はじめに
Treasure Data にはたくさんの独自関数(UDF)が存在しますが,その中でも日付に関する関数(DATE UDF)の充実とその便利さは群を抜いています。せっかくトレジャーデータを活用しているのですから,このメリットを享受しないのは大変もったいないと考えます。そこで,トレジャーデータ公式ドキュメントを補間する形で,より丁寧に紹介していきます。
また, DATE UDF を使いこなすためのトレーニングページ, 及びより実践での利用例を紹介する実践ページを順次用意していきます。
トレーニングページ
- 『SQLトレーニング』その① 〜Treasure Data の日付関数(DATE UDF)編〜 ← 後日公開
実践ページ
TD_TIME_FORMAT
様式
string TD_TIME_FORMAT( time, format, 'JST')
TD_TIME_FORMAT は第一引数で与えられた unixtime を format で定めた日付文字列に変換するクエリです。本ブログにおける format は以下のものに統一しておりますので,その他の format やルールなどについては公式ドキュメントを参照ください。
TD_TIME_FORMAT( time, 'yyyy-MM-dd', 'JST') # 2018-01-01
TD_TIME_FORMAT( time, 'yyyy-MM-dd HH:mm:ss', 'JST') # 2018-01-01 00:00:00
TD_TIME_RANGE
様式
boolean TD_TIME_RANGE(time, start_time, end_time, 'JST')
TD_TIME_RANGE は関数の引数として start_time(始点)と end_time(終点)を定めることによって,この範囲内に該当するレコードのみを抽出する条件句に使用される関数です。
1番目の引数はレコード内の unixtime を持ったカラムを指定します。基本的には time カラムとなるでしょう。2番目の「始点」と3番目の「終点」をうまく指定できれば,この関数は大変便利に使用することができます。
A. 特定の時間軸での範囲指定
SELECT ... WHERE TD_TIME_RANGE(time, '2018-01-01', '2018-02-01','JST') # 月
SELECT ... WHERE TD_TIME_RANGE(time, '2018-01-01', '2018-01-08','JST') # 週
SELECT ... WHERE TD_TIME_RANGE(time, '2018-01-01', '2018-01-02','JST') # 日
SELECT ... WHERE TD_TIME_RANGE(time, '2018-01-01 00:00:00', '2018-01-01 01:00:00','JST') # 時間
SELECT ... WHERE TD_TIME_RANGE(time, '2018-01-01 00:00:00', '2018-01-01 00:01:00','JST') # 分
特定の時間範囲内のレコードを抽出するには,上の様なコードを書きます。いくつかの注意点を述べておきます。
1.「始点」は含まれ,「終点」は含まれない
上の例えば月の範囲の指定を見たときに,「この句では2月1日も含まれるのでは?」と思う人もいるかもしれません。答えはNOで,始点は含まれますが終点の時間は含まれません。始点(00:00:00)ちょうどから,終点ぎりぎり(23:59:59.999)までの時間までが含まれるのです。数学的に書くと [始点,終点) となります。逆に終点が含まれないような仕様では簡易かつ厳密に月単位の集計を行う事ができません。
2.「始点」,「終点」には unixtime に加え,様式に従った日付文字列も指定可能
先ほどの例は,「始点」「終点」に明確な時間が定まっているために,日付文字列として記述できました。しかし,実際の定時実行される自動クエリにおいては,ここに TD_DATE_TRUNC などの関数が入ってくることになり,またその場合は値として unixtime が指定されていることになります。他の関数では日付文字列が NG となるものもありますので注意してください。
3.TD_TIME_RANGE を使うと使わないとではパフォーマンスが圧倒的に異なる
Treasure Data を初めとしたビッグデータプラットフォームでは,大量のレコードを時間単位でパーティショニングして別々の場所に置かれています。TD_TIME_RANGE を使用すれば,指定された範囲外の時間のレコードについては,そもそもアクセスしに行きません。特に過去大量に蓄積されたデータにおいては,全てのパーティションを見に行くか,特定のパーティションだけを見に行くかで圧倒的にクエリ処理速度が異なってきます。
なお,パーティションの効率化を使用できない時間範囲指定というのは,例えば
WHERE start_time <= time AND time < end_time # NG
のようなものですね。また,TD_TIME_RANGE を使ってもルールに基づかない以下の様な記述の仕方をしてしまうと,同じようにパーティショニングが使えません。
SELECT ... WHERE TD_TIME_RANGE(time, '2013-01-01','JST') # NG
この関数では「終点」の記述を省くことで,「始点以降」という範囲とする事ができるのですが,こちらは書き方に注意が必要です。
B. 「始点以降」,「終点未満」
注:「以降」という言葉はその点を含み,「未満」という言葉はその点を含みません。
多くの分析では始点と終点が定まっているよりも,ある日「以降」であったり,昨日まで(=今日未満)の集計を行いたいケースもよくあります。この場合,始点か終点に NULL を入れる事で目的を達成することができます。
SELECT ... WHERE TD_TIME_RANGE(time, '2018-01-01', NULL, 'JST') # 始点以降
SELECT ... WHERE TD_TIME_RANGE(time, NULL, '2018-01-01', 'JST') # 終点未満
SELECT ... WHERE TD_TIME_RANGE(time, NULL, '2018-01-01 JST') # 始点以降
先ほどの注意点 A.3 における正解の書き方は上の1番目と3番目ですが,3番目は間違いやすい記述方式ですので本ブログでは一貫して1番目と2番目の「NULL」を含む記述方式を支持します。
TD_DATE_TRUNC
様式
long TD_DATE_TRUNC(unit, time, 'JTC')
TD_DATE_TRUNC は,指定された時間をあらゆる時間単位で「切り捨て」てくれる便利な関数です。TD_DATE_TRUNC は主にTD_TIME_RANGE内の「始点」と「終点」で設定されます。
2番目の time カラムは unixtime の値であり,日付文字列ではいけません。一般的にはこの2番目のカラムに入る変数は2種類あり,
- レコード内の time カラム
- TD_SCHEDULED_TIME() の値
TD_SCHEDULED_TIME は後述しますが,外側から任意の時間を挿入することができる便利な変数(関数)です。
また,日付ユニットには以下の種類があります:
- 'minute'
- 'hour'
- 'day'
- 'week'
- 'month'
- 'quarter'
- 'year'
今, 2番目の引数の time カラムの値が '2018-11-23 11:11:00' の unixtime であったとします。この時,この関数によってどんな値が返ってくるのでしょうか?以下の例では,次の時間の unixtime (時間文字列ではありません!)が返ってきます。
SELECT TD_DATE_TRUNC('hour', time) FROM ... # 時間の始まり: 2018-11-23 11:00:00
SELECT TD_DATE_TRUNC('day', time) FROM ... # 日の始まり: 2018-11-23 00:00:00
SELECT TD_DATE_TRUNC('week', time) FROM ... # 週の始まり: 2018-11-19 00:00:00 (週始まりは月曜日!)
SELECT TD_DATE_TRUNC('month', time) FROM ... # 月の始まり: 2018-11-01 00:00:00
SELECT TD_DATE_TRUNC('year', time) FROM ... # 年の始まり: 2018-01-01 00:00:00
このように,半端な時間を持った time カラムを各日付ユニットの「始点」に値を切り捨ててくれる便利な関数です。
TD_TIME_ADD
様式
long TD_TIME_ADD( time, duration, 'JST')
TD_TIME_ADD は第一引数に指定された unixtime または時間文字列に対して, duration 分の時間の加減算を行ってくれる便利な関数です。time カラムが unixtime であれば普通に秒数(例えば1日分だと 606024 秒)の加減算をしても良いのですが,できる限りこの関数を活用することを以下の意味で強く推奨します。
- 時間文字列に対しても加減算ができる
- どの時間軸で加減算しているのかが明確でコードの可読性があがる
- '-1h30m' = '1時間30分前' といった半端な時間の加減算にも対応している
duration のバリエーション
- 'Nd': N日後 (e.g. '1d', '2d', '30d')
- 'Nd': N日前 (e.g. '-1d', '-2d', '-30d')
- 'Nh': N時間後 (e.g. '1h', '2h', '48h')
- 'Nh': N時間前 (e.g. '-1h', '-2h', '-48h')
- 'Nm': N分後 (e.g. '1m', '2m', '90m')
- 'Nm': N分前 (e.g. '-1m', '-2m', '-90m')
- 'Ns': N秒後 (e.g. '1s', '2s', '90s')
- 'Ns': N秒前 (e.g. '-1s', '-2s', '-90s')
- 'NdMhLs': N日M時間L分後 (e.g. '1d6h30m', '-2d3h', '-1h30m')
TD_SCHEDULED_TIME
様式
long TD_SCHEDULED_TIME()
TD_SCHEDULED_TIME はそのクエリが実行された時の unixtime を返すもので,バッチクエリ(定時実行クエリ)として登録されたクエリに関しては,毎回そのクエリが実行された時間が入ります。
A. バッチクエリで使用する場合
トレジャーデータでは,クエリをスケジュール登録することができ,任意の時間単位で定時実行する事が可能です。
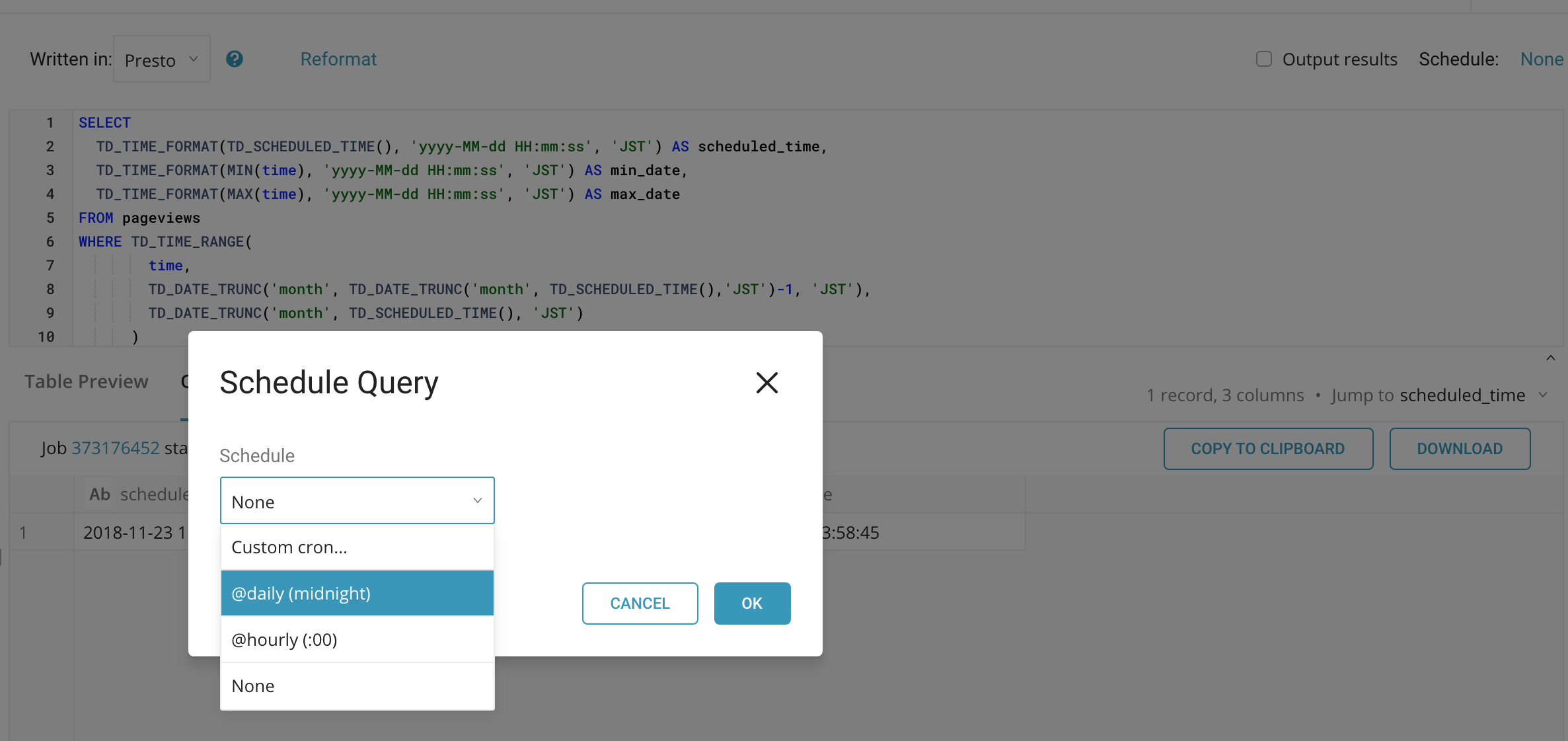
そのバッチクエリ内で TD_SCHEDULED_TIME を使用した場合,クエリが実行された時刻がこの値としてクエリ内で使用される事になります。例えば daily を指定すれば,毎日日付が変わる時間:「00:00:00」に実行されることになり,この時TD_SCHEDULED_TIME()の値には「2018-11-24 00:00:00」の unixtime が入ることになります。ここで以下のポイントをおさえておいてください。
スケジュールされた時間と実際に実行された時間は異なる
丁度日付が変わった時点でクエリを実行するようにスケジュールしていたとしても,実際には他の処理の混み具合などによって実際に実行される時間は遅延する場合が多いです。 例えば, daily で 「00:00:00」の実行をスケジュールしたのに,実際の処理は遅延がおこって「06:00:00」に実行されてしまった場合,
a. 「スケジュールされた(予定通りの)時間 = 00:00:00」
b. 「実際に実行された時間 = 06:00:00」
のどちらの unixtime が入るのでしょうか?
TD_SCHEDULED_TIME()はいつでもスケジュール時間が入り, 実際の実行時の時間がはいる NOW() とは違う
答えは a.であり,処理がどんなに遅延したとしても,この値は変わりません。また,b. となるのは NOW 関数を使ったときで,この2つの関数の挙動が異なる事の理解はとても重要です。
a. TD_SCHEDULED_TIME(): 00:00:00
b. NOW(): 06:00:00
B. アドホッククエリで使用する場合
アドホッククエリとは,その場で実行して結果を待つタイプのクエリを意味します。先ほどと同じクエリを考えます。トレジャーデータでは TD_SCHEDULED_TIME を含んだクエリをその場で実行しようとすると,以下の様なカレンダーが表示されます。
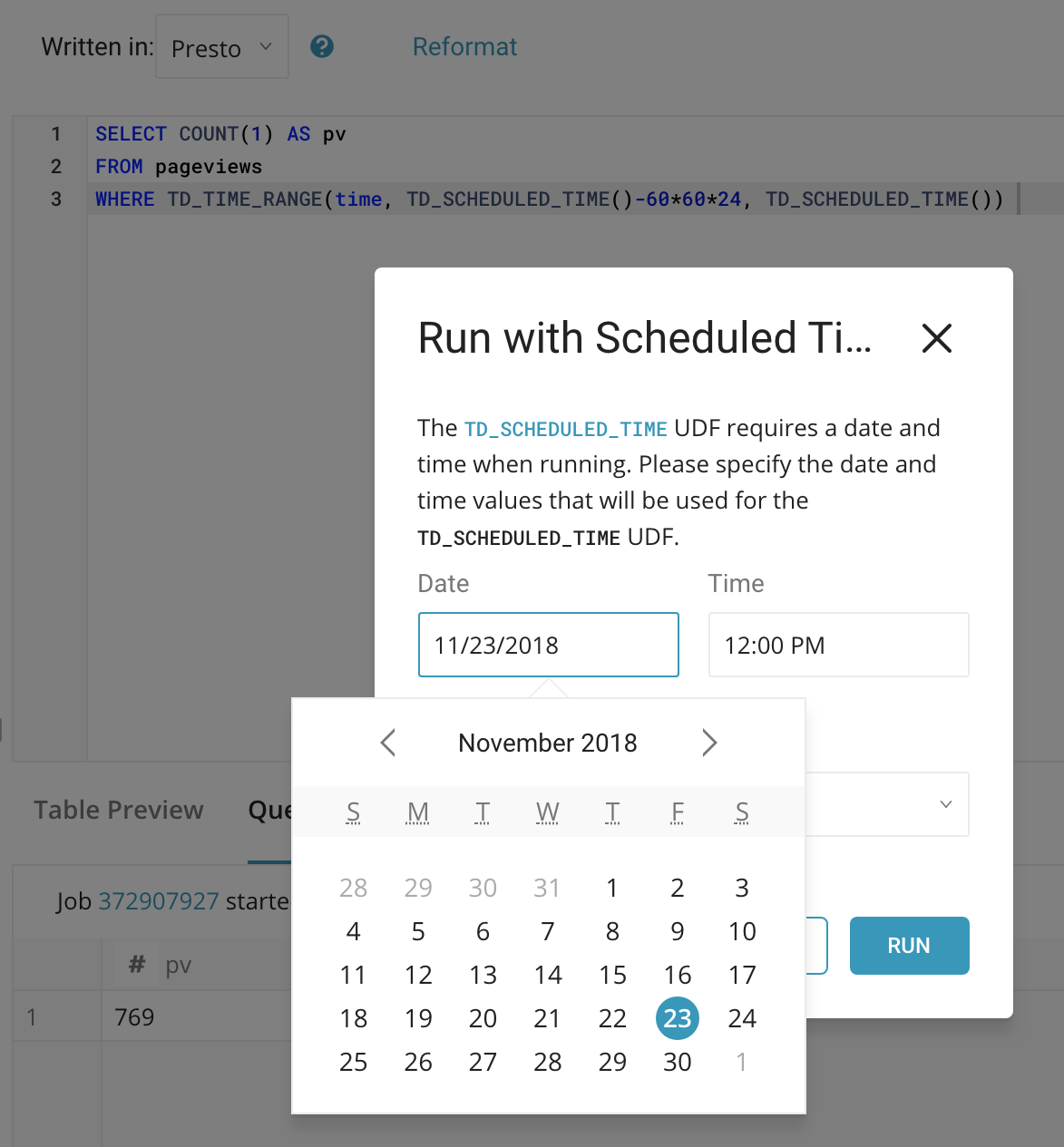
これは非常に親切な行為で,自分で TD_SCHEDULED_TIME に入れたい日次の unixtime を指定することができます。これが NOW 関数であれば,自動的に実行した際の unixtime が勝手に挿入されます。このアドホッククエリで用いる TD_SCHEDULED_TIME は,過去の月次処理をし直す場合などで大きな効力を発揮します。
応用:TD_TIME_RANGE を使用した「日次」,「週次」,「月次」処理
ここで今まで登場した関数を使って,過去の任意の日,週,月での日次,週次,月次処理を考えます。例えば
基準日 = TD_SCHEDULED_TIME() = '2018-11-23 11:11:00' とした時,望む集計範囲は以下になります。
基準日 = '2018-11-23 11:11:00'
[2018-11-22 00:00:00, 2018-11-23 00:00:00) # 日次
[2018-11-12 00:00:00, 2018-11-19 00:00:00) # 週次
[2018-10-01 00:00:00, 2018-11-01 00:00:00) # 月次
これを今までの関数で実装する場合には,以下の様に書くことになります。
# TD_SCHEDULED_TIME() = '2018-11-23 11:11:00' の unixtime
TD_TIME_RANGE(
time,
TD_TIME_ADD(TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST'),'-1d'),
TD_DATE_TRUNC('day', TD_SCHEDULED_TIME(), 'JST')
) # 日次 [2018-11-22 00:00:00, 2018-11-23 00:00:00)
TD_TIME_RANGE(
time,
TD_TIME_ADD(TD_DATE_TRUNC('week', TD_SCHEDULED_TIME(), 'JST'),'-1w'),
TD_DATE_TRUNC('week', TD_SCHEDULED_TIME(), 'JST')
) # 週次 [2018-11-12 00:00:00, 2018-11-19 00:00:00)
TD_TIME_RANGE(
time,
TD_DATE_TRUNC(
'month', TD_DATE_TRUNC('month', TD_SCHEDULED_TIME(),'JST')-1, 'JST'
),
TD_DATE_TRUNC('month', TD_SCHEDULED_TIME(), 'JST')
) # 月次 [2018-10:01 00:00:00, 2018-11-01 00:00:00)
TD_INTERVAL
TD_INTERVAL は2018年に流星のごとく表れた革命的な関数です。この関数の登場までは TD_TIME_RANGE と TD_DATE_TRUNC を駆使して過去の月次処理を行っていましたが,彼の登場によってこの関数のみでそれができるようになったのです。(もっとも TD_DATE_TRUNC も最近登場した関数で,その前はもっと苦労していたのですが…)
様式
boolean TD_INTERVAL(time, interval_string, 'JST')
今,基準日 = TD_SCHEDULED_TIME() = '2018-11-23 11:11:00' とした時,この関数は以下の範囲内でのレコードを返します。
# TD_SCHEDULED_TIME() = '2018-11-23 11:11:00'
# !基準日をNOW以外にする場合、クエリ内に TD_SCHEDULED_TIME() を入れる事を忘れない!
TD_INTERVAL(time, '1d', 'JST') # 今日 [2018-11-23 00:00:00, 2018-11-24 00:00:00)
TD_INTERVAL(time, '-1d', 'JST') # 昨日 [2018-11-22 00:00:00, 2018-11-23 00:00:00)
TD_INTERVAL(time, '-7d', 'JST') # 今週 [2018-11-22 00:00:00, 2018-11-23 00:00:00)
TD_INTERVAL(time, '1w', 'JST') # 今週 [2018-11-19 00:00:00, 2018-11-26 00:00:00)
TD_INTERVAL(time, '-1w', 'JST') # 前週 [2018-11-12 00:00:00, 2018-11-19 00:00:00)
TD_INTERVAL(time, '1M', 'JST') # 今月 [2018-11-01 00:00:00, 2018-12-01 00:00:00)
TD_INTERVAL(time, '-1M', 'JST') # 前月 [2018-10-01 00:00:00, 2018-11-01 00:00:00)
TD_INTERVAL(time, '-2M', 'JST') # 前月+前々月 [2018-09-01 00:00:00, 2018-11-01 00:00:00)
週の始まりは月曜日であることに注意してください。
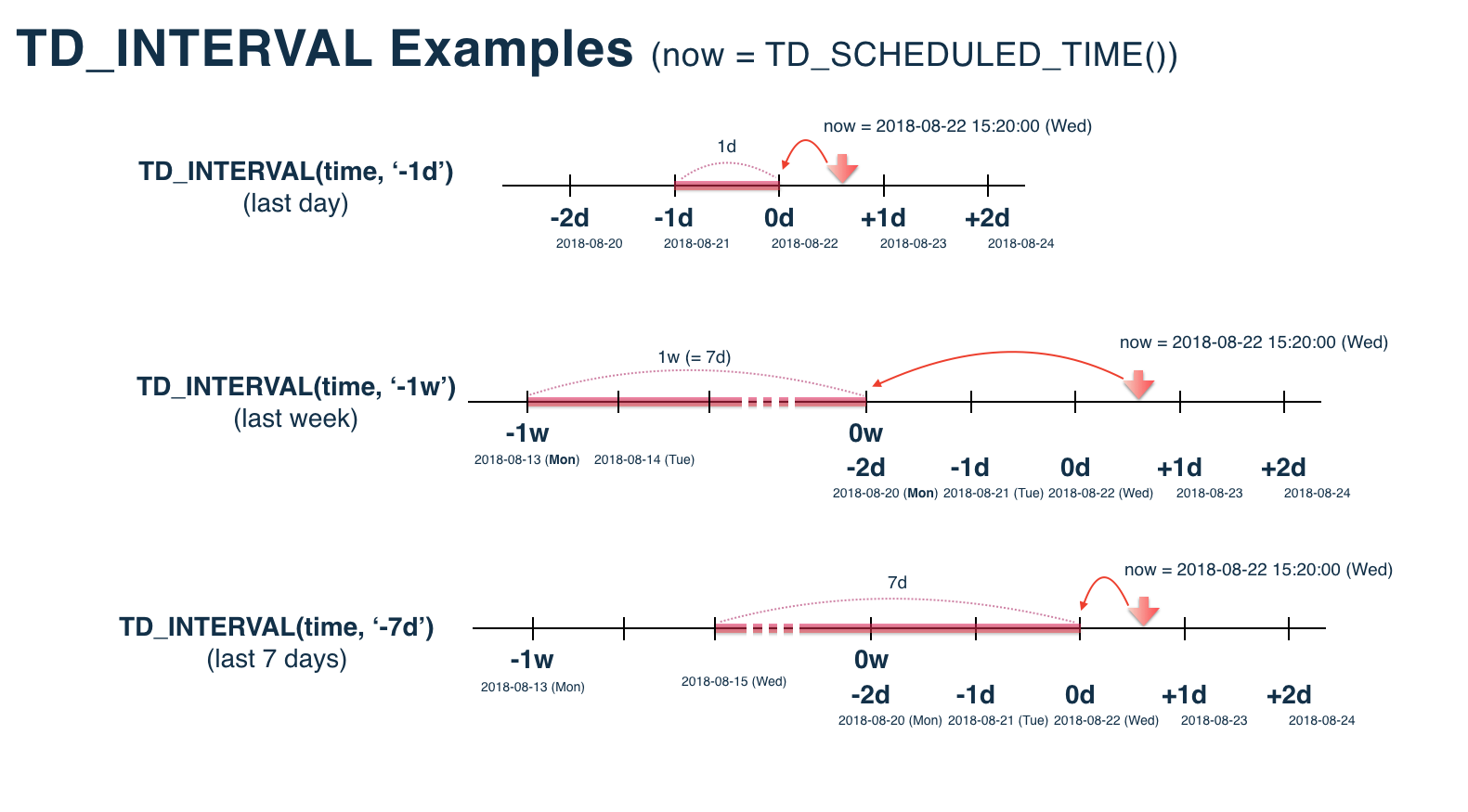
TD_INTERVAL は上図のように, TD_SCHEDULED_TIME で指定した基準日をまず TRUNC して日(週,月)の始まりの時間に整えた上で, interval_string で指定した長さ範囲を定めます。
重要な注意点
TD_INTERVAL の第一引数には TD_SCHEDULED_TIME を入れる事ができません(エラーとなります)。そして、TD_SCHEDULED_TIME がクエリの中に含まれない場合には、TD_INTERVAL の基準日は常に NOW(クエリ実行時の時間)となることに注意してください。
本記事では、過去の日付を基準日にするために、TD_SCHEDULED_TIME を利用することになります。この際には、クエリのどこか(コメントアウトしていても構わないので)に TD_SCHEDULED_TIME を入れておくことになります。
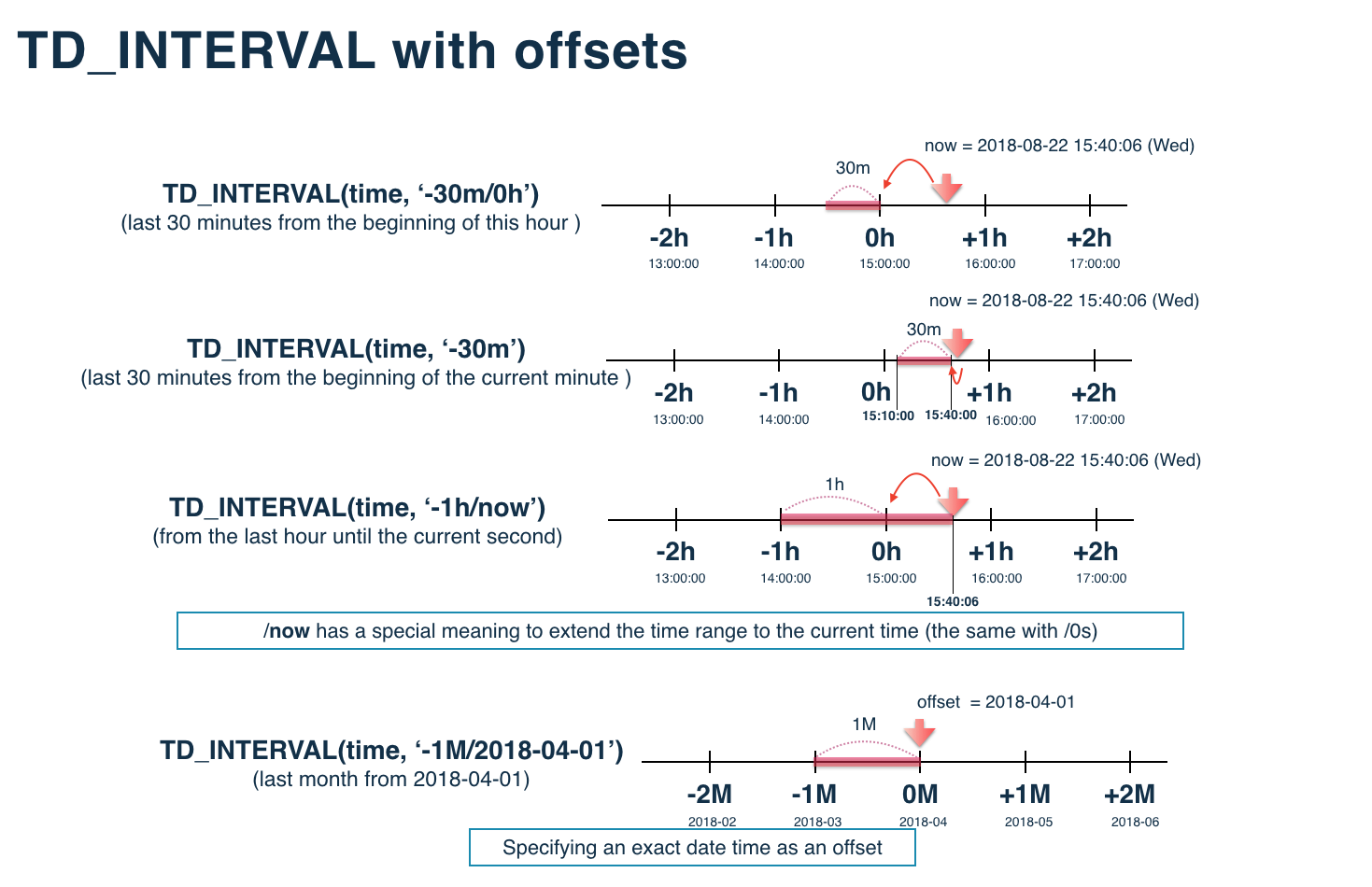
強力なオフセット機能
この関数の強力な点はさらに,オフセット: '-Ld/-Nd','-Lw/-Nw','-LM/-NM'を使用できる事です(L,Nは任意の整数)。これによって,
(N+1)日(週,月)前の L 日(週,月)期間」を指定することができます。また,異なる interval_string の併用も可能です。
# TD_SCHEDULED_TIME() = '2018-11-23 11:11:00'
# !基準日をNOW以外にする場合、クエリ内に TD_SCHEDULED_TIME() を入れる事を忘れない!
TD_INTERVAL(time, '-1d/-1d', 'JST') # 2日前 [2018-11-21 00:00:00, 2018-11-22 00:00:00)
TD_INTERVAL(time, '-1d/-2d', 'JST') # 3日前 [2018-11-20 00:00:00, 2018-11-21 00:00:00)
TD_INTERVAL(time, '-1w/-1w', 'JST') # 2週間前 [2018-11-05 00:00:00, 2018-11-12 00:00:00)
TD_INTERVAL(time, '-1M/-1M', 'JST') # 2ヶ月前 [2018-09-01 00:00:00, 2018-10-01 00:00:00)
TD_INTERVAL(time, '-1M/-2M', 'JST') # 3ヶ月前 [2018-08-01 00:00:00, 2018-09-01 00:00:00)
TD_INTERVAL(time, '-2M/-1M', 'JST') # 1ヶ月前の2ヶ月間 [2018-08-01 00:00:00, 2018-10-01 00:00:00)
応用:TD_INTERVAL を使用した「日次」「週次」「月次」処理
先ほどは TD_TIME_RANGE や TD_DATE_TRUNC などを駆使して過去の任意の日,週,月での日次,週次,月次処理を紹介しましたが,同様の事が TD_INTERVAL を使えば以下の様に簡単に書くことができます。
基準日 = '2018-11-23 11:11:00'
[2018-11-22 00:00:00, 2018-11-23 00:00:00) # 日次
[2018-11-12 00:00:00, 2018-11-19 00:00:00) # 週次
[2018-10-01 00:00:00, 2018-11-01 00:00:00) # 月次
# TD_SCHEDULED_TIME() = '2018-11-23 11:11:00'
# !基準日をNOW以外にする場合、クエリ内に TD_SCHEDULED_TIME() を入れる事を忘れない!
TD_INTERVAL(time, '-1d', 'JST') # 日次 [2018-11-22 00:00:00, 2018-11-23 00:00:00)
TD_INTERVAL(time, '-1w', 'JST') # 週次 [2018-11-12 00:00:00, 2018-11-19 00:00:00)
TD_INTERVAL(time, '-1M', 'JST') # 月次 [2018-10-01 00:00:00, 2018-11-01 00:00:00)