30 秒で分かる要約
- 何を作ったか : ブログ記事の URL を渡すと、5 分間のポッドキャスト音声・Marp スライド・要約テキストを自動生成する Lambda 関数
- 解決する課題 : 記事 → 音声化の手作業をゼロに。NotebookLMが使えない企業でも利用可能に!!
モチベーション
Web 記事を読む時間がない人向けに 音声メディア で聞きたい。NotebookLMの音声解説が流行りました。しかし、
- 企業内でGoogle環境使うのが厳しい、、、って話もあると思います
そこで AWS Bedrock (Claude Sonnet)と Polly Neural を組み合わせ、
URL 1 本 → 5 分ポッドキャスト
を自動生成するサーバーレスワークフローを作成しました。Googleはダメだけど、AWSはOKって企業にはピッタリです。
この記事ではその実装ポイントを共有します。
アーキテクチャ概要
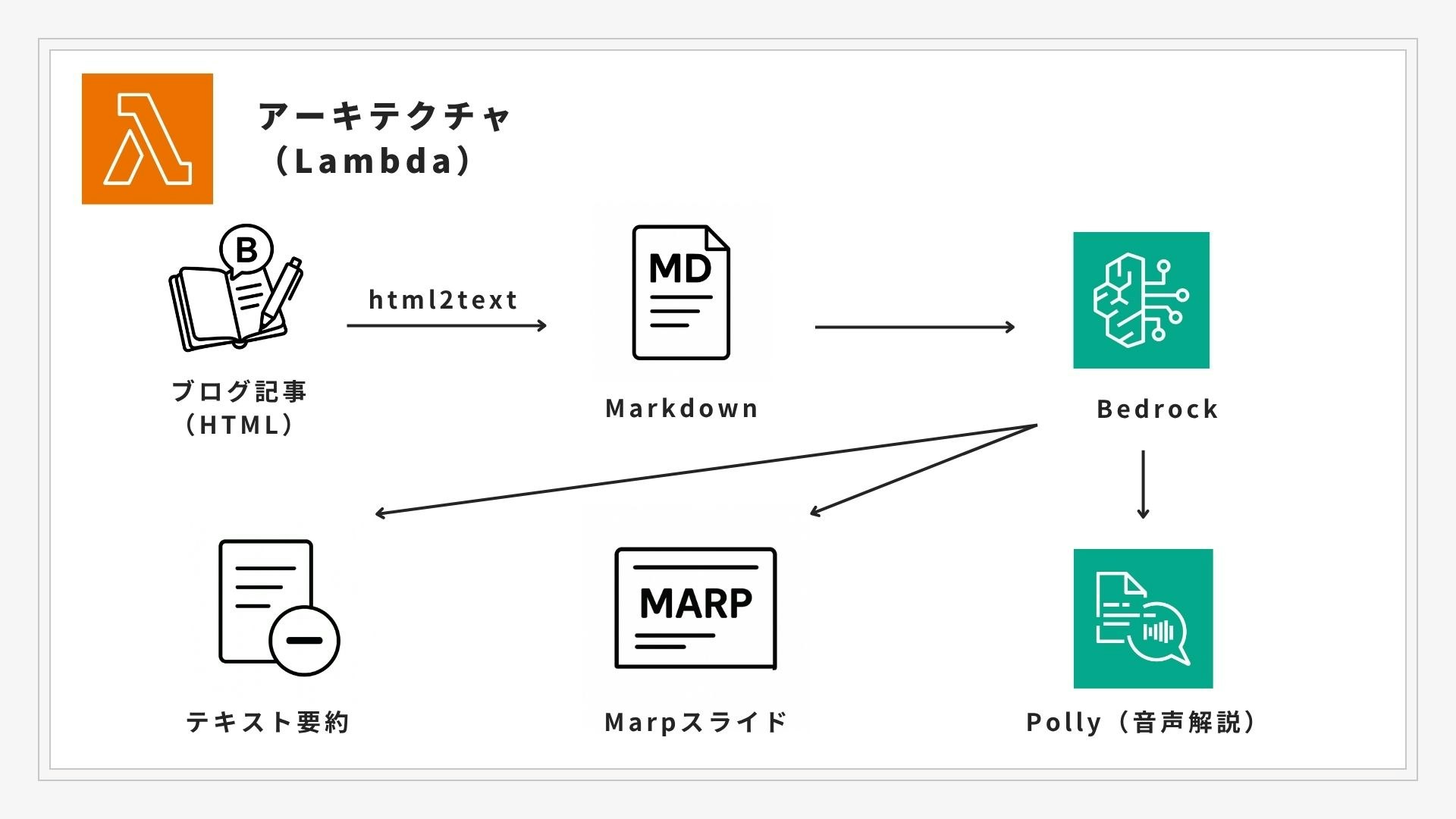
Lambdaから、BedrockのClaude-sonnetを呼び出して、要約・対話スクリプト・marp用markdownを出力してます。対話スクリプトは、Pollyに渡すことによって音声化してます。
事前準備
| # | 作業内容 | コマンド / 参考リンク |
|---|---|---|
| 1 | AWS アカウント作成 & 各サービスの有効化 | Bedrockでモデルアクセスを有効にする。Cross-region inferenceからモデルIDを取得。 |
| 2 | IAM ロール作成 (Bedrock, Polly, S3 アクセス) |
AWSBedrockFullAccess,AmazonPollyFullAccess,AmazonS3FullAccessなどをLambdaにアタッチ |
| 3 | S3 バケット作成 (claude-audio-summary-<your-name>) |
- |
| 4 | Lambda Layer に html2textライブラリ追加 |
↓コードを参照 |
Layer用のコマンド
mkdir -p html2text-layer/python
cd html2text-layer/python
pip install html2text -t .
cd ..
zip -r html2text-layer.zip python
でzipができるので、Lambdaレイヤーにアップロード / アタッチをしてください。
コード全体像
import json, re, unicodedata, urllib.request, uuid, os, tempfile, datetime
from datetime import timezone, timedelta
import boto3, html2text
# ─────────────── 基本設定 ───────────────
BEDROCK_REGION = "us-east-1"
MODEL_ID = "us.anthropic.claude-sonnet-4-20250514-v1:0"
POLLY_REGION = "ap-northeast-1"
VOICE_MAP = {"Host": "Tomoko", "Guest": "Takumi"} # どちらも Neural 対応
MAX_INPUT_CHARS = 20_000
MAX_TOKENS_OUT = 3_000
S3_BUCKET_NAME = "XXXXXXXXXX" # 置き換え
S3_PREFIX = "audio/"
bedrock = boto3.client("bedrock-runtime", region_name=BEDROCK_REGION)
polly = boto3.client("polly", region_name=POLLY_REGION)
s3 = boto3.client("s3")
# ───────── Claude①:ミニインタビュー台本生成プロンプト ─────────
SYSTEM_PROMPT = """
あなたは一流のテック系ポッドキャスト・プロデューサーです。
入力は Markdown 形式のブログ記事本文です。
**「5 分でわかる初心者向け解説インタビュー」** を日本語で作成し、**必ず JSON だけ** を出力してください。
【全体構成(話者=Host/Guest)】
1. **前置き (Preface)**
- Host が 20 秒以内で番組タイトルと記事テーマを紹介
- Guest が「今日は~についてお話しします」と軽く導入
2. **質問パート ×3**
各パートは **(a)シンプル回答 → (b)もう一歩深掘り → (c)キーポイント再確認** の 3 行で構成する
- Host Q: 120 文字以内。初心者が知りたい素朴な疑問で終える
- Guest A‑1: 180 文字以内。まず結論だけを分かりやすく
- Guest A‑2: 200 文字以内。例え話や具体例で少し掘り下げ
- Host Recap: 120 文字以内。「つまり〜なんですね」と要点を言い直す
3. **まとめ (Wrap‑up)**
- Host が本編を振り返り **3 行** で要点を列挙し、
**書き出しは必ず**
「1つ目は〜」「2つ目は〜」「3つ目は〜」
で始める(各 70 文字以内)。
- Guest が「今日覚えてほしいのは…」と 1 行で締める
【文字数・時間目安】
- 合計 4 000〜4 500 全角文字 ≒ 音声 4.5〜5 分
- 1 行あたりの文字数は上記上限を厳守
【語調・トーン】
- Host: やや軽快。初心者に寄り添う質問。
- Guest: 丁寧で落ち着いた口調。比喩と例示を多用。
- キーワードや専門用語は **最初にカタカナ+日本語訳** を入れる(例:クラウド=インターネット上のサーバー)。
- 難しい用語を使ったら **直後に簡単な言い換え** を必ず入れる。
【禁止事項】
- マークダウンや箇条書き、コードブロック、説明文を JSON 外に出力しない。
- セリフ以外の注釈(※〇〇)を入れない。
【出力フォーマット】
{
"title": "<記事タイトルを20文字以内で要約>",
"dialogue": [
{"speaker":"Host", "section":"preface", "text":"..."},
{"speaker":"Guest", "section":"preface", "text":"..."},
{"speaker":"Host", "section":"q1", "text":"..."},
{"speaker":"Guest", "section":"q1_a1", "text":"..."},
{"speaker":"Guest", "section":"q1_a2", "text":"..."},
{"speaker":"Host", "section":"q1_recap","text":"..."},
{"speaker":"Host", "section":"q2", "text":"..."},
{"speaker":"Guest", "section":"q2_a1", "text":"..."},
{"speaker":"Guest", "section":"q2_a2", "text":"..."},
{"speaker":"Host", "section":"q2_recap","text":"..."},
{"speaker":"Host", "section":"q3", "text":"..."},
{"speaker":"Guest", "section":"q3_a1", "text":"..."},
{"speaker":"Guest", "section":"q3_a2", "text":"..."},
{"speaker":"Host", "section":"q3_recap","text":"..."},
{"speaker":"Host", "section":"wrapup", "text":"..."},
{"speaker":"Guest", "section":"wrapup", "text":"..."}
]
}
"""
# ───────── Claude②:Marp スライド生成プロンプト ─────────
MARP_PROMPT = """
You are a slide copy‑writer.
Input is a JSON object that contains a podcast script with {title:str, dialogue:list[…]}.
TASK
----
Create **Marp markdown** for **exactly 4 slides** (Japanese).
LAYOUT
------
- Marp **gaia** theme, 16:9, page numbers
- **Slide‑1**: title & one‑line summary — BOTH centered automatically by `#` heading
- **Slides 2‑4**: left‑aligned
- Headline format: `## Q1? {{headline}}` ← MUST be疑問形、ハイフン不要
- Detail: 1 – 3 日本語 sentences, plain text (≤ 120 全角 total).
Insert `<br/>` only if行長>45 全角
MARKDOWN TEMPLATE
-----------------
---
marp: true
theme: gaia
paginate: true
class: lead
size: 16:9
---
# {{title}}
{{one_line}}
---
## Q1? {{point1_head}}
{{point1_sent1}}<br/>{{point1_sent2}}<br/>{{point1_sent3}}
---
## Q2? {{point2_head}}
{{point2_sent1}}<br/>{{point2_sent2}}<br/>{{point2_sent3}}
---
## Q3? {{point3_head}}
{{point3_sent1}}<br/>{{point3_sent2}}<br/>{{point3_sent3}}
INSTRUCTIONS
------------
1. `{{title}}` : ≤18 全角
2. `{{one_line}}` : 40 全角以内
3. `{{pointN_head}}`: 35 全角以内の疑問形見出し
4. `{{pointN_sent1‑3}}`: 句点で終わる文。必要なければ空文字で良い
– 文数は 1〜3。不要行は空文字を残し `<br/>` を維持して整列
RULES
-----
- 完全にテンプレートを埋めて返す。余計なテキストは禁止
- `-`・`•` などの箇条書き記号を入れない
- Markdown だけを出力する(JSON や解説不可)
"""
# ───────── Claude③:主張+学びテキスト生成プロンプト ─────────
SUMMARY_PROMPT = """
あなたは AWS 分野に精通したシニア技術編集者です。
入力はブログ記事を要約したポッドキャスト台本(JSON)です。
以下の **2 段落のテキスト** を日本語で出力してください。
【フォーマット】
この記事の主張:
<最大 2 文・必ず「です/ます」調・メインメッセージを簡潔にまとめる>
学びになること:
<2〜3 文。AWS エンジニアとして今後どう活かすかが分かるよう、
Next Actions や教訓を具体的に示す。 箇条書きは使わない>
【ルール】
- 行頭のラベル「この記事の主張:」「学びになること:」は必ず残す
- マークダウンや記号装飾、JSON、コードブロックは不要
- 最大 300 日本語文字以内
- それ以外のテキストや説明を追加しない
"""
# ───── HTML → Markdown ─────
def html_to_md(html: str) -> str:
h = html2text.HTML2Text()
h.body_width = 0
h.ignore_links = False
h.ignore_images = True
return h.handle(html)[:MAX_INPUT_CHARS]
# ───── Claude 出力から JSON を抽出 ─────
JSON_RE = re.compile(r"\{\s*\"title\".*\}", re.DOTALL)
def extract_json(raw_text: str) -> dict:
if raw_text.startswith("```"):
raw_text = raw_text.strip("`").lstrip("json").strip()
m = JSON_RE.search(raw_text)
if not m:
raise ValueError("Claude output does not contain JSON")
return json.loads(m.group())
# ───── タイトルをスラッグ化 ─────
def slugify(text: str, max_len: int = 20) -> str:
norm = unicodedata.normalize("NFKC", text)
slug = re.sub(r'[^A-Za-z0-9]+', '_', norm)
slug = slug.strip('_')
return slug[:max_len] or "untitled"
# ───────────────────────────────────────
# Lambda 本体
# ───────────────────────────────────────
def lambda_handler(event, _):
url = event["url"]
# 1) ブログ記事取得 → Markdown へ変換
html = urllib.request.urlopen(url, timeout=10).read().decode("utf-8", "ignore")
md = html_to_md(html)
# 2) Claude①:インタビュー台本 JSON を取得
req = {
"anthropic_version": "bedrock-2023-05-31",
"system": SYSTEM_PROMPT,
"messages": [{"role": "user", "content": md}],
"max_tokens": MAX_TOKENS_OUT,
"temperature": 0.3
}
resp = bedrock.invoke_model(modelId=MODEL_ID,
contentType="application/json",
accept="application/json",
body=json.dumps(req).encode())
raw_text = json.loads(resp["body"].read())["content"][0]["text"].strip()
script = extract_json(raw_text) # dict
# 3) S3 フォルダ名を決定(YYYYMMDD_スラッグ)
JST = timezone(timedelta(hours=9)) # 日本標準時
date_prefix = datetime.datetime.now(JST).strftime("%Y%m%d")
folder_name = f"{date_prefix}_{slugify(script['title'])}"
base_s3 = f"{S3_PREFIX}{folder_name}/"
parts_dir = base_s3 + "parts/"
# 4) 台本を Polly で音声化(発話ごとに MP3 作成)
tmp_dir = tempfile.gettempdir()
part_files = []
part_keys = []
for idx, turn in enumerate(script["dialogue"]):
voice_id = VOICE_MAP[turn["speaker"]]
# Neural 合成
try:
audio_bytes = polly.synthesize_speech(
Text=turn["text"],
TextType="text",
OutputFormat="mp3",
VoiceId=voice_id,
Engine="neural"
)["AudioStream"].read()
except polly.exceptions.ValidationException:
# Neural 非対応なら Standard にフォールバック
audio_bytes = polly.synthesize_speech(
Text=turn["text"],
TextType="text",
OutputFormat="mp3",
VoiceId=voice_id,
Engine="standard"
)["AudioStream"].read()
local_path = os.path.join(tmp_dir, f"{idx:02d}_{turn['speaker']}.mp3")
with open(local_path, "wb") as f:
f.write(audio_bytes)
part_files.append(local_path)
part_key = f"{parts_dir}{idx:02d}_{turn['speaker']}.mp3"
s3.put_object(Bucket=S3_BUCKET_NAME, Key=part_key,
Body=audio_bytes, ContentType="audio/mpeg")
part_keys.append(part_key)
# 5) 全 MP3 を連結して final.mp3 を作成
final_local = os.path.join(tmp_dir, "final.mp3")
with open(final_local, "wb") as fout:
for p in part_files:
with open(p, "rb") as fin:
fout.write(fin.read())
final_key = base_s3 + "final.mp3"
with open(final_local, "rb") as f:
s3.put_object(Bucket=S3_BUCKET_NAME, Key=final_key,
Body=f, ContentType="audio/mpeg")
# 6) Claude②:Marp スライド Markdown を生成
req2 = {
"anthropic_version": "bedrock-2023-05-31",
"system": MARP_PROMPT,
"messages": [{"role": "user", "content": json.dumps(script, ensure_ascii=False)}],
"max_tokens": 600,
"temperature": 0.3
}
resp2 = bedrock.invoke_model(modelId=MODEL_ID,
contentType="application/json",
accept="application/json",
body=json.dumps(req2).encode())
marp_md = json.loads(resp2["body"].read())["content"][0]["text"]
marp_key = base_s3 + "deck.marp.md"
s3.put_object(Bucket=S3_BUCKET_NAME, Key=marp_key,
Body=marp_md.encode("utf-8"),
ContentType="text/markdown")
# 7) Claude③:主張+学びテキストを生成
summary_req = {
"anthropic_version": "bedrock-2023-05-31",
"system": SUMMARY_PROMPT,
"messages": [{"role": "user", "content": json.dumps(script, ensure_ascii=False)}],
"max_tokens": 800,
"temperature": 0.2
}
summary_resp = bedrock.invoke_model(
modelId=MODEL_ID,
contentType="application/json",
accept="application/json",
body=json.dumps(summary_req).encode()
)
summary_txt = json.loads(summary_resp["body"].read())["content"][0]["text"].strip()
summary_key = base_s3 + "summary.txt"
s3.put_object(Bucket=S3_BUCKET_NAME, Key=summary_key,
Body=summary_txt.encode("utf-8"),
ContentType="text/plain")
# 8) Lambda レスポンス
return {
"url": url,
"title": script["title"],
"script": script,
"audio": f"https://{S3_BUCKET_NAME}.s3.amazonaws.com/{final_key}",
"marp": f"https://{S3_BUCKET_NAME}.s3.amazonaws.com/{marp_key}",
"summary": f"https://{S3_BUCKET_NAME}.s3.amazonaws.com/{summary_key}", # ★ 追加
"parts": [f"https://{S3_BUCKET_NAME}.s3.amazonaws.com/{k}" for k in part_keys]
}
主要ロジック解説
5.1 HTML→Markdown 変換
h = html2text.HTML2Text()
h.body_width = 0
h.ignore_links = False
md = h.handle(html)[:MAX_INPUT_CHARS]
-
body_width = 0で改行挿入を防ぎ、Bedrock への入力をクリーンに。 - 20,000 文字でカットし トークン超過 を回避。
5.2 Claude①:インタビュー台本生成
req = {
"anthropic_version": "bedrock-2023-05-31",
"system": SYSTEM_PROMPT,
"messages": [{"role": "user", "content": md}],
"max_tokens": MAX_TOKENS_OUT,
"temperature": 0.3
}
- JSON 強制 & 字数制限 で安全にパース
- Host / Guest のキャラクター設定で聞きやすさを担保
5.3 Polly 音声合成
try:
audio_bytes = polly.synthesize_speech(..., Engine="neural")
except polly.exceptions.ValidationException:
audio_bytes = polly.synthesize_speech(..., Engine="standard")
- Neural 非対応 VoiceId は Standard にフォールバックし、実行エラーをゼロに。
-
VOICE_MAP = {"Host": "Tomoko", "Guest": "Takumi"}は Neural 対応 声優を使用
5.4 MP3 連結 & アップロード
with open(final_local, "wb") as fout:
for p in part_files:
with open(p, "rb") as fin:
fout.write(fin.read())
-
tempfileのローカルストレージで高速マージ。 - S3 へのキーは
audio/20250727_slug/parts/nn_Host.mp3形式で日付+スラッグ管理。
こちらの記事を参考にして、それぞれで音声を作成し最後に連結させました
5.5 Marp スライド生成 / Summary 生成
- Marp 4枚縛り テンプレを Bedrock に渡しているので、後段のスライド修正コストが低い
- 学びテキストは「この記事の主張: / 学びになること:」2 段落のみでシンプル
デモ: Lambda を回してみる
Test イベントに
{
"url": "https://qiita.com/amixedcolor/items/b8c40c7224c0e624affb"
}
をセット。
Relicエイミさんが書いた、Jr.Champioons Meetupについての記事を利用します。
Lambda 実行後、S3に次のようなファイルが保存されます。
①summary.txt
この記事の主張:
Jr. ChampionsはAWSの若手エンジニア向け表彰プログラムで、技術力と発信力を兼ね備えたメンバーが最新の実践的な技術を共有し合う活発なコミュニティです。参加者は専門性を深めながら信頼を構築し、将来のキャリアアップを目指しています。
学びになること:
AWSエンジニアとして成長するには、特定分野の専門家として深い知識を身につけ、継続的なアウトプットを通じて社内外での信頼を積み重ねることが重要です。DynamoDBのシングルテーブルデザインやAmazon Q Developerによる開発自動化など、最新の実践的手法を学び続けることで技術的優位性を保てます。技術コミュニティでの活動は単なる学習の場ではなく、専門性とリーダーシップを発揮してキャリアを加速させる戦略的な投資として捉えるべきです。
②deck.marp.md
---
marp: true
theme: gaia
paginate: true
class: lead
size: 16:9
---
# Jr. Champions Meetup参加記
AWSの若手エンジニア表彰プログラムの活動内容
---
## Jr. Championsとは何ですか?
AWSが若手エンジニアを対象に行っている表彰プログラムです。<br/>選ばれた人だけが参加できる限定のMeetupがあり、技術的な学びや交流を深めています。<br/>現役Jr. Championsは21のコミュニティで活動し、QiitaのAWSカテゴリでOrganizationランキング1位を獲得するほど活発です。
---
## どんな技術的な発表がありましたか?
DynamoDBの設計手法とAmazon Q Developerを使った開発自動化の話が特に印象的でした。<br/>DynamoDBでは「シングルテーブルデザイン」という従来のRDBMSとは全く違うアプローチが紹介されました。<br/>Q Developerではチケット作成からプルリクエスト作成まで10分程度で自動化できる事例が共有されました。
---
## この活動をキャリアにどう活かしていますか?
多くの人がAWS Ambassadorsなどの上位表彰プログラムを目指しています。<br/>そのために「専門家」として深い知識を身につけ、社内外での「信頼」を積み重ねることを重視しています。<br/>特定のAWSサービスの専門家になったり社内で若手育成企画をリードするなど、一つの分野を深く追求してリーダーシップを発揮することがキャリア加速の鍵です。
Marpでスライド化するとこんな感じ




③final.mp3
音声ファイルはアップロードできなかったので、実際に試してみてね!
まとめ
- ブログ URL 1 本で「台本+音声+スライド+学び要約」を自動生成 するワークフローを構築
- Lambda + Bedrock + Polly の フルマネージド構成 でサーバーレス運用
これで、積読してたブログをサクサク消化できるはず!!