はじめに
本シリーズは,Treasure Data,つまり基本SQLで実現可能な様々なアクセスログ分析事例を具体的なクエリと可視化を交えて紹介していくブログです。多くは当たり前のものですが,時には実に良く捻られたものと思って頂けるよう,私が知りうる限りの全ての事例を提供していく予定です。
今回の内容を理解するに当たって,参考になる記事を挙げておきます。
- 『優しく学ぶ Treasure Data』その① 〜日付関数(DATE UDF)を理解しよう〜
- 『Treasure Data でアクセスログ分析の限界に挑む』その① 〜「日次」「週次」「月次」の集計を正しく理解する〜
- 『Treasure Data でアクセスログ分析の限界に挑む』その② 〜アクセスに基づいたユーザーセグメントの作成 月次編(アクティビティ)〜
今回のテーマ
今回は『ユーザーがアクセスしたか否か』,この一点のみに着目してそこから導き出される様々な指標を導出します。
そして,これらが今後有益なユーザー『セグメント』として機能して行くことをお見せします。
- これから数回に渡って「日次」「週次」「月次」それぞれについて,「アクセスの有無」に基づいた様々な指標を求めるクエリを紹介します。
- セグメント対象となるユーザーは,特定の範囲内のユーザーではなく,常にデータベース上の全ユーザーとなります。
- 今回は「月次編」の「頻度」に着目します。
前提とするデータ定義
本シリーズでは以下の様な pageview テーブルを想定していきますが,多くの場合では time カラムと td_client_id カラム(または何らかのユーザーを識別するカラム)しか使いませんので,アクセスログに限らず様々なログで応用可能です。
| time | td_client_id | td_title | td_ip |
|---|---|---|---|
| 1542956154 | c445a751288 | Treasure Data | 72.215.178.105 |
| 1542955952 | 6b5a0357b2f | Treasure Data | 103.206.191.199 |
| 1542955625 | 344503ae8cb | td command line tool reference | 185.3.22.17 |
| 1542954891 | 178e1a1d3e4 | SQL & Performance Tuning Tips | 103.250.170.50 |
| 1542954151 | f556371264a | Installing and Updating... | 39.110.208.102 |
| 1542953658 | c31baa01dfe | Planning and Implementation... | 203.132.82.75 |
| 1542953160 | 9894e8afc72 | gtm-msr | 66.102.8.8 |
要旨
今回は,月次のユーザーセグメントを求める方法を紹介する第2回目です。前回の内容を読んで頂いた方には,楽に読んで頂けると思います。また,前回は結論として「前月」と「前々月」を同時に求めたセグメントのみを採用しましたが,今回は「前月」のみで求めたセグメントと,「前月」と「前々月」を同時に見たセグメントの両方を採用し,後の活用可能性を高めておきます。これからの文章は以下の結果を得るための説明になります。
A. 前月に基づく Frequency Segment
| 週当たりのアクセス頻度 | 人数 |
|---|---|
| 週7 | 1 |
| 週6 | 5 |
| 週5 | 25 |
| 週4 | 38 |
| 週3 | 56 |
| 週2 | 131 |
| 週1 | 481 |
| 週1未満 | 11722 |
| アクセス無し | 468330 |
前月の間に何日(1回でも)アクセスしたかを求め,それを週当たりのアクセス頻度としてセグメントを作り,集計しました。
B. 前月と前々月に基づく Frequency Segment
| 前月からの頻度の変化 | 人数 |
|---|---|
| 激増 | 11 |
| 増 | 125 |
| 微増 | 1375 |
| 変化無し | 465104 |
| 微減 | 13786 |
| 減 | 367 |
| 激減 | 21 |
次に「前月」と「前々月」でのアクセス頻度の変化を上の様なセグメントに分け,集計しました。アクセス頻度が「激増」しているユーザーにはきっと理由があるはずです。「激減」しているユーザーにはすぐにサポートアクションが必要になりますね。
2. Frequency Segment (アクセス頻度)
A. 前月に基づく Frequency Segment
前月の間に「何回」(一度でも)アクセスしたかを,頻度セグメントとして考えて行きます。クエリのポイントは,
TD_DATE_TRUNC('day',time,'JST') AS access_day
によって同日のアクセスをどれもその日の初めの時間に統一することです。異なる 'access_day' の数をユーザーごとに集計することで目的が達成されます。
/* TD_SCHEDULED_TIME() = '2018-11-23 11:11:00' */
/*
SELECT target_month, freq/*_per_week*/ ,COUNT(1) AS cnt, AVG(pv_daily_avg) AS pv_daily_avg, STDDEV(pv_daily_avg) pv_stdev
FROM
(
*/
SELECT
TD_TIME_FORMAT(TD_DATE_TRUNC('month', TD_DATE_TRUNC('month', TD_SCHEDULED_TIME(),'JST')-1, 'JST'),'yyyy-MM-dd','JST') AS target_month,
IF(past_month.td_client_id IS NOT NULL, past_month.td_client_id, past_month_ago.td_client_id ) AS td_client_id,
IF(freq IS NOT NULL, freq, 0) AS freq,
IF(freq IS NOT NULL, freq/4,-1) AS freq_per_week,
IF(pv IS NOT NULL, pv, 0) AS pv,
IF(pv_daily_avg IS NOT NULL,pv_daily_avg, 0) AS pv_daily_avg,
IF(pv_stdev IS NOT NULL, pv_stdev, 0) AS pv_stdev,
min_time, max_time
FROM
(
SELECT
td_client_id,
COUNT(1) AS freq, SUM(pv) AS pv, AVG(pv) AS pv_daily_avg, STDDEV(pv) AS pv_stdev,
TD_TIME_FORMAT(MIN(min_time),'yyyy-MM-dd','JST') AS min_time, TD_TIME_FORMAT(MAX(max_time),'yyyy-MM-dd','JST') AS max_time
FROM
(
SELECT td_client_id, TD_DATE_TRUNC('day',time,'JST') AS access_day, COUNT(1) AS pv, MIN(time) AS min_time, MAX(time) AS max_time
FROM pageviews
WHERE TD_INTERVAL(time, '-1M', 'JST')
GROUP BY td_client_id, TD_DATE_TRUNC('day',time,'JST')
)
GROUP BY td_client_id
) past_month
FULL OUTER JOIN
(
SELECT td_client_id
FROM pageviews
WHERE TD_INTERVAL(time, '-10y/-1M', 'JST') /* 1ヶ月前より過去 */
GROUP BY td_client_id
) past_month_ago
ON past_month.td_client_id = past_month_ago.td_client_id
/*
)
GROUP BY target_month, freq/*_per_week*/
ORDER BY freq/*_per_week*/ DESC
*/
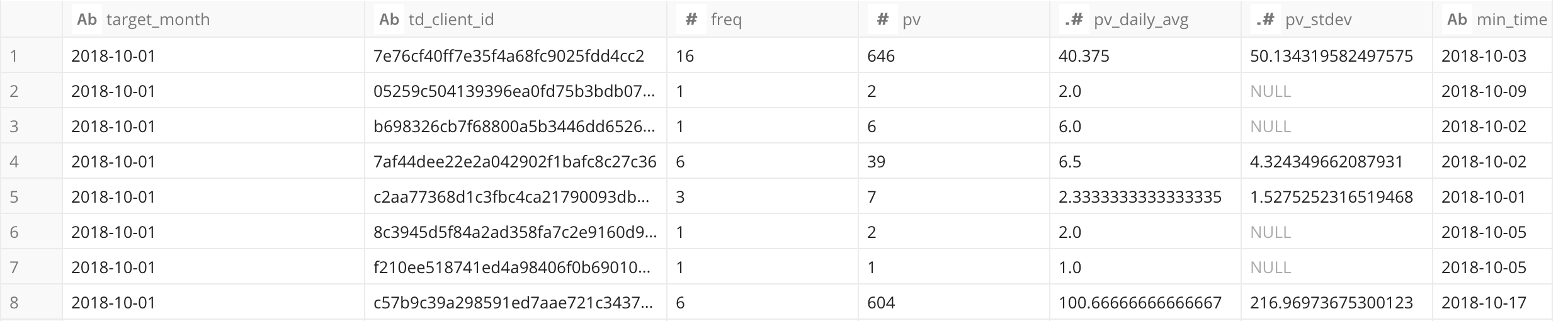
ここでは,頻度以外に
- pv: 1月の総アクセス回数
- pv_daily_avg: 1日の平均アクセス回数
- pv_stdev: 平均アクセス回数の標準偏差(日毎のアクセス回数にどれだけムラがあるか)
を求めています。後者2つは今後,この指標も登場することになるので覚えておいて下さい。
このクエリの上下のコメント部分を外せば, freq (頻度)ごとの集計が行えます。
| target_month | freq | cnt | pv_daily_avg | pv_stdev |
|---|---|---|---|---|
| 2018-10-01 | 28 | 1 | 117.1428571 | |
| 2018-10-01 | 26 | 1 | 92.73076923 | |
| 2018-10-01 | 25 | 2 | 71.56 | 30.37730732 |
| ... | ... | ... | ... | ... |
| 2018-10-01 | 3 | 431 | 13.45862336 | 57.62710726 |
| 2018-10-01 | 2 | 1275 | 5.566666667 | 20.78065973 |
| 2018-10-01 | 1 | 10016 | 4.107527955 | 16.06210859 |
| 2018-10-01 | 0 | 468330 | 0.0 | 0.0 |
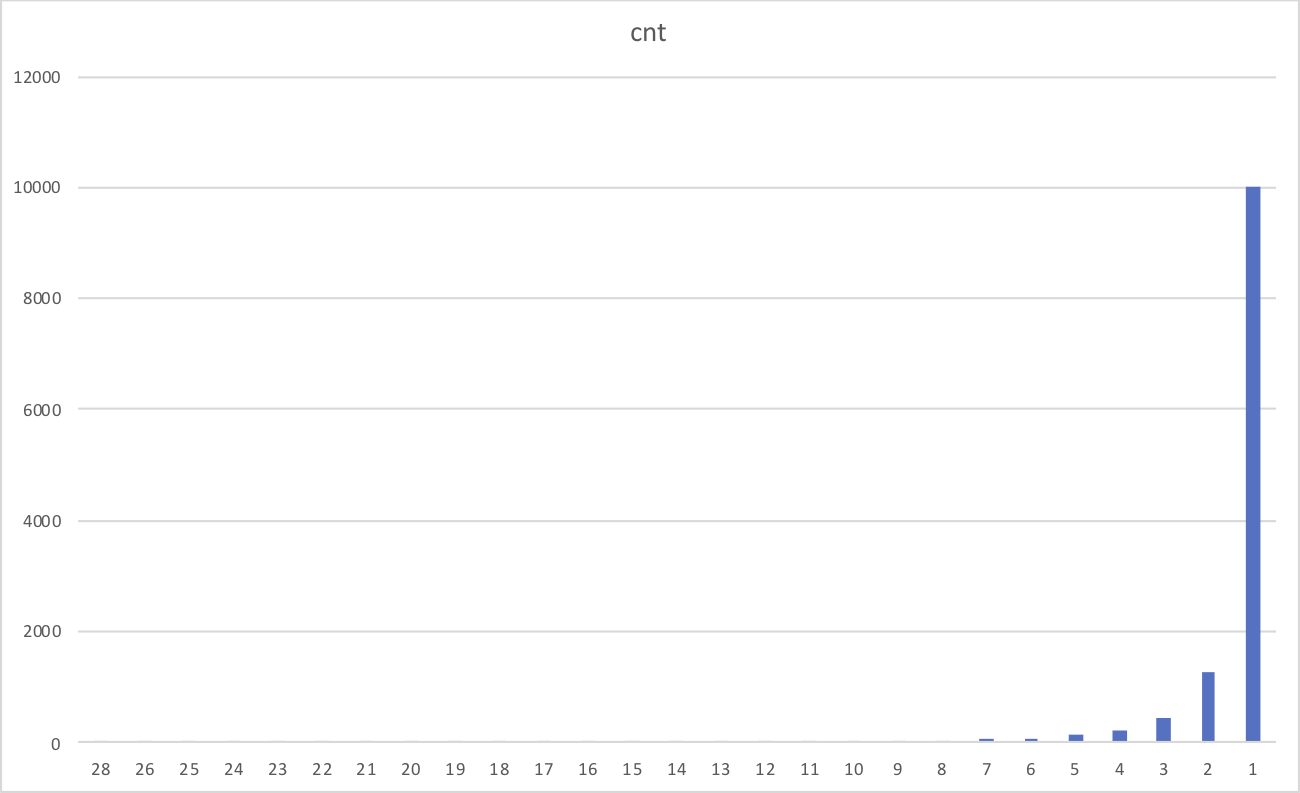
0を除いた頻度別の分布を見てみましたが月に一回しかアクセスしてくれないユーザーが多いですね。
この freq による区分は [0,31] の最大32個の区分になるので少し多すぎますね。そこで,ざっくりと「(平均的に)週n回の頻度でアクセスしているか」で区分することにします。上のクエリの 'freq/*_per_week*/' となっている 3箇所のコメントを外す,つまり 'freq_per_week' について集計すると以下のより少ない区分での集計結果が得られます。
| target_month | freq_per_week | cnt |
|---|---|---|
| 2018-10-01 | 7 | 1 |
| 2018-10-01 | 6 | 5 |
| 2018-10-01 | 5 | 25 |
| 2018-10-01 | 4 | 38 |
| 2018-10-01 | 3 | 56 |
| 2018-10-01 | 2 | 131 |
| 2018-10-01 | 1 | 481 |
| 2018-10-01 | 0 | 11722 |
| 2018-10-01 | -1 | 468330 |
今回はこちらを 'monthly_segment_frequency_single' テーブルとして保存して置くことにします。次に以下の様な 'monthly_segment_frequency_single_master' テーブルを作り,解釈しやすいセグメント名に変換できるようにしておきます。
| freq_per_week | segment_name |
|---|---|
| -1 | アクセス無し |
| 0 | 週1未満 |
| 1 | 週1 |
| 2 | 週2 |
| 3 | 週3 |
| 4 | 週4 |
| 5 | 週5 |
| 6 | 週6 |
| 7 | 週7 |
週4以上の高頻度アクセスユーザーには,是非とも継続してこの頻度を保てるようにしていって欲しいところです。また,週2以下の低頻度アクセスユーザーにはアクセスのモチベーションを上げてもらっていく必要がありますね。
B. 前月と前々月に基づく Frequency Segment
前回と同様に,前月と前々月の Frequency Segment を同時に見ることで, ユーザーごとのアクセス頻度の推移を見ることができます。
/* TD_SCHEDULED_TIME() = '2018-11-23 11:11:00' */
/*
SELECT target_month, frequency_past_1, frequency_past_2, frequency_past_1-IF(frequency_past_2 IS NOT NULL,frequency_past_2,0) AS diff, COUNT(1) AS cnt
FROM
(
*/
SELECT
TD_TIME_FORMAT(TD_DATE_TRUNC('month', TD_DATE_TRUNC('month', TD_SCHEDULED_TIME(),'JST')-1, 'JST'),'yyyy-MM-dd','JST') AS target_month,
past_1month.td_client_id,
past_1month.freq_per_week AS frequency_past_1,
past_2month.freq_per_week AS frequency_past_2,
past_1month.min_time AS min_time_past_1, past_1month.max_time AS max_time_past_1,
past_2month.min_time AS min_time_past_2, past_2month.max_time AS max_time_past_2
FROM
(
SELECT
IF(past_month.td_client_id IS NOT NULL, past_month.td_client_id, past_month_ago.td_client_id ) AS td_client_id,
IF(freq IS NOT NULL, freq, 0) AS freq,
IF(freq IS NOT NULL, freq/4,-1) AS freq_per_week,
IF(pv IS NOT NULL, pv, 0) AS pv,
IF(pv_daily_avg IS NOT NULL,pv_daily_avg, 0) AS pv_daily_avg,
IF(pv_stdev IS NOT NULL, pv_stdev, 0) AS pv_stdev,
min_time, max_time
FROM
(
SELECT
td_client_id,
COUNT(1) AS freq, SUM(pv) AS pv, AVG(pv) AS pv_daily_avg, STDDEV(pv) AS pv_stdev,
TD_TIME_FORMAT(MIN(min_time),'yyyy-MM-dd','JST') AS min_time, TD_TIME_FORMAT(MAX(max_time),'yyyy-MM-dd','JST') AS max_time
FROM
(
SELECT td_client_id, TD_DATE_TRUNC('day',time,'JST') AS access_day, COUNT(1) AS pv, MIN(time) AS min_time, MAX(time) AS max_time
FROM pageviews
WHERE TD_INTERVAL(time, '-1M', 'JST')
GROUP BY td_client_id, TD_DATE_TRUNC('day',time,'JST')
)
GROUP BY td_client_id
) past_month
FULL OUTER JOIN
(
SELECT td_client_id
FROM pageviews
WHERE TD_INTERVAL(time, '-10y/-1M', 'JST') /* 1ヶ月前より過去 */
GROUP BY td_client_id
) past_month_ago
ON past_month.td_client_id = past_month_ago.td_client_id
) past_1month
LEFT OUTER JOIN /* 集合 past_1month は past_2month を内包する */
(
SELECT
IF(past_month.td_client_id IS NOT NULL, past_month.td_client_id, past_month_ago.td_client_id ) AS td_client_id,
IF(freq IS NOT NULL, freq, 0) AS freq,
IF(freq IS NOT NULL, freq/4,-1) AS freq_per_week,
IF(pv IS NOT NULL, pv, 0) AS pv,
IF(pv_daily_avg IS NOT NULL,pv_daily_avg, 0) AS pv_daily_avg,
IF(pv_stdev IS NOT NULL, pv_stdev, 0) AS pv_stdev,
min_time, max_time
FROM
(
SELECT
td_client_id,
COUNT(1) AS freq, SUM(pv) AS pv, AVG(pv) AS pv_daily_avg, STDDEV(pv) AS pv_stdev,
TD_TIME_FORMAT(MIN(min_time),'yyyy-MM-dd','JST') AS min_time, TD_TIME_FORMAT(MAX(max_time),'yyyy-MM-dd','JST') AS max_time
FROM
(
SELECT td_client_id, TD_DATE_TRUNC('day',time,'JST') AS access_day, COUNT(1) AS pv, MIN(time) AS min_time, MAX(time) AS max_time
FROM pageviews
WHERE TD_INTERVAL(time, '-1M/-1M', 'JST')
GROUP BY td_client_id, TD_DATE_TRUNC('day',time,'JST')
)
GROUP BY td_client_id
) past_month
FULL OUTER JOIN
(
SELECT td_client_id
FROM pageviews
WHERE TD_INTERVAL(time, '-10y/-2M', 'JST') /* 1ヶ月前より過去 */
GROUP BY td_client_id
) past_month_ago
ON past_month.td_client_id = past_month_ago.td_client_id
) past_2month
ON past_1month.td_client_id = past_2month.td_client_id
/*
)
GROUP BY target_month, frequency_past_1, frequency_past_2
*/
ORDER BY frequency_past_1 DESC, frequency_past_2 DESC
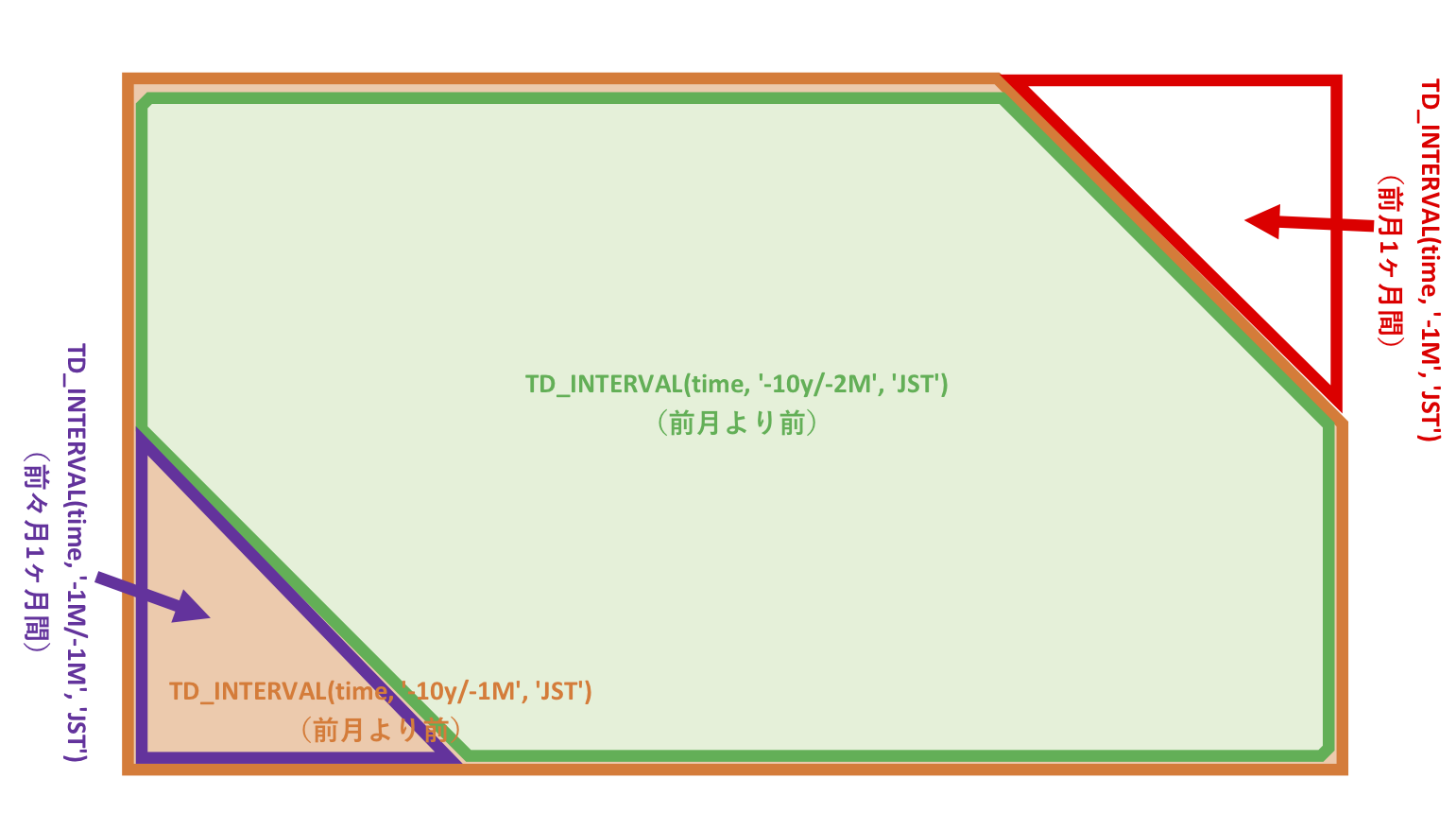
上のクエリにおいて, 1ヶ月前のアクティビティを求める サブクエリ: 'past_1month' 内では,上図の赤色とオレンジ色の領域(データ範囲)を使用し, 2ヶ月前のアクティビティを求める サブクエリ: 'past_2month' 内では,上図の紫色と緑色の領域(データ範囲)を使用して求めています。
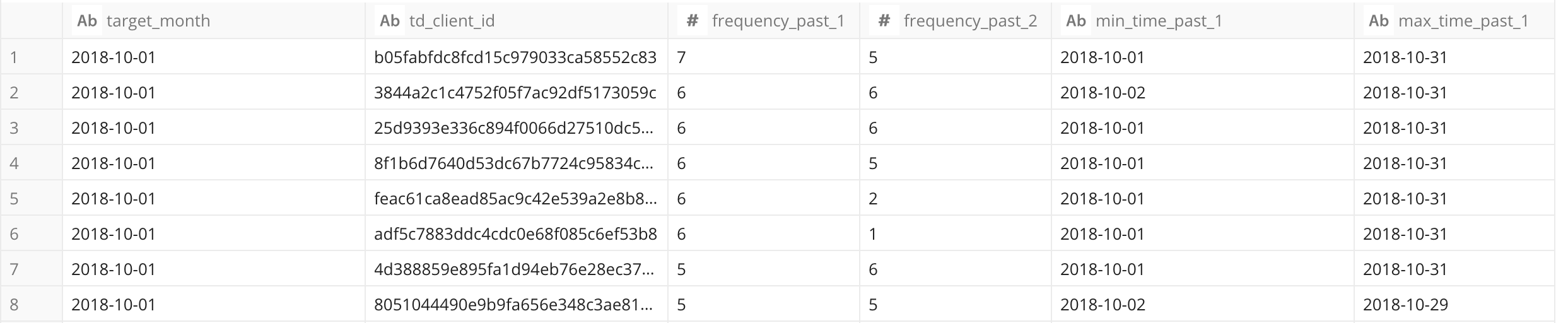
結果の中に 'frequency_past_2' が NULL のユーザーがあるかもしれませんが,それは先月新しく登録された新規ユーザーを意味します。
次に,いつもと同じように,クエリの上下のコメントアウト部分を外して,集計を行いましょう。また,これを 'monthly_segment_frequency' テーブルとして保存しておくことにします。
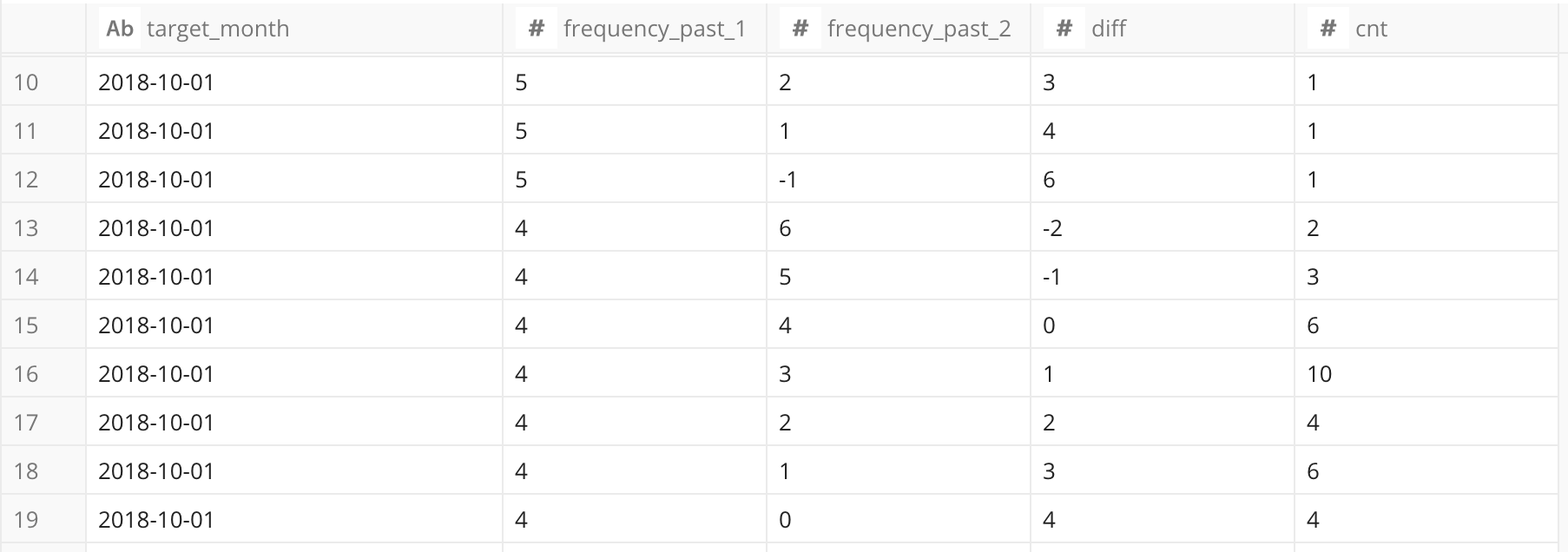
これからわかるのは,今回の 'frequency_past_1' と 'frequency_past_2' の取り得る組合せが多すぎる事です。そこで組合せを減らすために,『先月の頻度が先々月に比べてどれだけ増えた(減った)か』の diff カラムに着目することにします。
以下の例で diff は次の値を取ります。
- 先月:5(週5回), 先々月:7(週7回) → diff = -2
- 先月:6(週6回), 先々月:3(週3回) → diff = 3
- 先月:1(週1回), 先々月:0(週0回) → diff = 1
- 先月:1(週1回), 先々月:-1(アクセス無し) → diff = 2
- 先月:1(週1回), 先々月:NULL → diff = 1 (新規ユーザー)
そしてこの diff について集計してみると,次の少ない組合せでの集計が得られます。
| target_month | diff | cnt |
|---|---|---|
| 2018-10-01 | 6 | 1 |
| 2018-10-01 | 5 | 1 |
| 2018-10-01 | 4 | 9 |
| 2018-10-01 | 3 | 23 |
| 2018-10-01 | 2 | 102 |
| 2018-10-01 | 1 | 1375 |
| 2018-10-01 | 0 | 465104 |
| 2018-10-01 | -1 | 13786 |
| 2018-10-01 | -2 | 327 |
| 2018-10-01 | -3 | 40 |
| 2018-10-01 | -4 | 16 |
| 2018-10-01 | -5 | 3 |
| 2018-10-01 | -6 | 2 |
diff の大きさが意味するのは,『週当たりのアクセス頻度が diff 日増えた(減った)』というものです。diff が 0 というのはアクセス頻度に大きな変化が無かったことを意味します。そこで, この diff に対する segment_name を以下の 'monthly_segment_frequency_master' テーブルで定義しておきます。
| diff | segment_name |
|---|---|
| 6 | 激増 |
| 5 | 激増 |
| 4 | 激増 |
| 3 | 増 |
| 2 | 増 |
| 1 | 微増 |
| 0 | 変化無し |
| -1 | 微減 |
| -2 | 減 |
| -3 | 減 |
| -4 | 激減 |
| -5 | 激減 |
| -6 | 激減 |
この segment_name で集計した結果は以下になります。
| segment_name | cnt |
|---|---|
| 激増 | 11 |
| 増 | 125 |
| 微増 | 1375 |
| 変化無し | 465104 |
| 微減 | 13786 |
| 減 | 367 |
| 激減 | 21 |
それぞれのアクセス頻度の変化の度合いによって,取るアクションが異なってきますね。
ただ, diff によるセグメント集計は「変化」のみによって区分されており, 『A. 先月の Frequency Segment 』で求めたような,そもそもそのユーザーが『月にどれくらいの頻度でアクセスするユーザーか?』の有益な特徴を知ることはできません。
よって,この頻度におけるセグメント分けは 『A.の単月でのユーザーのアクセス頻度によるセグメント』と,『B.のアクセス頻度の変化によるセグメント』の両方を保持しておくことが賢明であると言えます。
後々,このセグメントの使い分けがうまく効いてきます。