はじめに
動機
今私の手元に GPU 搭載サーバがあります。その上へ Deep Learning 実行環境を構築しようと思います。
最近は__コンテナ上で GPU を使う__アプリが増えており、関連技術の開発も盛んです。デファクトスタンダードがあれば話が早いのですが、そう呼べるアプリやソフトはまだ無さそうです。では、その流れをくむ「今っぽい」環境の一例を作ってみようか、というのが本記事の動機です。
今っぽい、とはあやふやですが、先月(11/14)GPU メーカの NVIDIA社よりこんな記事が出ていました:
NGC コンテナーが今まで以上に多くのユーザー、アプリ、プラットフォームで利用可能に
この記事のエッセンスを取り入れて環境を構築し、Deep Learning 的な課題を実施してみます。
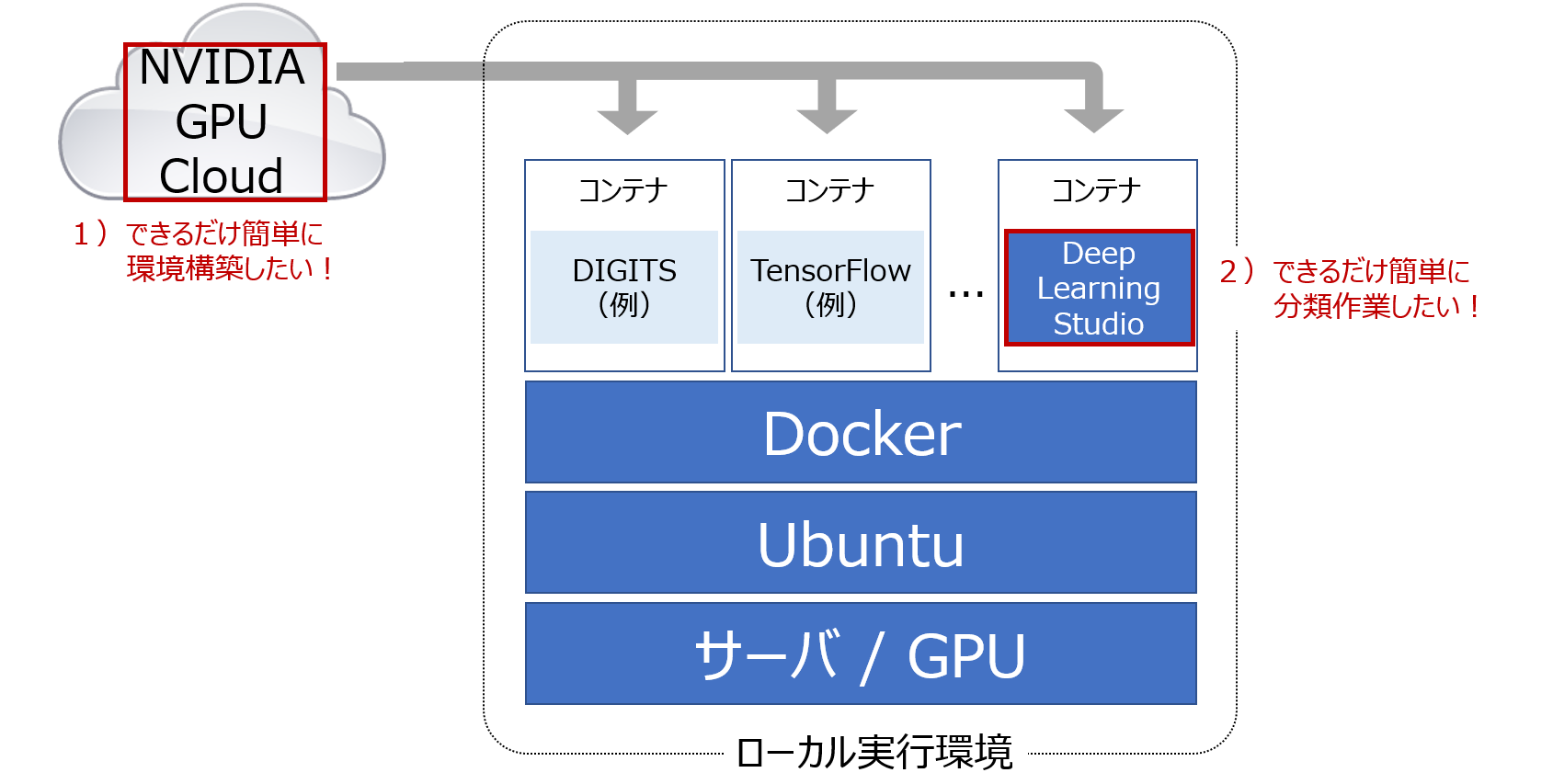
構成図
「今っぽい」を具体化します。コンテナを使う、だけでは芸がありませんので今回の構成の特徴をまとめてみました:
- NVIDIA GPU Cloud 活用で__できるだけ簡単に環境を構築__
- Deep Learning Studio 活用で__できるだけ簡単に分類作業を実施__
- 上記を__無償__で
NVIDIA GPU Cloud (NGC) とは
NVIDIA 社が2017年に開始したクラウドサービスです。GPU に対応したソフトウェア(TensorFlow, DIGITS 等)のコンテナを入手できます。NVIDIA 社やパートナーが検証をして最適化していますので、質の高いコンテナが簡単に手に入ります。似たような仕組みに Docker Hub がありますが、NVIDIA社作成コンテナとしては NGC の方が品揃えが良く、執筆時点で Docker Hub は 15 種、NGC は 41 種です。以下説明する Deep Learning Studio も NGC 経由でしか入手できません。ユーザ登録をすれば無償で利用可能です。
注意点として、公式にサポートされる実行環境は限られています。当初は NVIDIA 社の DGX-1 等に限定されており、徐々にサポート対象が広がっているというのが冒頭の記事でしたが、公式にサポートを受けたい場合は機材が正式に対象となっているか確認するようにして下さい。今回の環境(UCS C240 M5)にて動作確認していますが、公式リストには含まれていません(近いところで UCS C480 ML M5 はサポート対象)。
Deep Learning Studio (DLS) とは
Deep Learning Studio は Deep Cognition Inc.社が開発した AI 開発者用のツールです。クラウド版とデスクトップ版の二種類が存在し、後者はローカルマシン(Windows と Ubuntu に対応)にインストールして使います。基本機能は無償で使えます。クラウド版は AWS のインスタンス利用料と同額がかかり、DLS 自体の利用料は無償、ということのようです。
優れたユーザインターフェイスが特長のひとつで、Deep Learning のモデルをドラッグ&ドロップに対応した GUI 上で作成することができます。また、AutoML (ベータ版) に対応しており、Deep Learning の知識が無くてもひとまず動かして結果を出してみるといった使い方ができます。
なお、Azure でも利用可能です。
画像分類の課題
環境構築後に実施する課題をご理解頂くため、まずは人力での分類にご協力下さい。
問. 写真の花は次の3つの内どれでしょう1?

- Iris cristata(クリスタータ)
- Iris germanica(ドイツアヤメ)
- Iris tingitana(ティンギタナ)
ヒント(各選択肢に対して30種のサンプル):

正解は・・・
Iris cristata でした2。
いかがでしょうか。計90枚のサンプル画像からグループ毎の特徴を読み取り解答するのは少々面倒だったかもしれません。各花の特徴を表す典型的な写真が多いともう少し楽だと思いますが...中々手ごわい分類になりそうです。
ImageNet にはこうした画像が3種計で千数百枚ありますのでこれらを機械に学習してもらいましょう。
環境構築の手順
では環境を構築していきます。スタート地点として、手元の GPU 搭載サーバには OS として Ubuntu 18.04LTS のみがインストールされており、機械学習関連のソフトは何も入っていない前提です。
0. サーバ側の設定
NGC 利用には事前にサーバ側の設定が必要です。必要な作業はこちらにまとめています(注:リンク先の記事では NVIDIA ドライバに 410.48 を使っていますが、執筆時点で DLS が対応していません。396.26 を使う必要があります)。
1. レジストレーション
NGC 利用にはレジストレーションが必須です。NGC のサイトから必要項目を入力してレジストを完了します。
※ レジストしないで git pull すると以下のエラーが出て止まります
unauthorized: authentication required
2. NGC APIキーの生成
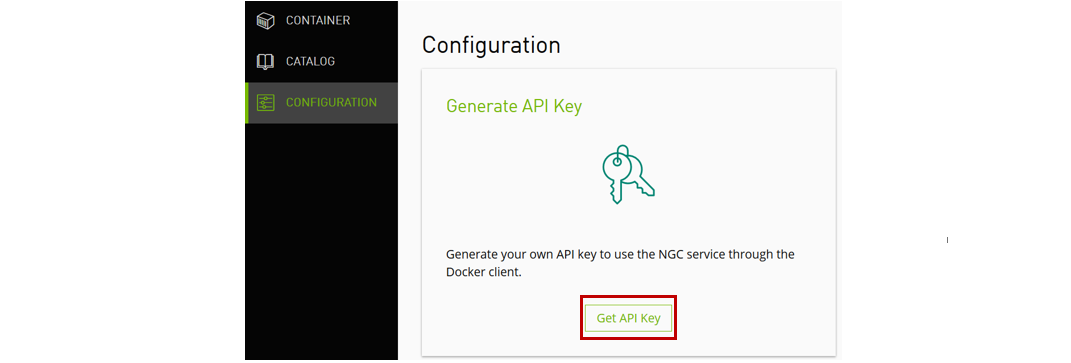
"Get API Key" をクリックした後、"Generate API Key" をクリックすると API キーが生成されます。他人に見られてはいけないキーですので安全な場所へ保存します。
保存完了後、Docker でログインを実施します。ユーザ名は下記の通り $oauthtoken をそのまま使用し、パスワードには今生成した API キーを使用します。
$ sudo docker login nvcr.io
Username: $oauthtoken
Password:
これで docker pull できるようになりました。
3. DLS コンテナをダウンロードする
利用可能なコンテナ一覧は CATALOG から取得可能です。DLS は DEEP LEARNING の中にあります。
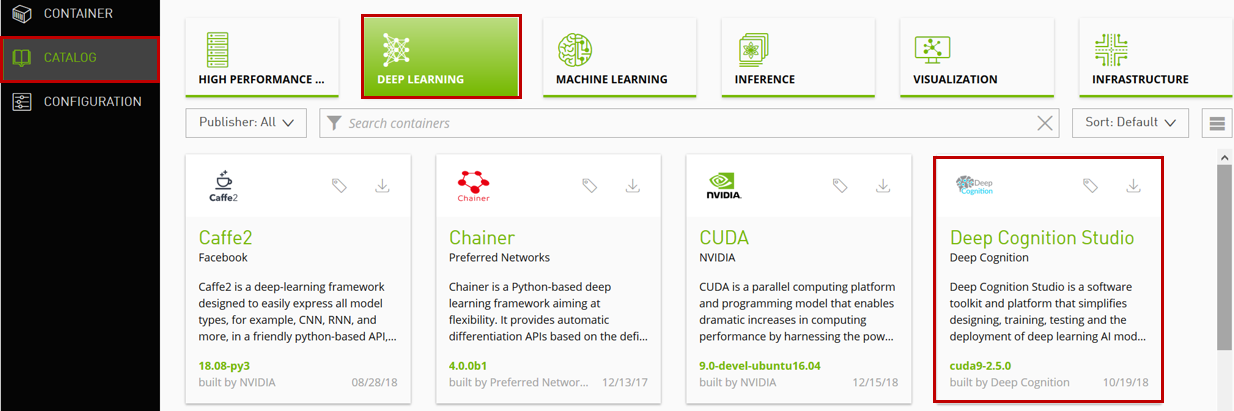
Deep Learning Studio の文字をクリックすると詳細が表示されます。画面下部にある Tags をクリックすると各種バージョンが表示され(といっても執筆時点で DLS には一種類のタグしかありませんが)、矢印をクリックすると Pull コマンドがクリップボードへコピーされます。
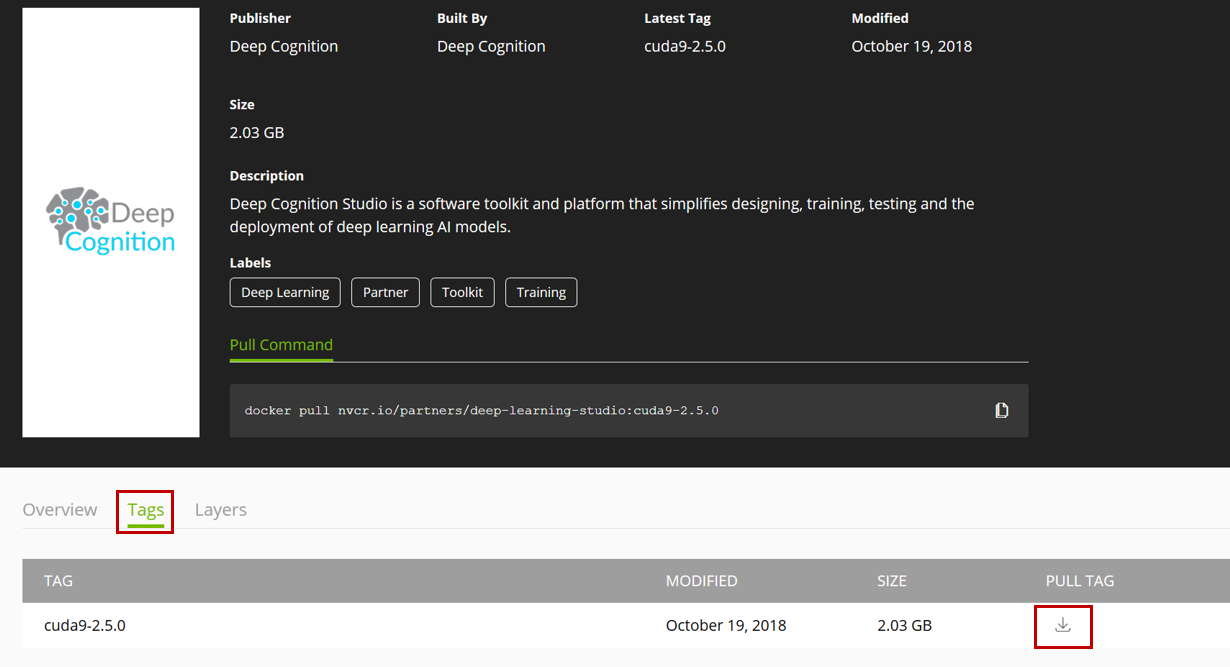
以下のコマンドで cuda9-2.5.0 のコンテナをダウンロードします。
docker pull nvcr.io/partners/deep-learning-studio:cuda9-2.5.0
起動の前に、コンテナのデータ保存用ディレクトリを作成します:
$ mkdir -p $HOME/dls/database $HOME/dls/keras $HOME/dls/data
コンテナを起動します:
$ sudo nvidia-docker run -d --rm --name deep_learning_studio -p 8880:80 -p 8881:80 -p 8888:8880 -p 8886:8888 -p 8889:3000 -v $HOME/dls/data:/data -v $HOME/dls/database:/home/app/database -v $HOME/dls/keras:/root/.keras -e DLS_EULA_AGREED=y nvcr.io/partners/deep-learning-studio:cuda9-2.5.0
ブラウザより http://(IPアドレス):8880 でログイン画面が表示されます。
DLS の認証に成功するとダッシュボードが表示されます。以上で環境構築は完了です。
画像分類の手順
それでは実際に DLS を使って Iris の分類をしていきます。DLS の基本的な使い方は Deep Cognition 社のサイトにわかりやすい動画ファイルがまとまっているのでステップ毎の操作は割愛し、ポイントをハイライトで見ていきます。
基本メニュー
DLS のメニューは洗練されています。メニューのみを抜き出したのが下図で、基本的な流れとして1~8を順に実行していくと Deep Learning 解析作業が一通り終わります。

0. データの取得
画像データは ImageNet から取得します。今回はこちらを利用させて頂きました:
Pythonのurllibを使ってImageNetから画像をダウンロードする
実行の結果、3種の花に対応して3つのディレクトリが作成され、その中へ画像ファイルがダウンロードされます。3種計で1,846枚の画像が準備できました。
1. Datasets(データセットの作成)
ダウンロードした画像ファイルから DLS 用データセット=を作成します。
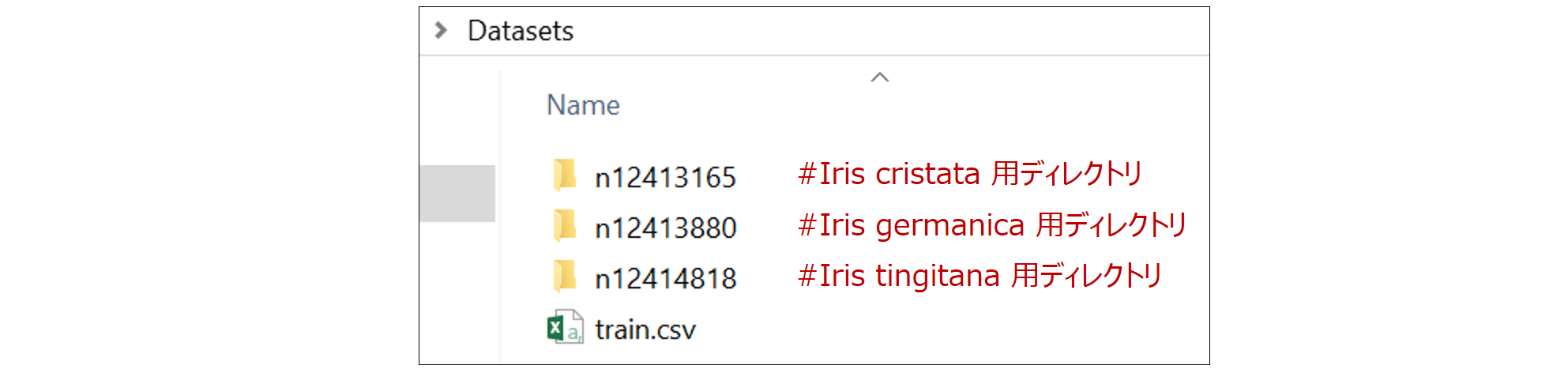
上から3つは画像ファイルです。4つ目の train.csv は新たに作成する必要があり、各画像が三種のどの花か(教師ラベル)を CSV 形式で指定します。サンプルは以下の通りです(一行目はカラム名)。
filename,Label
n12413165/n12413165_5683.jpg,Iris cristata
n12413165/n12413165_2788.jpg,Iris cristata
n12413165/n12413165_1779.jpg,Iris cristata
n12413165/n12413165_902.jpg,Iris cristata
n12413165/n12413165_1859.jpg,Iris cristata
...
これらから1つの zip ファイルを作成すれば準備完了です。以下の画面から zip ファイルをドラッグ&ドロップでアップロードします。
アップロードしたデータに対してお好みの名前(ここでは NEW_DATASET と命名)をつければデータセット作成は完了です。
2. Projects(プロジェクトの作成)
+ボタンをクリックし、プロジェクトをお好みの名前で新規作成します(ここでは NEW_PROJECT と命名)。3~8 の手順はこの中で実行します。

3. Projects:Data(データセットの指定)
プロジェクトに対し、1. で作成したデータセット =NEW_DATASET を指定します。1,846枚の画像ファイルの80%を学習用に使い、20%をテスト用に残しておく等の設定も可能です。
4. Projects:Model(モデルの作成)
使用するモデルを決める画面です。ドラッグ&ドロップで複雑な Deep Neural Network を作成することもできますが、ここは赤枠のステッキらしきアイコンをクリックしてみます。すると・・・

AutoML がデータセットのデータ種別を自動判定して推奨モデルを作ってくれました!(ただしベータ版)
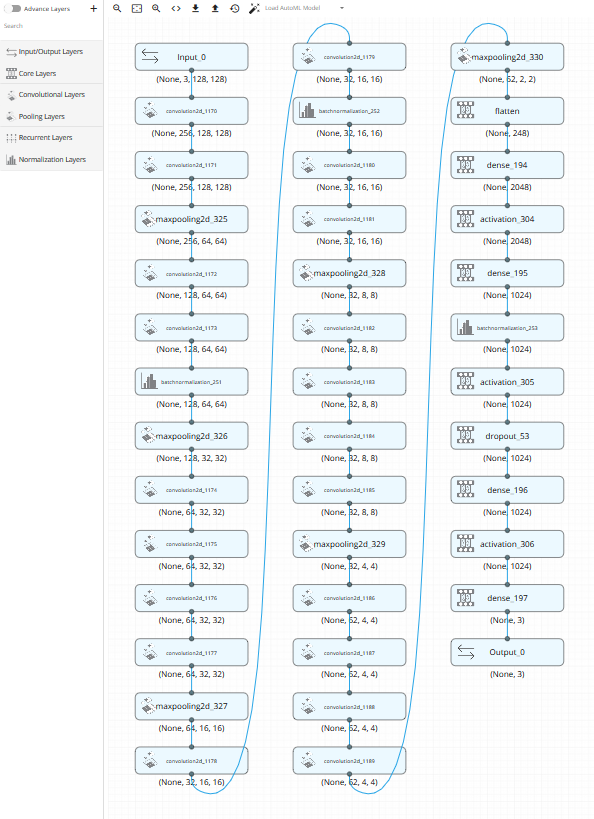
ステッキの3つ隣にある View Code アイコンをクリックするとモデルに対応する Keras のコードを表示することもできます。
5. Projects:HyperParameters(ハイパーパラメータの設定)
デフォルトのままでもOKです。十分学習させたい場合は Number of Epoch を大きくするとよいでしょう。
6. Projects:Training(学習の実施)
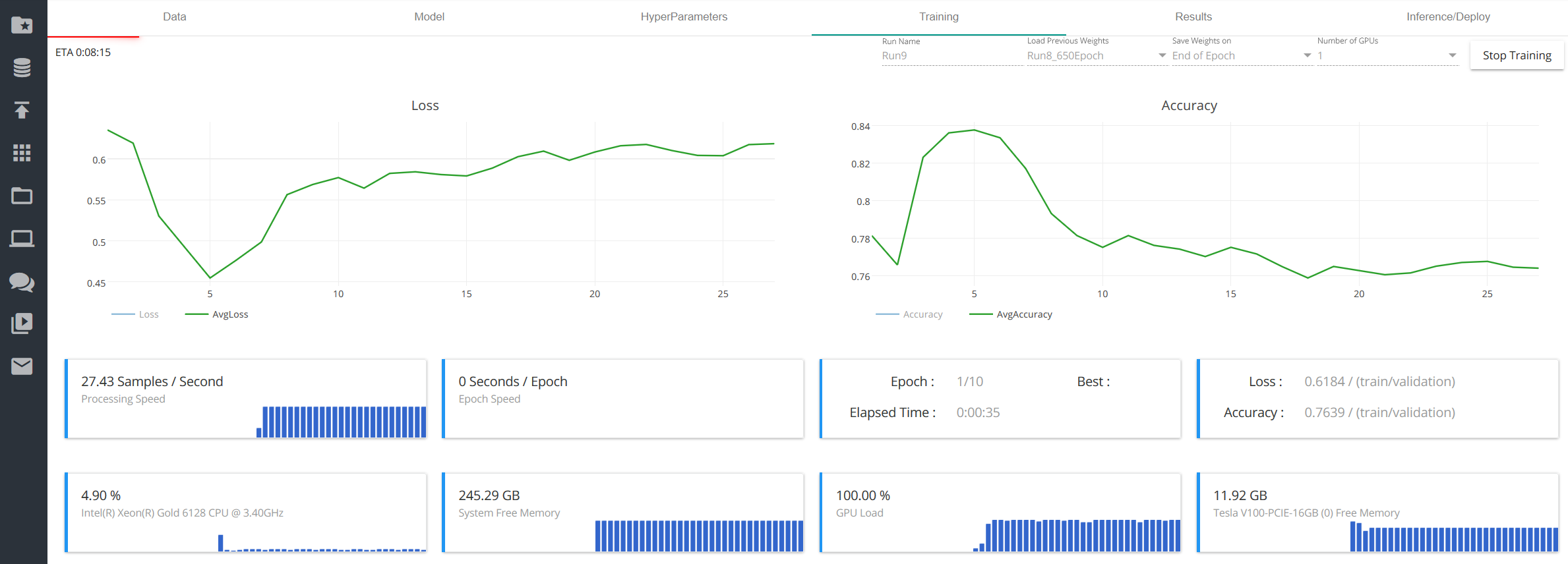
必要な設定は終わりました。いよいよ学習です!
"Start Training" ボタンをクリックすると学習用画像を使った学習が始まります。ある程度の正解率を出すには GPU を使っても数時間~数十時間はかかります。なお、GPU は自動的に使われます。
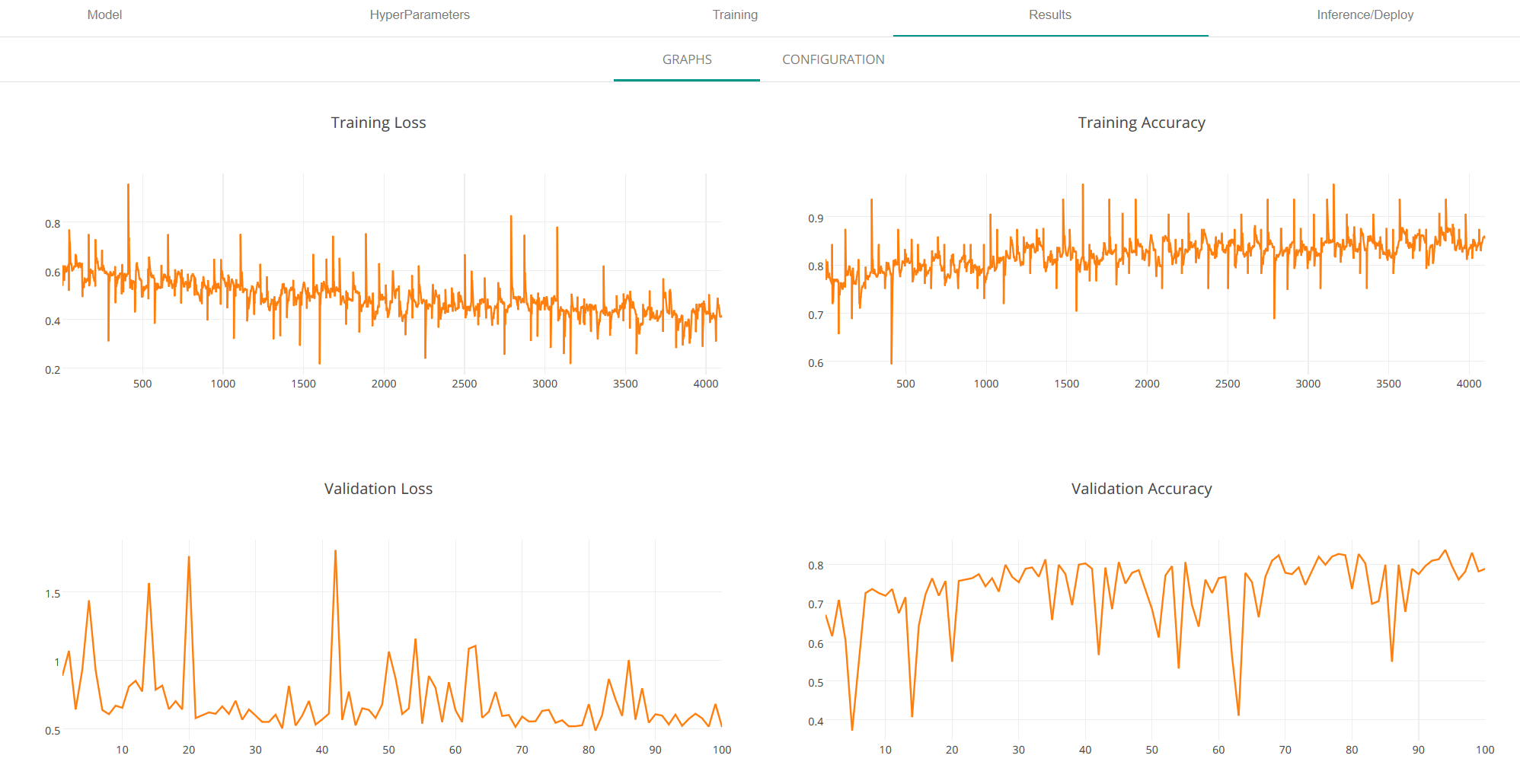
7. Projects:Results(結果を見る)
学習が完了すると、損失関数と学習中の正答率の履歴を見ることができます。
8. Projects:Inference(学習済モデルを使って推論する)
さあ、学習の成果を試す時です。
残しておいたテスト用画像を学習済の機械へ渡して推論してもらいましょう。
下記はテスト画像毎の結果です(一部)。画像の右隣りが正解、さらに右が機械の予測です。3つ目と8つ目を間違えています。
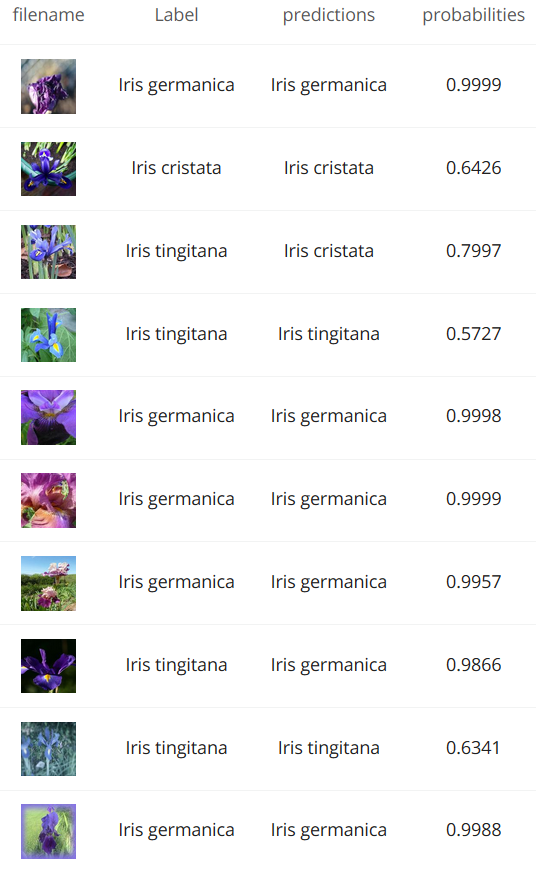
正答率は・・・66.4%でした(ちなみに、三択なので当てずっぽうでは正答率 33.3%)。やはり画像が手強かったでしょうか。
さいごに
なお DSL の名誉のために、別のデータセットへ AutoML 生成モデルを適用した結果を最後に書き添えておきます。MNIST 手描き数字のデータセットを使った場合の正答率は98.77%でした。
今回使用したコンポーネント
| 要素 | 今回使用 |
|---|---|
| サーバ | UCS-C240-M5 |
| GPU | V100 |
| OS | Ubuntu 18.04LTS |
| Docker CE | 18.09.0 |
| Nvidia-docker | 2.0.3 |
| Nvidia Driver | 396.26 |
| DLSコンテナ | cuda9-2.5.0 |