1. はじめに
近年、社内AIエージェントや自然言語で操作可能な分析ツールが注目されています。
代表例として、メルカリの Socratesや、海外企業でも社内業務効率化を目的としたAIエージェント導入が進んでいます。
こうした動きの背景には以下のような潮流があります。
- データドリブン経営の推進:現場担当者が自らデータを引き出し意思決定に活用する必要性が増している
- ノーコード・セルフサービスBIの需要増:非エンジニアでもデータ分析できる環境が競争力に直結する
本記事では、この潮流を踏まえ、自作で簡易的なデータ自動分析アプリを構築し、実際に何ができるのか・どこに課題があるのかを整理します。
実装した技術は以下です。
- LangGraph+LLMでSQLを自動生成
- FastAPIでバックエンドを構築
- Streamlitでグラフ可視化とインサイト表示
なお今回は、ERPのオープンソースであるOdooのスキーマデータをデータに使っています。
(テストデータは全て生成AIで生成したものです。)
2. アーキテクチャ概要
今回構築したアーキテクチャの全体像は以下です。
ユーザー(自然言語クエリ入力)
↓
[ Streamlit ]
↓ API呼び出し
[ FastAPI + LangGraph Workflow ]
├─(1) LLMがSQL生成
├─(2) SQLiteへクエリ実行
├─(3) LLMが最適なグラフメタ情報生成
└─(4) LLMがインサイト生成
↓
[ Streamlit ]
├─ データテーブル表示
├─ グラフ描画
└─ インサイトテキスト表示
ディレクトリ構成(主要部分):
├───docker-compose.yml
│
├───api/
│ ├───Dockerfile
│ ├───requirements.txt
│ ├───main.py # FastAPIアプリのエントリポイント。ルーターを読み込む。
│ ├───router.py # APIエンドポイント(/analyze など)の定義。
│ ├───models.py # PydanticモデルとAgentStateの定義。
│ ├───llm.py # LLMの初期化ロジック。
│ ├───db.py # データベース接続ロジック。
│ ├───graph.py # LangGraphのノードとワークフローの定義。
│
├───app/
│ ├───Dockerfile
│ ├───requirements.txt
│ ├───main.py # Streamlitアプリのエントリポイント。UIコンポーネントを呼び出す。
│ ├───api_client.py # バックエンドAPIと通信するためのクライアント関数。
│ └───ui_components.py # Streamlitの各UIセクションを定義。
│
└───data/
├───odoo_schema.json # DBのメタデータを管理
└───odoo_test_data_v2.db # 実際のデータ(SQLiteを利用)
3. 実装のポイント – SQL生成からグラフ可視化までの自動化フロー
3.1 SQL生成(LangGraphノード:generate_sql)
LangGraphで定義するノード例です。
ポイントは、毎回Odooスキーマ(odoo_schema.json)をLLMに渡している点です。
# api/graph.py(一部抜粋)
import json
from langgraph.graph import StateGraph, END
from .models import AgentState
from .llm import get_llm
from .db import fetch_data
def node_generate_sql(state: AgentState) -> AgentState:
"""自然言語からSQLを生成するノード"""
print("Executing node: generate_sql")
user_query = state["user_query"]
# スキーマ情報を読み込み
with open("data/odoo_schema.json", "r") as f:
schema = json.load(f)
schema_str = json.dumps(schema, indent=2, ensure_ascii=False)
llm = get_llm()
prompt = f"""
以下のデータベーススキーマ情報を参考にして、ユーザーの要求を満たすSQLクエリを生成してください。
SQLクエリのみを返し、説明は一切含めないでください。
## スキーマ情報
{schema_str}
## ユーザーの要求
{user_query}
## SQL
"""
response = llm.invoke(prompt)
raw_sql = response.content.strip()
cleaned_sql = (
raw_sql.removeprefix("```sql")
.removesuffix("```")
.strip()
)
print(f"Generated SQL: {cleaned_sql}")
state["sql"] = cleaned_sql
return state
def node_execute_sql(state: AgentState) -> AgentState:
"""生成したSQLをSQLiteで実行"""
print("Executing node: execute_sql")
df = fetch_data(state["sql"])
state["df"] = df
return state
SQL生成例
自然言語入力:
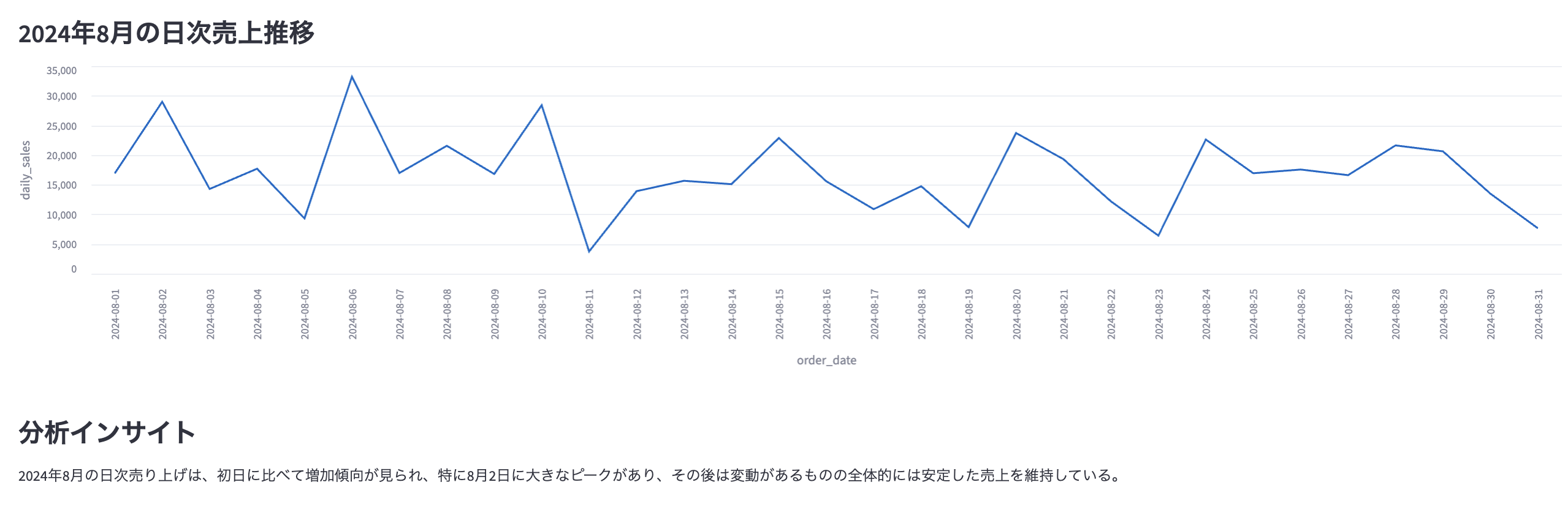
「2024年8月の日次売上推移を教えて」
LLM出力(SQL):
SELECT DATE(date_order) as order_date, SUM(amount_total) as daily_sales
FROM sale_order
WHERE strftime('%Y-%m', date_order) = '2024-08'
GROUP BY DATE(date_order)
ORDER BY order_date;
実際に上記SQLが自動生成されました。
3.2 グラフメタデータ生成(generate_graph_metadata)
グラフ推奨は、型(line / bar / scatter)を固定し、パラメータ(X軸、Y軸、タイトル)だけLLMに生成させる設計としています。
def node_generate_graph_metadata(state: AgentState) -> AgentState:
"""グラフ描画に必要なメタデータを生成"""
print("Executing node: generate_graph_metadata")
df = state["df"]
if df.empty:
state["graph_metadata"] = {
"type": "none",
"message": "データがありません。"
}
return state
df_info = f"Columns: {df.columns.tolist()}\nSample:\n{df.head().to_markdown(index=False)}"
llm = get_llm()
prompt = f"""
以下のデータフレーム情報に基づき、グラフ描画に必要なJSONを生成してください。
型は line / bar / scatter のいずれかを選んでください。
## DataFrame
{df_info}
## JSON形式
{{"type": "line", "x_col": "date", "y_col": "sales", "title": "日別売上推移"}}
"""
response = llm.invoke(prompt)
state["graph_metadata"] = json.loads(response.content.strip())
return state
生成されるメタデータ例
{
"type": "line",
"x_col": "order_date",
"y_col": "daily_sales",
"title": "2024年8月の日次売上推移"
}
3.3 インサイト生成(generate_insights)
簡易的ですが、DataFrameの先頭データを渡し、LLMに要約させるだけです。
def node_generate_insights(state: AgentState) -> AgentState:
"""データから傾向を要約"""
print("Executing node: generate_insights")
df = state["df"]
if df.empty:
state["insights_text"] = "データがありません。"
return state
df_info = f"Columns: {df.columns.tolist()}\nSample:\n{df.head().to_markdown(index=False)}"
llm = get_llm()
prompt = f"""
以下のデータから読み取れる傾向を日本語で簡潔にまとめてください。
説明は不要、インサイトのみを書いてください。
## DataFrame
{df_info}
## インサイト
"""
response = llm.invoke(prompt)
state["insights_text"] = response.content.strip()
return state
3.4 フロントエンド(Streamlit)
Streamlitでは、自然言語入力→FastAPI呼び出し→データ&グラフ表示までを1画面で完結させています。
# app/ui_components.py
import streamlit as st
import pandas as pd
import json
import api_client
def backend_communication_section():
st.subheader("1. 自然言語でデータ分析")
user_query = st.text_area("クエリを入力してください:", height=80)
if st.button("分析実行"):
if not user_query:
st.warning("クエリを入力してください。")
return
response = api_client.analyze_query(user_query).json()
# テーブル表示
df = pd.read_json(response["data_json"], orient="split")
st.dataframe(df)
# グラフ表示
graph_metadata = json.loads(response["graph_code"])
if graph_metadata.get("type") == "line":
st.line_chart(df, x=graph_metadata["x_col"], y=graph_metadata["y_col"])
elif graph_metadata.get("type") == "bar":
st.bar_chart(df, x=graph_metadata["x_col"], y=graph_metadata["y_col"])
# インサイト表示
st.subheader("インサイト")
st.write(response["insights"])
4. 動作デモと得られた知見
実際の動作キャプチャ(一部):
得られた知見
良かった点
- シンプルな集計・時系列分析は高精度にSQLが生成され、即時にグラフ化できた
- 自然言語ベースで現場担当者も触れる「セルフサービスBI」に近い操作感
課題
- 複雑な自然言語クエリはまだ不安定(多段JOINや条件分岐を含む場合にSQLが破綻することがある)
- グラフ表現の最適化が限定的(棒グラフと折れ線グラフの誤選択など)
5. 今後の改善と実務適用の視点
実運用を意識すると、現状のままでは実務適用にはまだ課題が多いと感じています。特に以下のポイントが重要です。
技術的改善
- 権限管理
- 現状はすべてのテーブルに対してフルアクセスできてしまうため、OdooユーザーのロールやERP側のアクセスコントロールと連携する仕組みが必要です
- 各エージェントのバージョン管理・チューニング
- SQL生成、グラフ推奨、インサイト生成などのエージェントを個別にアップデートできるようにし、精度改善を継続的に行える設計が望ましいです
- ガードレール実装
- SQL検証レイヤーを設け、高負荷なクエリや不正なテーブル参照を事前にブロックする必要があります
- メタデータのinput制御
- 現状は「全テーブルのスキーマ情報を毎回LLMに渡す」という作りですが、ユーザーが問い合わせた対象テーブルだけを動的に抽出して渡す設計にすることで、LLMへの負荷軽減や誤ったテーブル選択の抑制が期待できます
ビジネス活用時の視点
- 運用負荷の軽減
- エージェントがブラックボックス化すると保守が困難になるため、運用者向けにSQLログやLLMプロンプトの可視化機能が必要
- 業務適用フェーズの拡張
- まずは「日次売上や受注状況レポート」など限定的な用途から始め、徐々に「在庫最適化」や「営業案件分析」へ広げるアプローチが現実的
6. まとめ – 本アプローチがもたらす可能性と今後挑戦したいこと
今回の取り組みで、LangGraph+LLMがOdooなどの業務データ活用を大幅に加速できる可能性を確認できました。
ただ一方で、ビジネス現場への本格適用にはガードレールや権限管理が不可欠です。
そのため、次のステップとして、以下を目指したいです。
- 各種AIエージェントの精度向上
- 入力部分に対してのガードレールの適用
- DBのメタデータの読み込みの簡易化
参考リンク
- Githubリポジトリ