はじめに
SIGNATEで8月に開催されていた第1回Beginner限定コンペ( https://signate.jp/competitions/292 )に参加してみました。
しっかりやりきったコンペは今回が初めてでしたが、最終スコアはAUC=0.8588949で、13位でした(すごく中途半端な結果ですが...)。
このコンペでは、ある値よりもスコアが大きいとBeginnerからIntermediateに昇格することができ、無事に昇格しました。
やったこと、振り返ってみてやればよかったことを今後の自分のためにもまとめておこうと思います。
なお、本コンペのモデルと分析結果については、情報公開ポリシーに則って公開しています。
コンペの概要
データは金融機関における定期預金のキャンペーンデータになっています。
データのもとはこちらですが、若干加工されていると思います。
評価の指標はAUCとなります。
詳細は上記リンクを参照してください。
環境
$sw_vers
ProductName: Mac OS X
ProductVersion: 10.13.6
BuildVersion: 17G14019
$python --version
Python 3.7.3
やったこと
0. random_seedを決める
料理の前に手を洗うようなものですが、あとで再現しなくなることもあるので大事。
結果が必ず再現するように、random_seed あるいは random_stateの引数をもつ関数を使うときに、必ず代入していきます。
1. 一旦どんなものか見てみる(H2O)
H2Oに入れて、データの情報やAutoMLで回したときにどのようなアルゴリズムが上位に来るのか確認しました。
H2Oについては過去の記事をご覧ください。
ここでパーっとデータみつつ、AutoMLで走らせた結果、決定木系のアルゴリズムが上位に来たので、今後LightGBMを使って行こうと決めました。
2.データ取得〜機械学習モデル構築〜予測までの流れを作る(JupyterNotebook)
Notebookファイルはデータ加工と、モデル構築で分けて用意しました(一つのファイルにすると見通しが悪くなったり、毎回不要な処理を流してしまうことがあるため)。
2-1. データ加工部分
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import category_encoders as ce
%matplotlib inline
pd.set_option('display.max_columns', None)
random_state = 1234
df = pd.read_csv('./0_rawdata/train.csv')
データ確認用のコードをいくつか書いていきます。
データの型や、nullの有無の確認↓
df.info()
df.describe()
数値データの可視化↓
df.hist( figsize=(14, 10), bins=20)
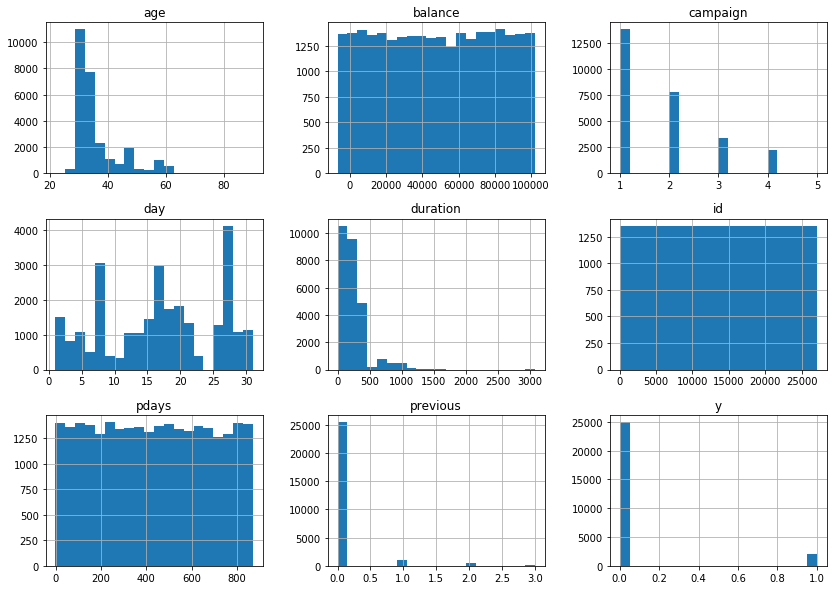
文字列データの可視化↓
plt.figure( figsize = (20, 15))
cols = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'poutcome']
for i, col in enumerate(cols):
plt.subplot(3,3,i+1)
df[col].value_counts().plot.bar()
plt.title(col)
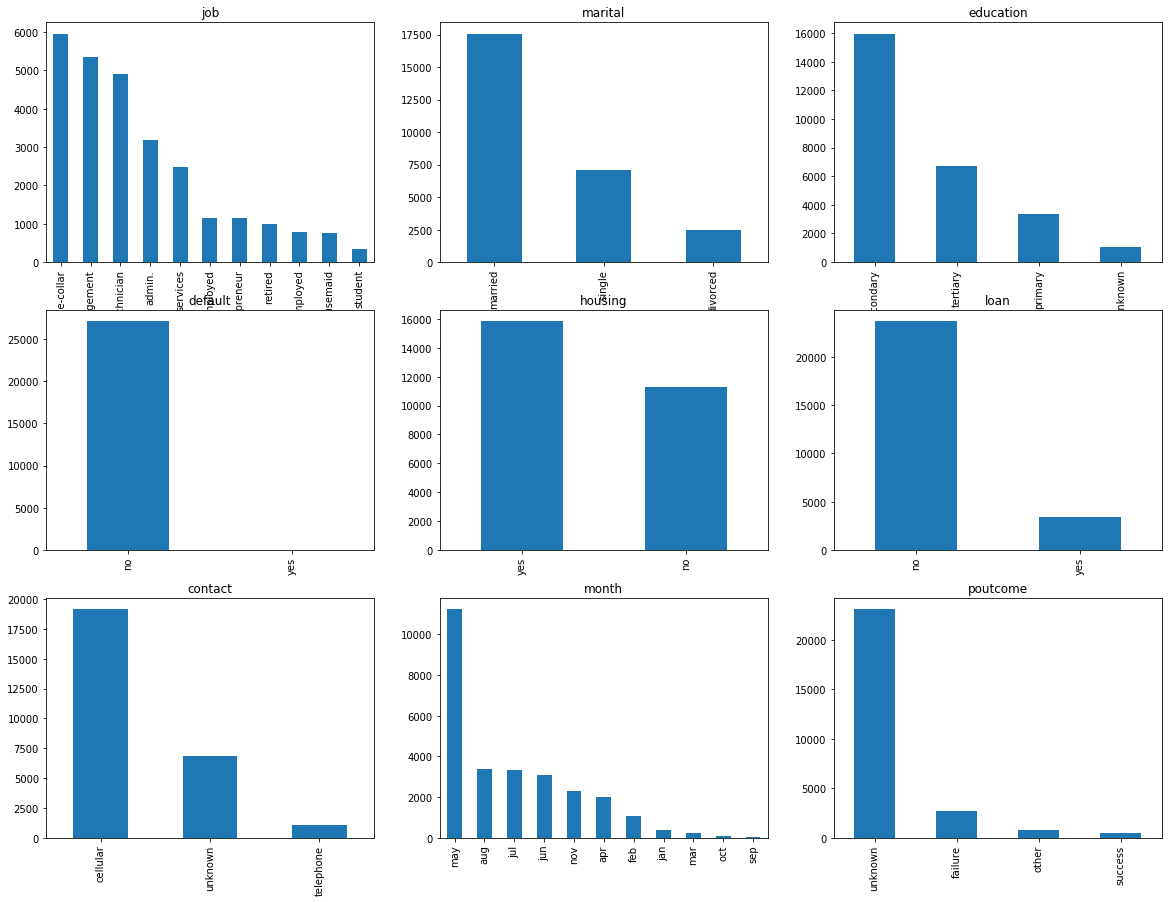
上記の可視化で、idはもちろんですが、 balance, pdaysは一様分布担っているように見えたので、この後学習に用いるデータから削除します。
defaultについてもほとんどのデータがnoだったため、削除します。
また、文字列やカテゴリデータを数値化する処理を入れて、学習に用いるデータを作成しました。
df2 = df.copy()
df2 = df2.drop( columns=['id', 'balance', 'pdays', 'default'])
# month
month_map={
'jan':1,
'feb':2,
'mar':3,
'apr':4,
'may':5,
'jun':6,
'jul':7,
'aug':8,
'sep':9,
'oct':10,
'nov':11}
df2['month'] = df2['month'].fillna(0)
df2['month'] = df2['month'].map(month_map)
# job, marital, education, housing, loan, contact, poutcome
cols = ['job', 'marital', 'education', 'housing', 'loan', 'contact', 'poutcome']
ce_onehot = ce.OneHotEncoder(cols=cols,handle_unknown='impute')
ce_onehot.fit( df2 )
df2 = ce_onehot.transform( df2 )
df2['duration'] = df2['duration'] / 3600
df2.to_csv('mytrain.csv', index=False)
2-2. モデル構築・予測部分
import pandas as pd
import numpy as np
import category_encoders as ce
import lightgbm as lgb
# import optuna
from optuna.integration import lightgbm as lgb_optuna
from sklearn import preprocessing
from sklearn.model_selection import train_test_split,StratifiedKFold,cross_validate
from sklearn.metrics import roc_auc_score
pd.set_option('display.max_columns', None)
random_state = 1234
version = 'v1'
データを学習用、検証用に分割します(8:2)。
df_train = pd.read_csv('mytrain.csv')
X = df_train.drop( columns=['y'] )
y = df_train['y']
X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.2, random_state=random_state)
モデル構築・精度検証として以下の方法を取りました。
- 学習用データを層化抽出で5分割し、Cross Validation
- ハイパーパラメタ(以下、ハイパラ)チューニングはoptunaに任せる
- 最適化に用いる指標はloglossとする
- 学習用データ全体でモデルを再学習して、検証用データを用いてAUC算出
def build():
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=random_state)
lgb_train = lgb_optuna.Dataset(X_train, y_train)
lgbm_params = {
'objective': 'binary',
'metric': 'binary_logloss',
'random_state':random_state,
'verbosity': 0
}
tunecv = lgb_optuna.LightGBMTunerCV(
lgbm_params,
lgb_train,
num_boost_round=100,
early_stopping_rounds=20,
seed = random_state,
verbose_eval=20,
folds=kf
)
tunecv.run()
print( 'Best score = ',tunecv.best_score)
print( 'Best params= ',tunecv.best_params)
return tunecv
tunecv = build()
学習用データ全体でモデルを再学習して、検証用データを用いてAUC算出↓
train_data = lgb.Dataset( X_train, y_train )
eval_data = lgb.Dataset(X_holdout, label=y_holdout, reference= train_data)
clf = lgb.train( tunecv.best_params,
train_data,
valid_sets=eval_data,
num_boost_round=50,
verbose_eval=0
)
y_pred = clf.predict( X_holdout )
print('AUC: ', roc_auc_score(y_holdout, y_pred))
# AUC: 0.8486429810797091
3. データ・精度を見つつ試行錯誤
| # | やったこと | AUC | submit スコア | 感想 |
|---|---|---|---|---|
| 00 | 上記の処理をデフォルトとする | 0.8486 | --- | --- |
| 01 |
job, marital, education, poutcomeのエンコーディングをtarget encodingへ変更 |
0.8458 | --- | 微妙に下がったが、一旦これでいく |
| 02 | num_boost_round=200 (学習曲線を出したらもう少しスコアがよくなりそうだったので) | 0.8536 | --- | 上がった。これでいく |
| 03 | 学習用データ全体でモデルを再学習する部分の学習パラメタがハイパラチューニング用のパラメタと違うことに気がつく。num_boost_round=200、early_stopping_rounds = 20で統一。 | 0.8585 | --- | これでいく |
| 04 | 最適化指標をAUCにしてみる | 0.8557 | --- | 下がった。loglossのままにする |
| 05 | loan, housing, contactをordinal encodingへ変更 | 0.8593 | 0.8556 | AUCは上がっているのでこれでいく。ただし、submitのスコアはちょい低い。 |
| 06 | テストデータと学習データの違いを確認。可視化で比較しても大きな違いはない。テストデータを予測するモデルを作成してみたが、AUC=0.5程度なので、テストデータと学習データの違いはないと判断 | --- | --- | --- |
| 07 | monthのエンコーディングを変更(データ数が少ないいくつかの月を合体) | 0.8583 | 0.8585 | 03のAUCとほぼ変わらず。却下。 |
| 08 | monthのエンコーディングを変更(データ数が少ないいくつかの月を合体) | 0.8583 | 0.8585 | 05からAUCが下がった。却下。 |
| 09 | 時系列のラグ変数のように先月のyの平均を列として追加 | 0.8629 | 0.8559 | 学習用データではスコアが改善したが、テストスコアが下がったため、却下 |
| 10 |
ageをカテゴライズ(行数の少ないageを合体) |
0.8599 | 0.8588 | 微妙に改善。これでいく。 |
| 11 | PCAにつっこんでみる | 0.8574 | --- | 下がった |
| 12 | 他のアルゴリズムを試してみる(SVM, RandomForest, LogisticRegression) | --- | --- | 下がった |
上記以外にも細かいところを変更してみたりしたものの、精度は改善されず。
また、いちいち記録するのもめんどくさくなり...コンペ期間終了という感じです。
やればよかったと思うこと
- データ加工系
- もう少しクロス集計も含め、データをよく眺めてみれば何か発見できたかも
- 元データ(UCI)とマージしてみる(おそらく一部加工されているので、工夫は必要)
- 交互作用項の考慮
- モデル系
- random_stateを変えたLightGBMとのアンサンブルはやってみてもよかった
- 解釈系
- 精度が悪かったところを深掘って調べればよかった(それで
ageのカテゴライズなどできた部分もありましたが、もう少しできれば)
- 精度が悪かったところを深掘って調べればよかった(それで
- ツール、その他系
- Gitでもいいですが、コード管理のツールを活用すればよかった
- 同じく、実験管理系のツールを入れればよかった(MLOpsでもあるようなやつ)
さいごに
他にもやったほうがよいことはいくらでもありそうです。よければコメントいただければと思います。
次回コンペに出るときに今回の反省と、kaggleのカーネルなど参考にしながらテクニックを取り入れていきたいと思います。