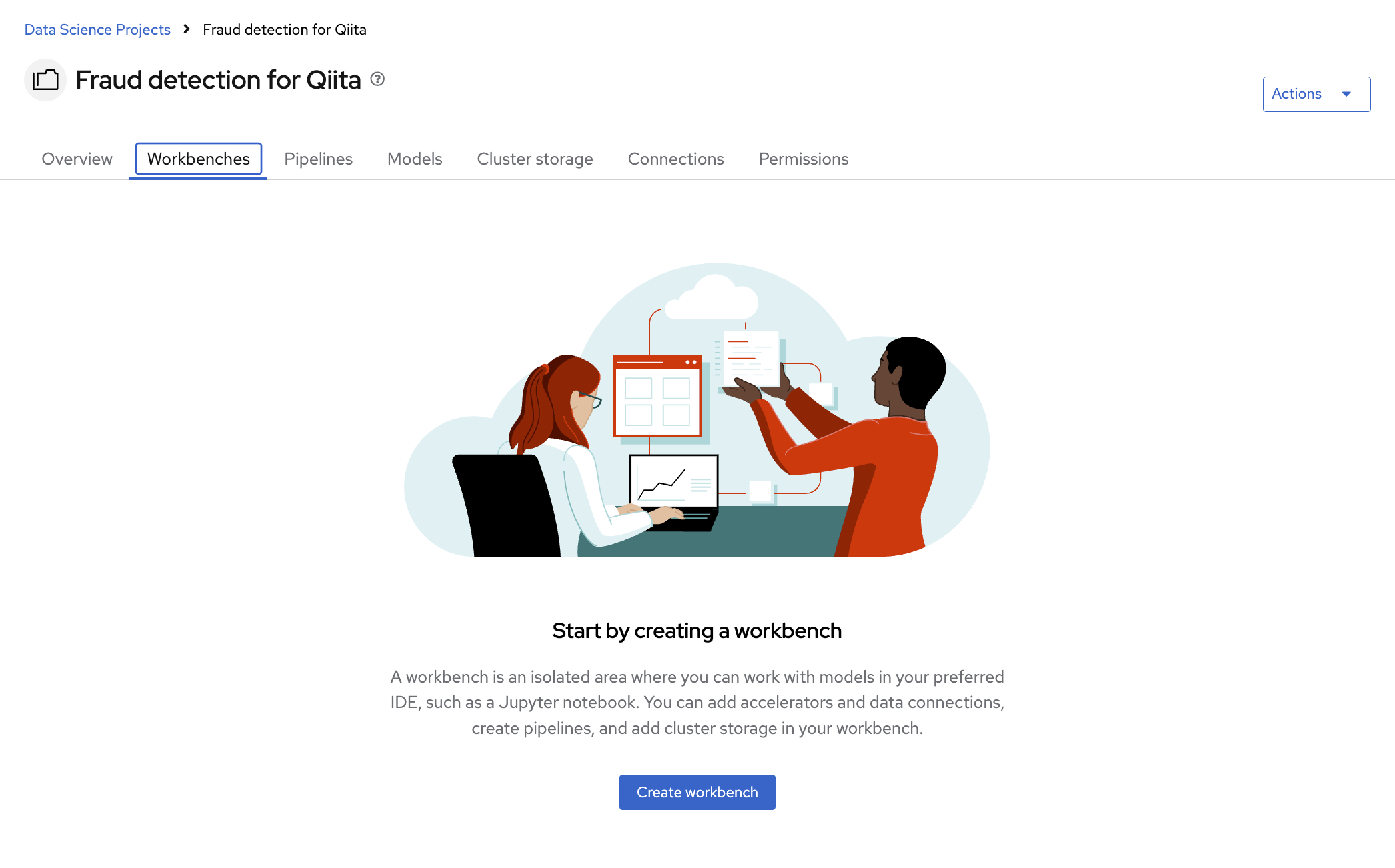
開発および実験環境のインスタンスであるワークベンチを作成します。
"Create workbench"をクリックします。
Red Hatは、サポート対象のワークベンチイメージを複数提供しています。Notebook image セクションでは、デフォルトのイメージまたは管理者が設定したカスタムイメージのいずれかを選択できます。Tensorflow イメージには、このチュートリアルに必要なライブラリーが含まれています。
今回のデモに必要なライブラリーが含まれているTensolflowを選択します。他にもCUDA, Pytorch, TrustyAI, code-serverなどが提供されています。
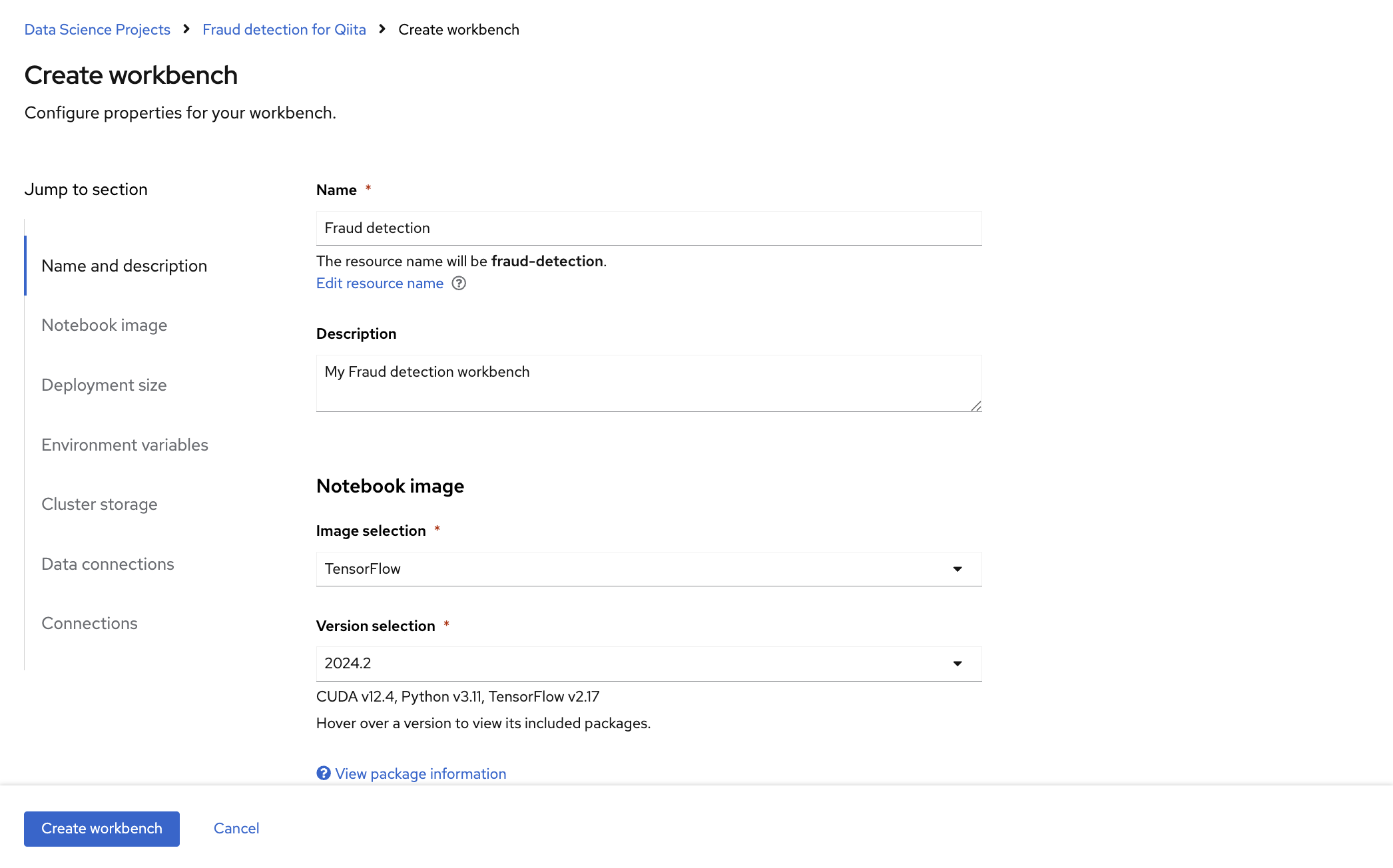
Connectionは先ほど作成したMy storageを指定します。
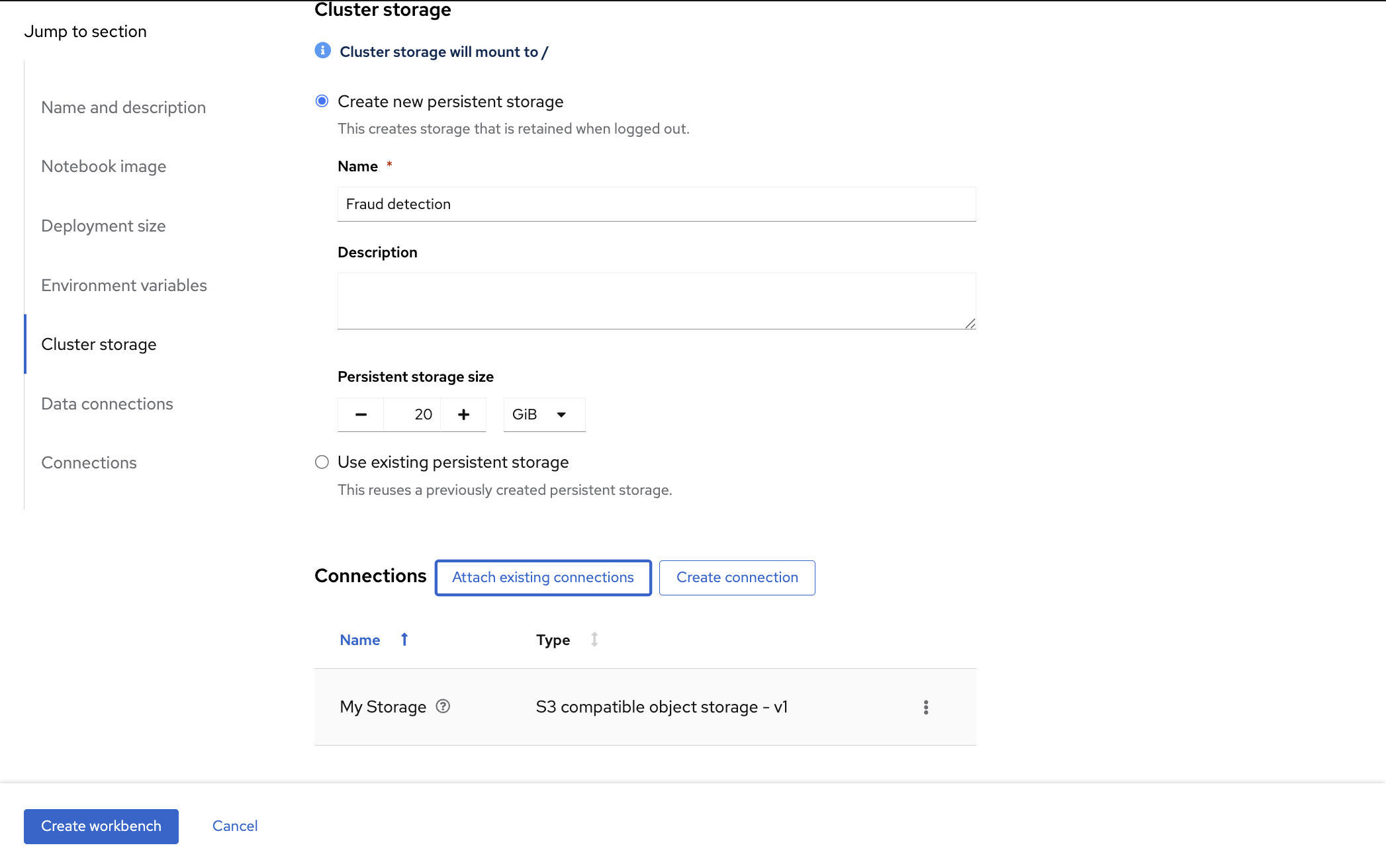
"Create workbench"をクリックします。
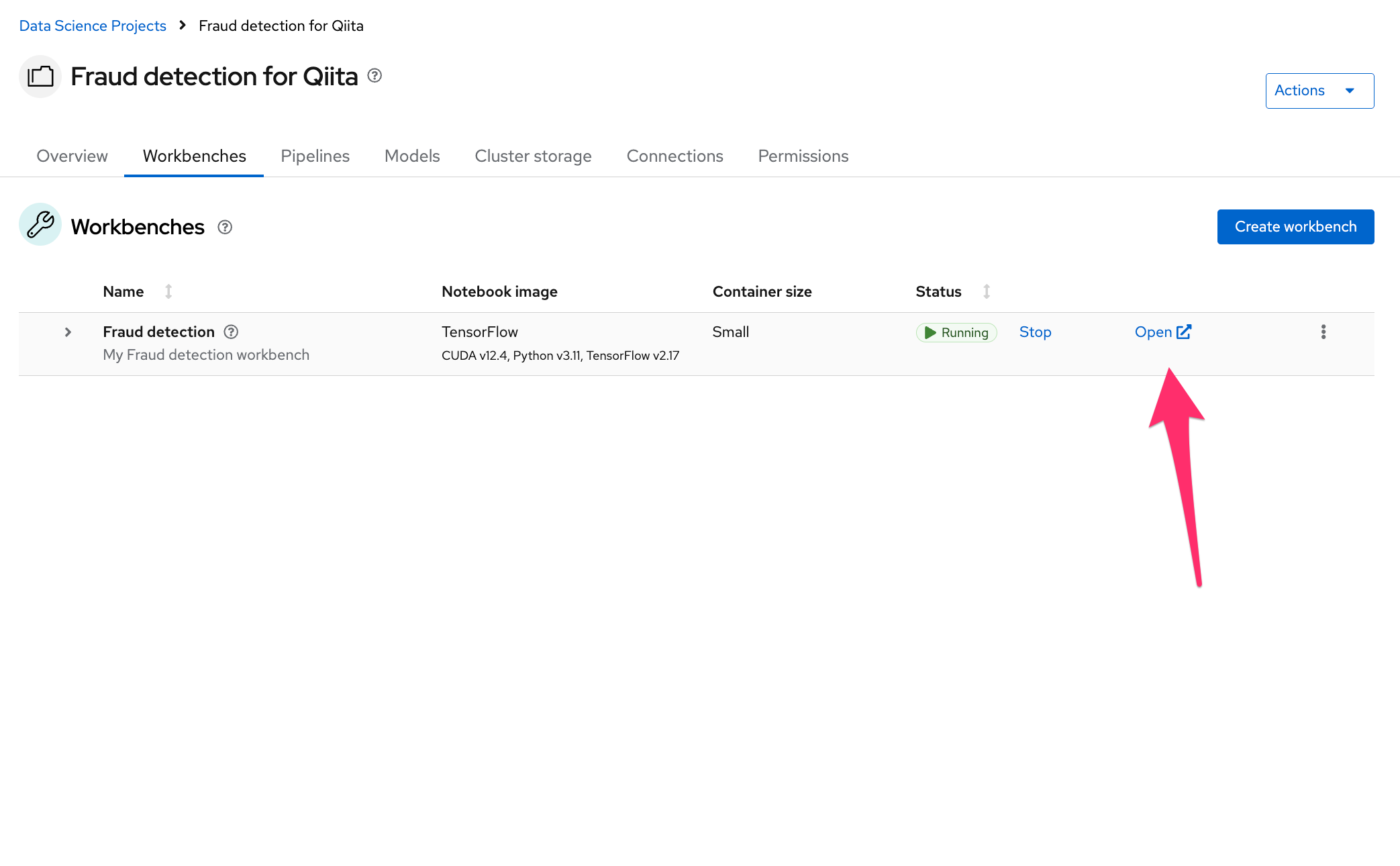
StatusがRunningに変わったら、"Open"から開きます
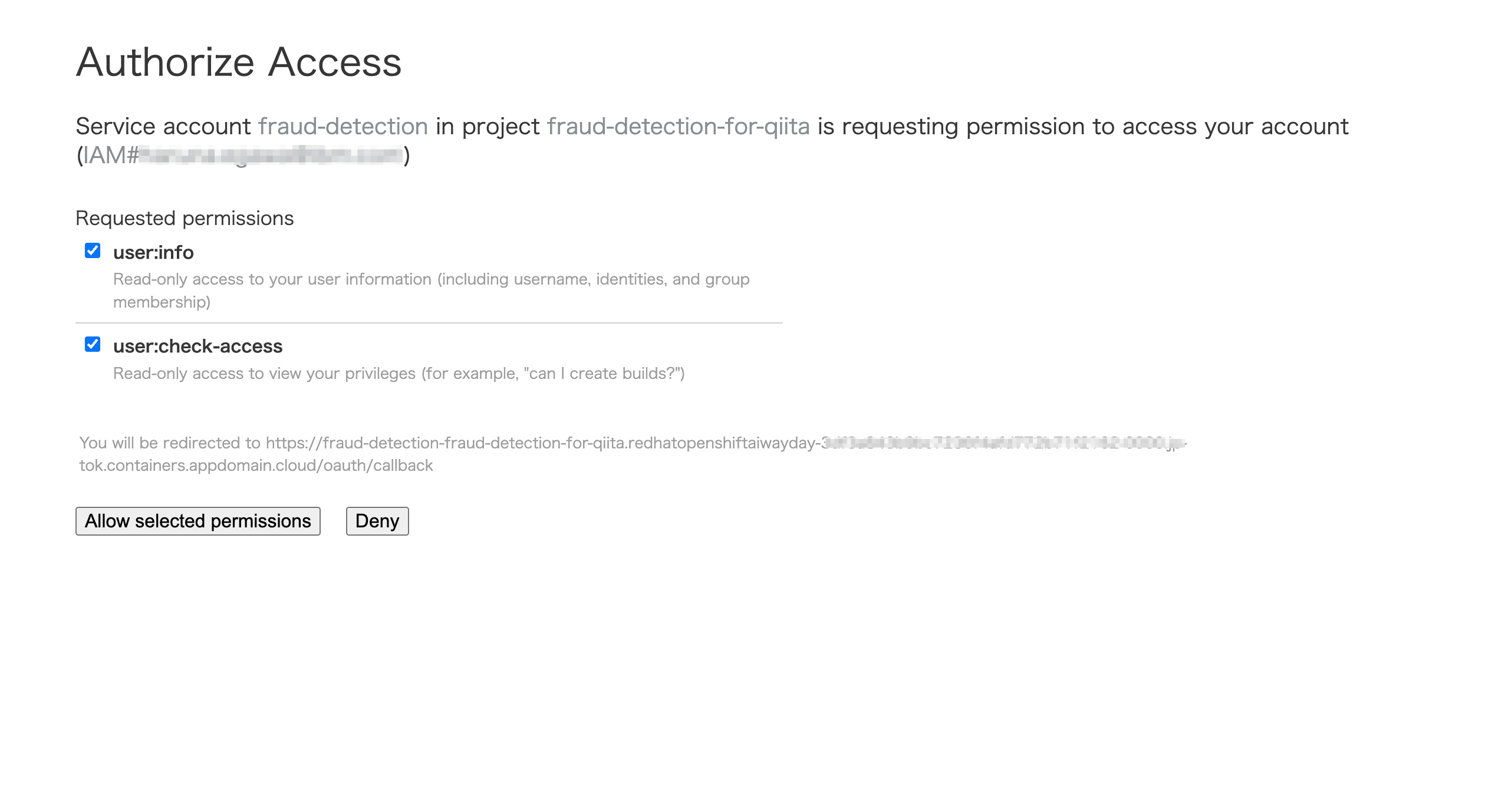
アクセス許可を求められるので、"Allow selected permissions"をクリックします。
JupyterLab環境のウィンドウが開きます
JupyterLab環境はJupyterNotebookの後継製品で、ブラウザ上で動作するプログラムの対話型実行環境です。その環境内で行うことはすべてRed Hat OpenShift AI上で行われ、OpenShiftクラスターによって実行されます。
不正検知デモのチュートリアルの内容をJupyterLab環境に取り込みます。
ツールバーで、Git Cloneアイコンをクリックし、チュートリアルGitのURlをペーストします。
https://github.com/rh-aiservices-bu/fraud-detection.git
Include submodules オプションを選択し、Clone をクリック
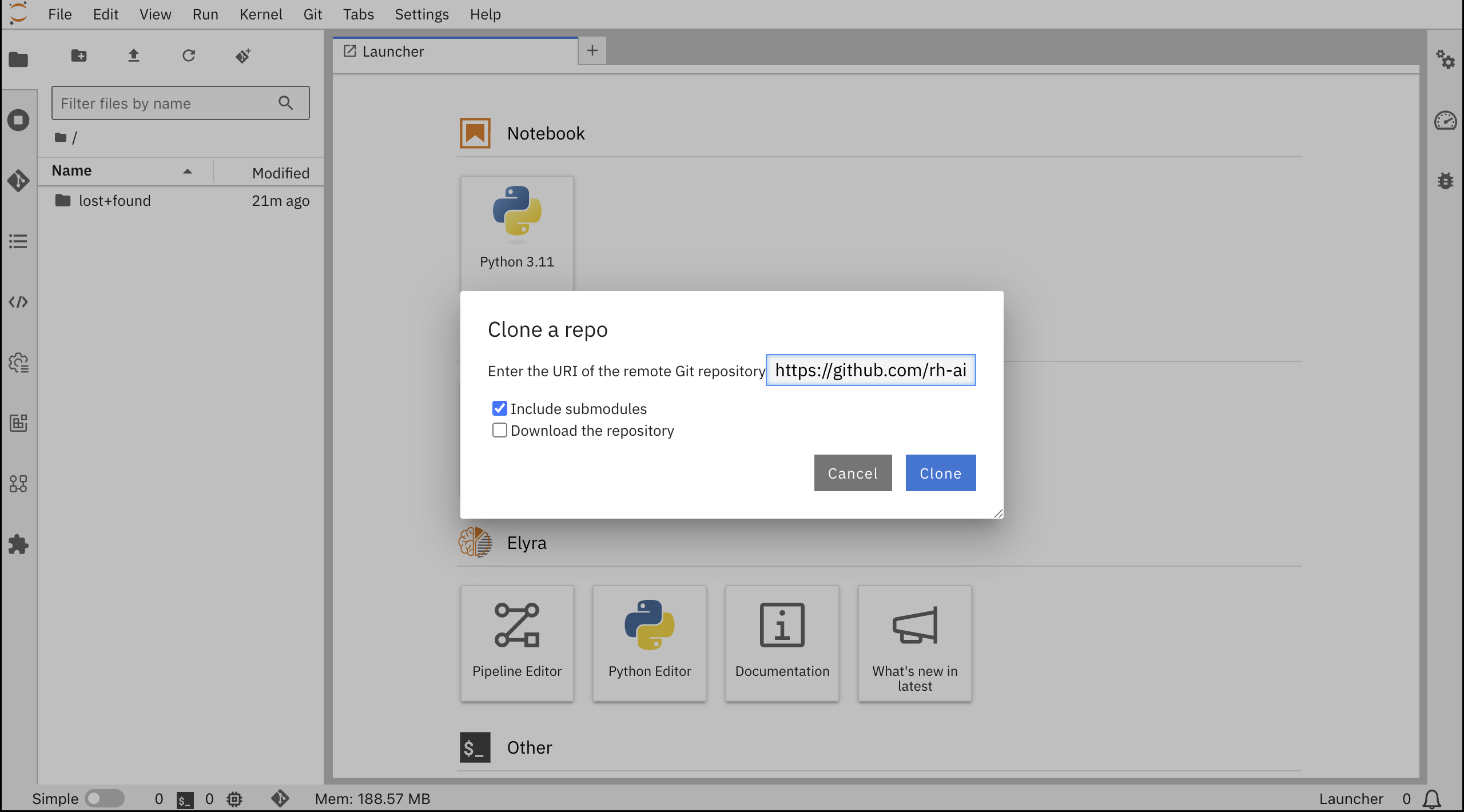
GitからレポジトリのCloneが成功しました。
ファイルブラウザーに、Git から複製したノートブックが表示されたら、モデルトレーニングの準備完了です。
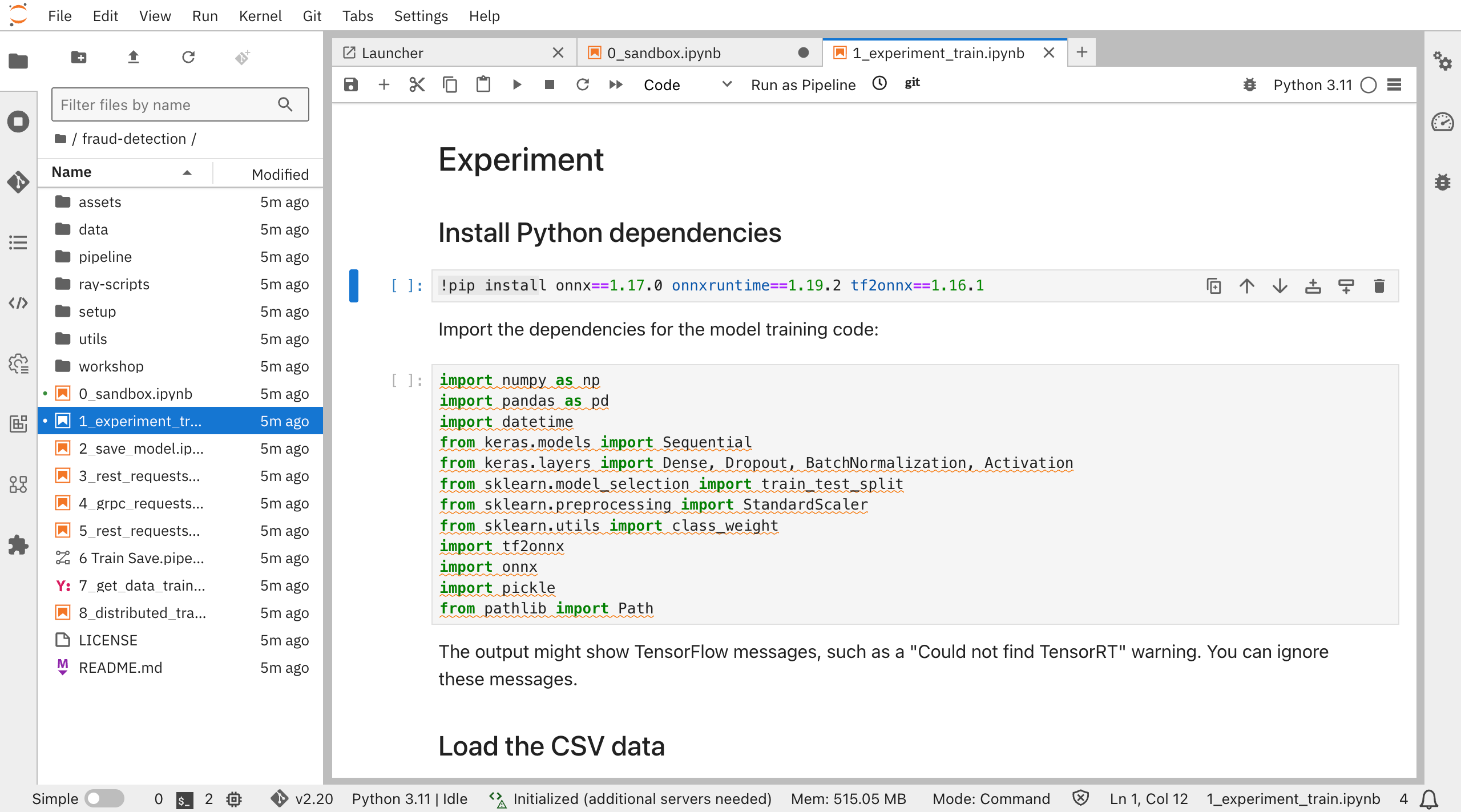
6. 不正検知モデルのトレーニング(notebook"1_experiment_train.ipynb")
JupyterLab環境で不正検知モデルをトレーニングします。
以下のコード内容がすでに準備されているので、順に実行していきます。
- モデルのトレーニングや推論を行うために必要なライブラリをインストール
- onnx, onnxruntime,etc.
- モデルトレーニングのためのCSVデータをダウンロード
- データの種類:トランザクションが発生した地点と自宅からの距離、最後にトランザクションが発生した場所からの距離、暗証番号の使用有無、オンライン注文かどうか,etc.
- モデルをビルド、トレーニング、保存、テスト
あるトランザクションが不正であるかどうか検知するサンプルを実行します。
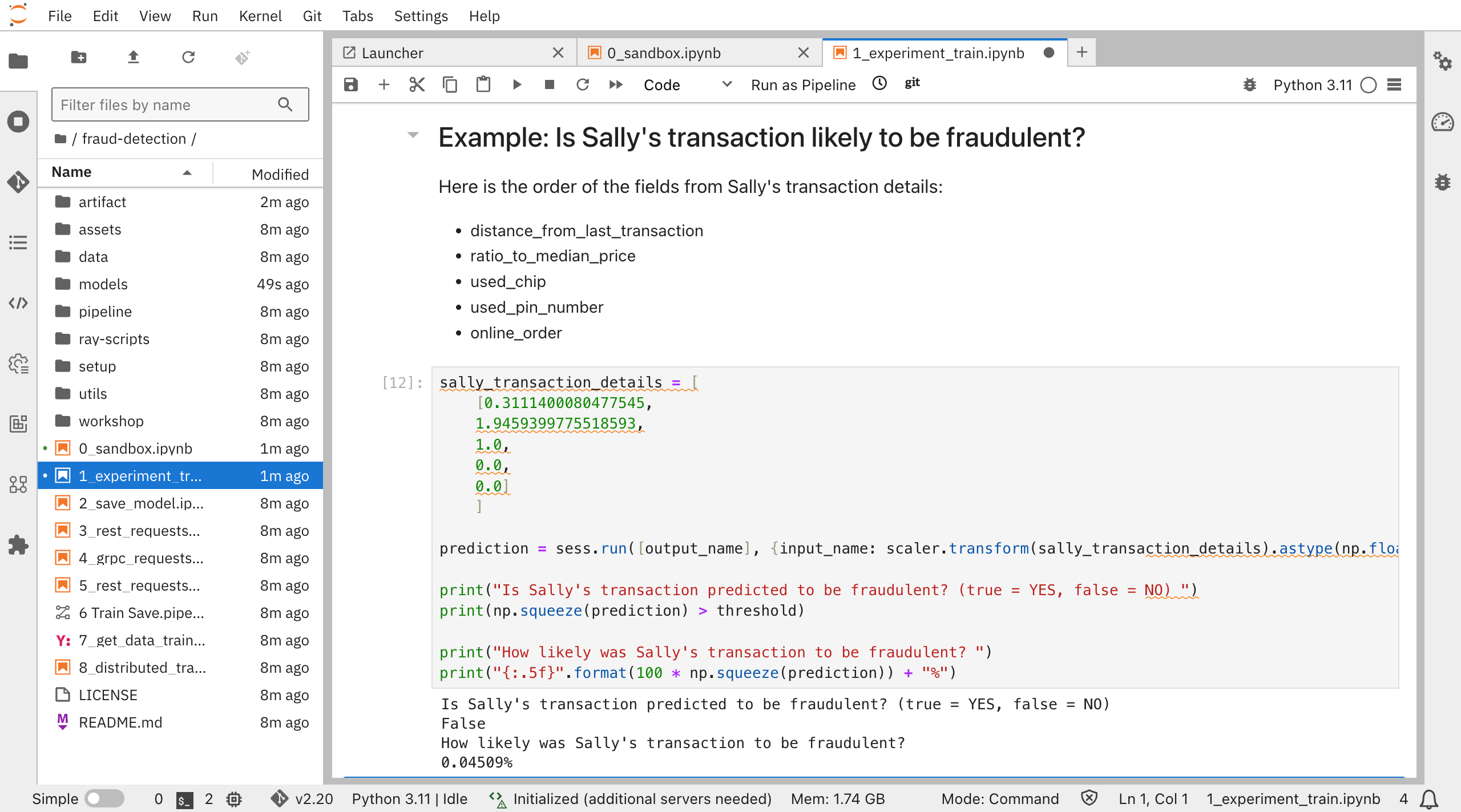
このトランザクションは不正である可能性が0.04509%と出ました。
モデルファイルをSaveしておきます。
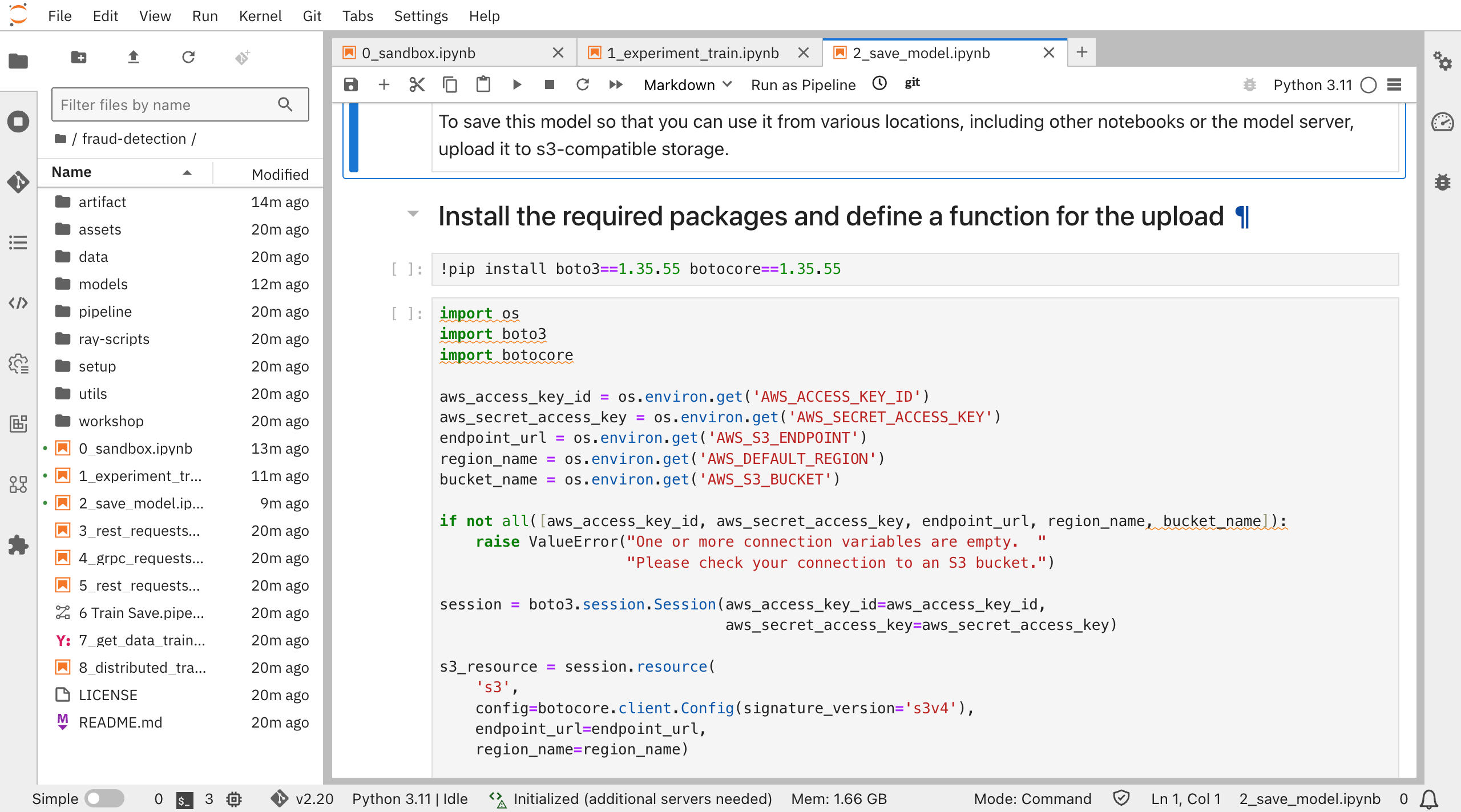
7. 不正検知モデルの保存(notebook"2_save_model.ipynb")
(デモガイド4.1. デプロイメント用のモデルの準備)
notebook1で作成したモデルを他の場所やnotebookからも参照できるように、モデルファイルをONNX形式に変換し、ストレージ(ICOSバケット”My storage”)に保存します。
ONNXとは、機械学習モデルを表現するために使用されるオープンソースのフォーマットです。ONNX形式に変換することにより、フレームワーク間でのモデルの共有が出来るようになります。
notebook2では以下の内容がコード化されているので、順に実行していきます。
- 必要なパッケージをインストール
- 引数としてストレージ情報
- ONNX形式に変換し、ストレージに保管
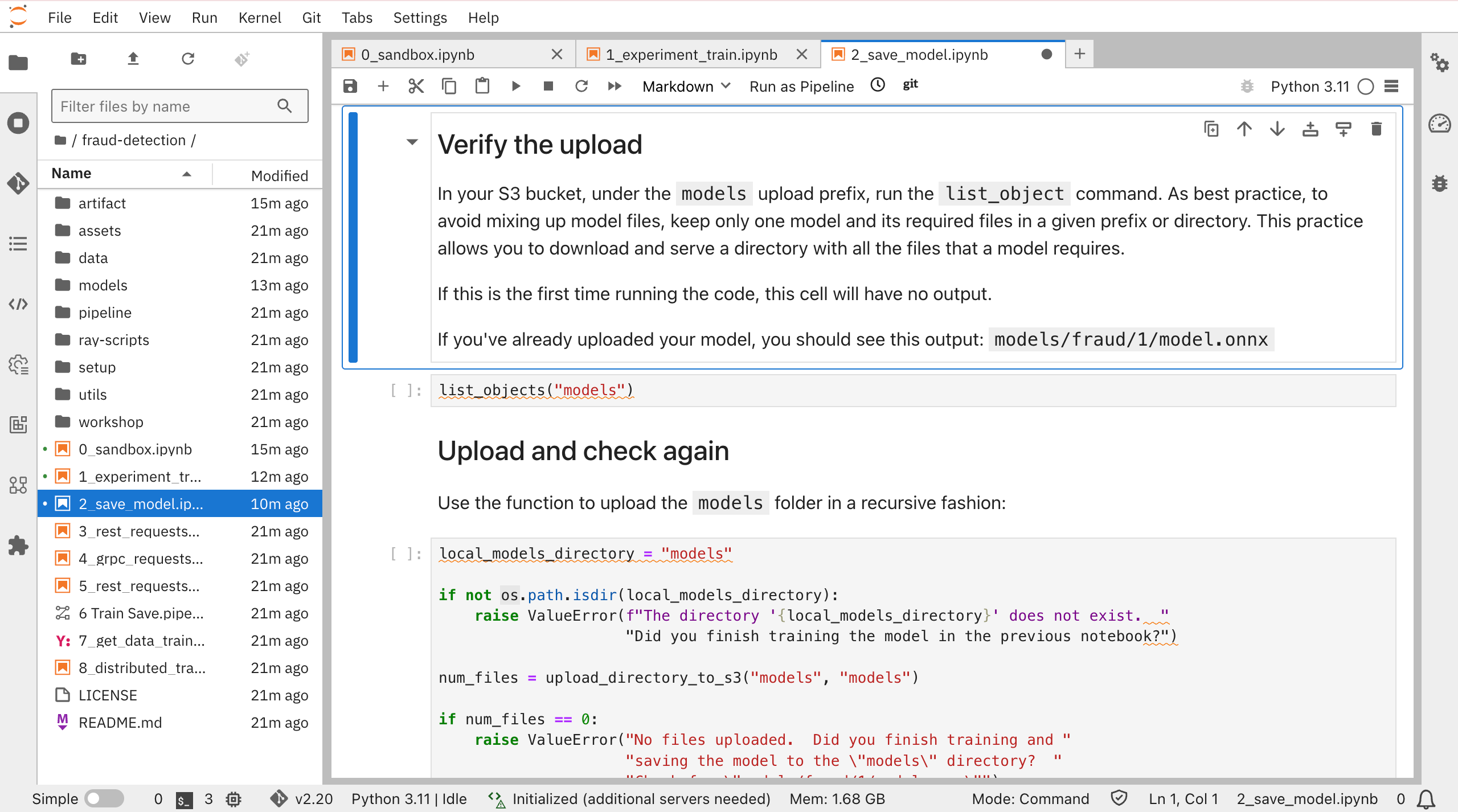
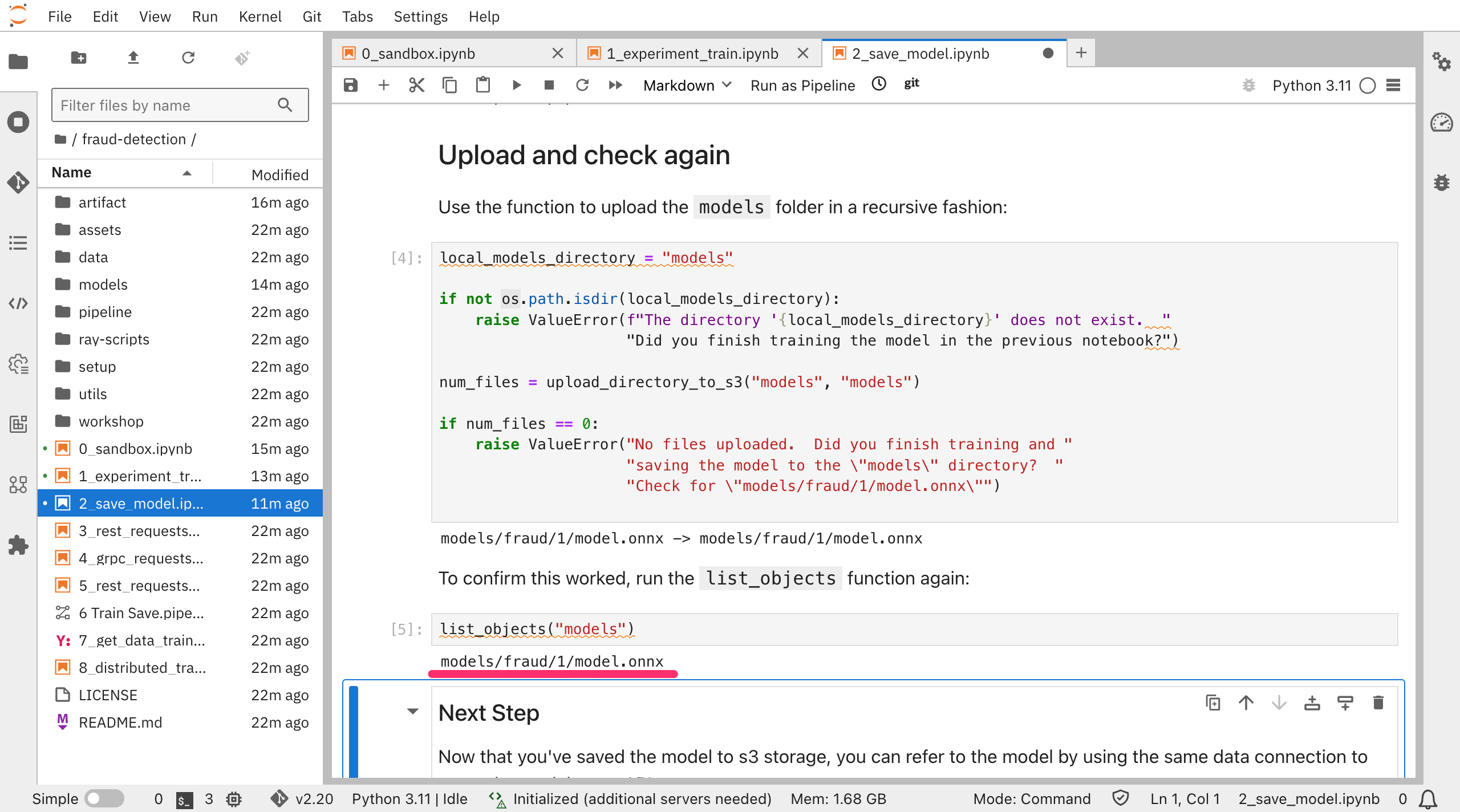
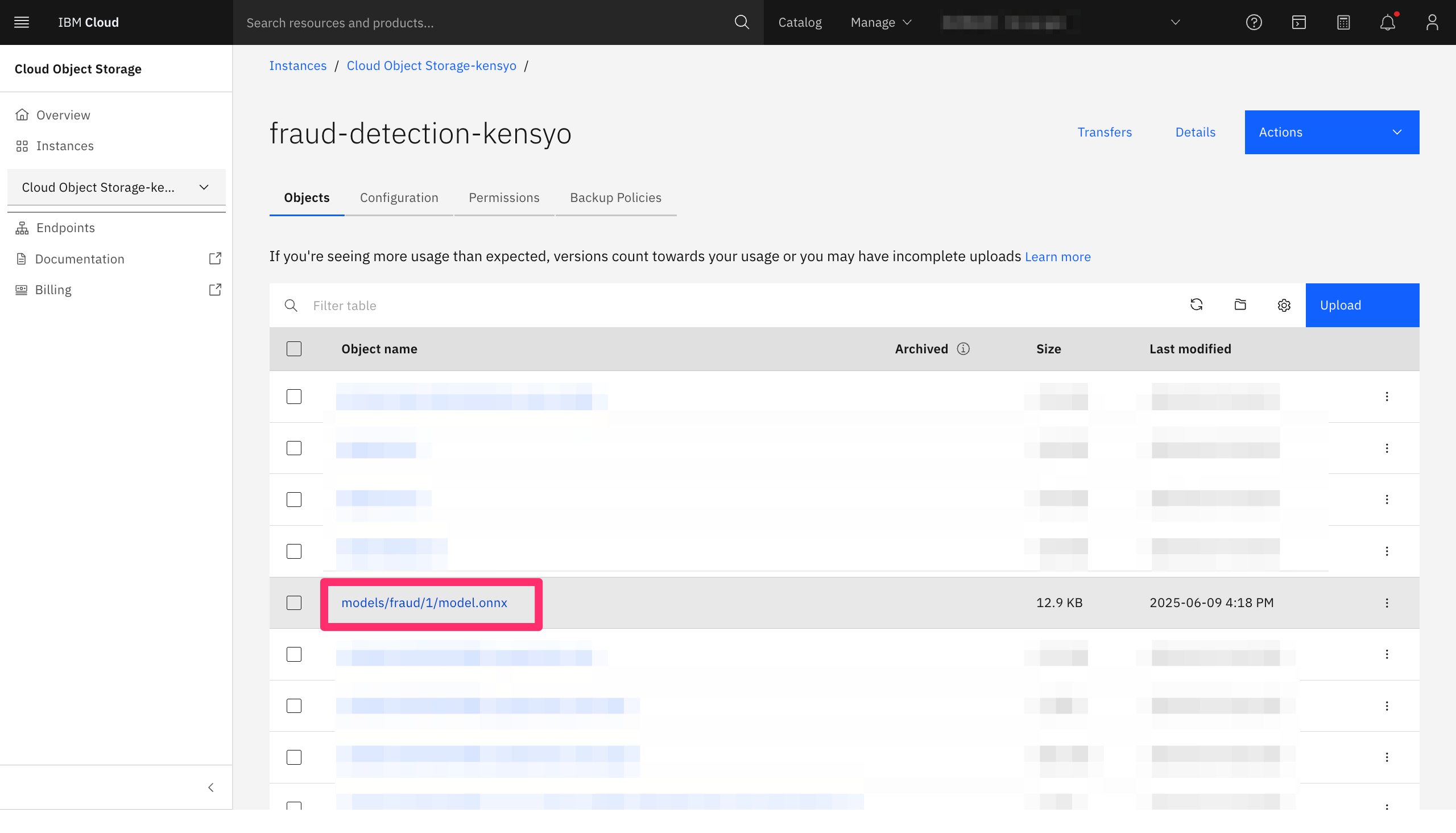
ICOSのバケット内をみると、models/fraud/1/model.onnxが保存されていることがわかります。
8. モデルサーバーへのデプロイ
(デモガイドマルチモデルサーバーへのモデルのデプロイ)
続いて、モデルをAPIで呼び出せるように、モデルサーバーにデプロイします。
OpenShift AIではシングルモデルサーバーとマルチモデルサーバーの2種類が準備されていますが、IBM Cloudではマルチモデルサーバーといって、複数のモデルを同時にホストできるサーバータイプのみ選択できるようになっています。
まず、モデルサーバーを作成します。
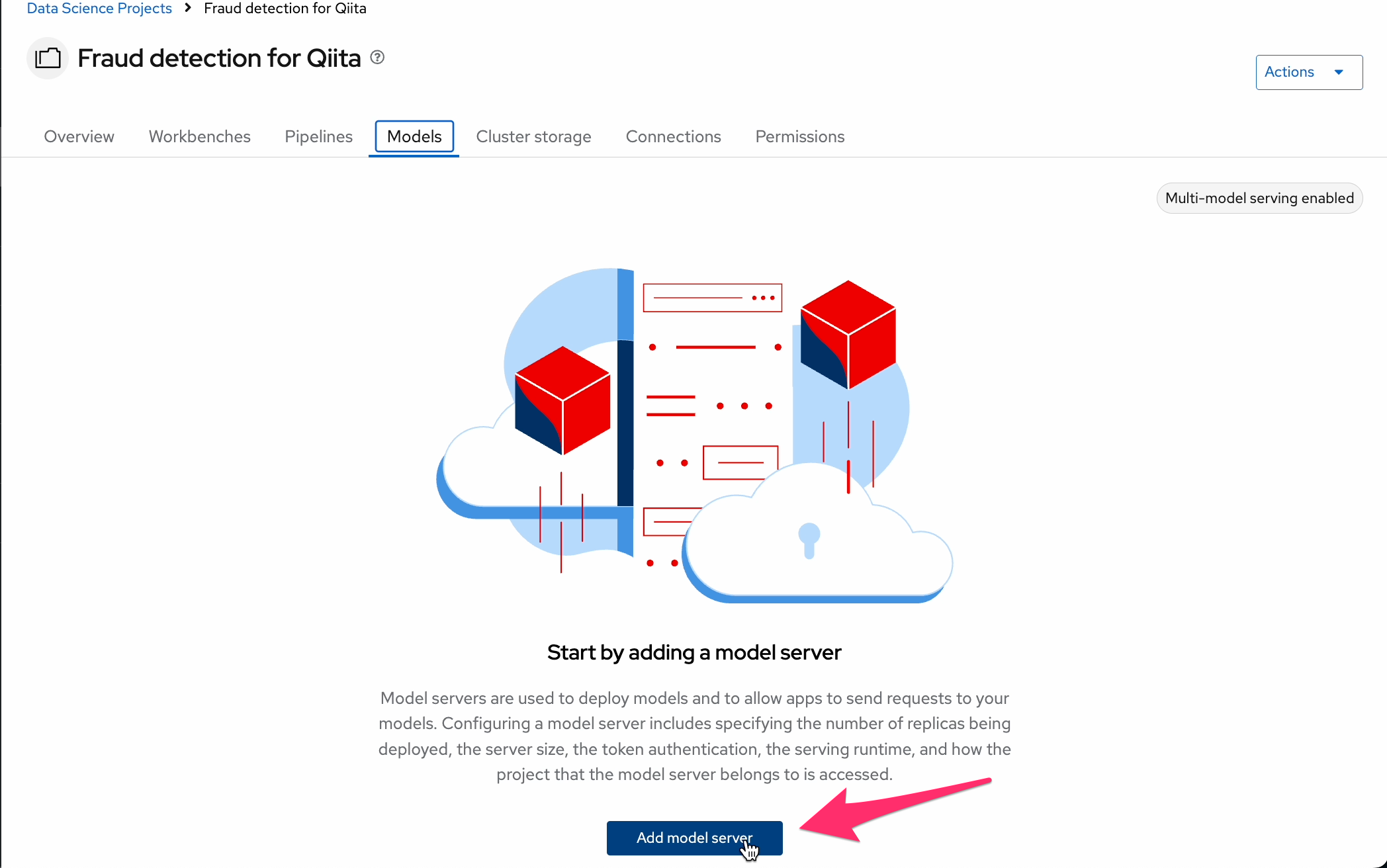
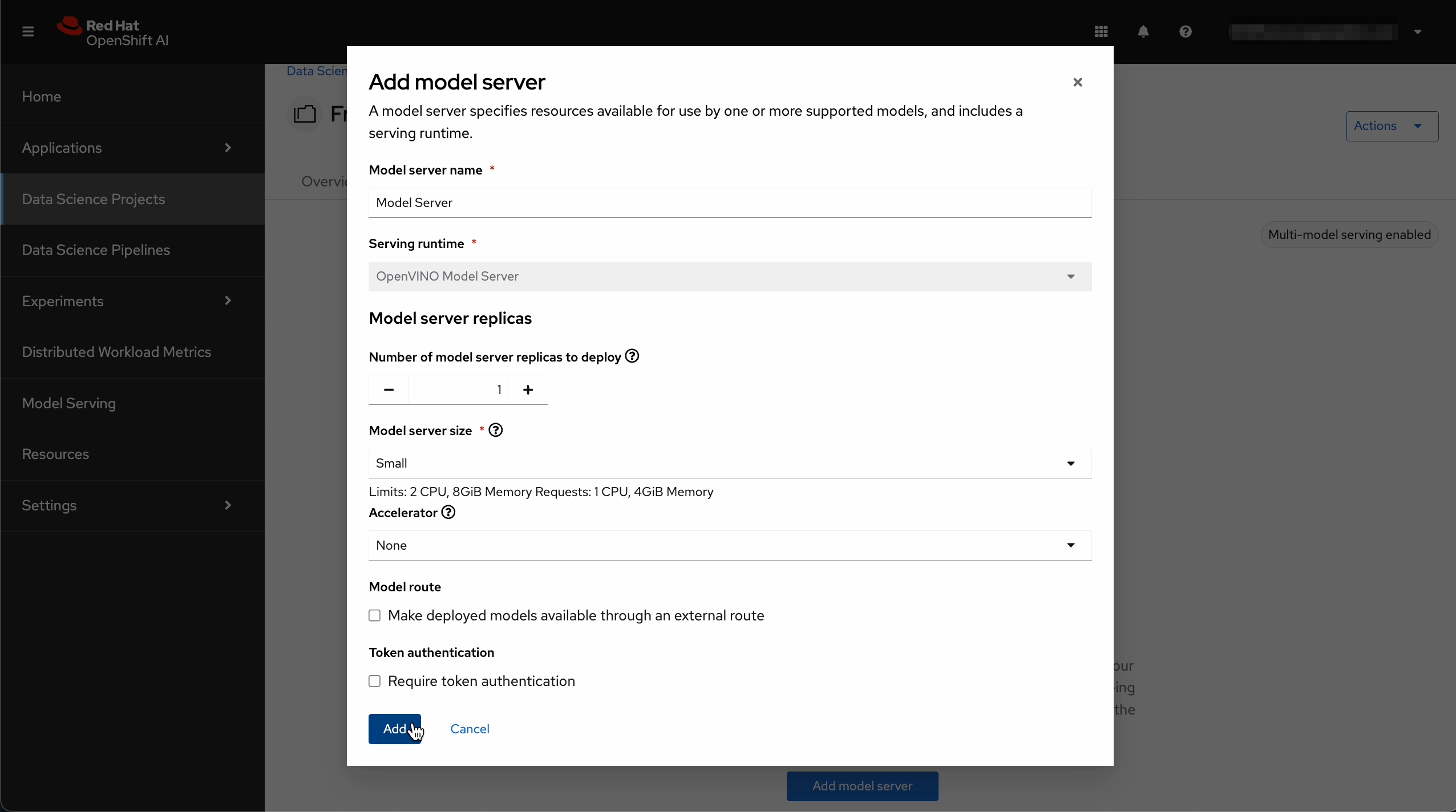
- Model server name: "Model Server"などの名前を入力
- Serving runtime: OpenVINO Model Server を選択
- その他のフィールドはデフォルト設定
モデルサーバーを作成したら、そこにモデルをデプロイします。
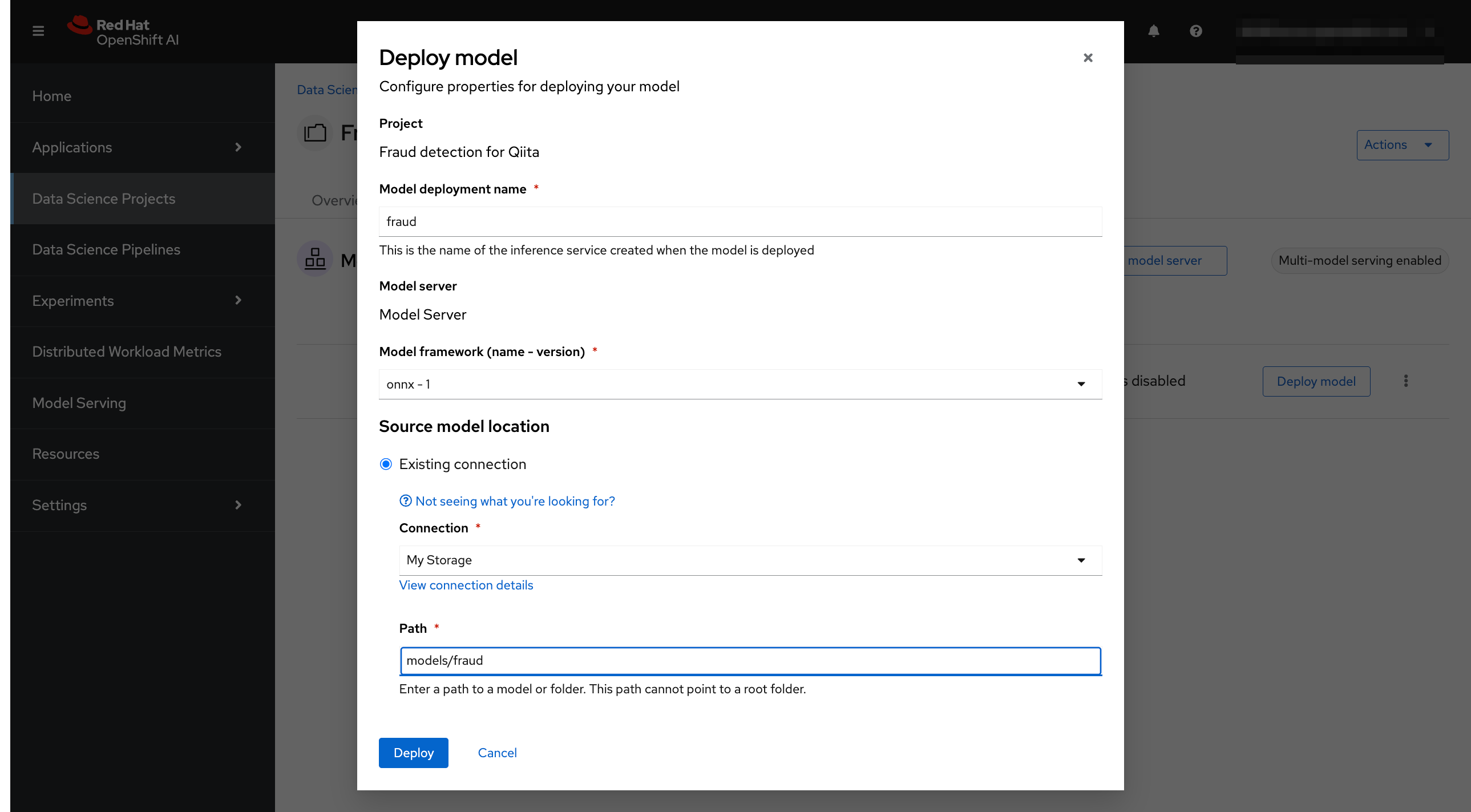
- Model deployment name: "fraud"
- Model framework: "onnx-1"を選択
- Existing connection: "My Storage"を選択
- モデルファイルを含むバージョンフォルダーへのパス (models/fraud) を入力します。
- その他のフィールドはデフォルト設定のままにします。
Deployをクリックします。
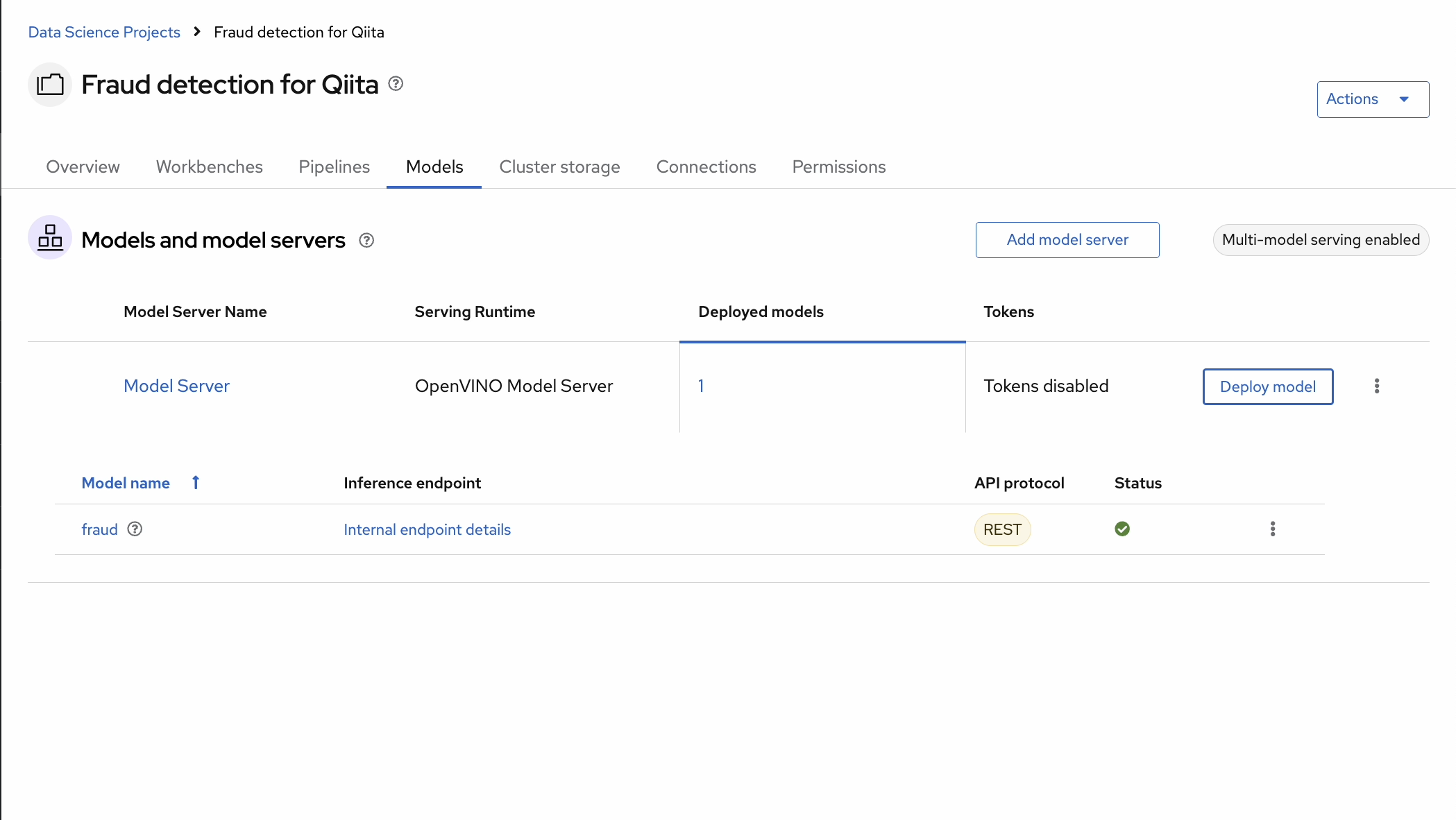
数分待つと、Statusが緑のチェックマークに変わります。これで、モデルのデプロイが完了したことがわかります。
API呼び出しをテストしてみる
続いてAPIエンドポイントをテストしていきます。
"Internal endpoint details"をクリックすると、grpcUrlとrestUrlが確認できます。こちらをメモしておきます。
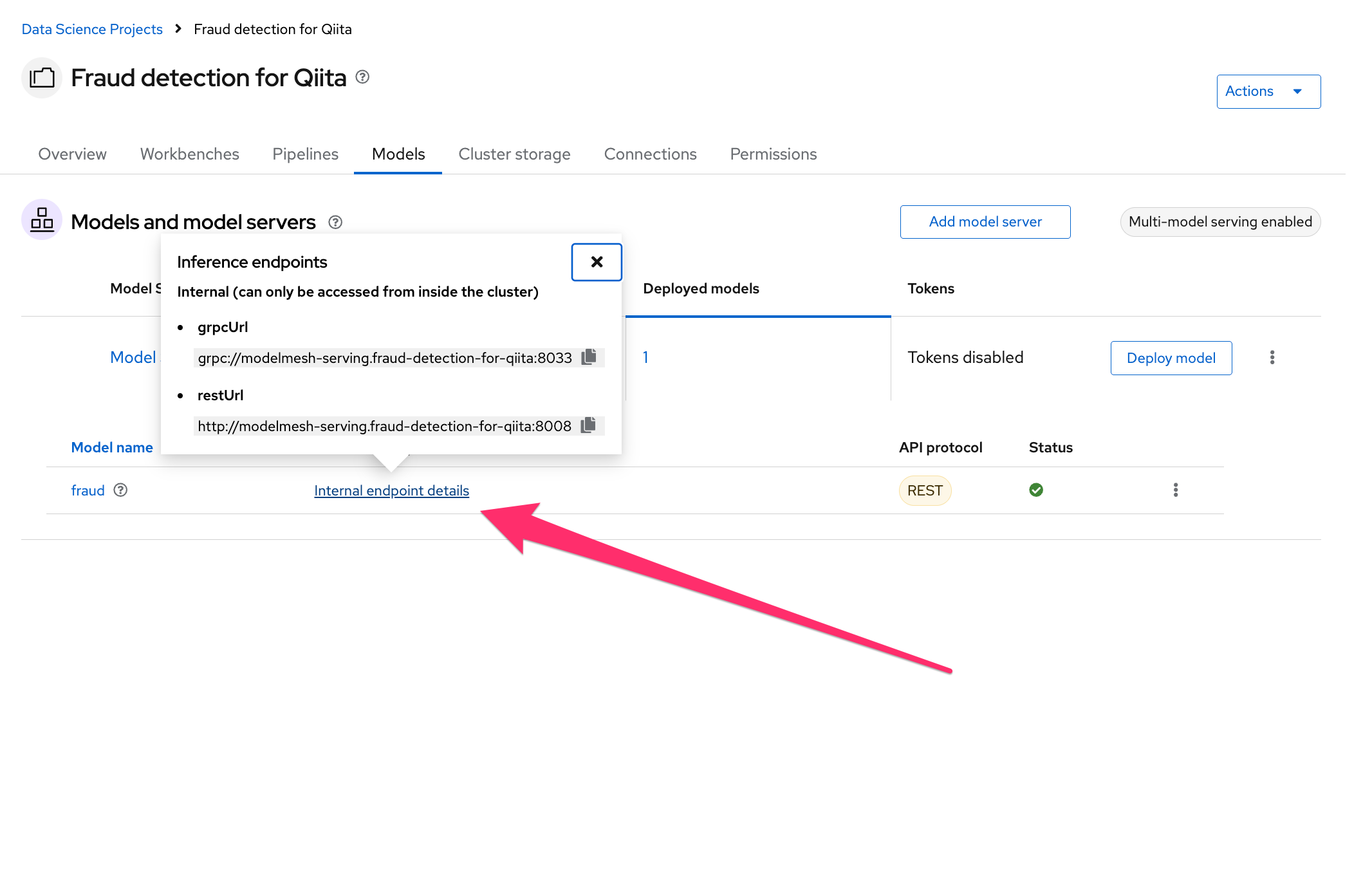
再びJupyterLab環境を開き、notebook"3_rest_requests_multi_model.ipynb"でREST API呼び出しを、notebook"4_grpc_requests_multi_model.ipynb"でgRPC API呼び出しを試行します。
コード内のrest_urlを、先ほど確認したrestUrlを見比べて、必要に応じて書き換えます。
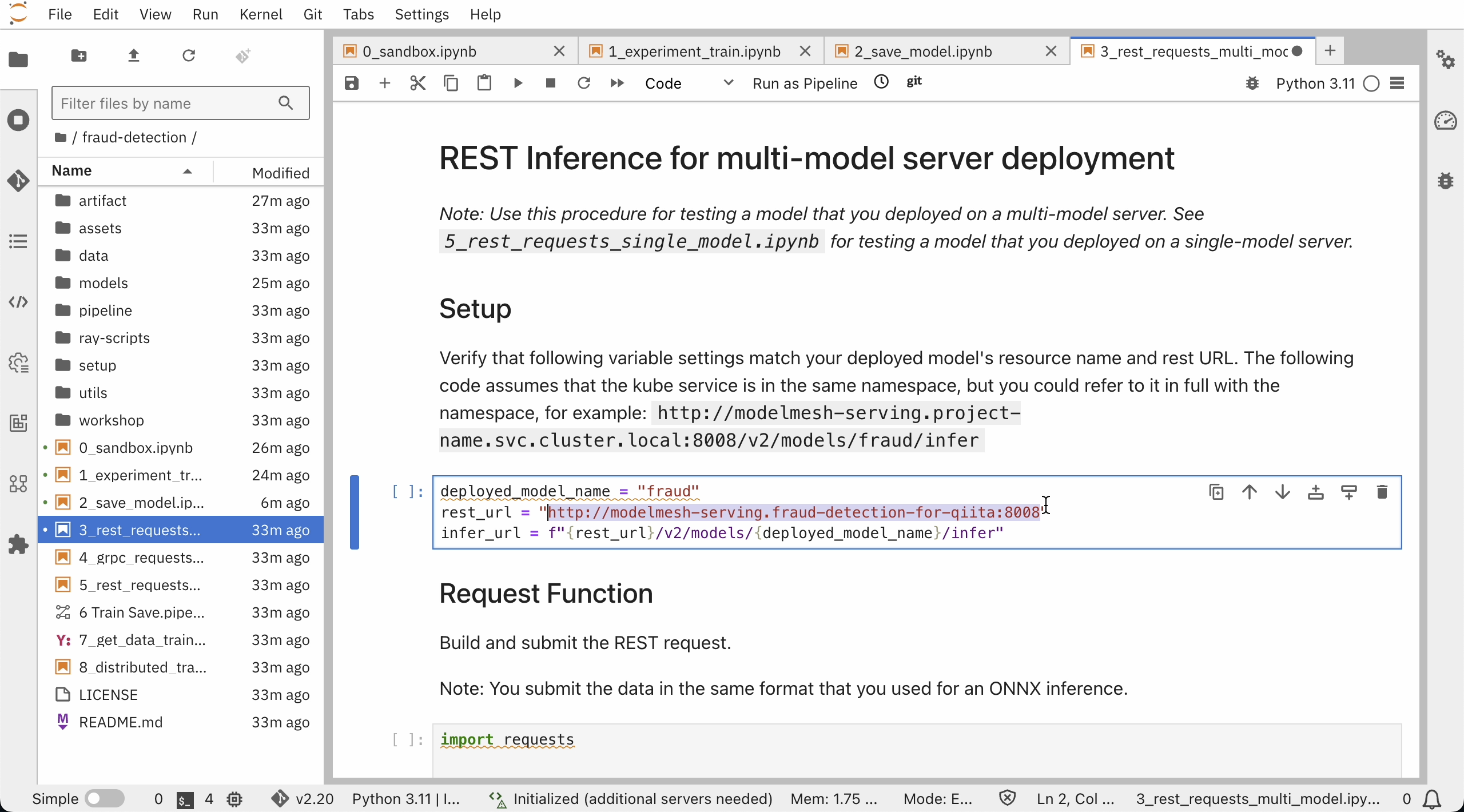
notebook3のコードを順に実行していきます。
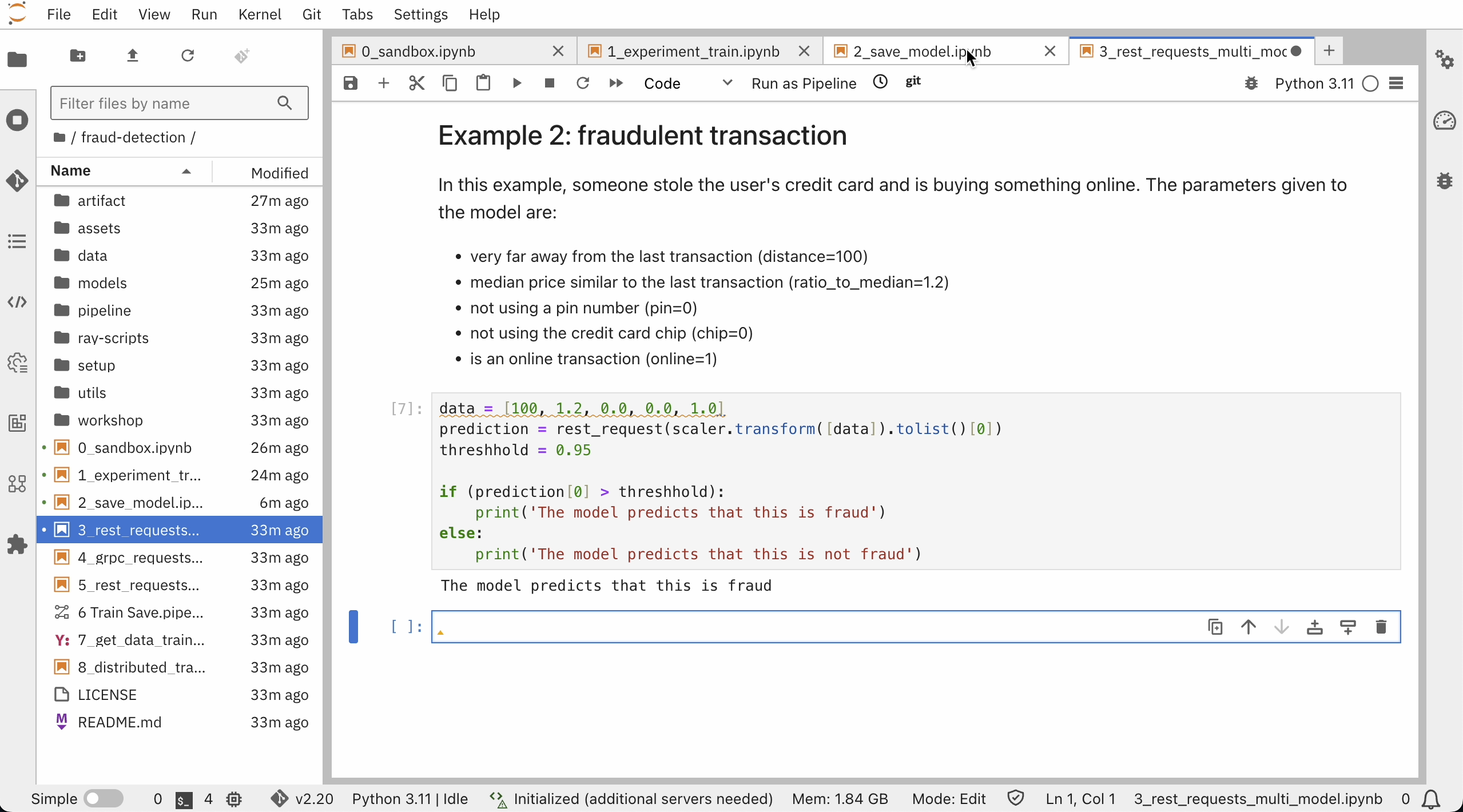
最後に、サンプルを実施してみます。
モデルが問題なく稼働しているようです。
grpcUrlも同様に確認しておきます。
9. パイプラインの実装
パイプラインを作成すると、複数のノートブックの実行を自動化することができます。パイプラインを使用することで、モデル開発の高速化とMLOpsを実現し、モデルの開発と運用をシームレスに統合できます。データサイエンティスト、エンジニア、アプリケーション開発者など、チーム全体で機械学習モデルの正確性と最新性を維持することができます。
今回は以下のnotebookを自動化するよう、パイプラインを作成します。
- notebook
"1_experiment_train.ipynb":モデルファイル"models/fraud/1/model.onnx"を作成 - notebook
"2_save_model.ipynb":モデルを S3 ストレージバケットにアップロード
Pipeline作成開始
"Pipeline Editor"を選択します。
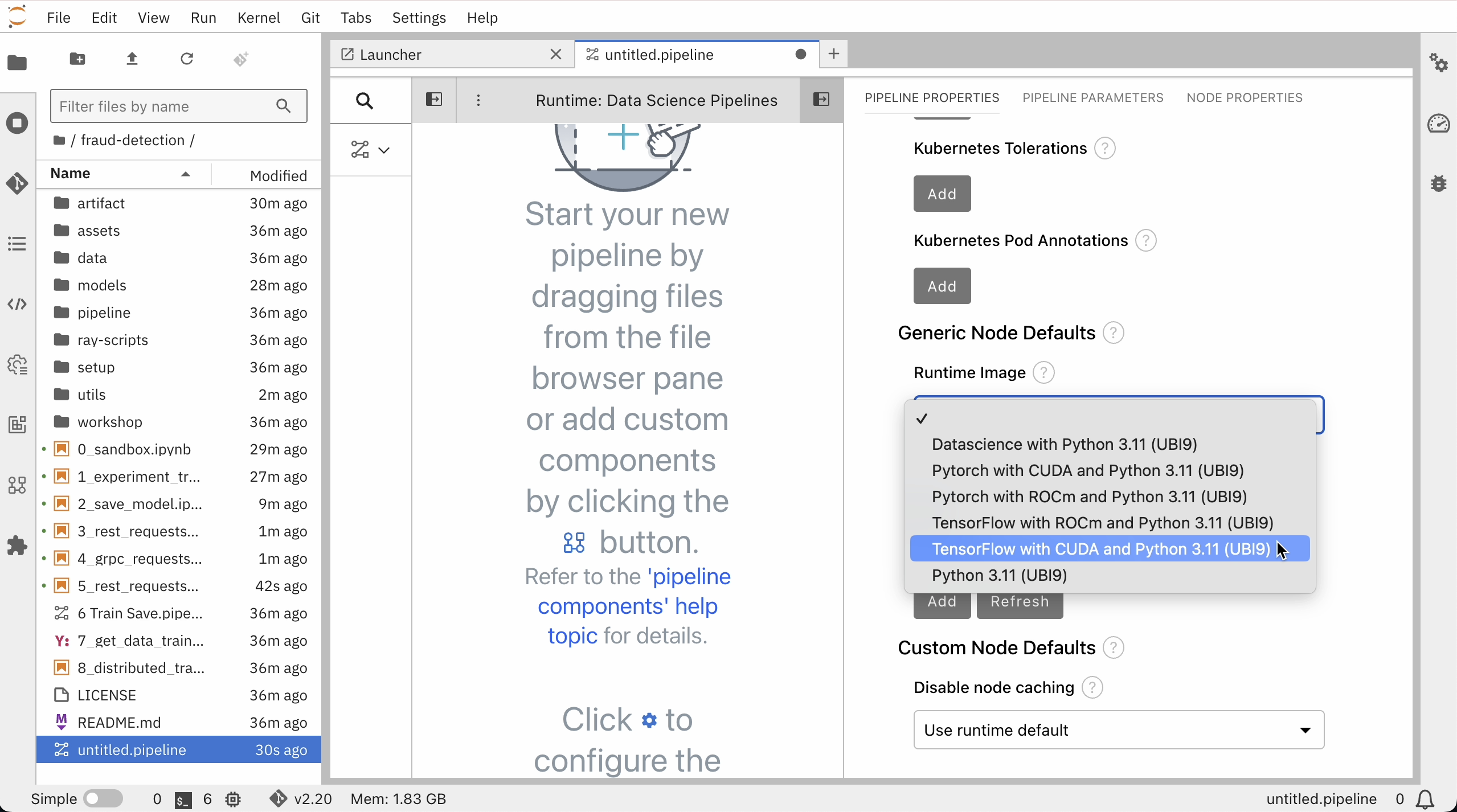
Pipeline Propertiesを開き、Generic Node DefaultsのRuntime Imageを"Tensorflow with Cuda and Python 3.11 (UBI 9)"に設定し、Save Pipelineをしておきます。
自動化したいnotebookをドラッグ&ドロップ
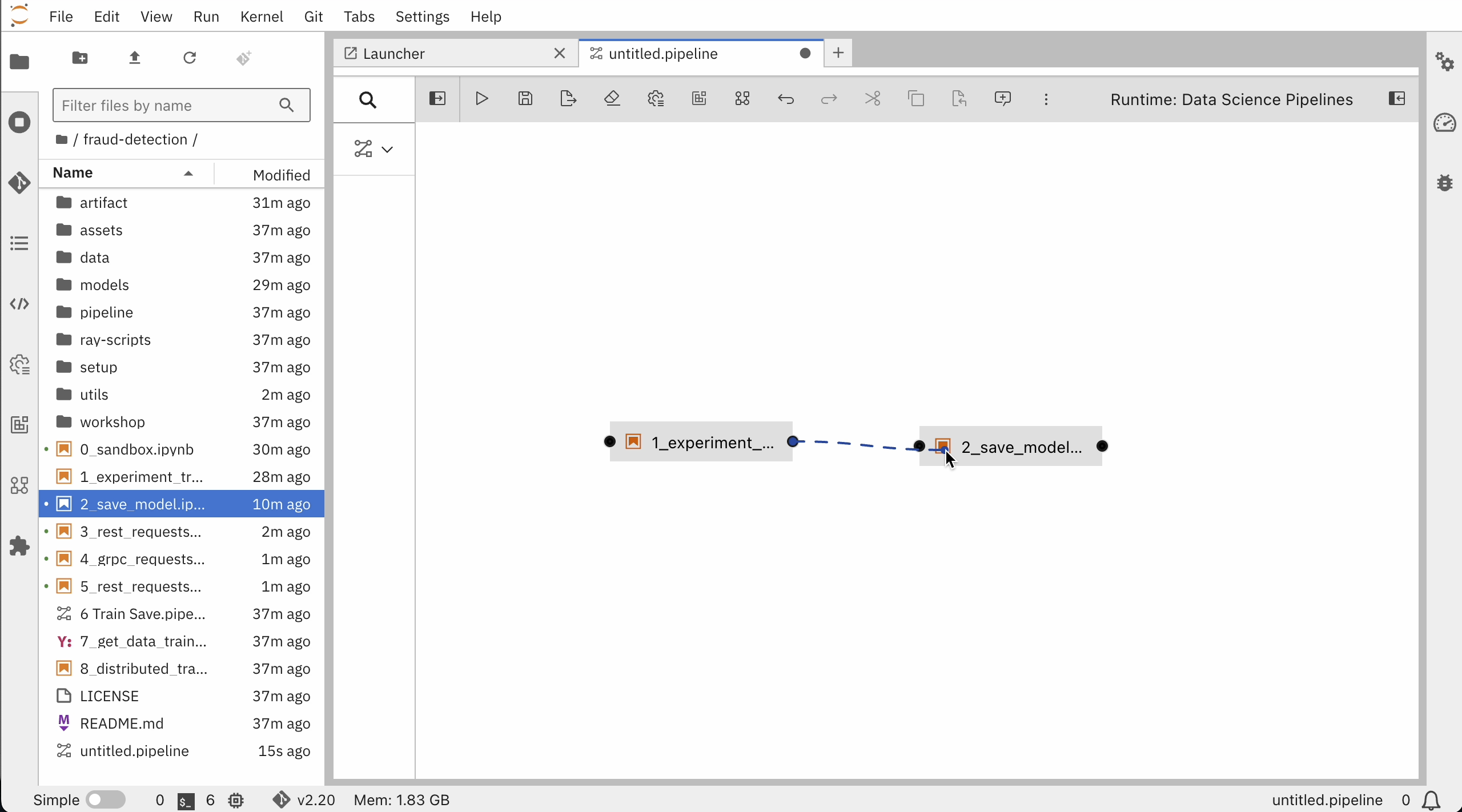
ノードのプロパティーを設定して、トレーニングファイルを依存関係として指定します。
ノード①"1_experiment_train.ipynb"の設定
- File Dependencies: モデルをトレーニングするためのデータが含まれる "data/*.csv"に値を設定→Include Subdirectories オプションを選択してSave Pipeline。
ノード①②の設定("1_experiment_train.ipynb", "2_save_model.ipynb")
- Node Properties: Output Filesセクションまで下にスクロールし、Addをクリック→値を"models/fraud/1/model.onnx"に設定。
ノード②"2_save_model.ipynb"の設定
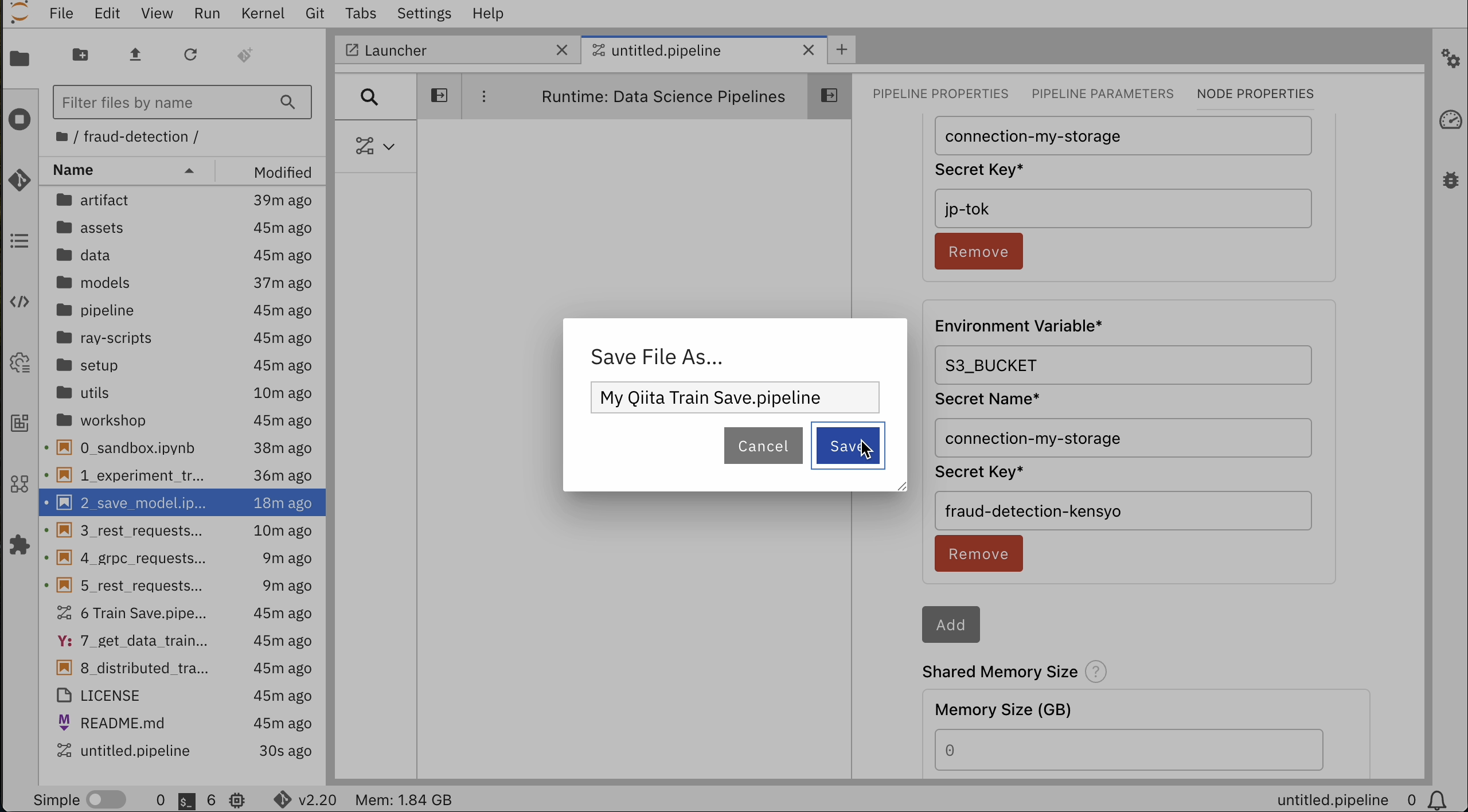
モデル保存先のs3互換オブジェクトストレージのシークレット情報を設定します。
- Node Properties タブを選択します。
Additional Propertiesに事前に入力されている環境変数を削除します。 - Kubernetes Secretsで、Add をクリックし、以下を入力します。
- 環境変数: ACCESS_KEY_ID
- シークレット名: my-storage
- シークレットキー: (ICOSシークレット情報を参照)
- 環境変数: SECRET_ACCESS_KEY
- シークレット名: my-storage
- シークレットキー: (ICOSシークレット情報を参照)
- 環境変数: S3_ENDPOINT
- シークレット名: my-storage
- シークレットキー: (ICOSエンドポイント"https://"は不要)
- 環境変数: DEFAULT_REGION
- シークレット名: my-storage
- シークレットキー: (ICOSバケットのあるリージョン:今回は
jp-tok) - 環境変数: S3_BUCKET
- シークレット名: my-storage
- シークレットキー: (ICOSバケット名)
パイプライン実行
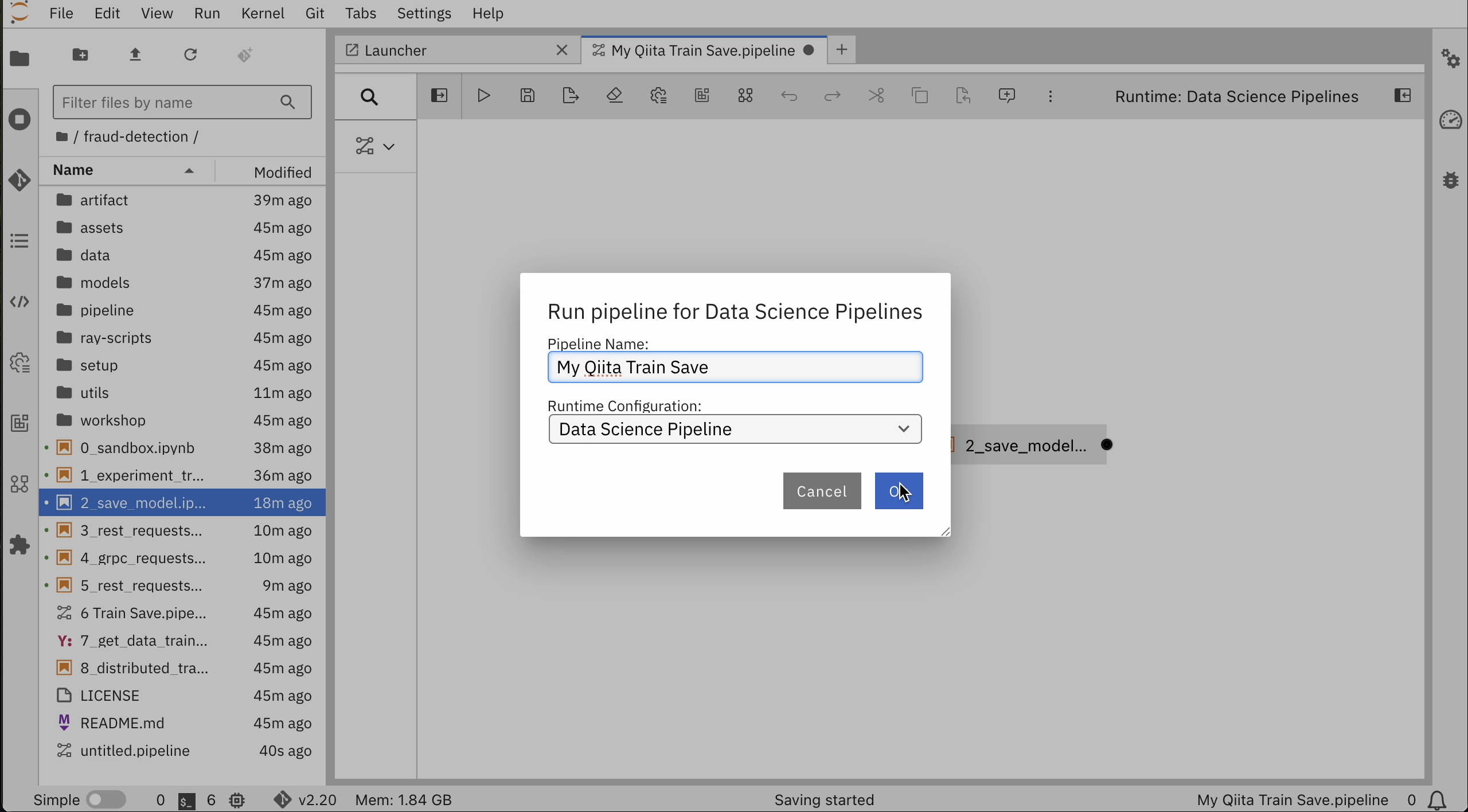
ここまで各ノードの設定ができたら、File → Save Pipeline Asを選択してPipelineに名前をつけて保存します。今回は "My Qiita Train Save.pipeline"として保存しました。
実行をクリックし、Runtime ConfigurationがData Science Pipelineに設定されていることを確認し、OKを押します。
パイプライン実行できたようです。
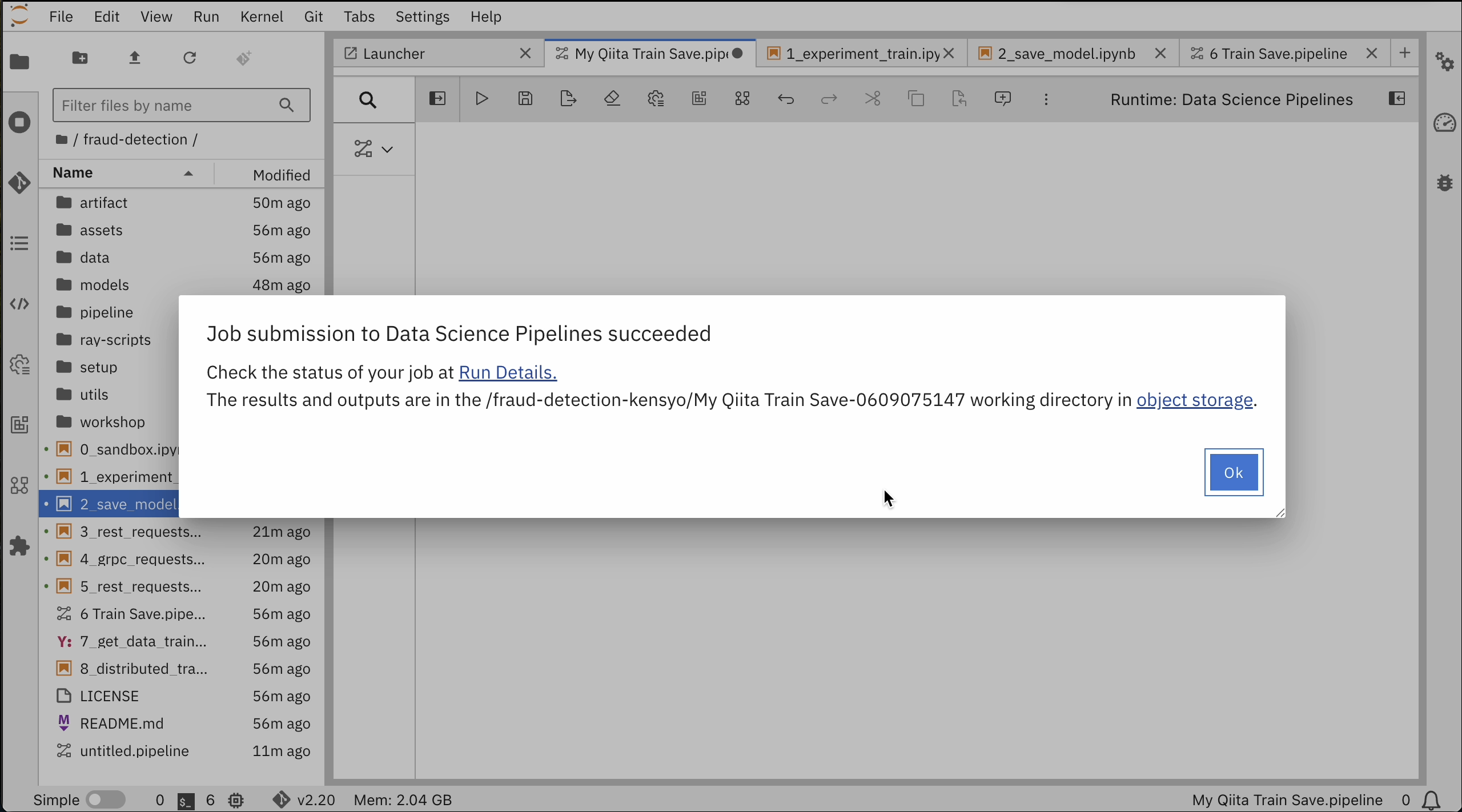
このとき、ICOSバケットにmodels/fraud/1/model.onnxファイルが保存されています。
GUIでもパイプラインが作成、実行を確認できます。
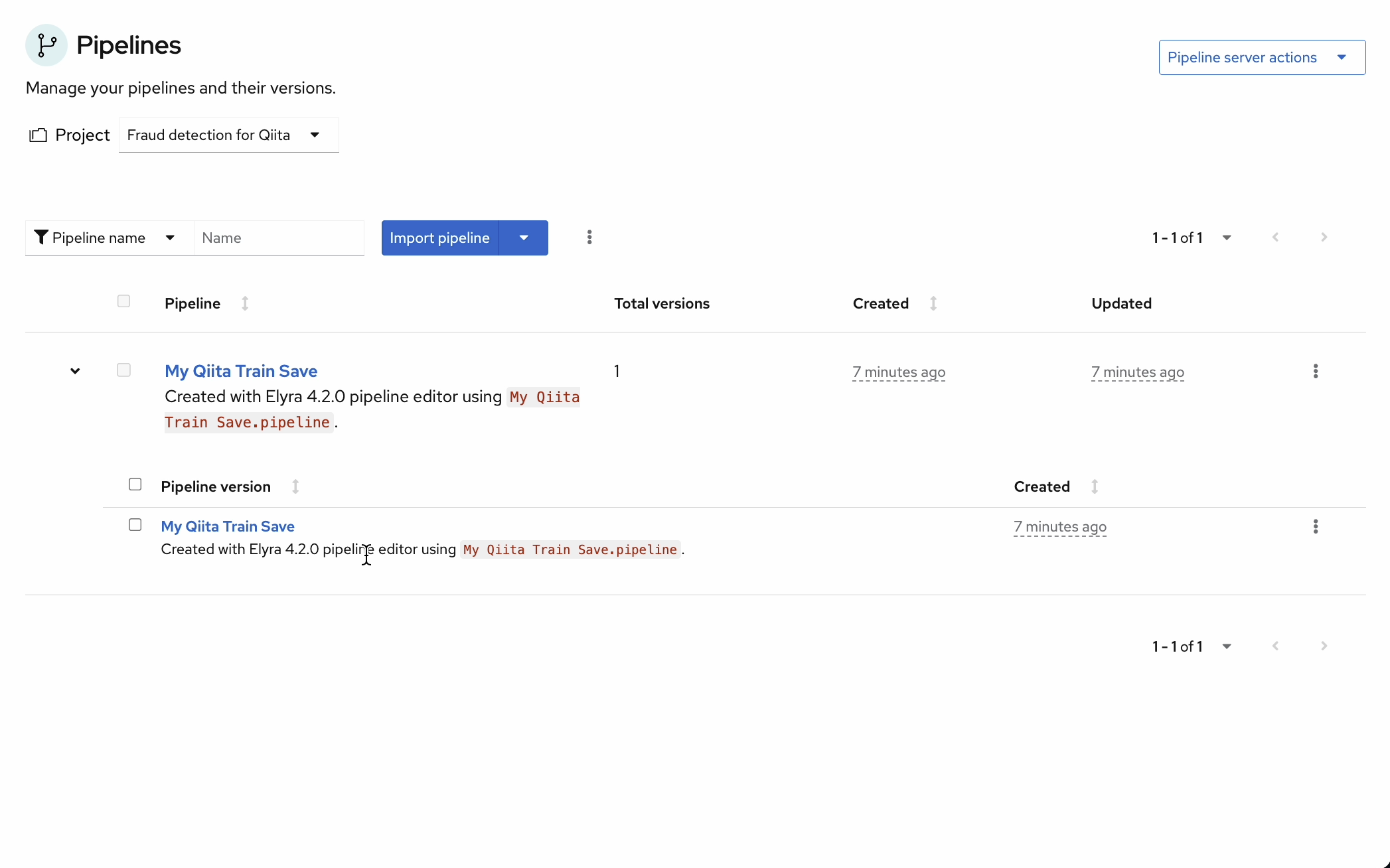
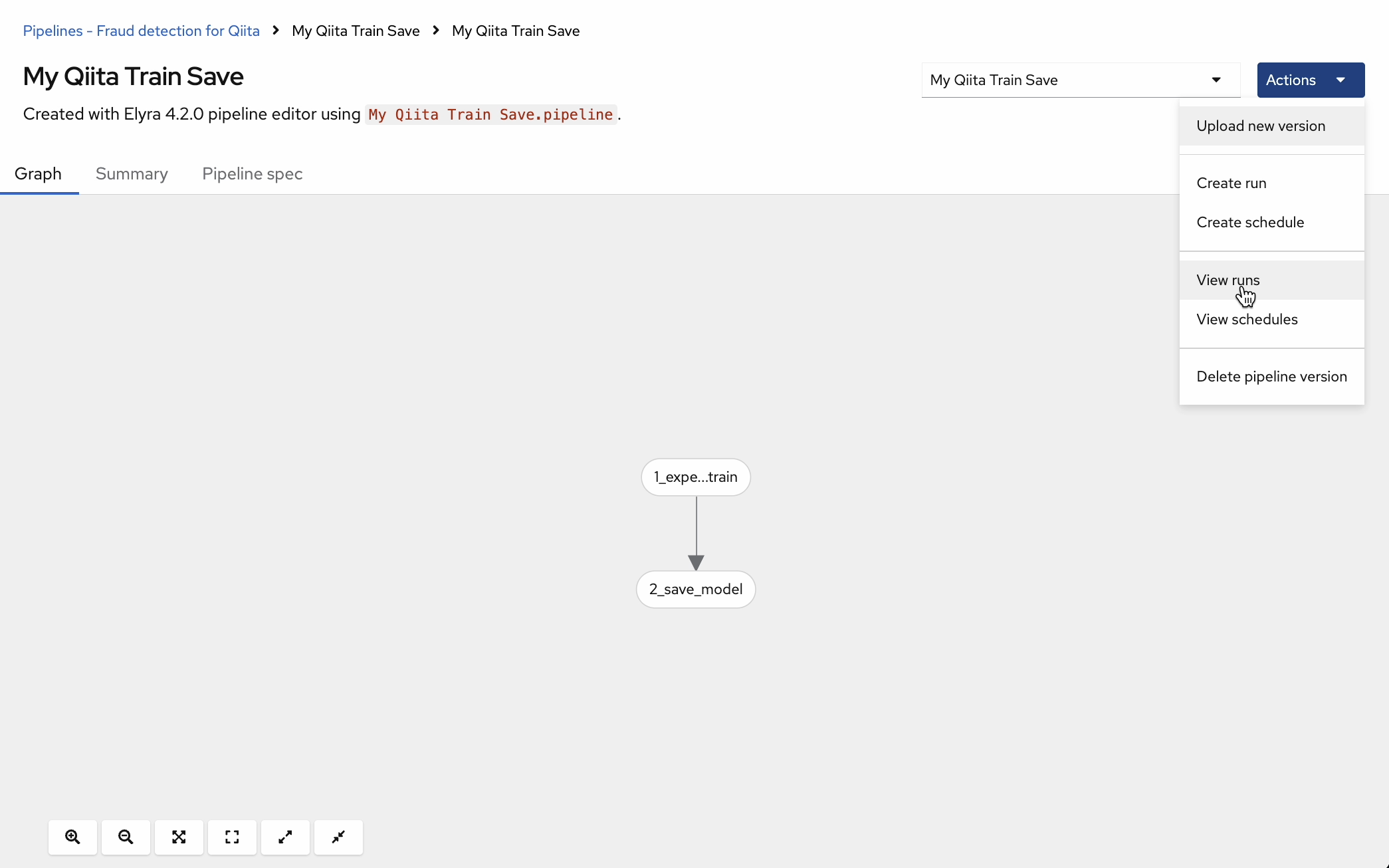
"View run"から実行できます。
最後に
今回Red Hat OpenShift AIを触ってみて、以下がポイントだと感じました。
- 単一のプラットフォームでモデルやデータを管理することができる
- モデルサービング機能を活用することで、RestAPIでAIモデルを呼び出すことが可能になり、OpenShiftの上でAIモデルをアプリと同じように動かしたり管理したりすることができる
- パイプラインを活用することで、モデル開発の高速化とMLOpsを実現できる
- OpenShiftの機能で高可用性の構成が取れる
- Red Hatにより検証済みのサードパーティ製品が統合されている