こんにちは!「蠢動する赤![]() 」です
」です
LLM と AI をもぞもぞ学んでいる蛰伏系エンジニアです。気づいたら急に強くなっている……そんな存在を目指してます![]()
はじめに
本記事は、【10 Days Challenge】論文解説AI「Paper Copilot」開発ログ——RAGからAgentまでシリーズの記念すべき第1日目です。具体的なコードは以下の GitHub リンクをご参照ください。
どのような形のコメントでも歓迎します。皆さんからのフィードバックが学習の助けになりますので、ぜひよろしくお願いいたします。![]()
近年、ChatGPTなどのLLM(大規模言語モデル)は驚異的な能力を見せていますが、「社内の規定について教えて」や「最新の製品仕様はどうなってる?」といった、学習データに含まれていない独自の知識に関する質問には答えられません。
ここで登場するのが RAG (Retrieval-Augmented Generation) です。
この技術を使えば、LLMに「教科書」や「マニュアル」を渡して、その内容に基づいて回答させることができます。
RAGが実現できること(実用例):
- 社内ヘルプデスクの自動化: 就業規則や経費精算の手順を即座に回答するボット
- カスタマーサポートの効率化: 膨大な製品マニュアルから適切な回答を提示するアシスタント
- 契約書・論文の分析: 大量の専門文書から特定の条項や知見を抽出するツール
このシリーズでは、単なる理論だけでなく、「実際に動くアプリケーション」 を作ることをゴールにします。
Day 1のテーマは 「RAGの基本構造と実装」 です。
まずはLangChainを使って、PDFドキュメントの内容に基づいて回答するシンプルなRAGアプリを作成し、その威力を体感してみましょう。
RAG(検索拡張生成)とは?
RAG (Retrieval-Augmented Generation) は、LLMが学習していない 外部データ(社内ドキュメント、最新ニュース、専門書など) を検索し、その情報をプロンプトに含めることで、より正確で具体的な回答を生成させる技術です。このアイデアは NeurPS2020の「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」で初めて提案されました。興味のある方はぜひ原論文を読んでみてください。
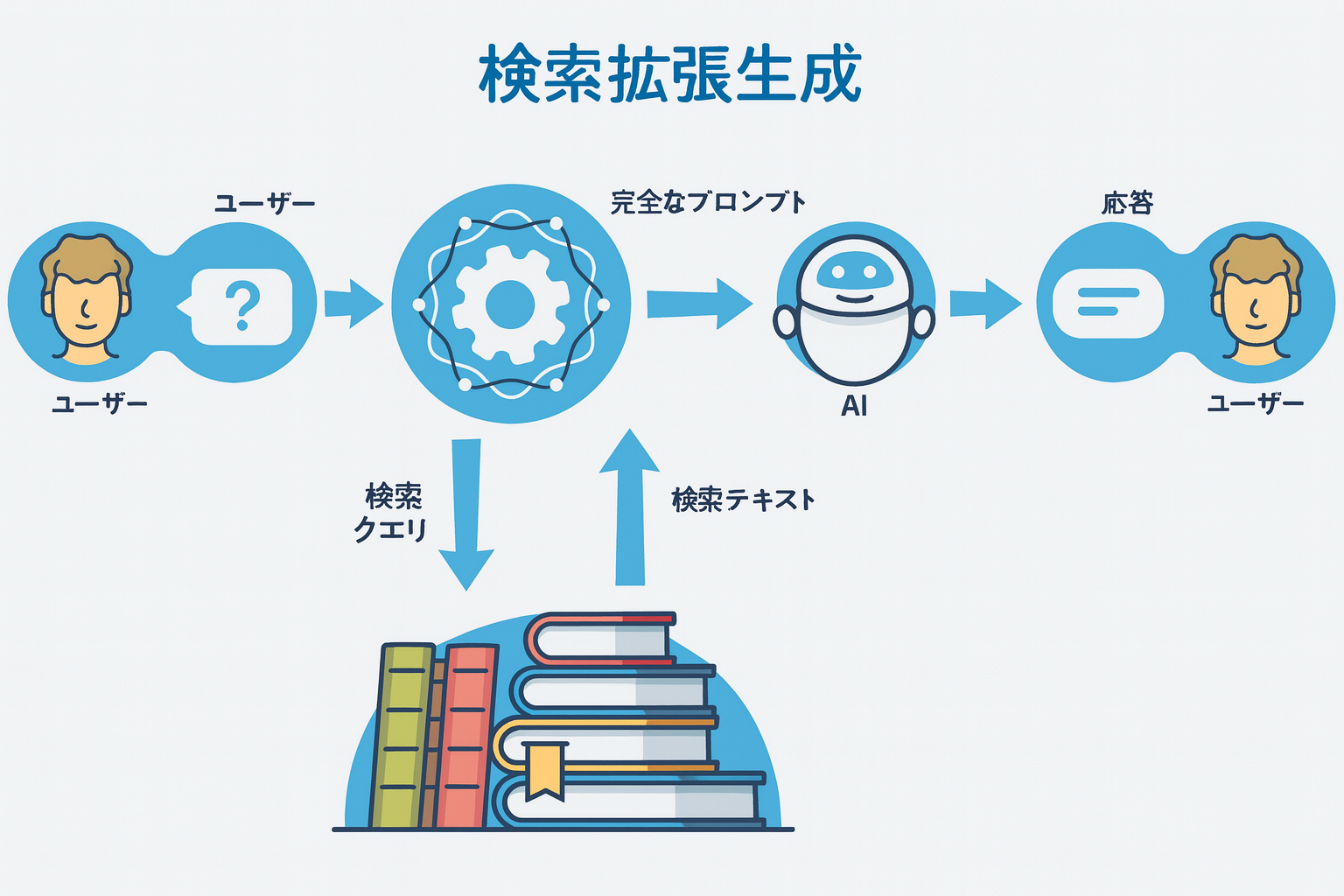
*RAGの概要図
なぜRAGが必要なのか?
LLM単体では以下の課題があります:
- 情報の鮮度: 学習データに含まれていない最新情報を知らない。
- ハルシネーション: 嘘の情報をもっともらしく答えてしまうことがある。
- プライベートデータ: 社内規定や個人のメモなど、非公開データを知らない。
RAGを使うことで、これらの課題を解決し、**「信頼性の高い、根拠に基づいた回答」**を得ることができます。
実装の流れ
今回は day1_rag.py というファイルを作成し、以下のステップで実装します。
- Data Ingestion: PDFを読み込む
- Chunking: テキストを適切なサイズに分割する
- Embedding & Vector Store: テキストをベクトル化してデータベースに保存する
- Retrieval & Generation: 質問に関連する情報を検索し、LLMに回答させる
環境準備
以下のライブラリを使用します。
pip install langchain langchain-openai langchain-chroma langchain-community pypdf langchain_classic
また、OpenAI API Keyが必要です。
一部の機能は langchain_classic クラス内のメソッドで実装しており、いわば旧版のやり方です。新版については現在勉強中で、今後この部分を更新する予定です。
コード解説
それでは、実際のコードを見ていきましょう。
1. ライブラリのインポートと設定
import os
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain_classic.chains import create_retrieval_chain
from langchain_classic.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
# API Keyの設定
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
安全のため、API キーなどはコード中に直接書かない方が良く、環境変数として管理するのが最適です。(ちなみに GitHub は非常に優秀で、コードに API キーがそのまま含まれていると push を拒否してくれます)
2. PDFの読み込み (Data Ingestion)
まずは対象となるPDFファイルを読み込みます。今回はRAGの有名な論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」を使用します。
def run_basic_rag(pdf_path, query):
print(f"--- ファイル処理中: {pdf_path} ---")
# PDFローダーの初期化と読み込み
loader = PyPDFLoader(pdf_path)
documents = loader.load()
print(f"PDFの読み込み成功、合計 {len(documents)} ページ")
3. テキスト分割 (Chunking)
LLMには一度に入力できるトークン数に制限があるため、長いドキュメントは小さな「チャンク」に分割する必要があります。
# テキスト分割の設定
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 1つのチャンクの文字数
chunk_overlap=200 # チャンク間の重複(文脈の分断を防ぐため)
)
splits = text_splitter.split_documents(documents)
print(f"ドキュメントを {len(splits)} 個のチャンクに分割しました")
4. ベクトル化と保存 (Embedding & Vector Store)
分割したテキストを、意味を理解しやすい「ベクトル(数値の羅列)」に変換し、検索可能な状態で保存します。今回は軽量な Chroma を使用します。
# Embeddingモデルの準備
embedding_model = OpenAIEmbeddings(model="text-embedding-3-small")
# ベクトルデータベースの作成
print("ベクトルデータベースを構築中...")
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embedding_model
)
print("ベクトルデータベースの構築完了!")
5. 検索と生成 (Retrieval & Generation)
最後に、ユーザーの質問に関連するチャンクを検索し、それをコンテキストとしてLLMに渡して回答を生成します。
# LLMの準備
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# Retriever(検索機)の作成
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 5})
# プロンプトの定義
prompt = ChatPromptTemplate.from_template("""以下のコンテキストに基づいて、質問に答えてください:
<context>{context}</context>
質問: {input}""")
# Chainの構築
combine_docs_chain = create_stuff_documents_chain(llm, prompt)
qa_chain = create_retrieval_chain(retriever, combine_docs_chain)
# 実行
result = qa_chain.invoke({"input": query})
return result
【深掘り解説】裏側で何が起きているのか?
ここで行われている処理は、単なるキーワード検索ではありません。**「意味の近さ」**に基づいた高度なマッチングが行われています。
1. ベクトル検索の仕組み
retriever = vectorstore.as_retriever(...) の部分では、以下の処理が行われます。
- 質問のベクトル化: ユーザーの質問(例:「この論文の主な貢献は何ですか?」)を、Embeddingモデルを使って数値の配列(ベクトル)に変換します
- 類似度計算: 事前に保存しておいた「PDFの各チャンクのベクトル」と「質問のベクトル」を比較します
-
ランキング: ベクトル同士の距離が近い(=意味が似ている)上位のチャンク(今回は
k=5なので5つ)を取り出します
2. 検索タイプの選択 (Search Type)
今回は search_type="similarity" を指定しましたが、他にも設定があります。
-
similarity(デフォルト):
単純にベクトル同士の距離が近い順に取得します。最も基本的な方法です。 -
mmr(Maximal Marginal Relevance):
「関連性」と「多様性」のバランスを取ります。似たような内容ばかりが選ばれるのを防ぎ、異なる視点の情報を取得したい場合に有効です。 -
similarity_score_threshold:
類似度が一定以上のものだけを取得します。「あまり関係ない情報は除外したい」という場合に使います。
3. プロンプトへの注入(Prompt Injection)
検索されたチャンクは、ChatPromptTemplate の {context} 部分に自動的に埋め込まれます。
最終的にLLMに送られるプロンプトは、以下のようになります。
以下のコンテキストに基づいて、質問に答えてください:
<context>
[チャンク1の内容: ...この論文ではRAGモデルを提案し...]
[チャンク2の内容: ...パラメトリックメモリとノンパラメトリックメモリを...]
...
</context>
質問: この論文の主な貢献は何ですか?
つまり、LLMは 「何も知らない状態」で答えているのではなく、「渡されたカンニングペーパー(context)を見ながら」答えている のです。これがRAGの種明かしです。
実行結果の比較
このコードでは、RAGを使わない場合(LLMの知識のみ)と、RAGを使った場合(PDFの知識あり)を比較できます。
質問: 「この論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」の主な貢献は何ですか?」
1. No RAG (LLMのみ)の結果
この論文の主な貢献は、知識密度の高い自然言語処理タスクにおいて、情報検索を活用した生成モデルの提案とその有効性の実証である。
2. Basic RAG (PDF参照)の結果 | k=5
この論文の主な貢献は、事前学習済みの生成型言語モデルに外部知識(非パラメトリックなドキュメント集合)への検索機構(リトリーバル)を組み合わせた「Retrieval-Augmented Generation(RAG)」アーキテクチャを提案し、知識集約型NLPタスクにおいて高 い性能と柔軟性を実現した点です。これにより、モデルの知識更新や根拠提示が容易になり、従来のパラメトリックモデルの限界を克服しています。
検索された関連項目
[Source 1] Page 0: Retrieval-Augmented Generation for Knowledge-Inten...
[Source 2] Page 11: [20] Kelvin Guu, Kenton Lee, Zora Tung, Panupong P...
[Source 3] Page 8: dialog, where generators have been conditioned on ...
[Source 4] Page 8: General-Purpose Architectures for NLP Prior work o...
[Source 5] Page 8: architecture, by learning a retrieval module to au...
3. RAGの調整結果(関連項目の係数調整など)
この論文の主な貢献は以下の通りです:
1. **RAG(Retrieval-Augmented Generation)モデルの提案**
事前学習済みの生成モデル(パラメトリックメモリ)と、Wikipediaなどの外部知識ベース(ノンパラメトリックメモリ)を組み合わせた新しいハイブリッド生成モデルを提案しました。
2. **2種類のRAGモデルの設計**
生成全体で同じ文書を参照するRAG-Sequenceと、トークンごとに異なる文書を参照できるRAG-Tokenの2つのアーキテクチャを設計・比較しました。
3. **多様な知識集約型NLPタスクでの評価とSOTA達成**
オープンドメインQAや知識集約型生成タスクで従来手法を上回る性能(SOTA)を達成し、特に生成タスクでより事実的・多様・具体的な出力を実現しました。
4. **知識の更新性と柔軟性の実証**
外部知識ベース(インデックス)を差し替えることで、モデルの知識を再学習なしで即座に更新できることを示しました。
5. **人手評価による有効性の確認**
人手評価で、従来のパラメトリックモデル(BART)よりもRAGの方が事実性・具体性で優れていることを示しました。
簡潔にまとめると、「パラメトリックとノンパラメトリックな知識を組み合わせたRAGモデルを提案し、知識集約型NLPタスクで高い性能と知識の柔軟な更新性を実現した」ことが本論文の主な貢献です。
検索された関連項目
[Source 1] Page 0: Retrieval-Augmented Generation for Knowledge-Inten...
[Source 2] Page 11: [20] Kelvin Guu, Kenton Lee, Zora Tung, Panupong P...
[Source 3] Page 8: dialog, where generators have been conditioned on ...
[Source 4] Page 8: General-Purpose Architectures for NLP Prior work o...
[Source 5] Page 8: architecture, by learning a retrieval module to au...
[Source 6] Page 0: decisions and updating their world knowledge remai...
[Source 7] Page 16: Appendices for Retrieval-Augmented Generation for...
[Source 8] Page 1: without access to an external knowledge source. Ou...
[Source 9] Page 0: per token. We fine-tune and evaluate our models on ...
[Source 10] Page 8: could represent promising future work. 6 Discussio...
結果の分析
今回の実験から、以下の2つの重要なポイントが見えてきました。
-
関連情報が多いほど、回答の質が向上する ( あまり意味のない一文
 )
)
k=5の場合よりも、調整を行ってより多くのコンテキストを与えた場合の方が、回答がより詳細で網羅的になりました。LLMは与えられた情報が多ければ多いほど、それを統合して高度な回答を生成できる能力があります。 -
検索精度の課題(ノイズの混入)
一方で、検索されたドキュメント(Source)を見てみると、必ずしもすべてのチャンクが質問に直結しているわけではありません。中には「参考文献リスト」や「著者の所属情報」など、回答には直接関係のないノイズも含まれています。
単純なベクトル検索では「単語の出現頻度」や「表面的な類似性」に引きずられることがあり、これがRAGの精度を下げる要因になり得ます。
この「検索精度をどう上げるか」が、実用的なRAGアプリを作る上での最大の壁となります。これについては、Day 2以降で詳しく扱っていきます。
まとめ
Day 1では、LangChainを使った基本的なRAGパイプラインを構築しました。
わずか数十行のコードで、独自のデータに基づいて回答するAIが作れることがわかりました。
次回 Day 2 では、より高度な検索手法や、精度の向上テクニックについて掘り下げていきます。お楽しみに!![]()
参考リンク