動機
Residual Networkのようなdeeeepなニューラルネットワークを使ってみたいと思いました。
MNISTでは物足りなく、ImageNetはデータ集めるのが大変そう&学習に時間がかかりそう、という理由でCIFAR-10画像データセットをつかって画像の分類を行いました。
CIFAR-10画像データセットとは
CIFAR-10画像データセットは小さいサイズのカラー画像のデータセットです
https://www.cs.toronto.edu/~kriz/cifar.html
- 画像サイズは32 x 32px
- 10クラスの画像がそれぞれ6000枚、計60000枚の画像がある
そのうち50000枚が学習データ、10000枚がテストデータ - クラスはairplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck
実行環境
以下の環境で実行しました
- Windows 10 (Ubuntu 14.04でも動作することを確認しています)
- Python 2.7
- Chainer 1.9.0
- CUDA 7.5
- cudnn v4
- GeForce GTX 970
ソースコードと機能
使用したソースコードは以下にあります。
後に記述するコマンドはこのコードをcloneしてソースツリーのルートにいることを前提とします。
https://github.com/dsanno/chainer-cifar
以下の機能を持っています
- 複数のニューラルネットワーク構成をサポート
- 学習データのaugmentation(水増し)
- 学習データ、テストデータの前処理
- 学習率のスケジュール(例: 100epoch学習させたら学習率を1/10にする)
- 損失曲線、エラー率曲線の描画
エラー率の測定
分類にあたっては以下のようにエラー率を測定しました
- 学習データ50000枚をランダムに学習用45000枚、検証用5000枚に分ける
- 各epochにおいて検証データのエラー率とテストデータのエラー率を測定
- 検証データのエラー率が最良のepochにおけるテストデータのエラー率を最終的なテストエラー率として採用する
データセットの取得
https://www.cs.toronto.edu/~kriz/cifar.html にあるリンク"CIFAR-10 python version"からダウンロードできます。
もしくは以下のコマンドでデータセットをダウンロードします。
データセットファイルは166MBあり、回線が細いと時間がかかります。
$ python src/download.py
ダウンロードしたデータセットを解凍すると以下の画像ができます。
- 学習データ(pickleファイル)
data_batch_1, data_batch_2, data_batch_3, data_batch_4, data_batch_5の5個 - テストデータ(pickleファイル)
test_batch - メタデータファイル、readme
data_batch_1等の中身はdictで、'data'に画像の生データ、'labels'にラベル情報が格納されています。
data_batch_1について調べつつ先頭の100個を画像として保存するサンプルを示します。
$ python
>>> import cPickle as pickle
>>> f = open('dataset/cifar-10-batches-py/data_batch_1', 'rb')
>>> train_data = pickle.load(f)
>>> f.close()
>>> type(train_data['data'])
<type 'numpy.ndarray'>
>>> train_data['data'].shape # 生データの形状を取得
(10000L, 3072L)
>>> train_data['data'][:5] # 生データの先頭5個を取得
array([[ 59, 43, 50, ..., 140, 84, 72],
[154, 126, 105, ..., 139, 142, 144],
[255, 253, 253, ..., 83, 83, 84],
[ 28, 37, 38, ..., 28, 37, 46],
[170, 168, 177, ..., 82, 78, 80]], dtype=uint8)
>>> type(train_data['labels'])
<type 'list'>
>>> train_data['labels'][:10] # ラベルデータの先頭10個を取得
[6, 9, 9, 4, 1, 1, 2, 7, 8, 3]
>>> from PIL import Image
>>> sample_image = train_data['data'][:100].reshape((10, 10, 3, 32, 32)).transpose((0, 3, 1, 4, 2)).reshape((320, 320, 3)) # 先頭100個をタイル状に並べ替える
>>> Image.fromarray(sample_image).save('sample.png')
以下の画像を取得できます

画像の前処理
以下のコマンドを実行すると3種類の前処理を行ったデータセットを生成します。
$ python src/dataset.py
- 画像から平均値を引く
- ZCA Whitening(今回は使わない)
- Contrast Normalization + ZCA Whitening
「画像の平均値」は学習データ全体のRGB値をRGBを問わず平均した値を使いました。
Contrast NormalizationはRGB値から各画像の平均値を引いた後、標準偏差が1になるように定数を掛けることでコントラストを揃えした。
ZCA Whiteningについてはきちんと理解していないのですが、朱鷺の杜Wikiによると「データの共分散行列が単位行列となるような変換」を行うそうです。
Whiteningの具体的な計算はまんぼう日記「CIFAR-10 と ZCA whitening」に詳しく書かれています。
Contrast Normalization + ZCA Whiteningを行った画像は以下のようになります。
そのままだとRGB値の分布が狭いので画像ごとにRGB値の分布が0~255の範囲に広がるようにnormalizeしています。

学習データのaugmentation(水増し)
どの学習においても以下のようなaugmentationを行っています。
テスト時にはaugmentationは行わず、前処理を行ったテストデータをそのまま使用しています。
- 学習データのサイズは32x32px
- -4~4pxの範囲でランダムに上下左右に画像をスライド
スライドによって空いた部分は0で埋める(前処理は完了しているので、0で埋めた部分は灰色に該当します) - ランダムに左右反転を行う
augmentation部分のコードは以下のようになっています。
import numpy as np
(中略)
def __trans_image(self, x):
size = 32
n = x.shape[0]
images = np.zeros((n, 3, size, size), dtype=np.float32)
offset = np.random.randint(-4, 5, size=(n, 2))
mirror = np.random.randint(2, size=n)
for i in six.moves.range(n):
image = x[i]
top, left = offset[i]
left = max(0, left)
top = max(0, top)
right = min(size, left + size)
bottom = min(size, left + size)
if mirror[i] > 0:
images[i,:,size-bottom:size-top,size-right:size-left] = image[:,top:bottom, left:right][:,:,::-1]
else:
images[i,:,size-bottom:size-top,size-right:size-left] = image[:,top:bottom,left:right]
return images
比較的浅いネットワークを使って分類してみる
以下のような比較的浅いネットワークで学習させてみます。
Tensorflorのチュートリアルで使っているネットワークに似た構造を使います。(まったく同じではなくレイヤー構成とパラメータ初期値に差があります)
Convolution Neural Network (CNN) + ReLU + MaxPoolingを3層重ねた後、Fully connected Layerが2層あります。
Fully Connected Layerの後はdropoutを設けて過学習を抑制します。
class CNN(chainer.Chain):
def __init__(self):
super(CNN, self).__init__(
conv1=L.Convolution2D(3, 64, 5, stride=1, pad=2),
conv2=L.Convolution2D(64, 64, 5, stride=1, pad=2),
conv3=L.Convolution2D(64, 128, 5, stride=1,
pad=2),
l1=L.Linear(4 * 4 * 128, 1000),
l2=L.Linear(1000, 10),
)
def __call__(self, x, train=True):
h1 = F.max_pooling_2d(F.relu(self.conv1(x)), 3, 2)
h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), 3, 2)
h3 = F.max_pooling_2d(F.relu(self.conv3(h2)), 3, 2)
h4 = F.relu(self.l1(F.dropout(h3, train=train)))
return self.l2(F.dropout(h4, train=train))
以下のコマンドで学習を実行します。
実行には40分くらいかかりました。
$ python src/train.py -g 0 -m cnn -b 128 -p cnn --optimizer adam --iter 300 --lr_decay_iter 100
オプションの意味は以下の通りです
- -g 0: 0番目のGPU使用
- -b 128: ミニバッチ数128
- --optimizer adam: OptimizerとしてAdamを使用
- --iter 300: epoch数300
- --lr_decay_iter 100: 学習率(Adamの場合はalpha値)を100epoch毎に1/10する
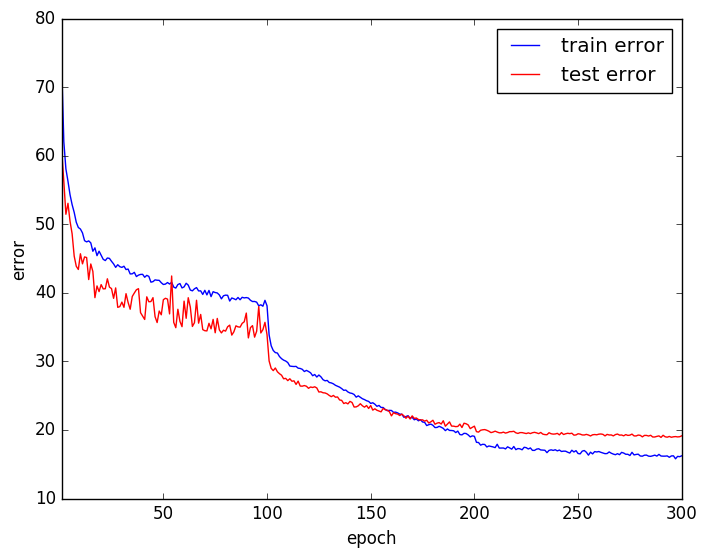
エラー曲線は以下のようになり、テストエラー率は18.94%でした。
エラー曲線を見ると、しばらく学習させた後に学習率を下げるとまた急激に学習が進んでいます。
このように一定回数学習したら学習率を下げるようにスケジュールするのは使われる手法です。
Contrast Normalization + ZCA Whitening を行ったデータセットを使用する
今度は前処理でContrast Normalization + ZCA Whiteningを行ったデータセットを使用して学習します。
以下のコマンドで学習を実行します。
実行には40分くらいかかりました。
$ python src/train.py -g 0 -m cnn -b 128 -p cnn_zca --optimizer adam --iter 300 --lr_decay_iter 100 -d dataset/image_norm_zca.pkl
"-d dataset/image_norm_zca.pkl"でContrast Normalization + ZCA Whiteningを行ったデータセットを指定しています。
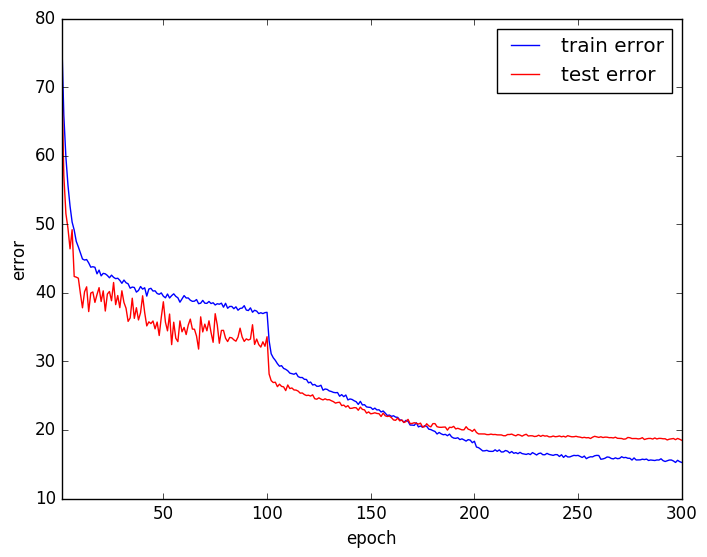
エラー曲線は以下のようになり、テストエラー率は18.76%でした。
平均値を引いただけの場合よりも良くなっているもののほとんど変わらないという結果になりました。
Batch Normalizationを使う
Batch Normalizationとはミニバッチごとに特定レイヤーの出力を平均0、分散1に正規化する手法です。
正規化することで次のレイヤーの学習を行いやすくする狙いがあります。
アルゴリズムについてはこの記事に詳しく書かれています。
ChainerでBatch Normalizationを行うにはchainer.links.BatchNormalizationを使えばよいです。
以下に今回使用したネットワークのコードを示します。
ネットワーク構成は先ほど使ったものとほぼ同じで、違いはBatch Normalizationの有無だけです。
class BatchConv2D(chainer.Chain):
def __init__(self, ch_in, ch_out, ksize, stride=1, pad=0, activation=F.relu):
super(BatchConv2D, self).__init__(
conv=L.Convolution2D(ch_in, ch_out, ksize, stride, pad),
bn=L.BatchNormalization(ch_out),
)
self.activation=activation
def __call__(self, x, train):
h = self.bn(self.conv(x), test=not train)
if self.activation is None:
return h
return F.relu(h)
class CNNBN(chainer.Chain):
def __init__(self):
super(CNNBN, self).__init__(
bconv1=BatchConv2D(3, 64, 5, stride=1, pad=2),
bconv2=BatchConv2D(64, 64, 5, stride=1, pad=2),
bconv3=BatchConv2D(64, 128, 5, stride=1, pad=2),
l1=L.Linear(4 * 4 * 128, 1000),
l2=L.Linear(1000, 10),
)
def __call__(self, x, train=True):
h1 = F.max_pooling_2d(self.bconv1(x, train), 3, 2)
h2 = F.max_pooling_2d(self.bconv2(h1, train), 3, 2)
h3 = F.max_pooling_2d(self.bconv3(h2, train), 3, 2)
h4 = F.relu(self.l1(F.dropout(h3, train=train)))
return self.l2(F.dropout(h4, train=train))
Batch Normalizationを使用して学習するには以下のコマンドを入力します。
実行には50分くらいかかりました。
$ python src/train.py -g 0 -m cnnbn -b 128 -p cnnbn --optimizer adam --iter 300 --lr_decay_iter 100
"-m cnnbn"でBatch Normalizationつきのモデルを使用します。
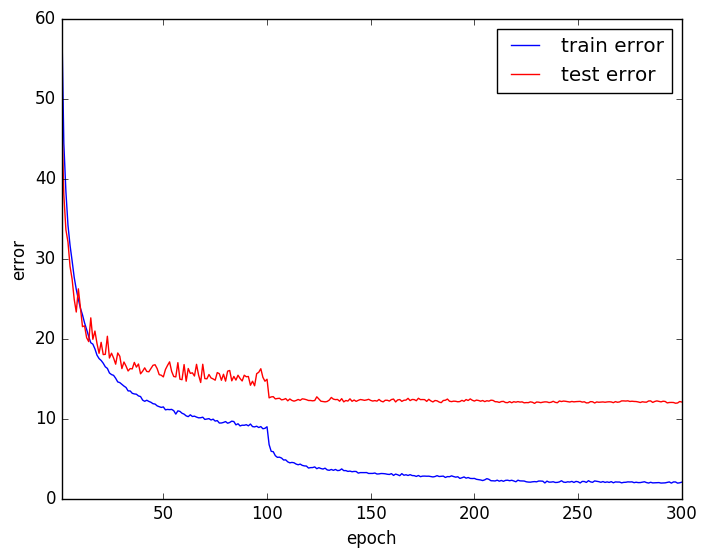
エラー曲線は以下のようになり、エラー率は12.40%になりました。
Batch Normalizationなしの場合と比べてエラー率が劇的に下がっていることがわかります。
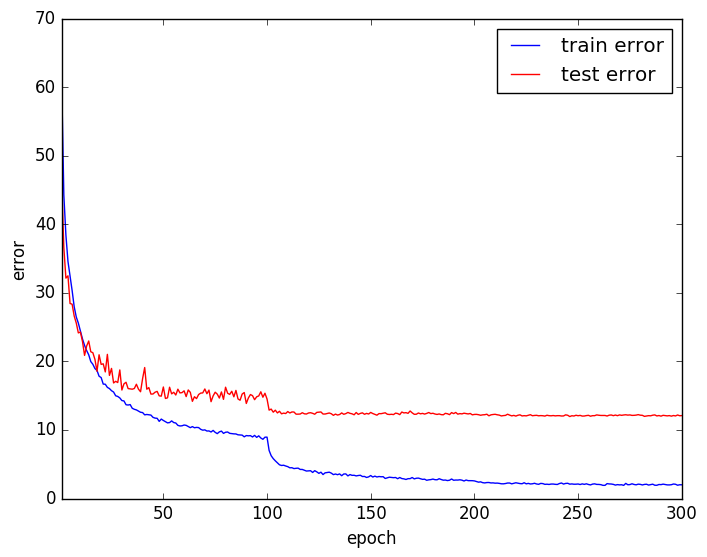
Contrast Normalization + ZCA Whiteningを行った学習データも使ってみました。
コマンドは以下の通りです。
$ python src/train.py -g 0 -m cnnbn -b 128 -p cnnbn --optimizer adam --iter 300 --lr_decay_iter 100 -d dataset/image_norm_zca.pkl
エラー率は12.27%で、平均値を引いただけの場合よりも少しだけ良くなりました。
VGG likeなモデルを使う
VGG 16 layerやVGG 19layerに似たモデルを使います。
VGGモデルでは、kernel size 3のCNN複数 + Max Poolingを何回か繰り返した後Fully Connectedレイヤーを設けています。
VGGをベースとしたネットワークをデー「Kaggle CIFAR-10の話」で使用していたので同様のネットワークを使って学習します。
このブログではテストデータの認識率94.15%という高いスコアを達成しています。
「Kaggle CIFAR-10の話」と異なる点は以下の通りです。
| 今回の実装 | Kaggle CIFAR-10の話 | |
|---|---|---|
| 入力データ | 32 x 32px | 24 x 24 px |
| Augmentation(学習時) | 平行移動、左右反転 | 平行移動、左右反転、拡大 |
| Augmentation(テスト時) | なし | 平行移動、左右反転、拡大 |
| モデルの個数 | 1個 | 6個(各モデルの出力の平均を使用) |
| Batch Normaliztion | あり | なし |
Chainerを使って記述すると以下のようになります。
class VGG(chainer.Chain):
def __init__(self):
super(VGG, self).__init__(
bconv1_1=BatchConv2D(3, 64, 3, stride=1, pad=1),
bconv1_2=BatchConv2D(64, 64, 3, stride=1, pad=1),
bconv2_1=BatchConv2D(64, 128, 3, stride=1, pad=1),
bconv2_2=BatchConv2D(128, 128, 3, stride=1, pad=1),
bconv3_1=BatchConv2D(128, 256, 3, stride=1, pad=1),
bconv3_2=BatchConv2D(256, 256, 3, stride=1, pad=1),
bconv3_3=BatchConv2D(256, 256, 3, stride=1, pad=1),
bconv3_4=BatchConv2D(256, 256, 3, stride=1, pad=1),
fc4=L.Linear(4 * 4 * 256, 1024),
fc5=L.Linear(1024, 1024),
fc6=L.Linear(1024, 10),
)
def __call__(self, x, train=True):
h = self.bconv1_1(x, train)
h = self.bconv1_2(h, train)
h = F.dropout(F.max_pooling_2d(h, 2), 0.25, train=train)
h = self.bconv2_1(h, train)
h = self.bconv2_2(h, train)
h = F.dropout(F.max_pooling_2d(h, 2), 0.25, train=train)
h = self.bconv3_1(h, train)
h = self.bconv3_2(h, train)
h = self.bconv3_3(h, train)
h = self.bconv3_4(h, train)
h = F.dropout(F.max_pooling_2d(h, 2), 0.25, train=train)
h = F.relu(self.fc4(F.dropout(h, train=train)))
h = F.relu(self.fc5(F.dropout(h, train=train)))
h = self.fc6(h)
return h
以下のコマンドで実行します。
"-m vgg"でVGG likeなモデルを指定しています。
実行には5時間半くらいかかりました。
$ python src/train.py -g 0 -m vgg -b 128 -p vgg_adam --optimizer adam --iter 300 --lr_decay_iter 100
エラー率は7.65%になり、認識精度が向上しています。
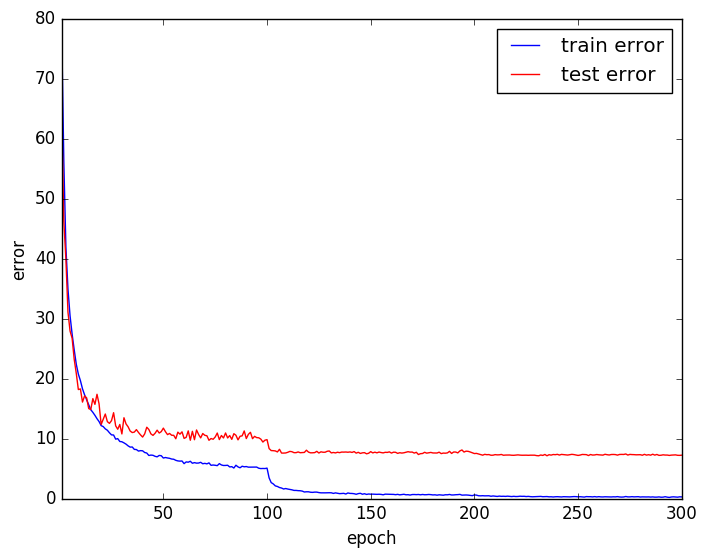
Residual Networkを使う
Residual Networkは、恒等変換とCNN複数レイヤーを組み合わせることで階層を深くしてもうまく学習を行えるようにしたネットワークです。
この記事に詳しく書かれています。
今回実装したネットワークは全部で74 layerで以下の構成になっています。
レイヤーの数え方ですが、Residual BlockはCNNを2 layer使っているので、Residual Block 1個で 2 layerと数えています。
- CNN + Batch Normalization + 1 layer
- Residual Block 36個(72 layer)
- Fully Connected 1 layer
本当は110 layerにしたかったのですがGPUメモリ不足で実行できませんでした。
入力画像を小さくして24 x 24pxにした場合は110 layerで実行できることを確認しています。
Chainerでのネットワークの実装は以下のようになります。
class ResidualBlock(chainer.Chain):
def __init__(self, ch_in, ch_out, stride=1, swapout=False, skip_ratio=0, activation1=F.relu, activation2=F.relu):
w = math.sqrt(2)
super(ResidualBlock, self).__init__(
conv1=L.Convolution2D(ch_in, ch_out, 3, stride, 1, w),
bn1=L.BatchNormalization(ch_out),
conv2=L.Convolution2D(ch_out, ch_out, 3, 1, 1, w),
bn2=L.BatchNormalization(ch_out),
)
self.activation1 = activation1
self.activation2 = activation2
self.skip_ratio = skip_ratio
self.swapout = swapout
def __call__(self, x, train):
skip = False
if train and self.skip_ratio > 0 and np.random.rand() < self.skip_ratio:
skip = True
sh, sw = self.conv1.stride
c_out, c_in, kh, kw = self.conv1.W.data.shape
b, c, hh, ww = x.data.shape
if sh == 1 and sw == 1:
shape_out = (b, c_out, hh, ww)
else:
hh = (hh + 2 - kh) // sh + 1
ww = (ww + 2 - kw) // sw + 1
shape_out = (b, c_out, hh, ww)
h = x
if x.data.shape != shape_out:
xp = chainer.cuda.get_array_module(x.data)
n, c, hh, ww = x.data.shape
pad_c = shape_out[1] - c
p = xp.zeros((n, pad_c, hh, ww), dtype=xp.float32)
p = chainer.Variable(p, volatile=not train)
x = F.concat((p, x))
if x.data.shape[2:] != shape_out[2:]:
x = F.average_pooling_2d(x, 1, 2)
if skip:
return x
h = self.bn1(self.conv1(h), test=not train)
if self.activation1 is not None:
h = self.activation1(h)
h = self.bn2(self.conv2(h), test=not train)
if not train:
h = h * (1 - self.skip_ratio)
if self.swapout:
h = F.dropout(h, train=train) + F.dropout(x, train=train)
else:
h = h + x
if self.activation2 is not None:
return self.activation2(h)
else:
return h
class ResidualNet(chainer.Chain):
def __init__(self, depth=18, swapout=False, skip=True):
super(ResidualNet, self).__init__()
links = [('bconv1', BatchConv2D(3, 16, 3, 1, 1), True)]
skip_size = depth * 3 - 3
for i in six.moves.range(depth):
if skip:
skip_ratio = float(i) / skip_size * 0.5
else:
skip_ratio = 0
links.append(('res{}'.format(len(links)), ResidualBlock(16, 16, swapout=swapout, skip_ratio=skip_ratio, ), True))
links.append(('res{}'.format(len(links)), ResidualBlock(16, 32, stride=2, swapout=swapout), True))
for i in six.moves.range(depth - 1):
if skip:
skip_ratio = float(i + depth) / skip_size * 0.5
else:
skip_ratio = 0
links.append(('res{}'.format(len(links)), ResidualBlock(32, 32, swapout=swapout, skip_ratio=skip_ratio), True))
links.append(('res{}'.format(len(links)), ResidualBlock(32, 64, stride=2, swapout=swapout), True))
for i in six.moves.range(depth - 1):
if skip:
skip_ratio = float(i + depth * 2 - 1) / skip_size * 0.5
else:
skip_ratio = 0
links.append(('res{}'.format(len(links)), ResidualBlock(64, 64, swapout=swapout, skip_ratio=skip_ratio), True))
links.append(('_apool{}'.format(len(links)), F.AveragePooling2D(8, 1, 0, False, True), False))
links.append(('fc{}'.format(len(links)), L.Linear(64, 10), False))
for name, f, _with_train in links:
if not name.startswith('_'):
self.add_link(*(name, f))
self.layers = links
def __call__(self, x, train=True):
h = x
for name, f, with_train in self.layers:
if with_train:
h = f(h, train=train)
else:
h = f(h)
return h
swapoutというパラメータがありますが、実験的な実装なので今は無視してください。
Residual Blockでは、入力と出力のサイズが異なる場合(幅と高さは出力の方が小さく、チャンネル数は同じか出力の方が大きい)に恒等変換部分について以下のようにします。
- x, y方向についてはAverage Poolingを使う
- channel方向については増加した分を0で埋める
以下のコマンドで実行します。
python src/train.py -g 0 -m residual -b 128 -p residual --res_depth 12 --optimizer sgd --lr 0.1 --iter 300 --lr_decay_iter 100
-m residualがResidual Networkの指定です。
--optimizer sgdはMomentumSGDを使う指定で、Adamを使った場合よりも良い結果になりました。
学習率の初期値は0.1が良いようです。
以下に挙げるResidual Networkを使ったCIFAR-10画像分類の実装では学習率の初期値が0.1になっていました。
実行には約10時間かかりました。
テストエラー率は8.06%と、VGG likeなモデルよりも悪い結果になりました。
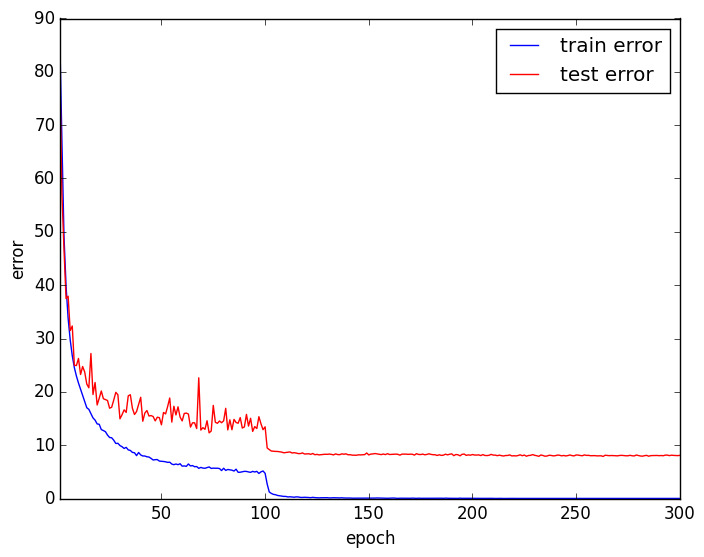
Stochastic Depthを使う
Stochastic Depthは、学習時に確率的にResidual Blockをスキップする手法です。
説明はこの記事が詳しいです。
ネットワークのコードはResidual Networkを使うに掲載しました。
ReisualBlockにskip_ratioというプロパティを持たせ、学習時にはskip_ratioに指定した確率でResidual BlockのCNN部を実行しないようにします。
テスト時にはCNN部を(1 - skip_ratio)倍した値を使います。
skip_ratioには傾斜をつけてより、Residual Blockが深い位置にあるほどskip_ratioが大きくなるようにしました。
今回は先頭のResidual Blockはskip_ratioが0、最深部のskip_ratioは0.5、その間にあるBlockについては線形に変化させました。
以下のコマンドで実行します。
python src/train.py -g 0 -m residual -b 128 -p residual_skip --skip_depth --res_depth 12 --optimizer sgd --lr 0.1 --iter 300 --lr_decay_iter 100
--skip_depthがStochastic Depthを使用するオプションです。
学習には約9時間かかりました。
テストエラー率は7.42%になり、精度が向上しました。
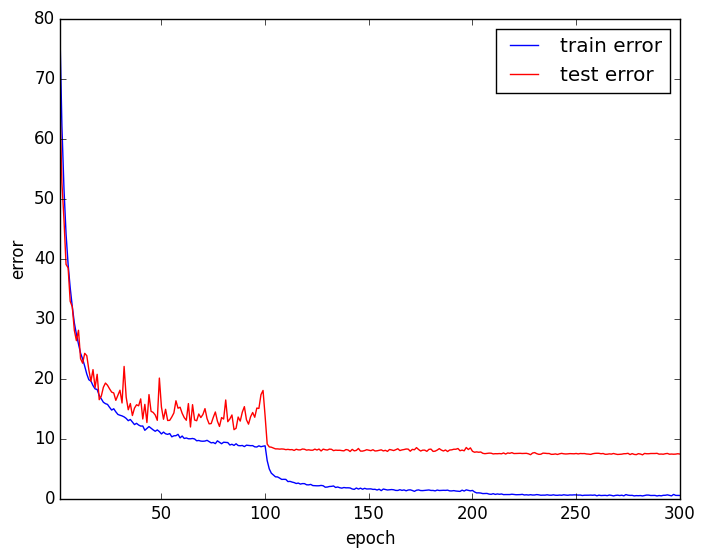
まとめ
様々なモデルを使ってCIFAR-10画像データセットの分類を行いました。
前処理の違い、Batch Normalizationの有無、モデルの違いによる認識率の差を確認できました。
今回はChainerで実装しましたが、例えばTorch7によるStochastic Depthの実装は今回使用した実装よりも高速・省メモリとなっていて、同じ環境(Ubuntu)で56layerのResidual Networkを学習させることができました。
よりDeepなモデルを実行したいという方は、別のフレームワークを検討するのもよいと思います。