こんにちは!「蠢動する赤![]() 」です
」です
LLM と AI をもぞもぞ学んでいる蛰伏系エンジニアです。気づいたら急に強くなっている……そんな存在を目指してます![]()
毎回のお知らせ
本記事は、【10 Days Challenge】論文解説AI「Paper Copilot」開発ログ——RAGからAgentまでシリーズの記念すべき第3日目です。
- Day 1: Basic RAG - 基本的なベクトル検索の実装。
- Day 2: Advanced RAG - 検索精度の向上。Hybrid Search(キーワード検索 + ベクトル検索)やRe-ranking(検索結果の再順位付け)を導入しました。
具体的なコードは以下の GitHub リンクをご参照ください。
どのような形のコメントでも歓迎します。皆さんからのフィードバックが学習の助けになりますので、ぜひよろしくお願いいたします。![]()
はじめに
これまでの2日間は、主に「1つのドキュメント(または独立したチャンク)」の中から正解を見つけ出す精度を高めることに注力してきました。
しかし、実世界のタスクでは、複数のドキュメントにまたがる情報を統合して理解する必要があります。
そこで Day 3 の今回は、「複数のドキュメント間の関係性」 を理解するという、より高度なタスクに挑戦します。
具体的には、以下の2つの論文を読み込ませ、その関係性を問います。
- Original RAG Paper: "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"
- GraphRAG Paper: "From Local to Global: A Graph RAG Approach to Query-Focused Summarization"
1. GraphRAGとは?
GraphRAG (Graph Retrieval-Augmented Generation) は、従来のRAG(ベクトル検索ベース)の課題を解決するために、ナレッジグラフ(Knowledge Graph) を組み合わせた新しい手法です。Microsoft Researchによって提案されました。
従来のRAGの課題: "Connecting the dots"
従来のRAG(Standard RAG)は、クエリに類似したテキストチャンク(断片)を検索します。これは「特定の事実」を見つけるのには適していますが、「全体像を理解する」 ことや 「離れた情報同士のつながりを見つける」 こと(Connecting the dots)は苦手です。
例えば、「AとBの関係は?」と聞かれたとき、AについてのチャンクとBについてのチャンクが別々に検索されても、その「関係性」が明示的に書かれたチャンクが存在しなければ、LLMは答えを導き出せないことがあります。これを Context Fragmentation(コンテキストの断片化) と呼びます。
GraphRAGのアプローチ
GraphRAGは、ドキュメントからエンティティ(人、場所、概念など) と 関係性(AはBの一部、AはBと対立、など) を抽出し、構造化されたグラフ(ナレッジグラフ)を構築します。
- Global Search: グラフ全体のコミュニティ(密な部分グラフ)を要約することで、データセット全体の概要(Q: "このデータセットは何について書かれていますか?")に答えることができます。
- Local Search: 特定のエンティティに関連するノードとエッジを辿ることで、深い関係性を探索します。
今回は、このうち Local Search の考え方を取り入れた簡易実装を行います。
2. 実装のポイント (Implementation Details)
day3_graph_rag.py では、以下のステップで簡易的なGraphRAGを実装しました。
Step 1: エンティティと関係性の抽出 (Triple Extraction)
LLMを使って、テキストチャンクから (Subject, Relation, Object) の形式(トリプル)で情報を抽出します。
def extract_triples(text, llm):
# プロンプトで「エンティティ」と「関係性」を抽出するように指示
prompt = """
以下のテキストから、重要なエンティティ(論文名、手法、概念など)とそれらの関係性を抽出してください。
出力形式 (CSV): entity1, relation, entity2
"""
# ... (LLM実行)
return triples
例えば、"GraphRAG addresses the limitations of RAG." という文から、("GraphRAG", "addresses", "limitations of RAG") というトリプルを抽出します。
Step 2: グラフ構築 (Graph Construction)
抽出したトリプルを用いて、networkx ライブラリで有向グラフを構築します。
G = nx.DiGraph()
for s, r, o in triples:
G.add_edge(s, o, relation=r)
これにより、テキストデータが「ノード(点)」と「エッジ(線)」のネットワーク構造に変換されます。
Step 3: グラフ検索 (Graph Retrieval)
クエリに関連する情報をグラフから探します。今回は 「キーワードマッチング + 1-hop近傍探索」 を行います。
- クエリに含まれる単語(例:"GraphRAG")と一致するノードをグラフから探す。
- そのノードに直接つながっている隣接ノード(Neighbors)と、その間のエッジ(関係性)を取得する。
# 1-hop 近傍の取得イメージ
context_lines = []
for neighbor in G[node]:
rel = G[node][neighbor]['relation']
context_lines.append(f"{node} -> [{rel}] -> {neighbor}")
これにより、単なるキーワード検索ではなく、「そのキーワードが他の要素とどう関わっているか」 という構造化されたコンテキストをLLMに渡すことができます。
3. 実行結果の分析 (Result Analysis)
「これら2つの論文(RAGとGraphRAG)の関係性は何ですか?また、GraphRAGは従来のRAGのどのような課題を解決しようとしていますか?」という質問に対する、3つのアプローチの結果を分析します。
1. Vanilla LLM (RAGなし)
[実行結果]
はい、ご質問にお答えします。
### 1. RAGとGraphRAGの関係性
- **RAG(Retrieval-Augmented Generation)**は、2020年にFacebook AI Researchによって提案された手法です。RAGは、外部知識ベース(たとえばWikipediaなど)から関連文書を検索(retrieval)し、その情報をもとに生成モデル(たとえばGPTやBARTなど)が回答を生成(generation)する、検索拡張型の生成モデルです。
- **GraphRAG**は、RAGの発展系・改良版の一つです。GraphRAGは、RAGの「検索した文書をそのまま使う」アプローチに対し、**文書間の関係性(グラフ構造)を活用する**ことで、より高度な知識統合や推論を可能にしようとしています。
つまり、**GraphRAGはRAGの枠組みを拡張し、検索した文書同士の関係性(グラフ)を活用することで、より良い回答生成を目指す手法**です。
---
### 2. GraphRAGが従来のRAGのどのような課題を解決しようとしているか
従来のRAGには以下のような課題がありました:
- **文書間の関係性を考慮しない**
RAGは、検索した文書を個別に扱い、それらの内容を単純に生成モデルに渡します。しかし、複数の文書間に因果関係や階層関係、同義語関係などがある場合、それらを考慮できません。
- **知識の統合が困難**
複数の文書から得られる断片的な知識を、うまく統合して一貫した回答を生成するのが難しい場合があります。
- **複雑な推論が苦手**
たとえば「A→B→C」のような知識の連鎖や、複数文書をまたいだ推論が必要な場合、RAGは十分に対応できません。
**GraphRAGはこれらの課題を解決するために、以下のようなアプローチを取ります:**
- **文書や知識片をノード、関係性をエッジとするグラフを構築**
検索した文書や知識片をグラフ構造で表現し、文書間の関係性(たとえば共通のエンティティ、因果関係、参照関係など)をエッジとして明示的に扱います。
- **グラフベースの推論や知識統合**
グラフ構造を活用することで、複数文書にまたがる知識の連鎖や統合、複雑な推論が可能になります。
- **より一貫性のある、正確な回答生成**
文書間の関係性を考慮することで、断片的な情報をつなぎ合わせ、一貫性のある回答を生成しやすくなります。
---
### まとめ
- **RAG**は「検索+生成」の枠組みで、検索した文書をそのまま使う。
- **GraphRAG**は、検索した文書間の関係性をグラフ構造で表現し、知識の統合や推論を強化することで、RAGの課題(知識統合・推論・一貫性)を解決しようとしています。
ご参考になれば幸いです。もし具体的な論文名や詳細が必要であれば、追加でご質問ください。
[分析]
- 結果の傾向: 一般的な知識に基づいて回答しています。GraphRAGについても概要は捉えていますが、これはLLMが学習データとして持っている一般的な知識(または名前からの推測)に基づいている可能性があります。
- 分析: 外部知識がないため、今回読み込ませた特定の論文("From Local to Global...")の具体的な内容(例えば「Global Search」や「Community Summaries」といった特定の用語や手法の詳細)には触れられていません。あくまで「一般的な概念としてのGraphRAG」の説明に留まっています。
2. Standard RAG (Vector Search)
[実行結果]
はい、以下の通りお答えします。
---
### 1. RAGとGraphRAGの関係性
- **RAG(Retrieval-Augmented Generation)**は、ユーザーのクエリに対して外部データソースから関連情報を検索し、その情報をLLM(大規模言語モデル)などの生成AIモデルのプロンプトに組み込んで応答を生成するシステム全般を指します。
典型的には、ベクトル検索(Vector RAG)などで関連文書を取得し、それをプロンプトに入れて回答を生成します。
- **GraphRAG**は、従来のRAGの発展形であり、RAGの基本的な枠組み(検索+生成)を踏襲しつつ、**知識グラフ**や**グラフ構造**を活用して、より高度な情報要約や意味理解(グローバルなサマリーや全体像の把握)を可能にする新しいアプローチです。
---
### 2. GraphRAGが従来のRAGのどのような課題を解決しようとしているか
#### 主な課題
従来のRAG(特にベクトルRAG)には以下のような課題がありました:
- **局所的な情報の寄せ集めに留まりやすい**
→ ベクトル検索で取得した一部の文書やパッセージの断片的な情報を組み合わせるため、全体像やグローバルなテーマを捉えた回答が難しい。
- **大規模コーパス全体の「意味づけ」や「要約」が苦手**
→ LLMのコンテキストウィンドウ制限により、全データを一度に扱えず、部分的な情報しかプロンプトに入れられない。
#### GraphRAGのアプローチと解決策
- **知識グラフの生成と活用**
→ コーパス全体から知識グラフ(エンティティや関係性のネットワーク)を構築し、グラフ構造を使って情報を整理・要約。
- **グラフのコミュニティ検出による階層的・テーマ別の要約**
→ グラフのモジュール性(コミュニティ構造)を活かし、関連性の高いノード群ごとに要約を作成し、それを階層的に統合していくことで、よりグローバルなサマリーを生成。
- **全体像の把握やグローバルな質問への対応力向上**
→ 局所的な事実の寄せ集めではなく、コーパス全体のテーマや傾向を反映した回答が可能になる。
#### 効果
- **包括性・多様性の向上**
→ 実験では、GraphRAGはベクトルRAGよりも「包括的で多様な回答」を生成できることが示されています。
- **グローバルな質問(全体像や大きなテーマに関する質問)への強さ**
→ ベクトルRAGでは難しかった「全体を俯瞰した要約」や「大きなテーマに関する質問」に対して、より適切な回答が可能。
---
### まとめ
- **GraphRAGはRAGの発展形であり、知識グラフとグラフ構造を活用することで、従来のRAGが苦手とした「全体像の把握」や「グローバルな要約・質問応答」の課題を解決しようとしている。**
- **従来のRAGが局所的な情報の寄せ集めに留まりやすいのに対し、GraphRAGはコーパス全体の意味構造を活かした包括的な情報提供を目指している。**
ご参考になれば幸いです。
[分析]
- 結果の傾向: 質問に関連するキーワード("relationship", "limitations", "GraphRAG")を含むチャンクを検索して回答しています。「コミュニティ検出」や「階層的要約」といった論文固有の用語が出てきており、Vanilla LLMより具体的です。
- 分析: しかし、回答の構成が少し箇条書きの羅列に近く、断片的な情報のつぎはぎ感があります。これは、ベクトル検索が「類似した部分」を独立して取得するため、それらを統合する論理的なつながり(Connecting the dots)が弱くなる傾向があるためです。
3. GraphRAG (Knowledge Graph)
[実行結果]
GraphRAG:
**1. RAGとGraphRAGの関係性**
- **進化・拡張の関係**
知識グラフによると、GraphRAGは「RAGの進化形(evolution of RAG approach)」であり、「RAGの拡張(is an extension of RAG)」です。つまり、GraphRAGはRAGの基本的な枠組みを発展・拡張させた新しい手法です。
- **比較・改善の関係**
GraphRAGは「RAG baselineより改善(improves over RAG baseline)」し、「従来手法(previous methods)」や「vector RAG approaches」と比較されています。GraphRAGはRAGの課題を解決し、より包括的かつ多様な回答(comprehensiveness and diversity of answers)を提供することを目指しています。
- **技術的なつながり**
両者とも「LLM(大規模言語モデル)」を活用し、外部コーパスから情報を取得してユーザークエリに応答する点で共通しています。
**2. GraphRAGが従来のRAGのどのような課題を解決しようとしているか**
- **グローバルなセンスメイキング(sensemaking)への対応**
RAGやvector RAGは「ローカルな意味的類似性(local semantic similarity)」や「局所的なクエリ(localized queries)」には強いですが、「グローバルなセンスメイキングクエリ(sensemaking queries)」には対応できません(vector RAG -> does_not_support -> sensemaking queries)。
GraphRAGは「グローバルなセンスメイキング(global sensemaking)」や「大規模コーパス全体にわたるセンスメイキング(global sensemaking over entire corpus)」を可能にします。
- **知識グラフの活用による構造的理解**
GraphRAGは「エンティティ知識グラフ(entity knowledge graph)」を構築し、「グラフベースのコミュニティ検出(graph-based community detection)」や「階層的なコミュニティ分割(hierarchy of communities)」を行うことで、情報の構造 的な把握と要約(community summaries)を実現します。
これにより、単なるベクトル空間の類似性に頼るRAGよりも、情報の網羅性や多様性が向上します。
- **大規模データコーパスへのスケーラビリティ**
GraphRAGは「ユーザークエリの一般性(generality of user questions)」や「ソーステキストの量(quantity of source text)」にスケールしやすい設計です。
RAGはLLMのコンテキストウィンドウ制約を回避するための手法ですが、GraphRAGはさらに大規模なコーパス全体に対してもグローバルな意味理解を可能にします。
- **多様で包括的な回答生成**
GraphRAGは「回答の包括性と多様性(comprehensiveness and diversity of answers)」を向上させることを主な貢献(main contribution)としています。
**まとめ**
- **RAG**は外部コーパスから情報を取得しLLMで回答を生成する手法ですが、主にローカルな意味的類似性に依存し、グローバルなセンスメイキングや大規模コーパス全体の構造的理解には限界がありました。
- **GraphRAG**はRAGを発展させ、知識グラフとコミュニティ検出を活用することで、グローバルなセンスメイキングや大規模データに対する包括的・多様な回答生成を可能にした手法です。
このように、GraphRAGはRAGの課題(ローカル性、スケーラビリティ、グローバルな意味理解の不足)を解決するために設計された、RAGの進化形・拡張版です。
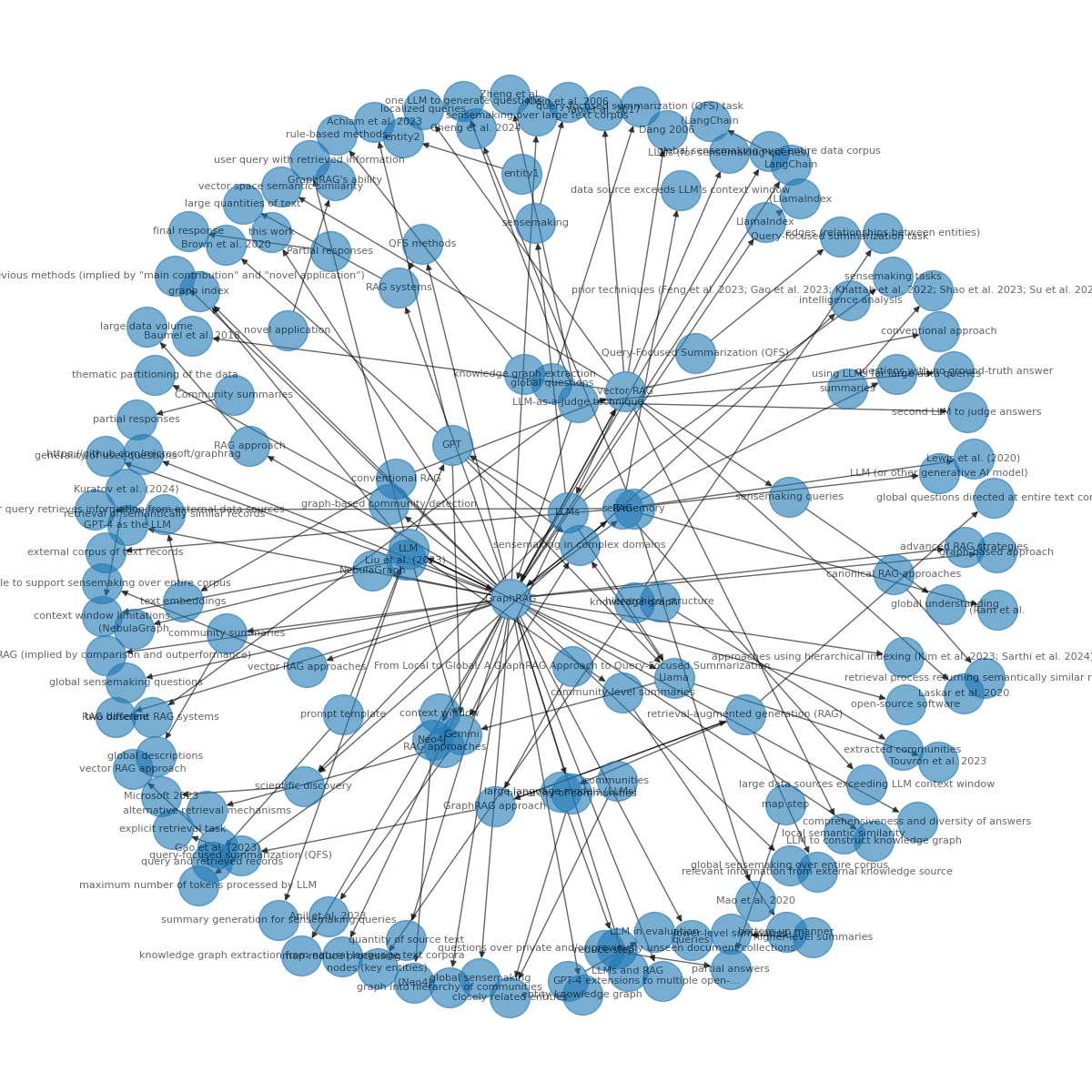
生成した関係図
[分析]
- 結果の傾向: 「GraphRAG --[improves]--> RAG baseline」や「vector RAG --[does_not_support]--> sensemaking queries」といった、グラフから抽出された明確な関係性に基づいた回答になっています。
- 分析: 特に「vector RAG -> does_not_support -> sensemaking queries」のような、否定的な関係や対比関係が明確に示されているのが特徴です。グラフ構造として関係性を保持しているため、LLMは「AはBではない」「AはBを解決する」という論理的なつながりを強く確信して回答できています。これがGraphRAGの強みである「構造化された知識に基づく回答」です。
3つのアプローチの比較まとめ
| アプローチ | 特徴 | メリット | デメリット |
|---|---|---|---|
| Vanilla LLM | 内部知識のみ | 実装不要、一般的知識に強い | 最新情報や専門知識に弱く、ハルシネーションのリスクあり |
| Standard RAG | ベクトル検索 | 具体的な事実の検索に強い | 情報が断片化しやすく、全体像や関係性の把握が苦手 |
| GraphRAG | ナレッジグラフ | 構造的な関係性の理解、全体像の把握 | 実装が複雑、グラフ構築にコストがかかる |
今回の実験から、「AとBの関係は?」といった構造的な理解を問う質問には、GraphRAGが圧倒的に有利であることが確認できました。Standard RAGが「点」の情報を集めるのに対し、GraphRAGは「線」でつながった情報を提示できるため、より人間に近い論理的な回答が可能になります。
4. 議論
GraphRAGは強力ですが、銀の弾丸ではありません。以下のトレードオフを考慮する必要があります。
- 構築コストとレイテンシ: グラフの構築(トリプル抽出)には多くのLLMコールが必要で、時間とコストがかかります。リアルタイム性が求められるシステムでは、事前にグラフを構築しておくなどの工夫が必要です。
- グラフの品質: LLMが抽出するエンティティや関係性の品質に依存します。ノイズが多いと、逆に検索精度が下がる可能性もあります。
しかし、「全体像の把握」や「複雑な推論」が必要なドメイン(法務、医療、研究開発など)では、このコストを支払う価値は十分にあります。
次回予告:RAGの自動評価 (RAG Evaluation)
ここまで3日間、様々なRAGの手法(Basic, Advanced, Graph)を試してきました。
「なんとなく良くなった気がする」ではなく、「どれくらい良くなったのか?」 を定量的に測る必要があります。
次回 Day 4 では、「RAGの自動評価」 に取り組みます。
Ragasなどのフレームワークを使い、Retrieval(検索)とGeneration(生成)のそれぞれの品質をスコアリングする方法を学びます。お楽しみに!