はじめに
本シリーズは,Treasure Data,つまり基本SQLで実現可能な様々なアクセスログ分析事例を具体的なクエリと可視化を交えて紹介していくブログです。多くは当たり前のものですが,時には実に良く捻られたものと思って頂けるよう,私が知りうる限りの全ての事例を提供していく予定です。
今回の内容を理解するに当たって,参考になる記事を挙げておきます。
- 『優しく学ぶ Treasure Data』その① 〜日付関数(DATE UDF)を理解しよう〜
- 『Treasure Data でアクセスログ分析の限界に挑む』その① 〜「日次」「週次」「月次」の集計を正しく理解する〜
- 『Treasure Data でアクセスログ分析の限界に挑む』その② 〜アクセスに基づいたユーザーセグメントの作成 月次編(アクティビティ)〜
- 『Treasure Data でアクセスログ分析の限界に挑む』その② 〜アクセスに基づいたユーザーセグメントの作成 月次編(頻度)〜
- 『Treasure Data でアクセスログ分析の限界に挑む』その③ 〜アクセスに基づいたユーザーセグメントの作成 月次編(平日/土日)〜
今回のテーマ
今回は『ユーザーがアクセスしたか否か』,この一点のみに着目してそこから導き出される様々な指標を導出します。
そして,これらが今後有益なユーザー『セグメント』として機能して行くことをお見せします。
- これから数回に渡って「日次」「週次」「月次」それぞれについて,「アクセスの有無」に基づいた様々な指標を求めるクエリを紹介します。
- セグメント対象となるユーザーは,特定の範囲内のユーザーではなく,常にデータベース上の全ユーザーとなります。
- 今回は「月次編」の「時間別のアクセスタイプ」に着目します。
前提とするデータ定義
本シリーズでは以下の様な pageview テーブルを想定していきますが,多くの場合では time カラムと td_client_id カラム(または何らかのユーザーを識別するカラム)しか使いませんので,アクセスログに限らず様々なログで応用可能です。
| time | td_client_id | td_title | td_ip |
|---|---|---|---|
| 1542956154 | c445a751288 | Treasure Data | 72.215.178.105 |
| 1542955952 | 6b5a0357b2f | Treasure Data | 103.206.191.199 |
| 1542955625 | 344503ae8cb | td command line tool reference | 185.3.22.17 |
| 1542954891 | 178e1a1d3e4 | SQL & Performance Tuning Tips | 103.250.170.50 |
| 1542954151 | f556371264a | Installing and Updating... | 39.110.208.102 |
| 1542953658 | c31baa01dfe | Planning and Implementation... | 203.132.82.75 |
| 1542953160 | 9894e8afc72 | gtm-msr | 66.102.8.8 |
要旨
今回は,月次のユーザーセグメントを求める方法を紹介する第4回目です。
前月に基づく Period Time Segment
また,1日のアクセスの中でも,どの時間帯の PV が多いのか,時間帯での内訳を見ることでユーザーを分類します。ただ,時間帯の区分の仕方というのはサイトの性質や分析の目的によって様々に異なるものですから,多分に多様性があります。
この時間帯のセグメント分けの方法でまず考えられるのは, '時間(24区分)' ごとに分けた上でいくつかの集合に統合することです。一般的には [00時, 06時),[06時, 12時),[12時, 18時),[18時, 24時) のようにどの区分の中にも等しい数の '時間' が入るべきですが,今回は応用例として以下の様にユーザーの行動時間帯で区分することにします。
- 「朝〜出勤(morning)」: 06時〜10時
- 「会社(working)」: 10時〜17時
- 「帰宅〜夜(night)」: 17時〜24時
- 「就寝(sleeping)」: 24時〜06時
この分類の上で,以下のルールによりセグメントを作ります。
- ルール1. 頻度および PV の意味で 50% 以上をその時間帯に閉める1組 → その時間帯に特化
- ルール2. 頻度および PV の意味で 30% 以上をその時間帯に閉める2組 → その2組の時間帯に特化
ルールはいくらでも複雑にできますが,それに増してクエリの記述料が増えますので気をつけて下さい。
今回は以下の様な集計結果が得られます。後ほど詳説していきます。
| target_month | segment | cnt |
|---|---|---|
| 2018/10/01 | working | 5987 |
| 2018/10/01 | sleeping | 2409 |
| 2018/10/01 | night | 2367 |
| 2018/10/01 | morning | 1591 |
| 2018/10/01 | sleeping,morning | 38 |
| 2018/10/01 | morning,working | 19 |
| 2018/10/01 | sleeping,working | 18 |
| 2018/10/01 | alltime | 14 |
| 2018/10/01 | working,night | 7 |
| 2018/10/01 | sleeping,night | 5 |
| 2018/10/01 | morning,night | 4 |
4. Period Time Segment (時間帯)
まず初めに,普通の時間帯の集計方法であれば,数ステップの集計を踏むことになります。
- まず,ユーザー当たり '時間(24区分)' ごとの集計を行い,テーブルに格納する。このテーブルは今までのユーザーセグメントの結果と違って, 1ユーザー当たり1レコードでは無く24レコードになっている事に注意してください。
- 各時間がどの時間帯に属するかの24行のマスタテーブルを作成する。
- 1.の結果をインプットとして2.のマスタテーブルを充てた上で時間帯ごとの集計などを行う。
しかし,今回は以上のような数ステップを踏まずに,1つのクエリ内でセグメント分けを行う,前回までの手順を無視した方法で行います。理由として,
- 上記のような数ステップで行う方が作業コストが高い
- 上のようなステップでやっても汎用性がうまく確保できない
があります。これは実際にやってみないと感じることでは無いのですが,私はそう感じています。
さて,今回の長く,そして汎用性の無いクエリを以下に紹介します。ただ,このクエリを理解しさえすれば,うまく書き換えてすぐにセグメントが出せる便利なものになっています。
/* TD_SCHEDULED_TIME() = '2018-11-23 11:11:00' */
/*
SELECT target_month, segment, COUNT(1) AS cnt
FROM
(
*/
SELECT target_month,
CASE
WHEN 50<=ratio_freq_sleeping OR 50<=ratio_pv_sleeping THEN 'sleeping'
WHEN 50<=ratio_freq_morning OR 50<=ratio_pv_morning THEN 'morning'
WHEN 50<=ratio_freq_working OR 50<=ratio_pv_working THEN 'working'
WHEN 50<=ratio_freq_night OR 50<=ratio_pv_night THEN 'night'
WHEN
(30<=ratio_freq_sleeping OR 30<=ratio_pv_sleeping) AND (30<=ratio_freq_morning OR 30<=ratio_pv_morning)
THEN 'sleeping,morning'
WHEN
(30<=ratio_freq_sleeping OR 30<=ratio_pv_sleeping) AND (30<=ratio_freq_working OR 30<=ratio_pv_working)
THEN 'sleeping,working'
WHEN
(30<=ratio_freq_sleeping OR 30<=ratio_pv_sleeping) AND (30<=ratio_freq_night OR 30<=ratio_pv_night)
THEN 'sleeping,night'
WHEN
(30<=ratio_freq_morning OR 30<=ratio_pv_morning) AND (30<=ratio_freq_working OR 30<=ratio_pv_working)
THEN 'morning,working'
WHEN
(30<=ratio_freq_morning OR 30<=ratio_pv_morning) AND (30<=ratio_freq_night OR 30<=ratio_pv_night)
THEN 'morning,night'
WHEN
(30<=ratio_freq_working OR 30<=ratio_pv_working) AND (30<=ratio_freq_night OR 30<=ratio_pv_night)
THEN 'working,night'
WHEN freq IS NULL THEN 'non_active'
ELSE 'alltime'
END AS segment,
freq, freq_sleeping, freq_morning, freq_working, freq_night,
ratio_freq_sleeping, ratio_freq_morning, ratio_freq_working, ratio_freq_night,
pv, pv_sleeping, pv_morning, pv_working, pv_night,
ratio_pv_sleeping, ratio_pv_morning, ratio_pv_working, ratio_pv_night
FROM
(
SELECT
TD_TIME_FORMAT(TD_DATE_TRUNC('month', TD_DATE_TRUNC('month', TD_SCHEDULED_TIME(),'JST')-1, 'JST'),'yyyy-MM-dd','JST') AS target_month,
IF(past_month.td_client_id IS NOT NULL, past_month.td_client_id, past_month_ago.td_client_id ) AS td_client_id,
freq, freq_sleeping, freq_morning, freq_working, freq_night,
ROUND(1.0*freq_sleeping/freq,2)*100 AS ratio_freq_sleeping,
ROUND(1.0*freq_morning /freq,2)*100 AS ratio_freq_morning,
ROUND(1.0*freq_working /freq,2)*100 AS ratio_freq_working,
ROUND(1.0*freq_night /freq,2)*100 AS ratio_freq_night,
pv, pv_sleeping, pv_morning, pv_working, pv_night,
ROUND(1.0*pv_sleeping/pv,2)*100 AS ratio_pv_sleeping,
ROUND(1.0*pv_morning /pv,2)*100 AS ratio_pv_morning,
ROUND(1.0*pv_working /pv,2)*100 AS ratio_pv_working,
ROUND(1.0*pv_night /pv,2)*100 AS ratio_pv_night,
min_time, max_time
FROM
(
SELECT
td_client_id,
SUM(IF(hour IN ('00','01','02','03','04','05'), 1, 0)) AS freq_sleeping,
SUM(IF(hour IN ('06','07','08','09'), 1, 0)) AS freq_morning,
SUM(IF(hour IN ('10','11','12','13','14','15','16','17'), 1, 0)) AS freq_working,
SUM(IF(hour IN ('18','19','20','21','22','23'), 1, 0)) AS freq_night,
COUNT(1) AS freq,
SUM(IF(hour IN ('00','01','02','03','04','05'), pv, 0)) AS pv_sleeping,
SUM(IF(hour IN ('06','07','08','09'), pv, 0)) AS pv_morning,
SUM(IF(hour IN ('10','11','12','13','14','15','16','17'), pv, 0)) AS pv_working,
SUM(IF(hour IN ('18','19','20','21','22','23'), pv, 0)) AS pv_night,
SUM(pv) AS pv,
TD_TIME_FORMAT(MIN(min_time),'yyyy-MM-dd','JST') AS min_time, TD_TIME_FORMAT(MAX(max_time),'yyyy-MM-dd','JST') AS max_time
FROM
(
SELECT td_client_id, TD_DATE_TRUNC('day',time,'JST') AS access_day, TD_TIME_FORMAT(time,'HH','JST') AS hour, COUNT(1) AS pv, MIN(time) AS min_time, MAX(time) AS max_time
FROM pageviews
WHERE TD_INTERVAL(time, '-1M', 'JST')
GROUP BY td_client_id, TD_DATE_TRUNC('day',time,'JST'), TD_TIME_FORMAT(time,'HH','JST')
)
GROUP BY td_client_id
) past_month
FULL OUTER JOIN
(
SELECT td_client_id
FROM pageviews
WHERE TD_INTERVAL(time, '-10y/-1M', 'JST') /* 1ヶ月前より過去 */
GROUP BY td_client_id
) past_month_ago
ON past_month.td_client_id = past_month_ago.td_client_id
)
/* 前月分のみのユーザーのみ取得で良いのならば past_month_ago サブクエリは不要 *//*
)
GROUP BY target_month, segment HAVING segment != 'non_active'
ORDER BY cnt DESC
*/
クエリのポイント
1. '時間' ごとの集計
SELECT td_client_id, TD_DATE_TRUNC('day',time,'JST') AS access_day, TD_TIME_FORMAT(time,'HH','JST') AS hour,
COUNT(1) AS pv, MIN(time) AS min_time, MAX(time) AS max_time
FROM pageviews
WHERE TD_INTERVAL(time, '-1M', 'JST')
GROUP BY td_client_id, TD_DATE_TRUNC('day',time,'JST'), TD_TIME_FORMAT(time,'HH','JST')
上のクエリで, 日毎かつ時間毎の集計を行っています。 TD_TIME_FORMAT(time,'HH','JST') は, 与えられた time における時間: '00'〜'23' までの文字列を返す関数です。いきなり時間毎の集計を期間内全日で行っても良いですが,日毎の指標値を得たい応用の場合などを考え,日毎かつ時間毎にするのをお薦めします。
2. SUM(IF) による, Pivot 化
SUM(IF(hour IN ('00','01','02','03','04','05'), 1, 0)) AS freq_sleeping,
SUM(IF(hour IN ('06','07','08','09'), 1, 0)) AS freq_morning,
SUM(IF(hour IN ('10','11','12','13','14','15','16','17'), 1, 0)) AS freq_working,
SUM(IF(hour IN ('18','19','20','21','22','23'), 1, 0)) AS freq_night,
- の時間毎の集計で得られたレコードは,同じユーザーでも各時間によって複数のレコードに分かれています。(これを「縦になっている」と呼びます。)これから時間帯ごとの比率を計算するのに当たって,この「縦になっている」状態は結構大変です。ですので上のクエリはこのユーザー当たり縦のレコードを「横にする(異なるカラムに分ける)」作業を上で行っています。
3. 時間帯ごとの(全体に対する)割合の計算
ROUND(1.0*freq_sleeping/freq,2)*100 AS ratio_freq_sleeping,
ROUND(1.0*freq_morning /freq,2)*100 AS ratio_freq_morning,
ROUND(1.0*freq_working /freq,2)*100 AS ratio_freq_working,
ROUND(1.0*freq_night /freq,2)*100 AS ratio_freq_night,
今, freq にはユーザーの全時間帯の合計頻度が入っているとします。(ここでの freq は,1日で各時間帯でアクセスが1回でもある場合に1となりますから,1日でも最高4の値をとります。)一方, freq_* は各々の時間帯での頻度です。上では, 全体に対してそれぞれの時間帯での比率を求め,四捨五入した上で % での値を出しています。故にこの4つの比率の和を取ると 100% になります。pv の方でも同じ事をやっています。
4. 前月存在しなかったユーザーを出す必要が無ければパフォーマンスを上げられる
ここでも前回までの慣例に従って,前月登場しなかったユーザーも登場させるようにしています。(もちろん全ての freq の値が NULL となり,ここではあまり意味がありません。)前月までの全ての過去にアクセスする以下のサブクエリを取り除き,
FULL OUTER JOIN
(
SELECT td_client_id
FROM pageviews
WHERE TD_INTERVAL(time, '-10y/-1M', 'JST') /* 1ヶ月前より過去 */
GROUP BY td_client_id
) past_month_ago
ON past_month.td_client_id = past_month_ago.td_client_id
かつ,上の方にある
IF(past_month.td_client_id IS NOT NULL, past_month.td_client_id, past_month_ago.td_client_id ) AS td_client_id,
この記述を純粋に td_client_id に書き換えれば,かなりのパフォーマンスアップを図る事ができます。
結果(ユーザー毎)
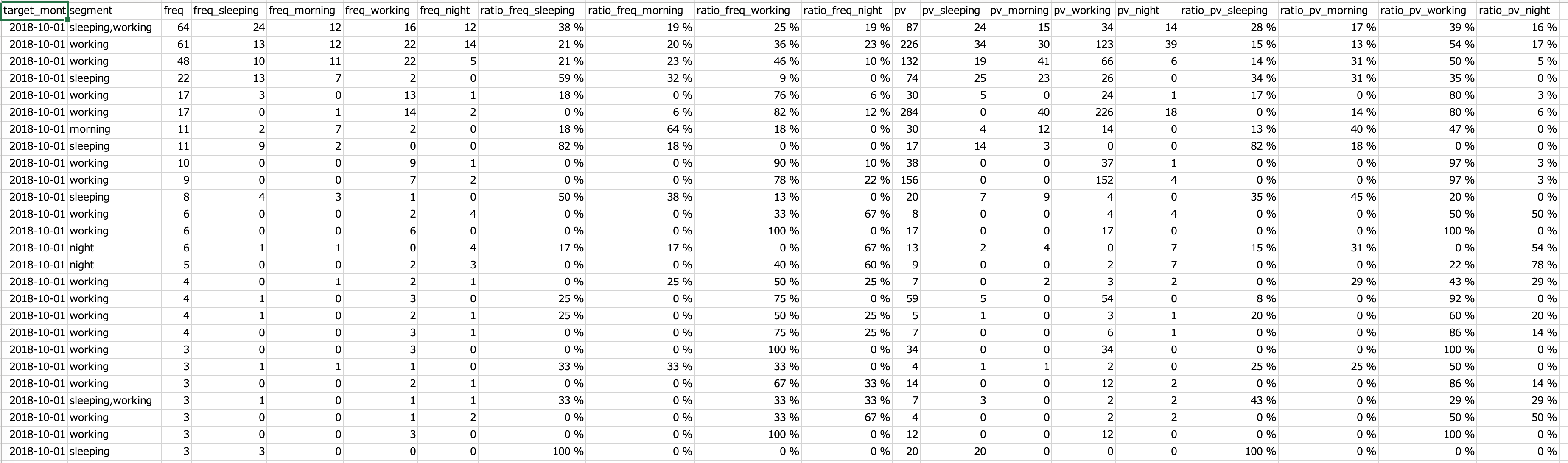
| segment | ratio_freq_sleeping | ratio_freq_morning | ratio_freq_working | ratio_freq_night | ratio_pv_sleeping | ratio_pv_morning | ratio_pv_working | ratio_pv_night |
|---|---|---|---|---|---|---|---|---|
| sleeping,working | 38 % | 19 % | 25 % | 19 % | 28 % | 17 % | 39 % | 16 % |
| working | 21 % | 20 % | 36 % | 23 % | 15 % | 13 % | 54 % | 17 % |
| working | 21 % | 23 % | 46 % | 10 % | 14 % | 31 % | 50 % | 5 % |
| sleeping | 59 % | 32 % | 9 % | 0 % | 34 % | 31 % | 35 % | 0 % |
| working | 18 % | 0 % | 76 % | 6 % | 17 % | 0 % | 80 % | 3 % |
| working | 0 % | 6 % | 82 % | 12 % | 0 % | 14 % | 80 % | 6 % |
| morning | 18 % | 64 % | 18 % | 0 % | 13 % | 40 % | 47 % | 0 % |
| sleeping | 82 % | 18 % | 0 % | 0 % | 82 % | 18 % | 0 % | 0 % |
| working | 0 % | 0 % | 90 % | 10 % | 0 % | 0 % | 97 % | 3 % |
| working | 0 % | 0 % | 78 % | 22 % | 0 % | 0 % | 97 % | 3 % |
| sleeping | 50 % | 38 % | 13 % | 0 % | 35 % | 45 % | 20 % | 0 % |
| working | 0 % | 0 % | 33 % | 67 % | 0 % | 0 % | 50 % | 50 % |
| working | 0 % | 0 % | 100 % | 0 % | 0 % | 0 % | 100 % | 0 % |
| night | 17 % | 17 % | 0 % | 67 % | 15 % | 31 % | 0 % | 54 % |
| night | 0 % | 0 % | 40 % | 60 % | 0 % | 0 % | 22 % | 78 % |
| working | 0 % | 25 % | 50 % | 25 % | 0 % | 29 % | 43 % | 29 % |
| working | 25 % | 0 % | 75 % | 0 % | 8 % | 0 % | 92 % | 0 % |
| working | 25 % | 0 % | 50 % | 25 % | 20 % | 0 % | 60 % | 20 % |
| working | 0 % | 0 % | 75 % | 25 % | 0 % | 0 % | 86 % | 14 % |
| working | 0 % | 0 % | 100 % | 0 % | 0 % | 0 % | 100 % | 0 % |
| working | 33 % | 33 % | 33 % | 0 % | 25 % | 25 % | 50 % | 0 % |
| working | 0 % | 0 % | 67 % | 33 % | 0 % | 0 % | 86 % | 14 % |
| sleeping,working | 33 % | 0 % | 33 % | 33 % | 43 % | 0 % | 29 % | 29 % |
| working | 0 % | 0 % | 33 % | 67 % | 0 % | 0 % | 50 % | 50 % |
結果で見るべきは上の9カラムで,先頭を除く前半4つが freq における割合, 後半4つが pv における割合を表しており,それぞれで「横」を見て傾向がないかを見ていきます。
今, freq の意味または pv の意味でどれかの時間帯の割合が 50% 以上であれば,十分にこの時間対に特化していると言うことができます。また,そうなっていないもので, どれか2つで 30% 以上の割合を占めていればその2つの時間帯に特化しているとここでは言うことにします。
結果(集計値)
クエリの上下のコメントを外して集計した結果が以下になります。
| target_month | segment | cnt |
|---|---|---|
| 2018/10/01 | working | 5987 |
| 2018/10/01 | sleeping | 2409 |
| 2018/10/01 | night | 2367 |
| 2018/10/01 | morning | 1591 |
| 2018/10/01 | sleeping,morning | 38 |
| 2018/10/01 | morning,working | 19 |
| 2018/10/01 | sleeping,working | 18 |
| 2018/10/01 | alltime | 14 |
| 2018/10/01 | working,night | 7 |
| 2018/10/01 | sleeping,night | 5 |
| 2018/10/01 | morning,night | 4 |
今回は 50% 以上の割合でその時間帯に特化としましたが,これを 60% や 75% にすれば, 2つの時間に特化したセグメントの数がそこから移動してくると思います。この当たりは各自の判断で適切な数値設定をして頂ければと思います。
本日は以上です。