Googleが提供しているVision APIをJavaで使ってみました。
Vision APIとは
Googleが提供しているAPIで
機械学習モデルを使い、対象となる画像から様々な情報を取得することができます。
画像に含まれている文字、物(猫や人物が履いているジーパンとか)、人物の表情などの
情報を取得することができます。
Google Cloud Platform(GCP)が提供する機械学習サービスの一種です。 このサービスを利用することで、Googleの持つ画像に関する機械学習モデルを使い、対象となる画像から様々な情報を取得することができます。
料金は、1000回/月(API実行回数)までなら無料です。
詳細は、Googleのページ⧉Cloud Vision の料金を参照ください。
1. Cloud Vision APIを使用するための準備
設定は下記から行います。
⧉Google クラウド プラットフォーム
1.1. プロジェクトの作成
まずはGCPでプロジェクトを作成します。
詳細はこちらの記事を参照ください
⧉[Google Sheets API] Google Sheets API v4をJavaで操作する(1.1. プロジェクトの作成)
1.2. Cloud Vision APIの設定
Cloud Vision APIを使えるようにします。
1. メニューの 「APIとサービス」 -> 「ライブラリ」 を選択します。

2. Croud Visionと入力して「Cloud Vision API」を検索します。

3. 「有効にする」ボタンを押して「Cloud Vision API」を使用可能にします。

1.3. Googleサービスアカウントの作成
APIを操作するためにサービスアカウントを作成します。
詳細はこちらの記事を参照ください
⧉[Google Sheets API] Google Sheets API v4をJavaで操作する(1.3. Googleサービスアカウントの作成)
上記の記事に加え、Cloud Storageに置いてある画像を元に画像処理をしたい方は
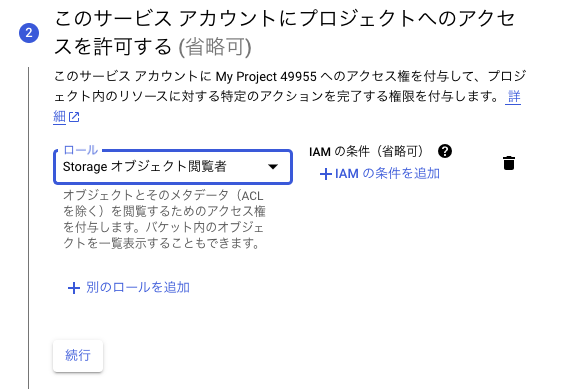
サービスアカウント作成時に「Storageオブジェクト閲覧者」の権限を付与します。
(サービスアカウント作成後でもOK)
元にする画像がローカルファイルだけであれば、権限は必要ありません。

1.4. Cloud Storageに使用する画像を置く
Cloud Storageに画像を置く手順です。
こちらもローカルにある画像ファイルを使うだけなら必要ありません。
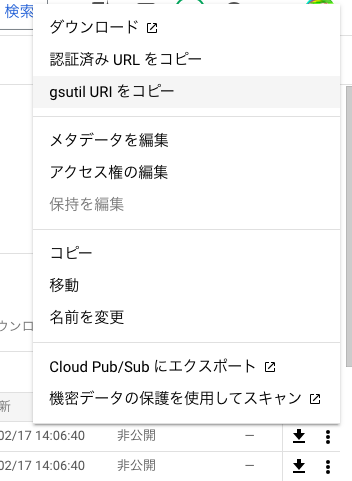
1. Cloud Storageに商品に登録する画像をおきます。

2. 登録した画像を選択して「gsutil URIコピー」を選択します。
このURLは後のプログラムで使用します。
2. Cloud Vision APIを使ってみる
2.1. googleライブラリの読み込み
Cloud Vision APIを使用するためにライブラリのパスを設定します。
私の環境はpom.xmlで下記を指定しています。
Javaのバージョンは21を使用しています。
dependenciesと同じ階層にdependencyManagementを追加します。
<dependencies>
....
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-vision</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.31.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
2.2. CredentialsProviderの取得
サービスアカウントのJSONを指定してCredentialsProviderを取得します。
ファイルパスには、1.3. Googleサービスアカウントの作成
でダウンロードしたJSONファイルのパスを指定してください。
private static CredentialsProvider getCredentialsProvider() throws IOException {
String jsonFilePath = "サービスアカウントJSONキーファイルのパス";
FileInputStream jsonFileInputStream = new FileInputStream(jsonFilePath);
GoogleCredentials credentials = GoogleCredentials.fromStream(jsonFileInputStream);
return FixedCredentialsProvider.create(credentials);
}
2.3. Imageインスタンスを取得
使用する画像がローカルにあるか、Cloud Storageにあるかで
Imageを取得する方法が変わります。
2.3.1. ローカル画像から
public static Image getLocalImage(String path) throws FileNotFoundException, IOException {
ByteString imgBytes = ByteString.readFrom(new FileInputStream(path));
return Image.newBuilder().setContent(imgBytes).build();
}
2.3.2. Cloud Storageの画像から
public static Image getGcsImage(String gcsPath) {
ImageSource imgSource = ImageSource.newBuilder().setGcsImageUri(gcsPath).build();
return Image.newBuilder().setSource(imgSource).build();
}
2.4. ImageAnnotatorClientの取得
Google Cloud Visionの画像検出系のAPIを使用するときに使うインスタンスです。
本記事以外の画像検出を行うときにも使用しますのでメソッド化しています。
private static ImageAnnotatorClient getImageAnnotatorClient() throws IOException {
ImageAnnotatorSettings imageAnnotatorSettings = ImageAnnotatorSettings.newBuilder()
.setCredentialsProvider(getCredentialsProvider()).build();
return ImageAnnotatorClient.create(imageAnnotatorSettings);
}
2.5. APIを呼び出す
APIを呼び出します。
Vision APIの画像検出のAPI実行は基本的に全て同じです。
実行したいAPIを「Feature.Type」で指定します。
private static BatchAnnotateImagesResponse execApi(Image img, Feature.Type type) throws IOException {
List<AnnotateImageRequest> requests = new ArrayList<>();
Feature feat = Feature.newBuilder().setType(type).build();
AnnotateImageRequest request = AnnotateImageRequest.newBuilder().addFeatures(feat).setImage(img).build();
requests.add(request);
try (ImageAnnotatorClient client = getImageAnnotatorClient()) {
BatchAnnotateImagesResponse response = client.batchAnnotateImages(requests);
return response;
}
}
2.6. プログラムの実行
プログラムを動かします。
実行したいAPIを「Feature.Type」で指定します。
実行した結果は、BatchAnnotateImagesResponseで取得できますが、
実行したAPIによって取得できる値が変わってきます。
public static void main(String[] args) throws Exception{
Image image = getLocalImage("ローカルファイルのパス");
//Cloud Storageの画像を使用したい場合はこちら
// image = getGcsImage("Cloud Storageのファイルパス");
BatchAnnotateImagesResponse res =
execApi(image,Feature.Type.LABEL_DETECTION);
}
3. いろいろとAPIを叩いてみる
APIの呼び出し方は全て同じで、
Feature.Typeの指定を変えるだけで結果を取得できます。
どのような結果が返ってくるかは、Feature.Typeの指定により変わります。
それぞのAPIで検証した結果を記事にしています。
実際の検証結果を見ればAPIがどのような動きをするのか一目瞭然かと思います。
3.1. 人物の顔を検出
指定するタイプ
Feature.Type.FACE_DETECTION
概要
画像内に含まれている人の顔を検出します。
画像内の人の顔の位置のみだけではなく、
・顔が向いている向き
・顔のパーツ位置(目、鼻など)
・表情(怒っているか、悲しんでいるかなど)
なども情報として取得できます。
記事
⧉[Vision API] Javaで画像内の人の顔を検出する
3.2. テキストを検出
指定するタイプ
Feature.Type.TEXT_DETECTION
か
Feature.Type.DOCUMENT_TEXT_DETECTION
概要
画像内に含まれている文字を検出します。
画像から光学式文字認識(OCR)を使用してテキストを検出、抽出できます。
記事
⧉[Vision API] Javaで画像内の文字を検出する
3.3. ランドマークを検出
指定するタイプ
Feature.Type.LANDMARK_DETECTION
概要
画像内に含まれているランドマークを検出します。
ランドマークとは、よく知られている自然や人工建造物を示すそうです。
画像内のランドマークの位置だけではなく、緯度と経度を取得できます。
記事
⧉[Vision API] Javaで画像内のランドマークを検出する
3.4. ロゴを検出
指定するタイプ
Feature.Type.LOGO_DETECTION
内容
画像内に含まれているロゴを検出します。
記事
⧉[Vision API] Javaで画像内のロゴを検出する
3.5. ラベルを検出
指定するタイプ
内容
画像内に含まれているラベルを検出します。
ラベルは、画像にどのようなものが写っているのかをAIで判定し、
文字列(英語)で返してくれます。
例えば、「ジーンズ」「猫」「自然食品」なども認識されます。
記事
⧉[Vision API] Javaで画像内のラベルを検出する
3.6. オブジェクトを検出
指定するタイプ
Feature.Type.OBJECT_LOCALIZATION
内容
画像内に含まれているオブジェクトを検出します。
画像にどのようなものが写っているのかをAIで検出し、画像内の位置とオブジェクト名前を返します。
記事
⧉[Vision API] Javaで画像内のオブジェクトを検出する
3.7. クロップヒントを検出
指定するタイプ
Feature.Type.CROP_HINTS
内容
APIを使用し、画像をクロップするヒント(座標)を取得します。
画像のクロップとは、中心のROI矩形領域のみの部分画像の切り出すことで
画像の最適化を行います。
記事
⧉[Vision API] Javaで画像のクロップヒントを検出する
3.8. 画像プロパティを検出
指定するタイプ
Feature.Type.IMAGE_PROPERTIES
内容
APIを使用し、画像のプロパティを取得します。
ドミナントカラーとクロップヒントを取得します。
記事
⧉[Vision API] Javaで画像のプロパティを検出する
3.9. 不適切なコンテンツを検出
指定するタイプ
Feature.Type.SAFE_SEARCH_DETECTION
内容
画像のセーフサーチ検出を行います。
セーフサーチ検出は、画像に含まれる不適切なコンテンツを検出します。
5つのカテゴリ(アダルトなど)が、画像にどの程度の可能性で存在するかチェックします。
記事
⧉[Vision API] Javaで不適切なコンテンツを検出する(セーフサーチ検出)
3.10. エンティティとページを検出
指定するタイプ
Feature.Type.WEB_DETECTION
内容
画像のエンティティとページを取得します。
指定した画像に対し、インターネット上の情報を取得できます。
下記のような情報が取得できます。
・インターネット上の類似の画像からのエンティティ
・インターネット画像に一致する画像
・視覚的に類似した画像
・リクエスト画像のトピックに関するサービスの最善の推測
・インターネットからの一致する画像を含む Web ページ
・インターネットからの部分一致画像
記事
⧉[Vision API] Javaで画像のエンティティとページを検出する
おしまい