はじめに
本記事ではSNIA(Storage Networking Industry Association)の以下のプレゼンテーション発表の内容について記載します。
-
Storage Requirements for AI
- Compute, Memory, and Storage Summit 2024にて発表されたもの
※自分向けメモとして雑多に書いています。そのため内容を簡潔にまとめるということは出来ていませんので、読みづらいかもしれませんがご了承ください。
※この記事内の画像はすべて公開済みの上記プレゼンテーション資料より引用したものです。
概要
- GPUが脚光を浴びることが多い一方で、AIインフラにおいてストレージが果たす重要な役割を認識することが不可欠である
- データの準備から事前学習、微調整、チェックポイント、推論に至るまで、AIのライフサイクル全体を通じて、ストレージは極めて重要である
- 本プレゼンテーションでは、具体例を用いてこれらの各段階を掘り下げ、特にパフォーマンスに関連する重要な要件を特定する
背景
- 現代のDeep Learningでは何百万もの行列演算が必要となる
- これらの計算を合理的な時間内に行うには並列処理が必須である
- 並列処理のためGPUの需要が高まっており取り合い状態になっている
- AIデータセンターではGPUの利用率を最大化することが求められる
AIのライフサイクル
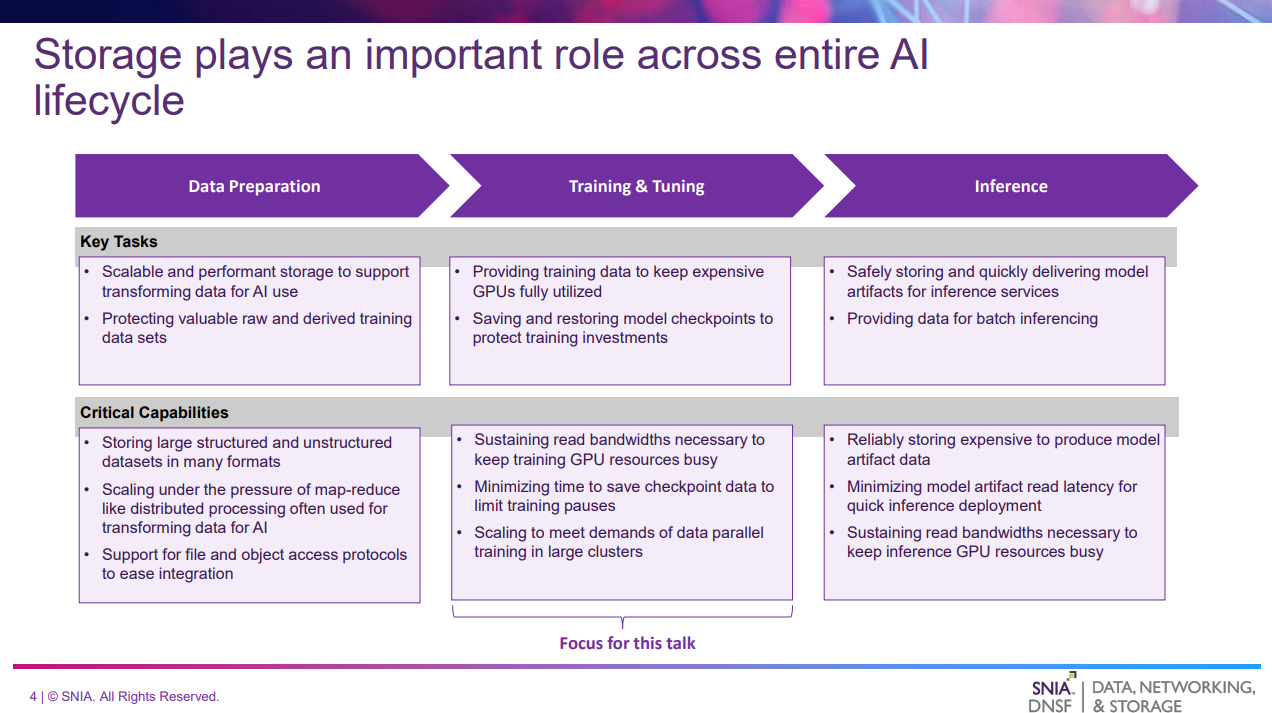
このスライドでは、AIのライフサイクルを以下の3つのフェーズに分類し、それぞれのタスクおよびストレージに求められる要件について述べている。
- Data Preparation
- 生データを分散処理フレームワークなどによってAIモデルに適した形式に変換する
- オープンデータ形式で構造化データと非構造化データを保存し、パフォーマンスの高いアクセスを提供することが重要である
- Training & Tuning
- GPUに学習データを供給し続けるための高いRead帯域幅が必要となる
- 学習中にモデルのチェックポイントを素早く保存するための高いWrite帯域幅が必要となる
- Inference
- ストレージからモデルデータを素早く読み取る必要がある
- バッチ推論の場合はGPUにデータを供給し続けるための高いRead帯域幅が必要となる
本プレゼンテーションでは、Training & Tuningを中心に説明する。
Training & Tuning の概要
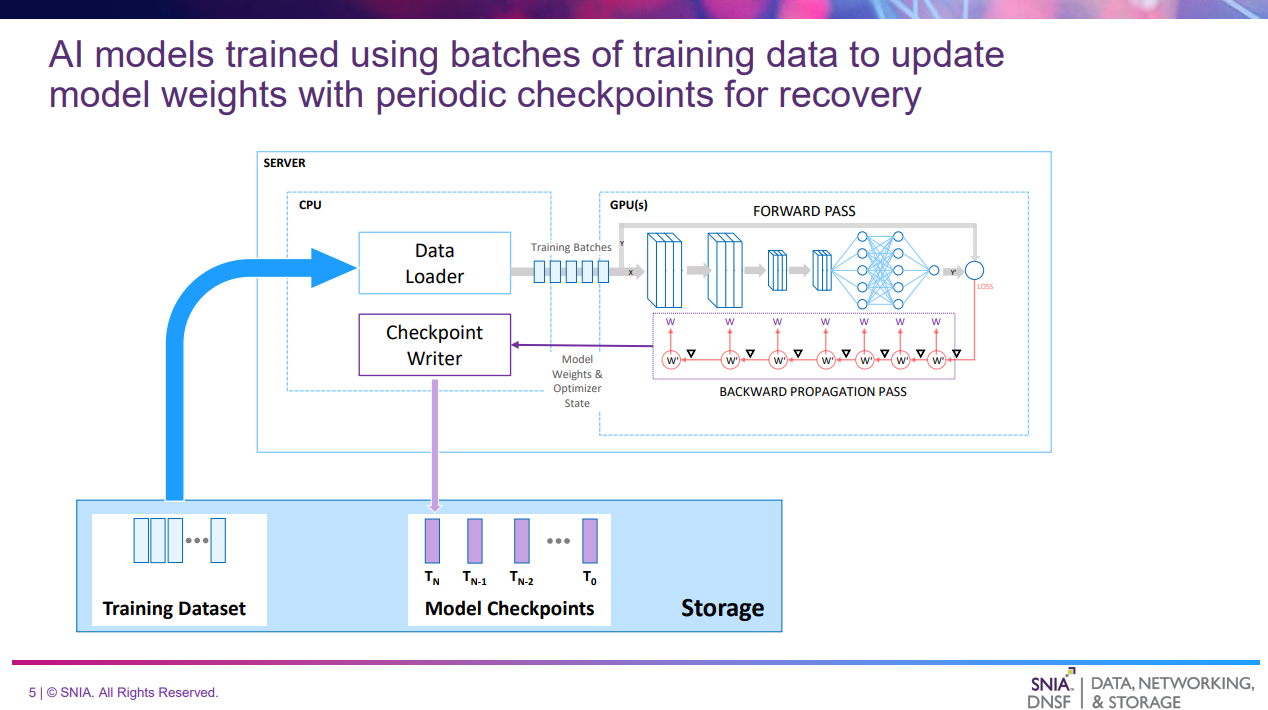
このスライドでは、Training & Tuningについてどのような処理が行われるかを解説している。
- 学習データはストレージから読み込まれ、比較的少数のランダム化されたバッチにパッケージングされる
- バッチを使ってモデルに推論させた結果と正解データを比較して損失スコアを計算する
- スコアをもとにモデルの重み(パラメータ)を調整することでモデルの精度を上げていく
- モデルが安定した精度に収束するまで繰り返す
- 障害に備えて定期的にチェックポイントを保存する
Training & Tuningに必要なストレージのRead性能要件
Training & Tuningについてストレージに求められる性能要件を解説する。
- GPUの利用率を最大化することが目的の場合、GPUベンチマークを使用して様々なモデルに必要なピークパフォーマンスから、それを維持するために必要なストレージのRead性能を逆算することが合理的なアプローチである
- ベンチマークはMLCommonsやMLPerf Trainingを使うのが最適
NVIDIA H100 80GB GPUを例として、各モデルのベンチマークから算出した必要となるストレージのRead帯域幅は以下である。
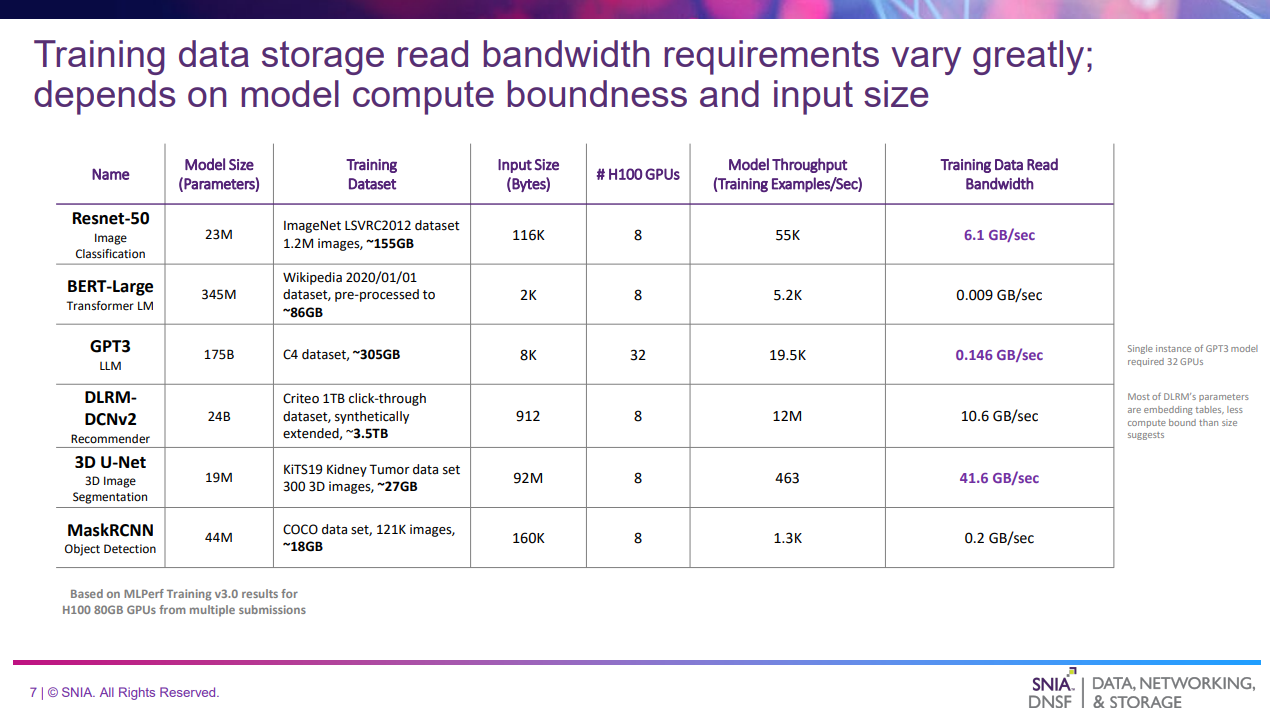
| 列 | 意味 |
|---|---|
| Name | モデル名 |
| Model Size | モデルサイズ(パラメータ数) |
| Training Dataset | 学習データセットの詳細 |
| Input Size | 各学習データサンプルのサイズ |
| # H100 GPUs | GPU数 |
| Model Throughput | 1秒間に学習できたデータ量 |
| Training Data Read BandWidth | Model Throughputを維持するのに必要なRead帯域幅 |
- モデルによって様々だが40GB/s以上のRead帯域幅が必要になるケースもある
- 必ずしもパラメータ数が大きいモデルがストレージ性能要件も高いとは限らない(Input Sizeの方が影響する)
I/Oパターンはアクセスするストレージによって変わる。
例として、Resnet50というモデルに対し、DLIOベンチマークを実行した際のI/OをトレースすることでどのようなI/Oアクセスを行っているかを解析した結果を示す。(NFSとS3で実施)
Resnet50はディープニューラルネットワークのトレーニングに関連する課題に対処するために設計された一連のモデル(よくわかっていない)。
DLIOはGPUをエミュレートするAIストレージベンチマークであり、以下のような特徴がある。
- GPU不要でストレージパフォーマンスを測定可能
- 学習データセットは1024~150KBのイメージテンソルを含むTFRecord
- 学習データはTensorflowのデータローダを使用して読み込まれる
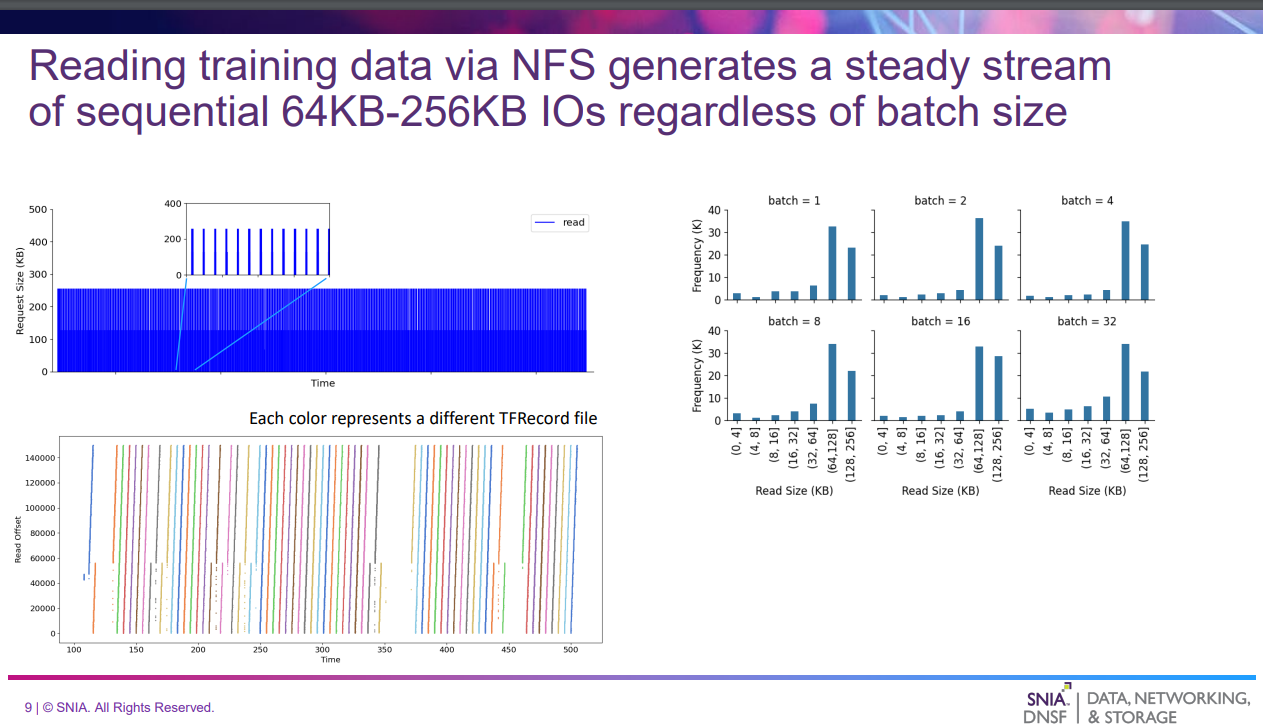
- NFSで実施した結果
- 左上は64KB-256KBの安定したIOストリームを示す
- 右側はバッチ当たりの学習データ数が変化してもIOサイズの分布は変化していないことを示す
- 左下はデータが順番に読まれている(シーケンシャルReadである)ことを示している
- GPUを最大限活用するには、64~256KBのIOシーケンシャルReadに対して、6.1GB/sのRead帯域幅を達成する必要がある(6.1GB/sは前のベンチマークの結果から)
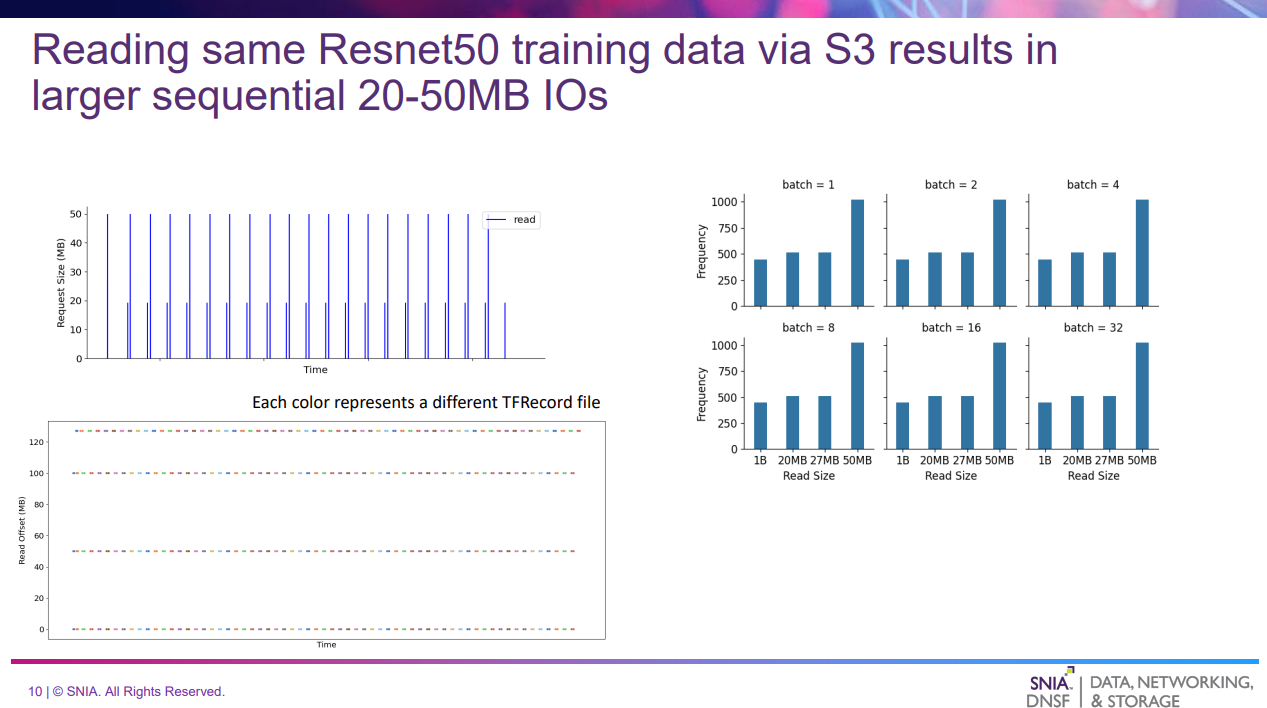
- S3で実施した場合
- 左上は20~50MBの大きなIOが発生していることを示す
- 右側はNFS同様
- 左下はランダムアクセスであることを示している
利用するストレージによってアクセスパターンが変わるため、AIストレージは多様なアクセスパターンに対して高いRead帯域幅を確保する必要がある。
チェックポイント書き出しの概要
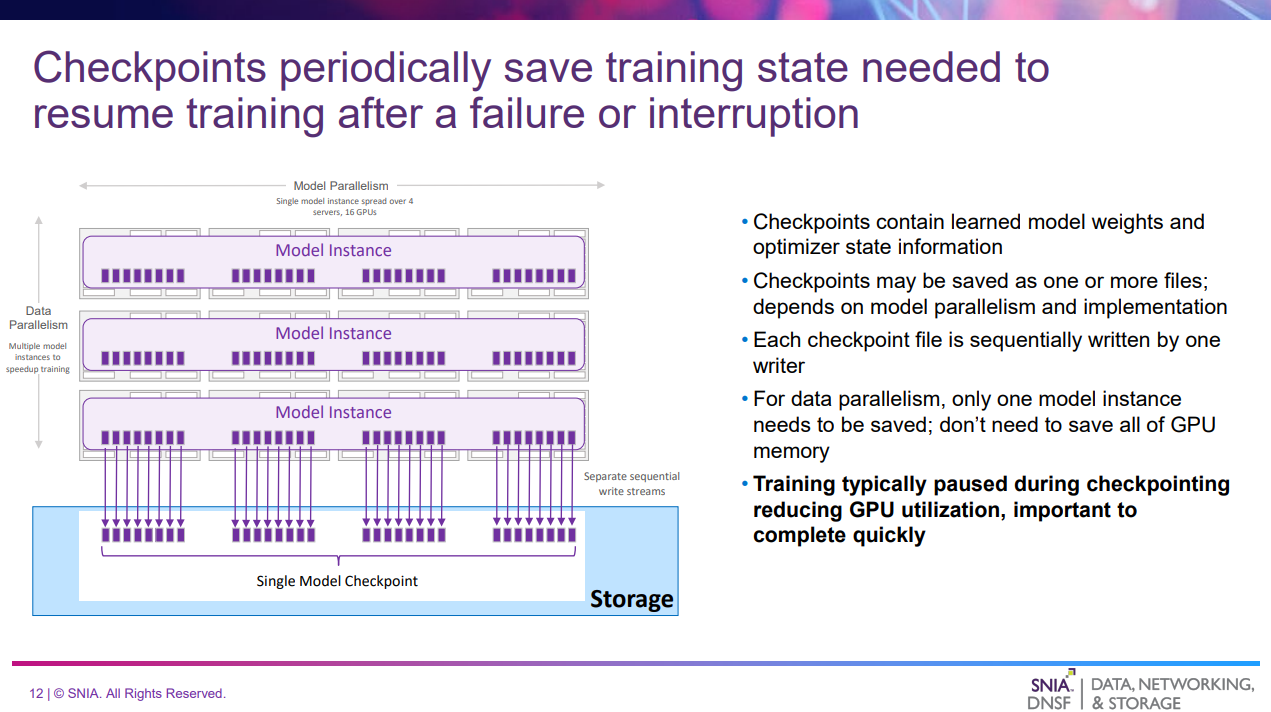
このスライドでは、Training & Tuningのチェックポイントの書き出しについて解説している。
- 大規模なAIモデル学習には数日~数週間かかる場合がある
- その間、学習データが処理されるにつれてモデルの重みは常に変化する
- 定期的に永続的なストレージにチェックポイントとして保存することでデータ損失を防ぐ
- チェックポイントは通常、1つ以上のファイルとして保存され、それぞれが単一のライターによって順番に書き込まれる
- 学習は通常、チェックポイント中に一時停止され、GPUの使用率が低下するため、チェックポイントの書き出しは迅速に完了することが重要
チェックポイント書き出しに必要なWrite帯域幅の推定
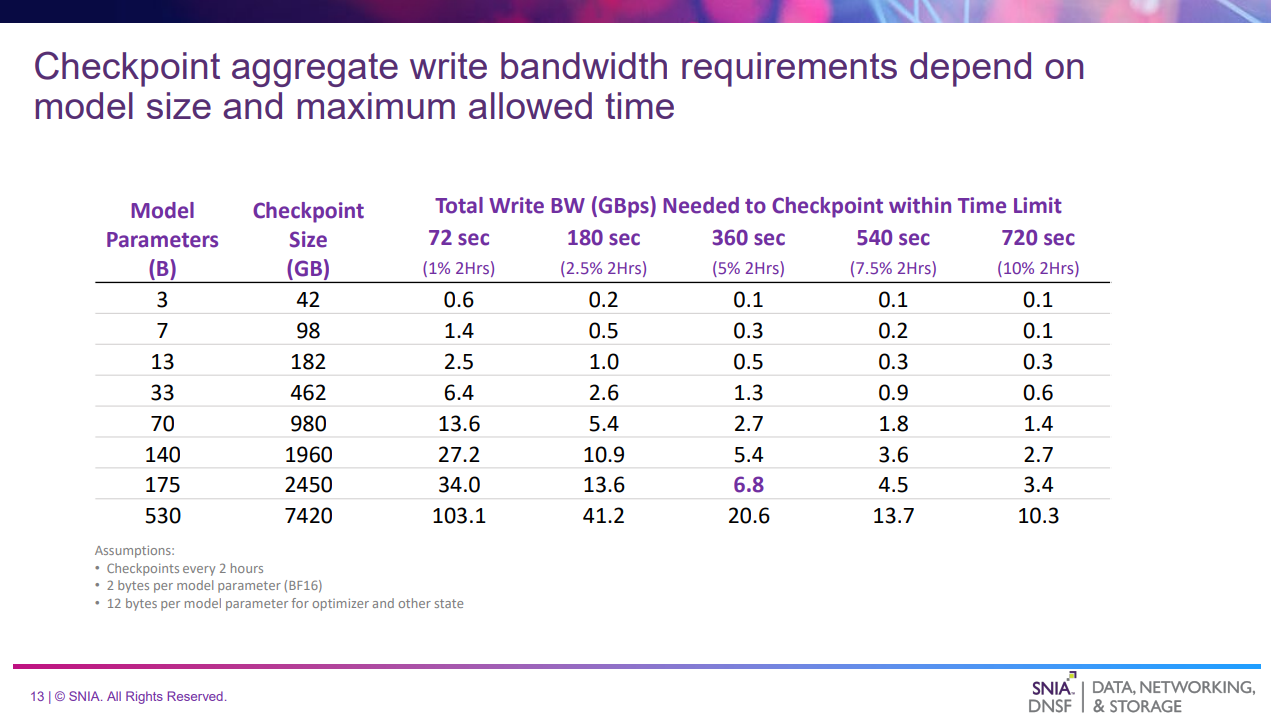
| 列 | 意味 |
|---|---|
| Model Parameters | モデルパラメータ数 |
| Checkpoint Size | チェックポイントの容量(1パラメータあたり14バイトで推定) |
| Total Write BW (GBps) Needed to Checkpoint within Time Limit | 制限時間内に書き出しが完了するために必要なWrite帯域幅 |
- モデルパラメータ数と、何分以内に書き出す必要があるかによって異なる
- 例:175Bのパラメータの場合2450GBのチェックポイントの書き出しが発生、これが360秒(2時間のうちの5%)で書き出す場合は6.8GB/sの帯域幅が必要
チェックポイントのリストア
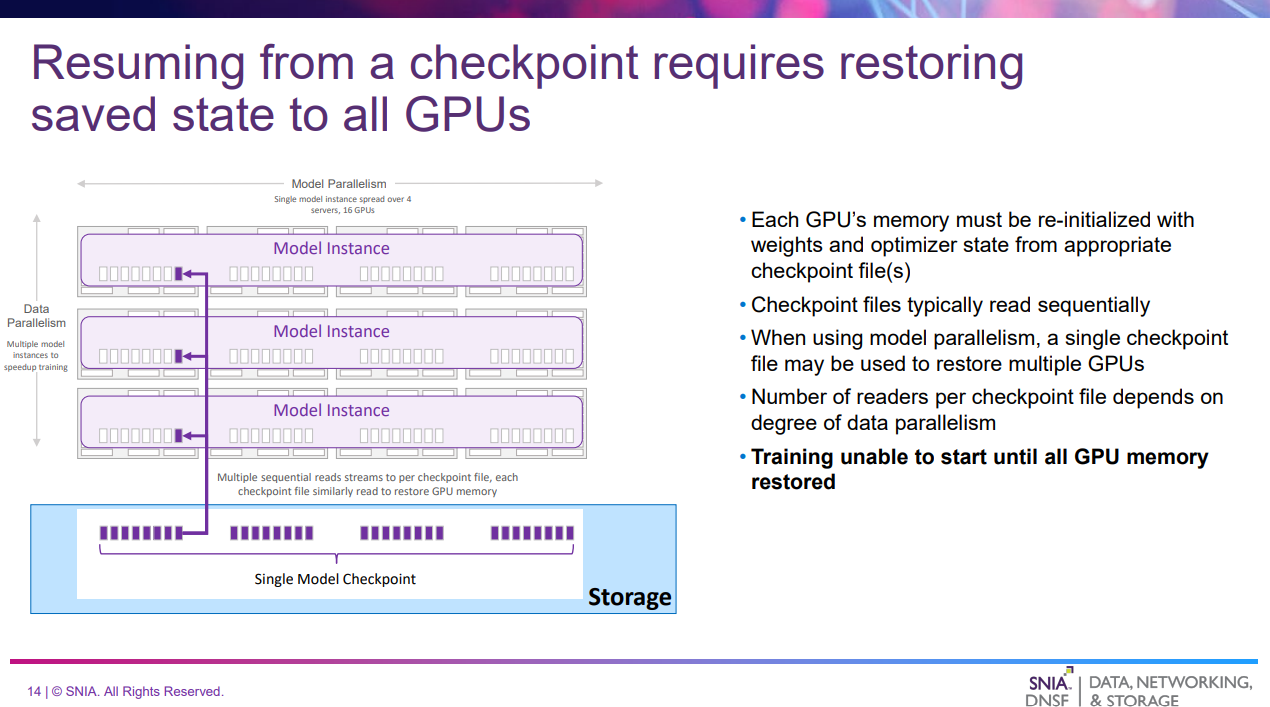
このスライドでは、Training & Tuningのチェックポイントのリストアについて解説している。
- 1つのチェックポイントが例えば3つのGPUでロードされ、モデルの同じ部分を保持する
- チェックポイントファイルは通常複数のGPUに並列で読み取られる
- チェックポイントがすべてのGPUに復元されるまでモデルのトレーニングを再開できない
チェックポイントのリストアに必要なRead帯域幅の推定
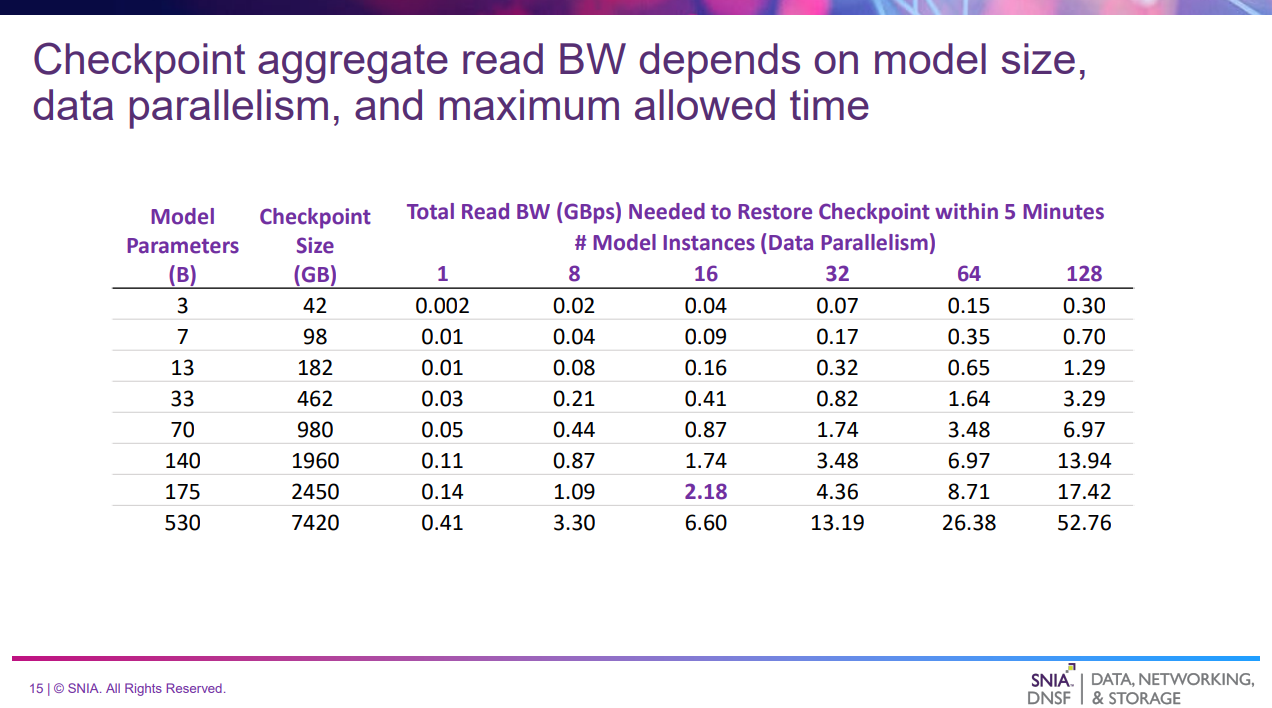
| 列 | 意味 |
|---|---|
| Model Parameters | モデルパラメータ数 |
| Checkpoint Size | チェックポイントの容量(1パラメータあたり14バイトで推定) |
| Total Read BW (GBps) Needed to Restore Checkpoint within 5 Minutes | 5分以内にリストアが完了するために必要なRead帯域幅 |
- 例:175Bのモデルを16のGPUに5分以内にロードする場合、2.18GB/sのRead帯域幅が必要
GPUクラスタとストレージ
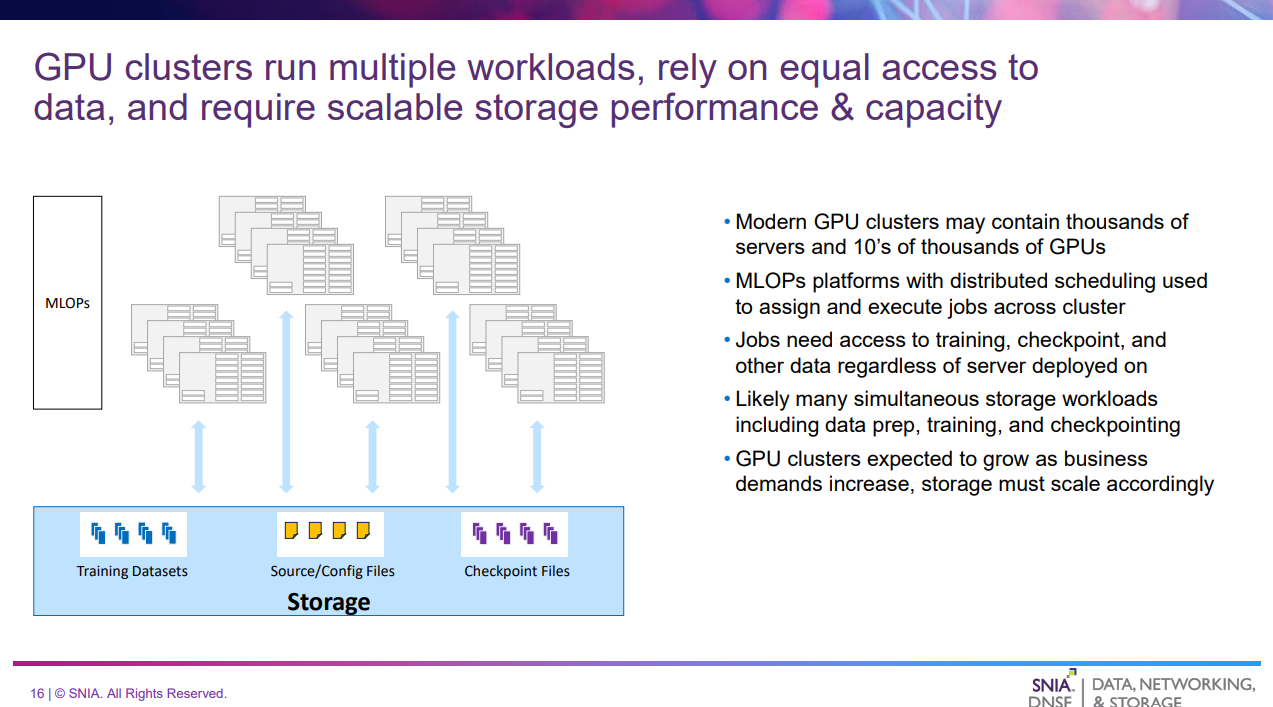
このスライドでは、GPUクラスタを考えた場合に必要となるストレージについて述べている。
- これまでは単一サーバ・単一モデルの場合を考えてきた
- 現実的には、GPUクラスタではAIライフサイクルの様々な段階の、多数のAIワークロードをホストしている可能性がある
- 分散スケジューラがクラスタ内のサーバにジョブを割り当てるため、どこに配置されるか関係なく平等にデータアクセスできる必要がある
- 単一のNameSpaceから、AIアクセスパターンが大きく異なる複数のワークロードのパフォーマンスニーズを満たす必要がある、かつスケールアウトできることがストレージとして求められる
まとめ
- ストレージはAIライフサイクルのすべてに関与し、要件はライフサイクルの各段階で異なる
- 適切なAIストレージソリューションを選択するには、予想されるワークロードやサービスが求める要件を洞察することが必要である