Googleが提供しているVision APIをJavaで使ってみました。
APIを使用し、画像内に含まれている文字を検出します。
画像から光学式文字認識(OCR)を使用してテキストを検出、抽出できます。
検出の指定は2つあります。
| タイプ | 検出内容 |
|---|---|
| TEXT_DETECTION | 抽出された文字列全体、個々の単語、それらの境界ボックスが取得できます。 |
| DOCUMENT_TEXT_DETECTION | 「TEXT_DETECTION」で取得できる情報に加え、 検出結果の信頼度、ページ、ブロック、段落、単語、改行の情報が取得できます。 |
APIを利用する環境の準備から始める場合や、コードを実行する際は、
⧉[Vision API] Javaで画像内のいろいろなものを検出する
を参照ください。
| No | 目次 | |
|---|---|---|
| 1 | Feature.Typeの指定 | |
| 2 | 検出言語の指定 | |
| 3 | 実行結果の取得 | |
| 1 | レスポンスの出力 | |
| 2 | レスポンスの内容 | |
| 4 | 結果の検証 | |
| 1 | 文字が少ない場合 | |
| 2 | 文字が多い場合 | |
| 3 | 手書き文字(数字)の場合 | |
| 4 | 手書き文字(ひらがな)の場合 |
1. Feature.Typeの指定
画像内の文字を検出する場合は、下記のどちらかを指定します。
Feature.Typeの指定によって、レスポンスで得られる情報に
confidence(検出結果の信頼度など)が追加されます。
| Type | 検出結果の信頼度などの有無 |
|---|---|
| Feature.Type.TEXT_DETECTION | 無し |
| Feature.Type.DOCUMENT_TEXT_DETECTION | あり |
以下の記事でexecApi()にタイプを指定します。
⧉[Vision API] Javaで画像内のいろいろなものを検出する
2. 検出言語の指定
検出されたい文字の言語を指定することもできます。
googleドキュメントでは、指定しない方が「自動言語検出」によって高い確率で
検出できるので言語の指定はしない方がよいと書いてありますが、
検出される文字が手書きなど、検出されづらい文字の場合は指定した方がよさそうです。
「4.2. 手書き文字(ひらがな)の場合」で言語指定有無を変えて検証しています。
コードの実装
⧉[Vision API] Javaで画像内のいろいろなものを検出する
のコードにあるexecApi()メソッドの下記のように書き換えてください。
ImageContextインスタンスを生成し、言語ヒント「ja-t-i0-handwrit」を指定します。
それをAnnotateImageRequestにsetImageContext()メソッドで追加しています。
ImageContext ic = ImageContext.newBuilder().addLanguageHints("ja-t-i0-handwrit").build();
AnnotateImageRequest request = AnnotateImageRequest.newBuilder().addFeatures(feat).setImageContext(ic).setIm
言語ヒントの記述方法は、googleドキュメントによると
languageHint の形式は、BCP47 言語コード形式のガイドラインに準拠しています。BCP47 指定の形式は次のとおりです。
language ["-" script] ["-" region] *("-" variant) *("-" extension) ["-" privateuse].
たとえば、言語ヒント en-t-i0-handwrit は、
英語(en)、変換拡張シングルトン(t)、入力方法エンジン変換の拡張コード(i0)、手書き入力変換コード(handwrit)を指定しています。
このコードは、「手書き入力から変換された英語」という意味になります。
スクリプト コードの指定は必要ありません。Latn は en 言語に含まれています。
だそうです。
なお「ja」だけの指定だと、言語未指定の場合と結果は変わりませんでした。
3. 実行結果の取得
3.1. レスポンスの出力
取得した結果をコンソールに出力します。
サンプルでは、検出されたテキストと画像内の位置を出力しています。
private static void output(BatchAnnotateImagesResponse response) {
List<AnnotateImageResponse> responses = response.getResponsesList();
for (AnnotateImageResponse res : responses) {
if (res.hasError()) {
System.out.format("Error: %s%n", res.getError().getMessage());
return;
}
for (EntityAnnotation annotation : res.getTextAnnotationsList()) {
System.out.format("Text: %s%n", annotation.getDescription());
System.out.format("Position : %s%n", annotation.getBoundingPoly());
}
}
}
3.2. レスポンスの内容
BatchAnnotateImagesResponseの
getResponsesListでAnnotateImageResponseリストが取得できます。
検出されなった場合は、空のリストが返ってきます。
AnnotateImageResponse
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getTextAnnotationsList | List<EntityAnnotation> | 検出されたテキストの画像内領域 リストの最初の要素に、検出された全ての文字と言語コードが返ります |
| getFullTextAnnotation | TextAnnotation | 検出されたテキストの情報(領域含む) |
EntityAnnotation
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getLocale | string | ロケールの言語コード リストの最初の要素のみ |
| getDescription | string | 検出されたテキスト |
| getBoundingPoly | BoundingPoly | テキストの画像領域 |
BoundingPoly
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getVerticesList | List<Vertex> | 境界ポリゴンの頂点。 左上、右上、左下、右下の順 |
Vertex
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getX | int | X座標 |
| getY | int | Y座標 |
TextAnnotation
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getText | string | 画像内で検出された全てのテキスト(UTF-8) |
| getPagesList | List<Page> | 検出に使用した画像情報。 1枚の画像に対して一つの要素 |
Page
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getProperty | TextProperty | 追加情報 文字がどの言語か確定されている場合は返しません |
| getWidth | int | 検出に使用した画像の幅 |
| getHeight | int | 検出に使用した画像の高さ |
| getBlocksList | List<Block> | この画像内の検出されたテキストの情報 |
| getConfidence | float | 検出結果の信頼度。範囲は0〜1 DOCUMENT_TEXT_DETECTIONの場合のみ |
TextProperty
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getDetectedLanguagesList | List<DetectedLanguage> | 検出結果の信頼度のリスト |
| getDetectedBreak | DetectedBreak | テキストセグメントの開始または終了 BreakTypeが検出された場合のみ |
DetectedLanguage
この値が返ってきた場合は、TypeがDOCUMENT_TEXT_DETECTIONだとかに
関係なくconfidenceが取得できます。
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getLanguageCode | string | 言語コード |
| getConfidence | float | 検出結果の信頼度。範囲は0〜1 |
DetectedBreak
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getType | BreakType(enum) | 検出されたテキストセグメント |
Block
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getBoundingBox | BoundingPoly | 境界 |
| getParagraphsList | List<Paragraph> | このブロック内の情報 |
| getBlockType | BlockType(enum) | 検出されたタイプ (今回の場合はTEXT固定) |
| getConfidence | float | 検出結果の信頼度。範囲は0〜1 DOCUMENT_TEXT_DETECTIONの場合のみ |
BoundingPoly
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getVerticesList | List<Vertex> | 画像の境界 |
Paragraph
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getBoundingBox | BoundingPoly | 境界 Blockの境界情報と同じ? |
| getWordsList | List | 単語のリスト |
| getConfidence | float | 検出結果の信頼度。範囲は0〜1 DOCUMENT_TEXT_DETECTIONの場合のみ |
Word
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getProperty | TextProperty | 追加情報 PageのgetPropertyがある場合に含まれる |
| getBoundingBox | BoundingPoly | 境界 |
| getSymbolsList | List<Symbol> | 単語内の記号のリスト。 記号の順序は、自然な読み取り順序に従う |
| getConfidence | float | 検出結果の信頼度。範囲は0〜1 DOCUMENT_TEXT_DETECTIONの場合のみ |
Symbol
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getProperty | TextProperty | このテキストの検出結果の信頼度と言語コード |
| getBoundingBox | BoundingPoly | 境界 |
| getText | string | 検出されたテキスト(UTF-8) |
| getConfidence | float | 検出結果の信頼度。範囲は0〜1 DOCUMENT_TEXT_DETECTIONの場合のみ |
BlockType
| タイプ | 内容 |
|---|---|
| Barcode | バーコードブロック |
| Picture | 画像ブロック |
| Ruler | 水平/垂直ラインボックス |
| Table | テーブルブロック |
| Text | 通常のテキストブロック |
| Unknown | 不明なブロック タイプ |
BreakType
| タイプ | 内容 |
|---|---|
| UNKNOWN | 不明 |
| SPACE | スペース |
| SURE_SPACE | スペース(広い) |
| EOL_SURE_SPACE | 改行 |
| HYPHEN | テキスト内に存在しない終了行のハイフン |
| LINE_BREAK | 段落を終了する改行 |
4. 結果の検証
画像に含まれる文字が少ない場合と多い場合についてそれぞれ検証してみました。
検出言語は、ほぼ正しく検出してくれたので指定していませんが、
手書き文字の一部のみ日本語を指定して実行しています。
結果画像の加工は取得した座標を使ってjava.awt.Graphics2Dで加工しています。
4.1. 文字が少ない場合
検出させる元画像
元の画像です。

検出された結果
取得できたPolygon座標を赤枠で囲み、認識された文字を青文字で追記しました。

先程の赤枠を白で塗りつぶし、認識された文字を青文字で書いてみました。
矢印まで文字として認識されているのは想定外でした。。

追加情報
日本語と検出しましたが、もしかしたら半分ぐらいで違うかも。
ということみたいです。
| 言語 | 信頼度 |
|---|---|
| ja | 0.5532319 |
4.2. 文字が多い場合
検出させる元画像

検出された結果
取得できたPolygon座標を赤枠で囲み、認識された文字を青文字で追記しました。

先程の赤枠を白で塗りつぶし、認識された文字を青文字で書いてみました。
ほぼほぼ、文字が認識されているのがわかります。
(「キャバクラ」が読めなかったみたいw)

追加情報
色々な言語の追加情報が返ってきました。
| 言語 | 信頼度 |
|---|---|
| ja | 0.35909998 |
| en | 0.22719632 |
| ha | 0.05234466 |
| vi | 0.022947626 |
| no | 0.018774534 |
| is | 0.013122048 |
| zh | 0.010697705 |
4.3. 手書き文字(数字)の場合
知り合いの6歳のお子さんの数字の書き取りをお借りしました。
検出させる元画像
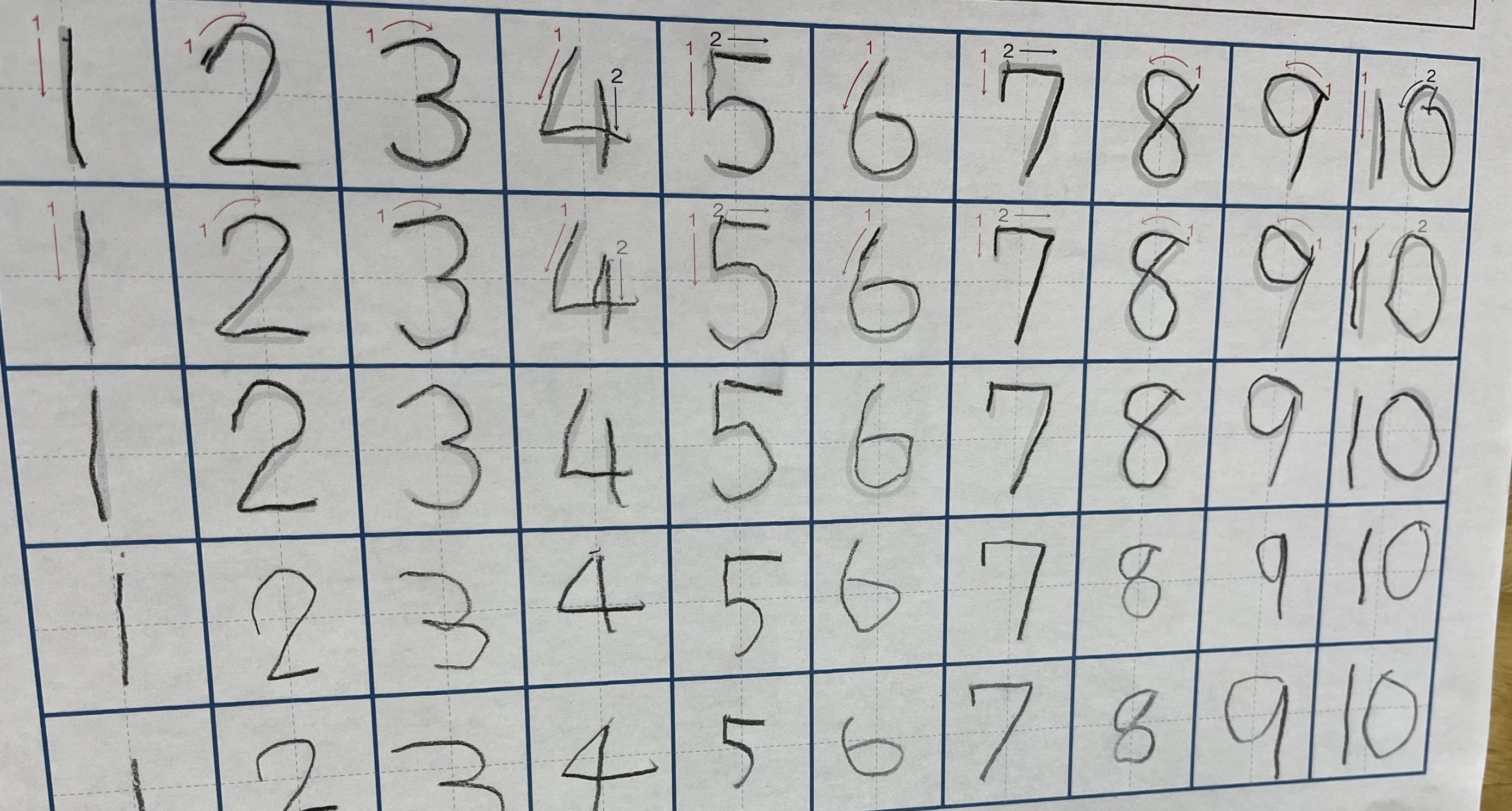
検出された結果

追加情報
追加情報は返ってきませんでした。
検出文字は英字であると確信しているようです。
数字の書き取りは100点ですね。
4.4. 手書き文字(ひらがな)の場合
知り合いの6歳のお子さんのひらがなの書き取りをお借りしました。
それぞれの文字で左側が薄い線をなぞって、右側が空欄に文字を書いているようです。
書いた文字をAIに判定させる。まさしく、AI先生ですね。
先に結論を書きますが、この子は「ま行」「や行」を書くのが苦手なようです。
日本語として検出されなかったので、この行のみ日本語指定パターンも試しています。
4.4.1. あ行、か行
検出させる元画像

検出された結果

追加情報
追加情報は返ってきませんでした。
検出文字は日本語であると確信しているようです。
4.4.2. さ行、た行
検出させる元画像

検出された結果

追加情報
追加情報は返ってきませんでした。
検出文字は日本語であると確信しているようです。
4.4.3. な行、は行
検出させる元画像

検出された結果

追加情報
追加情報は返ってきませんでした。
検出文字は日本語であると確信しているようです。
4.4.4. ま行、や行
この行のみ日本語であると検出されなかったので、言語を指定して検出してみました。
検出させる元画像

4.4.4.1.言語の指定なし
検出された結果

追加情報
日本の文字であると検出してくれませんでした。
可能性は低いけど、英語かクロアチア語だと思っているようです。
| 言語 | 信頼度 |
|---|---|
| en | 0.1996949 |
| hr | 0.15301146 |
4.4.4.2.言語の指定あり
検出された結果

追加情報
追加情報は返ってきませんでした。
「日本語」を指定しているので当然ですね。
言語指定ありでもこの精度でした。。
4.4.5. ら行、わ行
検出させる元画像
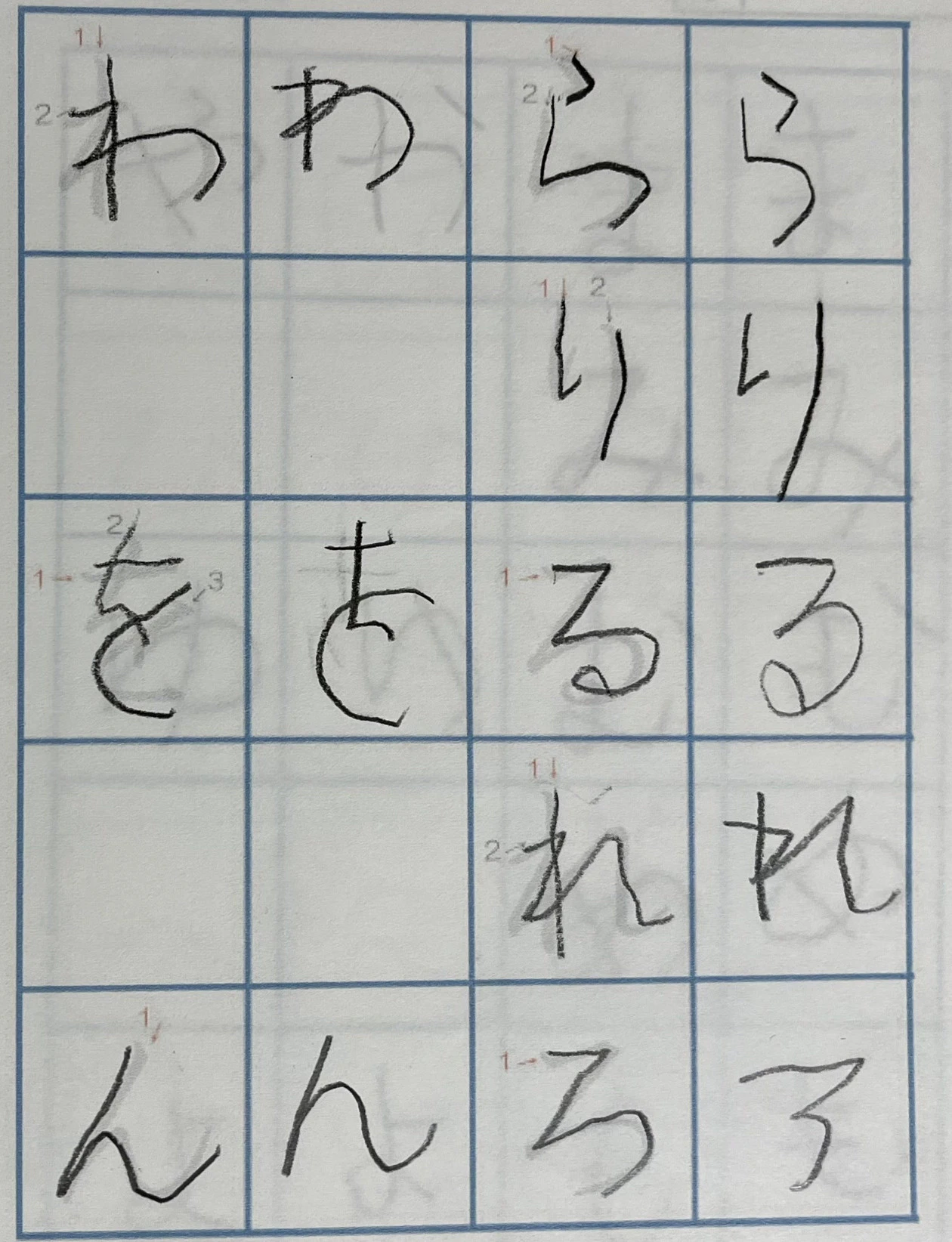
検出された結果
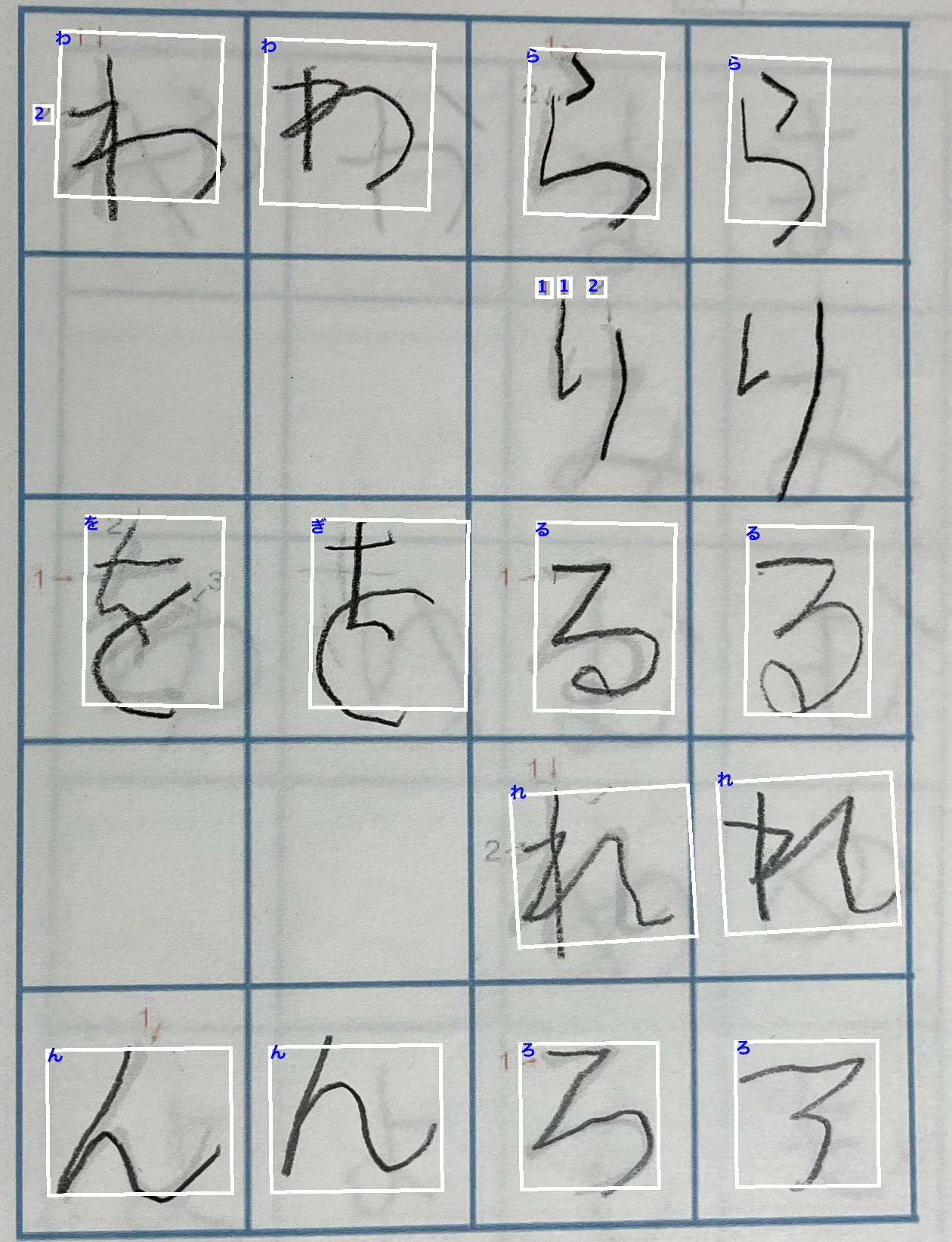
追加情報
追加情報は返ってきませんでした。
検出文字は日本語であると確信しているようです。
おしまい。。。