Googleが提供しているVision APIをJavaで使ってみました。
APIを使用し、画像内に含まれているオブジェクトを検出します。
画像にどのようなものが写っているのかをAIで検出し、
画像内の位置とオブジェクト名前を返します。
本記事の3.結果の検証でどのようなものが検出されるか試していますが、
大きめに映り込んでいるものしか検出されないようです。
ラベルを検出するの方がより細かい情報を取得できそうです。
APIを利用する環境の準備から始める場合や、コードを実行する際は、
⧉[Vision API] Javaで画像内のいろいろなものを検出する
を参照ください。
| No | 目次 | |
|---|---|---|
| 1 | Feature.Typeの指定 | |
| 2 | 実行結果の取得 | |
| 1 | レスポンスの出力 | |
| 2 | レスポンスの内容 | |
| 3 | 結果の検証 | |
| 1 | 駐車場 | |
| 2 | ボーリング中 | |
| 3 | 人物 | |
| 4 | 街 | |
| 5 | 野菜 | |
| 6 | 猫 | |
| 7 | 風景 | |
| 8 | デスク |
1. Feature.Typeの指定
オブジェクトを検出する場合は、
Feature.Type.OBJECT_LOCALIZATION
を指定します。
以下の記事でexecApi()にタイプを指定します。
⧉[Vision API] Javaで画像内のいろいろなものを検出する
2. 実行結果の取得
2.1. レスポンスの出力
取得した結果をコンソールに出力します。
private static void output(BatchAnnotateImagesResponse response){
List<AnnotateImageResponse> responses = response.getResponsesList();
for (AnnotateImageResponse res : responses) {
for (LocalizedObjectAnnotation entity : res.getLocalizedObjectAnnotationsList()) {
System.out.format("Object name: %s%n", entity.getName());
System.out.format("Confidence: %s%n", entity.getScore());
System.out.format("Normalized Vertices:%n");
entity.getBoundingPoly()
.getNormalizedVerticesList()
.forEach(vertex -> System.out.format("- (%s, %s)%n", vertex.getX(), vertex.getY()));
}
}
}
2.2. レスポンスの内容
BatchAnnotateImagesResponseの
getResponsesListでAnnotateImageResponseリストが取得できます。
検出されなった場合は、空のリストが返ってきます。
AnnotateImageResponse
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getLocalizedObjectAnnotationsList | List<LocalizedObjectAnnotation> | 検出されたラベル |
LocalizedObjectAnnotation
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getMid | string | OpaqueエンティティID |
| getName | string | 検出されたオブジェクトの名前 |
| getScore | float | 検出結果の信頼度。範囲は0〜1 |
| getBoundingPoly | BoundingPoly | オブジェクトが属する画像領域 |
BoundingPoly
正規化された頂点座標は元のイメージを基準としています。
座標を取得したい場合は、
X座標 = 画像の高さ x getX
Y座標 = 画像の幅() x getY()
で取得します。
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getNormalizedVerticesList | List<NormalizedVertex> | 正規化された頂点。 左上、右上、左下、右下の順 |
NormalizedVertex
| メソッド | 戻り値 | 内容 |
|---|---|---|
| getX | float | X座標 |
| getY | float | Y座標 |
3. 結果の検証
いろいろな画像でオブジェクトを検出してみました。
3.1. 駐車場
検出させる元画像

実行結果
大きめに写っている車のみ検出されていますね。
人もいるのですが検出されていません。小さすぎたのでしょうか。

3.2. ボーリング中
検出させる元画像

実行結果
屈んでいる女性がパンツと判定されている。

3.3. 人物
検出させる元画像

実行結果
持っているのは鏡だと思いますが、帽子と判定されていますね。

3.4. 街
検出させる元画像

実行結果
大きめに写っているビルが検出されています。

3.5. 野菜
検出させる元画像

実行結果
全部の野菜は認識されないようです。

3.6. 猫
検出させる元画像

実行結果
一匹だけ猫と判定されなかった子がいる。
動物と判定されているので間違いではないですが。

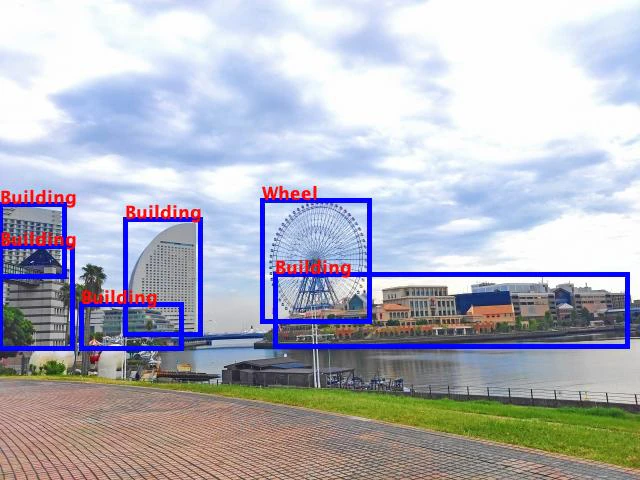
3.7. 風景
検出させる元画像

実行結果
遠くのビル群は、まとめてビルと判定されていますね。
3.8. デスク
検出させる元画像

実行結果
眼鏡(Glasses)の判定は正しいですが、サングラスには見えないですね。

おしまい。。。