ジョブカン事業部のアドベントカレンダー23日目です!![]()
はじめに
皆さん、楽したいですよね?
時間のかかる重たいタスクをLLMに任せて楽に仕事を進めたいですよね?
「楽」したいですよね???
そんな 楽をしたくてしたくて仕方ない皆さん のために、今回は「人が書くレベルのユニットテストをLLMに生成させるフローの確立」を目的に、色々試したので紹介します。
調査
手法の検討にあたり、LLMを用いてユニットテストを生成させる研究を行った論文を少し調べてきました。(詳しくは参考文献参照)
これら先行研究では以下のようなアプローチが見受けられました。
- LLMの入力となる自然言語の文章の工夫
- テスト対象のコードだけでなく、依存するメソッドの呼び出し順や、DB、モック対象など
- LLMの出力を指標に基づき評価
- 生成されたコードのビルド可否、実行可否、カバレッジが基準以上かなど
- LLMを複数回使用
- エラーが出たらそのログをLLMに食わせて修正させる、といったループ処理
そこで私も、これら3点のアプローチを網羅する形でLLMにユニットテストを作成させることにしました。
手法
前述のアプローチに基づき、以下のフローにてLLMを実行させるスクリプトを作成しました。
具体的な実装のポイントは以下の通りです。
1. 入力の工夫(AIエージェントの活用)
先行研究では、LLMに質の高いユニットテストを生成させるために、テスト対象のコードやそれに依存するコードなどをプロンプトに含めていました。
本記事ではCursorのAIエージェントを利用しました。
AIエージェントは、開発環境のコンテキストを自動で収集するため、開発者が手動で依存関係などの追加情報を準備する手間を削減できます。
それに皆さんは楽をしたいので、こんなところで苦労するわけにはいきません。
皆さんは楽をしたいので(念押し)
2. 出力の評価
ここは先行研究に倣って、以下の条件を満たすコードのみを採用します。
- コードが実行可能
- すべてのアサーションをクリアすること
- ラインカバレッジが80%以上
3. AIエージェントの複数回使用(自動修正ループ)
②で挙げた条件を満たさないコードは、再度AIエージェントを実行し、修正させます。
この時、エラーログあるいはラインカバレッジが足りないメソッドをプロンプトに含め、修正するよう指示を出します。
条件を満たすコードが出力されるまで(あるいは最大◯回)繰り返すことで、条件を満たすコードが得られる確度を高めます。
検証
今回は、バックオフィス支援クラウドERPサービス「ジョブカン」のアドベントカレンダー記事なので、ジョブカンのユニットテストを書いてもらうことにしました。
また、CursorのAIエージェントを使用するにあたり、モデルを選択する必要があるのですが、「ChatGPT5」を選びました。
理由は、スクリプト化して検証をおこなうため、CursorCLIを利用するのですが、CLIだと利用できるモデルに制限があり、その中で妥当そうなのがチャッピーくんだったからです。
結果
LLMに、処理が難解なメソッドをランダムに10個抽出してもらい、それらを対象にユニットテストを生成させてみました。
その際、内部で利用しているプライベートメソッドも網羅できるテストを作らせています。
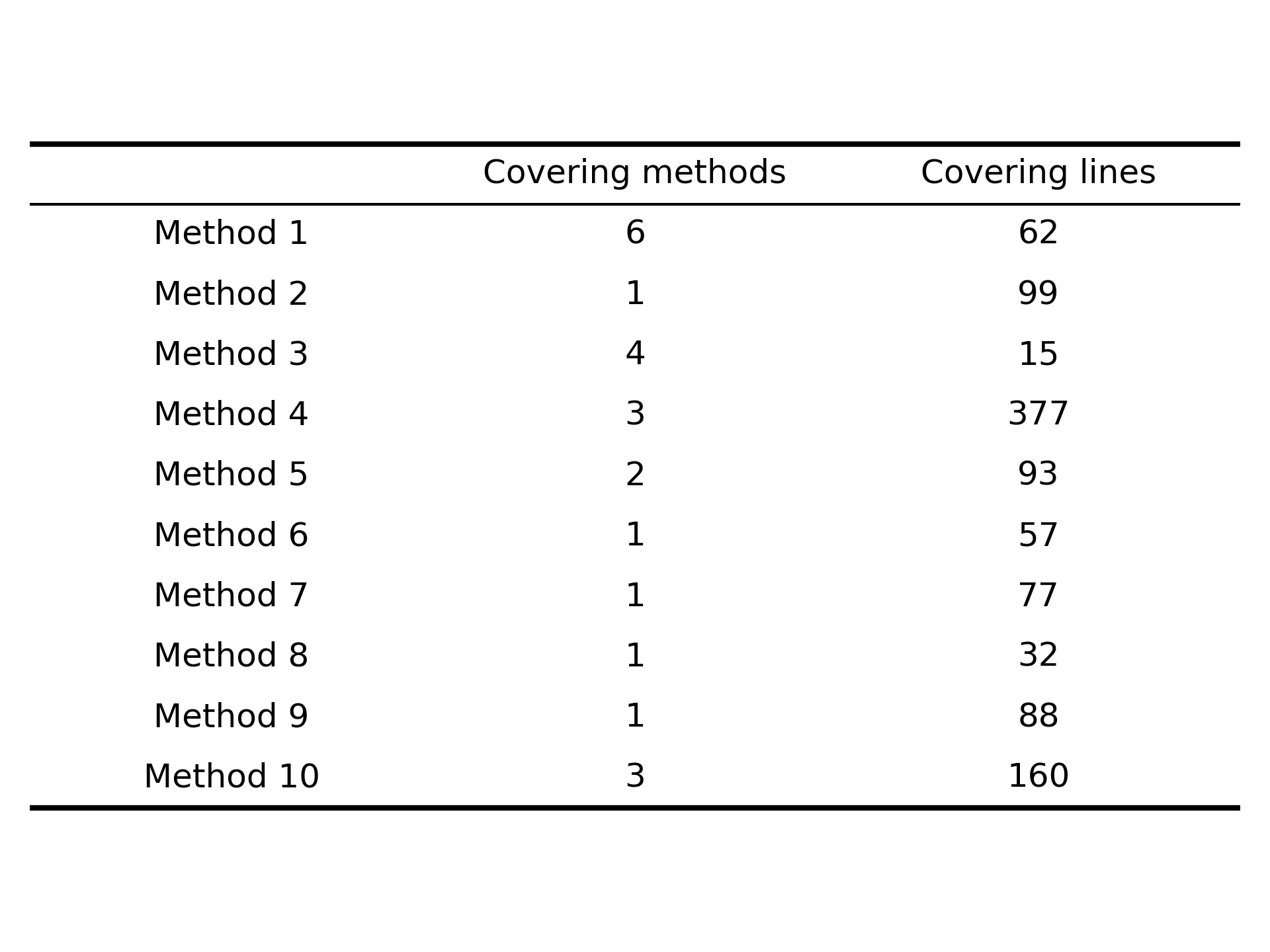
AIエージェント実行回数
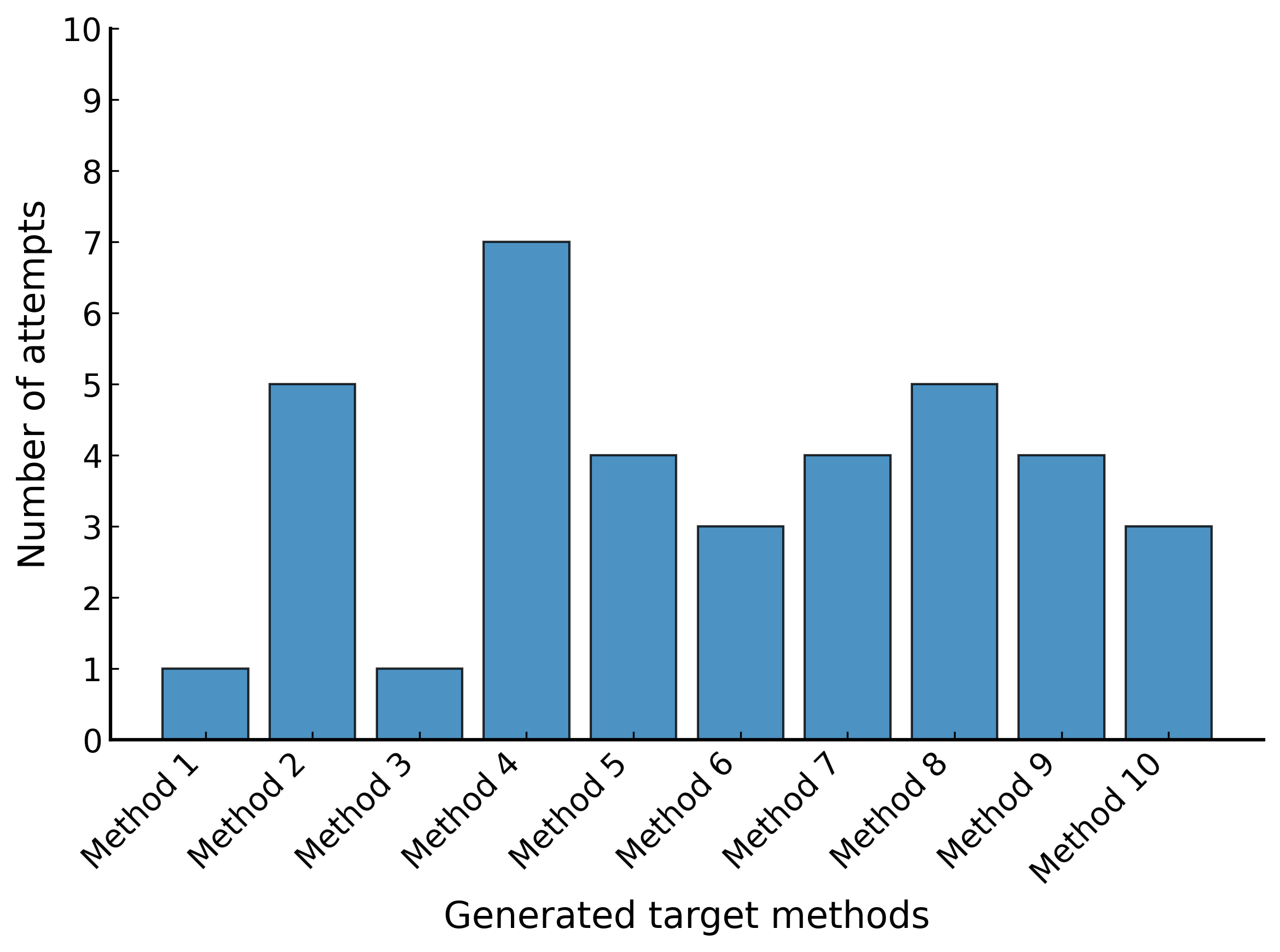
テストの作成時間
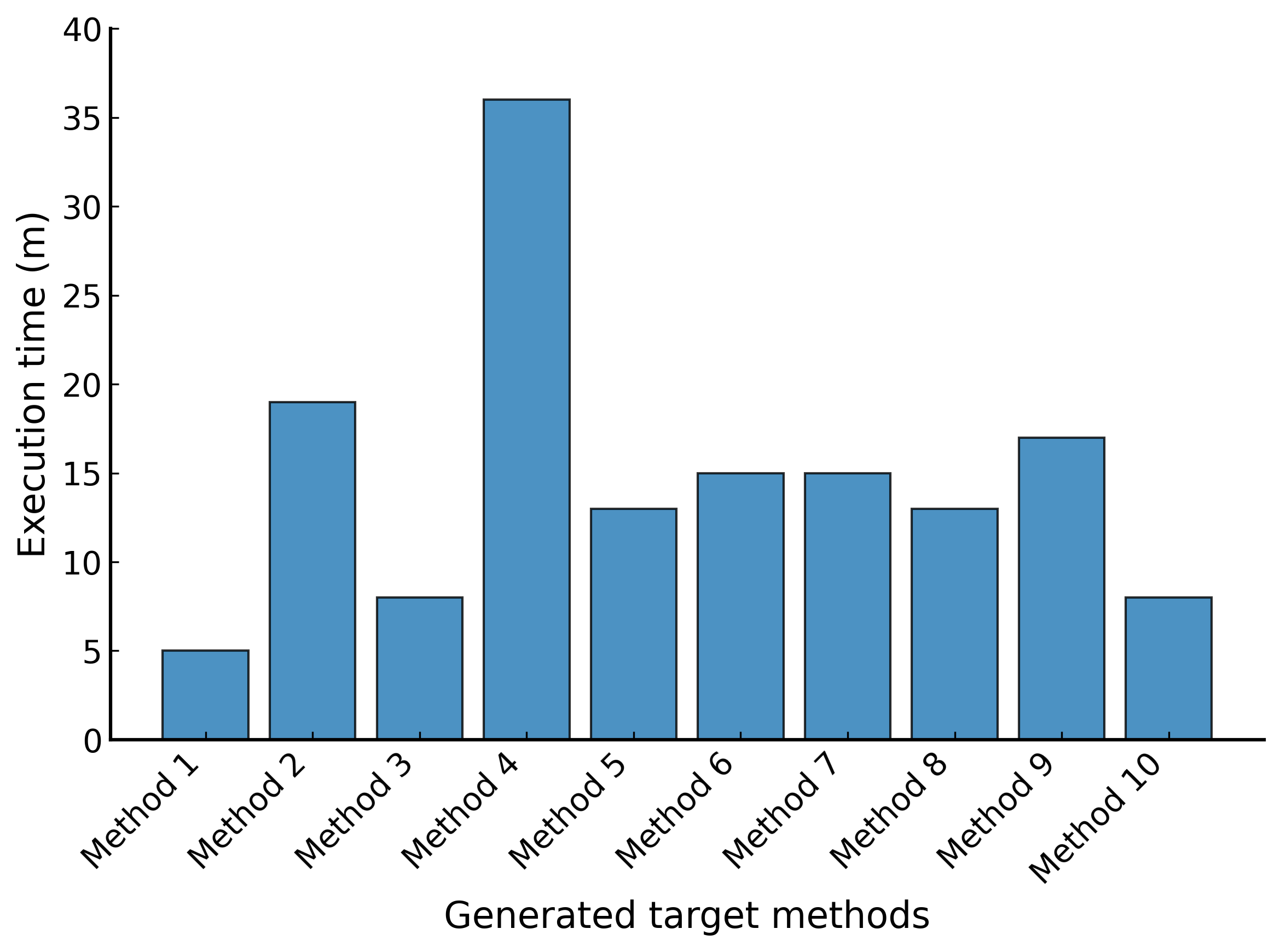
費用
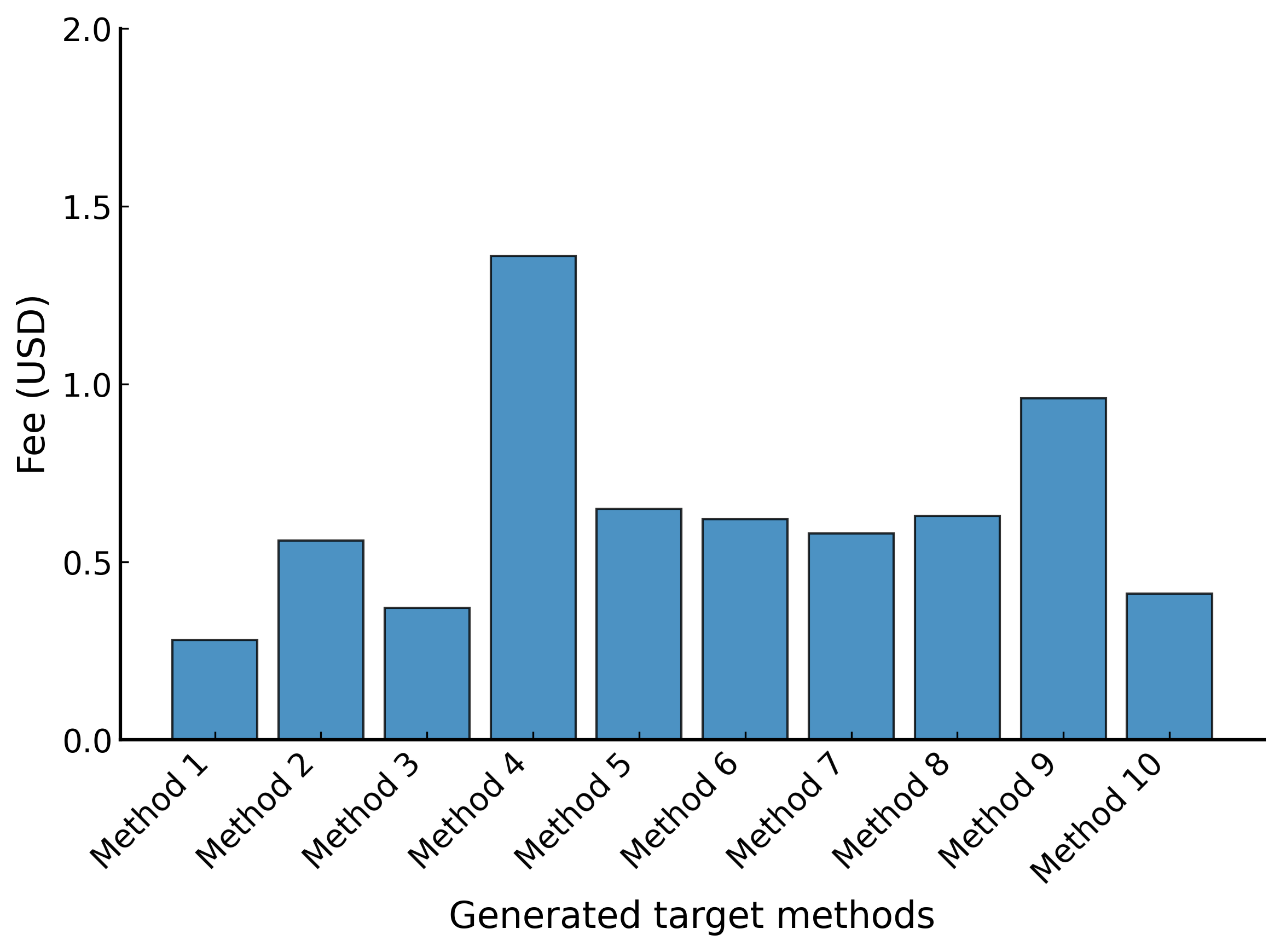
ラインカバレッジ
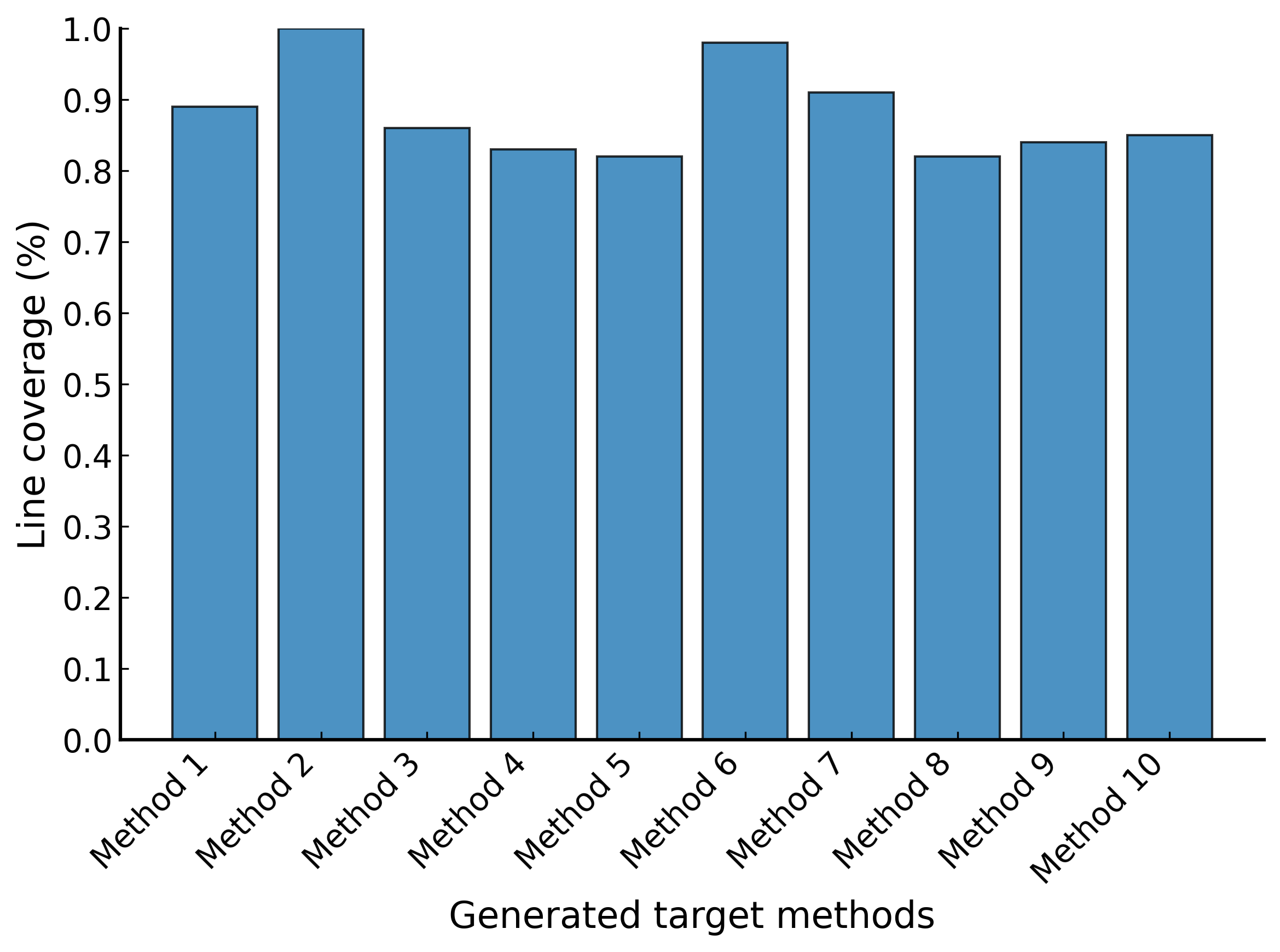
結論
結論、楽をするにはお金がかかる
(計 149分と5.77$ 必要でした)
さいごに
今回はユニットテストの合格条件を「実行可能」、「すべてのアサーションをクリアすること」、「ラインカバレッジ80%以上」とかなり緩い条件にしましたが、概ね実用的なテストコードが生成されていました。
ただ、所々で手直しが必要なテストもありました。
例えば、私の環境ではAIエージェントがDBの情報へアクセスできないため、DBが絡むテストはどうしても修正が必要でした。
(このあたりはMCPサーバーなどを活用すれば解決出来るんですかね?)
また、テストのロジックは悪くないものの、テストケースが不足しているものもいくつかありました。
これについては、指標を「ラインカバレッジ」ではなく「分岐カバレッジ」に変更したり、ルールを追加したりすることで改善できそうです。
まとめとして、今後の課題は以下の通りです。
- AIエージェントの情報参照範囲の拡大
- より厳格なルールの策定
同じような構成で試してみようと考えている方は、ぜひ参考にしてみてください。
さいごのさいごに
DONUTSでは、新卒中途を問わず積極的に採用活動を行っています!!
ジョブカン事業部も、一緒に働くエンジニアを募集しています!!
気になる方はお気軽に応募してみてください。
参考文献