はじめに
こんにちは。オークファン新卒1年目の @dongoh.lim です。
新卒の開発研修ではSpring Webfluxを利用してAPIを開発したり、Nuxtでフロントエンドを開発したりしました。
また、Spring Webfluxをもっと深く理解するためにその基盤となるReactorを勉強しました。
この記事では勉強した内容を自分なりに整理しました。
1. Project Reactorとは
- Project Reactor(以下Reactor)はReactive Streamsという仕様を実装したライブラリです。ここでReactive Streamsとはデータの流れをNon-Blockingに且つ非同期的に処理するにはどう実装すればいいかを定義したものです。Spring Frameworkを開発したチームはこのReactive StreamsをもとにReactorを実装したのです。
- ReactorはSpring Framework 5からSpring WebFluxの基盤技術として活用されています。
2. なぜReactor
- Reactive Streamsを実装したライブラリはReactorだけではありません。他にもRxJava, Akka Streamsなどがあります。では、私たちのチームではなぜReactorを選ぶ必要があったのでしょうか。
- 私たちのチームではバックエンドの開発をするとき基本Java, Kotlinを使っています。そのJava, KotlinでAPIを作成する時は皆さんがよく知っているSpringというフレームワークを利用することになります。このSpringがReactorを基盤とするWebFluxを提供しているのです。
- WebFluxを使うことで楽にコードを統合することができます。WebFluxはSpring Frameworkのデザインパターンに従っているので既存のSpring基盤のモジュールとの統合ができます。また、WebFluxは既存のSpring MVCとも互換するのでレガシーコードとの統合もできます。
3. Reactorの登場人物
- publisher: データを渡すものです。データを渡すのをデータをemitすると言います。また、データがemitされるところをupstream、そしてemitされたデータが入るところをdownstreamと言います。ReactorではMono, FluxというPublisherを提供しています。合わせて、そのMono、Fluxの初期データ(source dataと言います)をもっと効率的にemitしてくれるSinksというものもあります。
- operator: publisherとsubscriberの間でデータを加工する役割をするものです。様々なoperatorが存在していますが、この記事ではその一部であるBackpressureとSchedulerを指定するoperatorについて説明します。(コード例でそれ以外のものも少しは出てきます。)
- subscriber: データを最終的に受け取ってそのデータを処理するものです。publisherとoperatorとは全く別のスレッドで独自の処理をします(非同期処理のためにはそう実装すべきです)。外部のスレッドで加工まで済んだデータをsubscriber自身のスレッド内で後処理のようなものをすると思ってください。
4. publisherの種類
(1) Mono
-
Monoはデータを1個もしくは0個をemitします。
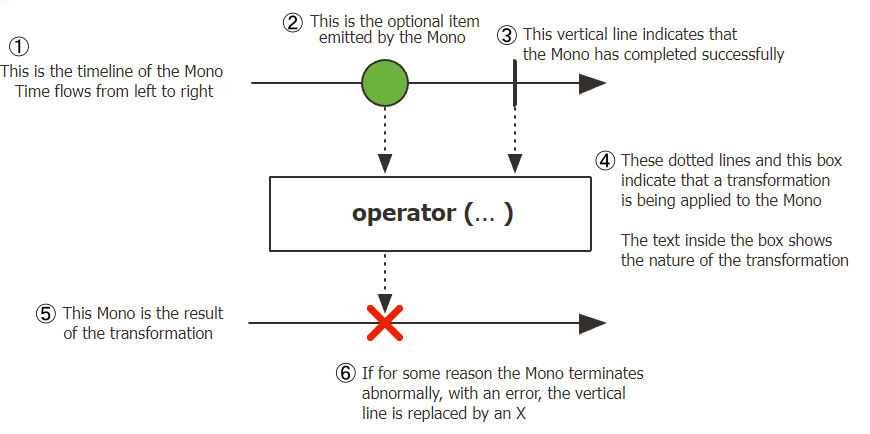
参考:https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Mono.html
- 上の図のようなものをMarble Diagramと言います。データの流れを表したものです。まず、上の矢印はupstreamのスレッドを意味します。また、中間にあるボックスはOperatorを意味します。下の矢印はdownstreamのスレッドを意味します。矢印の上にはデータがビー玉のような形で表示されています。ビー玉の中には番号が記入されている場合がありますが、それはデータの内容そのものであって、データが処理される順番ではないことに注意してください。また、矢印の上の垂直線はemitが完了したのを意味してバツの表示はupstreamがデータをemitする過程で問題が発生してそれをdownstreamで検知したことを意味します。
- では、上の図に戻って
Monoについて説明します。upstreamはデータを一個emitしていて(emitしなくてもいいです。)そのデータはoperatorで加工されdownstreamに伝達されるのですが、そのdownstreamはemitする過程でエラーが発生したことを検知してその後処理をしていることがわかります。
Mono.just("This is Data")
.subscribe(
data -> System.out.prinln("got onNext signal with:" + data),
error -> System.out.println(error),
() -> System.out.println("got onComplete signal")
);
-
Monoを使う例を紹介します。just()のoperatorは一個以上のデータをemitできるものです。ここでは文字列を一個emitしています。そしてそのデータはsubscribe()の中に登録されているsubscriberに届きます。subscriberはそのデータを出力する後処理をしています。もし、emitする過程でエラーが発生したら、そのエラーをExceptionの形で受け取る(バツ)ことになります。また、emitが完了したことを検知したとき(垂直線)どの処理をするかも指定できます。 -
subscribe()の中にいくつかのlambdaでsubscriberを定義しています。その一個目の引数がsubscriber内での処理を担当するlambdaで、二個目の引数がupstreamのemitする過程でエラーが発生したことを検知したときの処理を担当するlambdaで、三個目の引数がupstreamのemitが完了したことを検知したときの処理を担当するlambdaです。このlambdaたちは内部的にCoreSubscriberに統合・変換されるので、根本的にはCoreSubscriberの中に定義されているonSubscribe(),onNext(),onError(),onComplete()を利用する事になります。onSubscribe()はサブスクライブするときどの処理をするか、onNext()はemitされたデータを受け取ってどう処理するか、onError()はupstreamでデータをemitするときエラーが発生したらどう処理するか、onComplete()はupstreamがデータを全部emitしたらどの処理をするかを指定するものです。ちなみに、onSubscribe(),onNext(),onError(),onComplete()はReactive Streamsで仕様として存在するinterfaceです。ReactorがReactive Streamsに従っていることがわかりますね。 - 上のコードでsubscribeの引数であるsubscriberはpublisherと同じスレッドでデータの後処理をしています。このようにReactorでは下で説明する
publishOn()のoperatorなどでsubscriberのためのスレッドを作ってあげないと基本upstreamと同じスレッドを使います。上記のとおりこのコードのままだと非同期処理はされないでしょう。 - ちなみに上のようなメソッドチェーンをReactorではsequenceと言います。
(2) Flux
-
Fluxはデータを0個以上emitします。
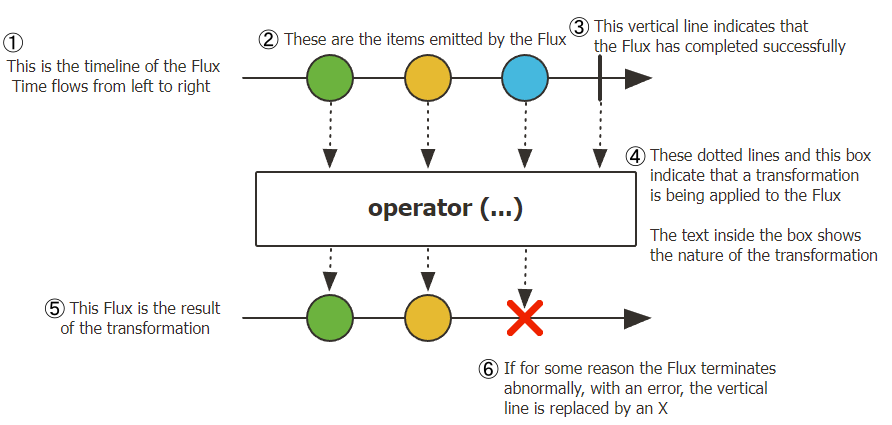
参考:https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Flux.html
-
Monoとは違ってupstreamにデータが複数emitされていることがわかります。そのデータはoperatorを経てdownstreamまで行きます。
Flux.fromArray(new Integer[]{1,2,3})
.filter(num -> num > 2)
.map(num -> num * 2)
.subscribe(System.out::println);
- 上のコードは
Fluxを使った例です。fromArray()のoperatorは配列を引数にもらって中の要素を一個一個のデータとして分節してemitします。filter()のoperatorは条件に合うデータだけ通過させます。map()のoperatorはupstreamからの各々のデータに対して指定した処理を施します。そしてsubscriberはそのデータを受けて出力する後処理をしています。 -
fromArray()ではなく、just()だったらどうでしょうか。その場合はFluxではなくMonoを使うべきでしょう。リストや配列は中に複数の要素を含んでいますが、リストや配列自体は一個だからです。
(3) Sinks
-
SinksはReactor3.4.0から登場した新しい概念です。Mono,Fluxのsequenceを作成する前にsource dataを複数のスレッドでemitできるようにしてくれます。既存のjust()とかfromArray()とかはupstreamのスレッド一個の中でデータをemitしていましたが、Sinksでは複数のスレッドでデータをemitすることができるということです。心配なのはスレッド安全であるかですが、Sinksはresourceに同時アクセスしていることを検知すると速やかに片方のスレッドをfailさせて(fail fastと言います)スレッド安全を保っています。 -
Sinksにはデータを一個emitするのをサポートするSinks.Oneとデータを複数emitするのをサポートするSinks.Manyがあります。Sinks.Manyにはまた一個のsubscriberをサポートするUnicastSpec、複数のsubscriberをサポートするMulticastSpec、同じく複数のsubscriberをサポートするが既にemitされたデータも遡ってemitしてくれるMulticastReplaySpecがあります。 -
Sinks.One- 一個のデータをemitするのをサポートする方法を定義したspecです。
Sinks.one()メソッドはspec interfaceをリターンしてくれます。 - そのspecの
emitValue()のメソッドを利用してemitするデータを指定することができます。引数は2個で二つ目の引数はemitする過程でエラーが発生したときどう処理するかを指定するものです。スレッド安全のためFAIL_FASTを入れましょう。 - そして、
Mono,Fluxがemitするデータを受けとるためにSinks.OneのasMono()やasFlux()のメソッドを利用してMono,Fluxのインスタンスに変換します。 - この後は、従来の通りsequenceを利用すればいいのです。
- ちなみに下記のコメントを解除すると1個目のデータはemitされますが、2個目のデータはdropされます。
- 一個のデータをemitするのをサポートする方法を定義したspecです。
Sinks.One<String> sinksOne = Sinks.one();
Mono<String> mono = sinksOne.asMono();
sinkOne.emitValue("Data 1", FAIL_FAST);
// sinkOne.emitValue("Data 2", FAIL_FAST);
mono.subscribe(data -> log.info("# Subscriber1 {}", data));
mono.subscribe(data -> log.info("# Subscriber2 {}", data));
// コメント解除前
// [main] INFO - # Subscriber1 Data 1
// [main] INFO - # Subscriber2 Data 1
// コメント解除後
// [main] DEBUG- onNextDropped: Data 2
// [main] INFO - # Subscriber1 Data 1
// [main] INFO - # Subscriber2 Data 1
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter9/Example9_4.java
-
Sinks.Many- 複数のデータをemitするのをサポートする方法を定義したspecです。まず
Sinks.many()メソッドがManySpecというspec interfaceをリターンしてくれます。 - 上記のとおりsubscriberを何個サポートするかを指定できますが、
unicast(),multicast(),replay()メソッドがそれを担当するUnicastSpec,MulticastSpec,MulticastReplaySpecをリターンしてくれます。 - そのspec interfaceに定義されている
onBackpressureBuffer()のメソッドはSinks.Manyをリターンしてくれます。replay()がリターンするMulticastReplaySpecに対してはreplay().limit()メソッドがSinks.Manyをリターンしてくれます。詳しくはコードで説明します。 -
Sinks.ManyのemitNext()メソッドを利用してemitするデータを指定することができます。Sink.Oneとは違ってメソッド名がemitNextです。引数の指定はSink.OneのemitValue()と同じです。 -
Mono,Fluxのインスタンスに変換します。そしてsequenceを作成します。 -
UnicastSpecのコードの説明- 結果ではsubscriberが登録される前のデータである1, 2が出力されます。これは
onBackpressureBuffer()メソッドの特性で、最初subscribeされるまでのemitされたデータを保管してくれます。(warm upの特性を持っていると言います。) - コメントを外すと二つのsubscriberがsubscribeすることになって
IllegalStateExceptionのエラーが発生します。
- 結果ではsubscriberが登録される前のデータである1, 2が出力されます。これは
-
MulticastSpecのコードの説明- 結果ではsubscriber1が1, 2, 3を、subscriber2が3を受けてsubscriber3は何も受けていません。subscriber2が1, 2を受けていないですが、これはsubscriber1が既に保管されていた1, 2を持っていったからです。warm upで保管されたデータは最初のsubscriberに全部渡されるのです。また、subscriber3が3を受けていない理由はemitされた後subscribeしているからです。このように自分がsubscribeした後のデータしか受け取れないupstreamをhot publisher、そのhot publisherからスタートするsequenceをhot sequenceと言います。
Sinksはhot publisherとして作動します。
- 結果ではsubscriber1が1, 2, 3を、subscriber2が3を受けてsubscriber3は何も受けていません。subscriber2が1, 2を受けていないですが、これはsubscriber1が既に保管されていた1, 2を持っていったからです。warm upで保管されたデータは最初のsubscriberに全部渡されるのです。また、subscriber3が3を受けていない理由はemitされた後subscribeしているからです。このように自分がsubscribeした後のデータしか受け取れないupstreamをhot publisher、そのhot publisherからスタートするsequenceをhot sequenceと言います。
-
MulticastReplaySpecのコードの説明- 結果ではsubscriber1が2, 3, 4を、subscriber2が3, 4を受けています。subscribeする時点を基準に
limit()で設定した数分前にemitされたデータを受け取っているのです。(onBackpressureBuffer()がないのでwarm upはないです。) - もし、
limit()ではなくall()を利用すると最初にemitされたデータから受け取るようになります。
- 結果ではsubscriber1が2, 3, 4を、subscriber2が3, 4を受けています。subscribeする時点を基準に
- 複数のデータをemitするのをサポートする方法を定義したspecです。まず
// UnicastSpec //
Sinks.Many<Integer> sinksManyUnicast = Sinks.many().unicast().onBackpressureBuffer();
Flux<Integer> flux = sinksManyUnicast.asFlux();
sinksManyUnicast.emitNext(1, FAIL_FAST);
sinksManyUnicast.emitNext(2, FAIL_FAST);
sinksManyUnicast.emitNext(3, FAIL_FAST);
flux.subscribe(data -> log.info("# Subscriber1: {}", data));
// flux.subscribe(data -> log.info("# Subscriber2: {}", data));
// コメント解除前
// [main] INFO - # Subscriber1: 1
// [main] INFO - # Subscriber1: 2
// [main] INFO - # Subscriber1: 3
// コメント解除後
// Caused by: java.lang.IllegalStateException: UnicastProcessor allows only a single Subscriber
// ----------- //
// MulticastSpec
Sinks.Many<Integer> sinksManyMulticast = Sinks.many().multicast().onBackpressureBuffer();
Flux<Integer> flux = sinksManyMulticast.asFlux();
sinksManyMulticast.emitNext(1, FAIL_FAST);
sinksManyMulticast.emitNext(2, FAIL_FAST);
sinksManyMulticast.emitNext(3, FAIL_FAST);
flux.subscribe(data -> log.info("# Subscriber1: {}", data));
flux.subscribe(data -> log.info("# Subscriber2: {}", data));
flux.subscribe(data -> log.info("# Subscriber3: {}", data));
// [main] INFO - # Subscriber1: 1
// [main] INFO - # Subscriber1: 2
// [main] INFO - # Subscriber1: 3
// [main] INFO - # Subscriber2: 3
// ----------- //
// MulticastReplaySpec
Sinks.Many<Integer> sinksManyMulticastReplay = Sinks.many().replay().limit(2);
Flux<Integer> flux = sinksManyMulticastReplay.asFlux();
sinksManyMulticastReplay.emitNext(1, FAIL_FAST);
sinksManyMulticastReplay.emitNext(2, FAIL_FAST);
sinksManyMulticastReplay.emitNext(3, FAIL_FAST);
flux.subscribe(data -> log.info("# Subscriber1: {}", data));
sinksManyMulticastReplay.emitNext(4, FAIL_FAST);
flux.subscribe(data -> log.info("# Subscriber2: {}", data));
// [main] INFO - # Subscriber1: 2
// [main] INFO - # Subscriber1: 3
// [main] INFO - # Subscriber1: 4
// [main] INFO - # Subscriber2: 3
// [main] INFO - # Subscriber2: 4
// ----------- //
参考:
https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter9/Example9_8.java
https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter9/Example9_9.java
https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter9/Example9_10.java
- ここまでが、
Sinks.Manyの説明でした。忘れてはならないことはemitNext()でデータをemitする部分はすべて別々のスレッドで行われていることです。データをemitする複数のスレッドたちが集まってsequenceのスレッド一つになるイメージです。複数のスレッドが一つにまとまるのがまるで流し台で水が合流するのと似ているからSinksにしたのかと勝手に思っていたりします。
5. Backpressure
- 上でsubscriberがemitされたデータを処理するのはpublisherとoperatorのスレッドとは全く別のスレッドで行われていると述べました。では、publisherがemitする速度がsubscriberがそれを処理する速度より速い場合はどうなるのでしょうか。処理されていないデータがどんどん溜まってoverflowが発生したりシステムが落ちたりすることになります。この負荷を適切に分けるのがBackpressureです。
(1) Backpressureの方法1:upstreamに要請するデータ数を決める
- subscriberが自分が一気に処理できるデータの量だけpublisherに要請することを言います。
Flux.range(1, 5)
.doOnRequest(data -> log.info("# doOnRequest: {}", data))
.subscribe(new BaseSubscriber<Integer>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
request(1);
}
@SneakyThrows
@Override
protected void hookOnNext(Integer value) {
Thread.sleep(2000L);
log.info("# hookOnNext: {}", value);
request(1);
}
});
// [main] INFO - # doOnRequest: 1
// [main] INFO - # hookOnNext: 1
// [main] INFO - # doOnRequest: 1
// [main] INFO - # hookOnNext: 2
// [main] INFO - # doOnRequest: 1
// [main] INFO - # hookOnNext: 3
// [main] INFO - # doOnRequest: 1
// [main] INFO - # hookOnNext: 4
// [main] INFO - # doOnRequest: 1
// [main] INFO - # hookOnNext: 5
// [main] INFO - # doOnRequest: 1
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter8/Example8_1.java
-
range()のoperatorは連続して増加する整数をデータとしてemitします。1から始まり、全体のデータの数が5になるようにemitします。また、doOnRequest()のoperatorを利用するとpublisherが要請を受けたとき実行するものを指定できます。 -
subscribe()にはsubscriberを引数として渡していたので、BaseSubscriberをOverride付きで入れておきます。Overrideを利用することで要請するデータの数とデータを受け取った際の処理内容をカスタマイズすることができます。 - 結果では、requestしたdataの数はずっと1で、
hookOnNext()は1, 2, 3, 4, 5を順に出力するようになります。
(2) Backpressureの方法2:IGNORE戦略を利用する
- Backpressureを適用しないことです。つまり、subscriberの処理速度がupstreamのemit速度に追いつけなくても
IllegalStateExceptionが発生するまま置いておくことです。
(3) Backpressureの方法3:ERROR戦略を利用する
- subscriberがデータのemit速度を追いつかない場合、
IllegalStateExceptionエラーを出します。
Flux.interval(Duration.ofMillis(1L))
.onBackpressureError()
.doOnNext(data -> log.info("# doOnNext: {}", data))
.publishOn(Schedulers.parallel())
.subscribe(data -> {
try {
Thread.sleep(5L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("# onNext: {}", data);
},
error -> log.error("# onError", error));
Thread.sleep(3000L);
// [parallel-2] INFO - # doOnNext: 0
// [parallel-2] INFO - # doOnNext: 1
// ...
// [parallel-2] INFO - # doOnNext: 8
// [parallel-1] INFO - # onNext: 0
// [parallel-2] INFO - # doOnNext: 9
// ...
// [parallel-2] INFO - # doOnNext: 255
// [parallel-1] INFO - # onNext: 41
// [parallel-1] INFO - # onNext: 42
// ...
// [parallel-1] INFO - # onNext: 255
// [parallel-1] ERROR- # onError
// reactor.core.Exceptions$OverflowException: The receiver is overrun by more signals than expected (bounded queue...)
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter8/Example8_2.java
-
interval()のoperatorは指定した時間置きに0から1ずつ増加する整数をemitします。ここでは0.001秒置きにデータをemitしています。doOnNext()のoperatorはupstreamからemitされたデータを利用するようにしてくれます。publishOn()のoperatorはdownstreamのスレッドを指定することができるようにしてくれます。詳しくはSchedulerで説明します。ここではsubscriberのスレッドを分離させるために利用しました。 - 私の環境で実行してみると、255までemitされてsubscriberは255まで処理します。しかし、その後
IllegalStateExceptionを継承したOverflowExceptionのエラーが出ます。ちなみに、ここでの数字はデータの順番ではなくデータそのものです。以下の実行結果の数字も同じくデータそのものです。
(4) Backpressureの方法4:DROP戦略を利用する
- bufferという筒(queueと言います)を用意してそれをpublisherとsubscriberの間において、subscriberの方の口を出口、publisherの方の口を入口ということにします。emitされたデータはどんどんbufferの出口から入口まで積もっていき、subscriberは出口がらデータを一個一個取って処理を行います。データがbufferに入らないくらいbufferがいっぱいになったら入口は閉じます。その後emitされたデータは入口が開いてないことを見て自分自身を入口の手前でDROPさせます。
- 一旦データがbufferの後ろまで全部積もるとbuffer内の全てのデータが処理されるまで入口は開かない事に注意してください。
Flux.interval(Duration.ofMillis(1L))
.onBackPressureDrop(dropped -> log.info("dropped: {}", dropped))
.publishOn(Schedulers.parallel())
.subscribe(data -> {
try {
Thread.sleep(5L);
} catch(InterrupedException e) {
throw new RuntimeException(e);
}
log.info("# onNext: {}", data);
},
error -> log.error("# onError", error));
Thread.sleep(3000L)
// [parallel-1] INFO - # onNext: 0
// [parallel-1] INFO - # onNext: 1
// ...
// [parallel-1] INFO - # onNext: 40
// [parallel-2] INFO - # dropped: 256
// [parallel-1] INFO - # onNext: 41
// [parallel-2] INFO - # dropped: 257
// ...
// [parallel-2] INFO - # dropped: 1184
// [parallel-1] INFO - # onNext: 191
// ...
// [parallel-1] INFO - # onNext: 222
// [parallel-2] INFO - # dropped: 1378
// ...
// [parallel-2] INFO - # dropped: 1578
// [parallel-1] INFO - # onNext: 255
// [parallel-2] INFO - # dropped: 1579
// ...
// [parallel-2] INFO - # dropped: 1584
// [parallel-1] INFO - # onNext: 1185
// [parallel-2] INFO - # dropped: 1585
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter8/Example8_3.java
- 私の環境で実行してみると、256~1184のデータがDROPされます。そして1185からまた
onNext()が出力を始めることがわかります。
(5) Backpressureの方法5:LATEST戦略を利用する
- bufferにemitされたデータが積もっていってbufferがいっぱいになると入口が閉じること、そしてbuffer内のデータが全部処理されるまで入口が開かないのはDROPと一緒です。しかし、新しくemitされたデータが入口の手前で入口が開くまで待っているデータを削除させて自分をその入口の手前に立たせる点が違います。
- 入口が開くまでemitされた順に削除され、bufferが空いた瞬間新しくemitされたデータが入口の手前で待機していたデータを削除させてbufferに入ります。
Flux.interval(Duration.ofMillis(1L))
.onBackpressureLatest()
.publishOn(Schedulers.parallel())
.subscribe(data -> {
try {
Thread.sleep(5L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("# onNext: {}", data);
},
error -> log.error("# onError", error));
Thread.sleep(3000L);
// [parallel-1] INFO - # onNext: 0
// [parallel-1] INFO - # onNext: 1
// ...
// [parallel-1] INFO - # onNext: 255
// [parallel-1] INFO - # onNext: 1197
// ...
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter8/Example8_4.java
- 私の環境で実行してみると、256~1196のデータが削除されています。そして1197からまた
onNext()が出力を始めることがわかります。
(6) Backpressureの方法6:BUFFER-DROP_LATEST戦略を利用する
- 上のBackpressureの戦略ではbuffer内の全てのデータをsubscriberが処理するまで入口は開かなかったのでした。しかし、BUFFER-DROP_LATESTとBUFFER-DROP_OLDESTではデータが絶えずにbufferに入ってきます。入口が開きっぱなしになっているわけですね。
- bufferがいっぱいになると一旦bufferにもう一個のデータが入ってきます。その瞬間、bufferにoverflowが発生する事になってそのoverflowを起こしたデータがDROPされます。
Flux.interval(Duration.ofMillis(300L))
.doOnNext(data -> log.info("# emitted by original Flux: {}", data))
.onBackpressureBuffer(2,
dropped -> log.info("** Overflow & Dropped: {} **", dropped),
BufferOverflowStrategy.DROP_LATEST)
.doOnNext(data -> log.info("[ # emitted by Buffer: {} ]", data))
.publishOn(Schedulers.parallel(), false, 1)
.subscribe(data -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("# onNext: {}", data);
},
error -> log.error("# onError", error));
Thread.sleep(3000L);
// [parallel-2] INFO - # emitted by original Flux: 0
// [parallel-2] INFO - [ # emitted by Buffer: 0 ]
// [parallel-2] INFO - # emitted by original Flux: 1
// [parallel-2] INFO - # emitted by original Flux: 2
// [parallel-2] INFO - # emitted by original Flux: 3
// [parallel-2] INFO - ** Overflow & Dropped: 3 **
// [parallel-1] INFO - # onNext: 0
// [parallel-1] INFO - [ # emitted by Buffer: 1 ]
// [parallel-2] INFO - # emitted by original Flux: 4
// [parallel-2] INFO - # emitted by original Flux: 5
// [parallel-2] INFO - ** Overflow & Dropped: 5 **
// [parallel-2] INFO - # emitted by original Flux: 6
// [parallel-2] INFO - ** Overflow & Dropped: 6 **
// [parallel-1] INFO - # onNext: 1
// [parallel-1] INFO - [ # emitted by Buffer: 2 ]
// [parallel-2] INFO - # emitted by original Flux: 7
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter8/Example8_5.java
-
onBackpressureBuffer()のoperatorでBuffer戦略を適用することができます。一番目の引数はbufferのsizeを三番目の引数はDROP_LATESTを設定しています。 - 私の環境で実行してみると、[0emit] -> [0がbufferからout] -> [1emit] -> [2emit] -> [3emit] -> [3drop] -> [0処理] -> [1がbufferからout] -> [4emit] -> [5emit] -> [5drop] -> ...の順に出力されます。
(7) Backpressureの方法7:BUFFER-DROP_OLDEST戦略を利用する
- DROP_OLDESTはbufferがいっぱいになっている状態で新しいデータが入口の方から入ってoverflowを発生させると、bufferの出口にあるデータ(つまり、bufferの一番目のデータ)がDROPされます。一番目のデータにとっては悔しい結果になりますね。
Flux.interval(Duration.ofMillis(300L))
.doOnNext(data -> log.info("# emitted by original Flux: {}", data))
.onBackpressureBuffer(2,
dropped -> log.info("** Overflow & Dropped: {} **", dropped),
BufferOverflowStrategy.DROP_OLDEST)
.doOnNext(data -> log.info("[ # emitted by Buffer: {} ]", data))
.publishOn(Schedulers.parallel(), false, 1)
.subscribe(data -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("# onNext: {}", data);
},
error -> log.error("# onError", error));
Thread.sleep(3000L);
// [parallel-2] INFO - # emitted by original Flux: 0
// [parallel-2] INFO - [ # emitted by Buffer: 0 ]
// [parallel-2] INFO - # emitted by original Flux: 1
// [parallel-2] INFO - # emitted by original Flux: 2
// [parallel-2] INFO - # emitted by original Flux: 3
// [parallel-2] INFO - ** Overflow & Dropped: 1 **
// [parallel-1] INFO - # onNext: 0
// [parallel-1] INFO - [ # emitted by Buffer: 2 ]
// [parallel-2] INFO - # emitted by original Flux: 4
// [parallel-2] INFO - # emitted by original Flux: 5
// [parallel-2] INFO - ** Overflow & Dropped: 3 **
// [parallel-2] INFO - # emitted by original Flux: 6
// [parallel-2] INFO - ** Overflow & Dropped: 4 **
// [parallel-1] INFO - # onNext: 2
// [parallel-1] INFO - [ # emitted by Buffer: 5 ]
// [parallel-2] INFO - # emitted by original Flux: 7
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter8/Example8_6.java
- 私の環境で実行してみると、[0emit] -> [0がbufferからout] -> [1emit] -> [2emit] -> [3emit] -> [1drop] -> [0処理] -> [2がbufferからout] -> [4emit] -> [5emit] -> [3drop] -> ...の順に出力されます。
6. Scheduler
- Schedulerはsequence内のデータの処理をどのスレッドで担当させるか決めてくれます。上記で説明したとおり、特別に指定しない限りdownstreamは基本的にupstreamのスレッド上で処理をします。Schedulerはupstreamとは別のスレッドを使うようにしてくれるのです。
- 具体的にはsequence内で「いつ」そして「どのScheduler」を利用するかをoperatorで指定できます。
(1) いつ-subscribeOn()
- subscribeが発生したとき新しいスレッドを作ります。subscriberが複数あってsubscribeするとsubscribeした数分のスレッドが作成されます。
- subscribeが発生したとき作ってくれるのでsource publisher(データを最初に生成してemitするpublisher)も新しく作ったスレッド上で処理をします。
- sequenceのどこでも一回使えます。
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.subscribeOn(Schedulers.boundedElastic())
.doOnNext(data -> log.info("# doOnNext: {}", data))
.doOnSubscribe(subscription -> log.info("# doOnSubscribe"))
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(500L);
// [main] INFO - # doOnSubscribe
// [boundedElastic-1] INFO - # doOnNext: 1
// [boundedElastic-1] INFO - # onNext: 1
// [boundedElastic-1] INFO - # doOnNext: 3
// [boundedElastic-1] INFO - # onNext: 3
// [boundedElastic-1] INFO - # doOnNext: 5
// [boundedElastic-1] INFO - # onNext: 5
// [boundedElastic-1] INFO - # doOnNext: 7
// [boundedElastic-1] INFO - # onNext: 7
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter10/Example10_1.java
-
doOnSubscribe()のoperatorはsubscribeが発生したときの処理を指定できるようにしてくれます。subscribeOn()と名前が似てますが別のものですので注意してほしいです。 - 結果では、
doOnSubscribe()だけmainスレッドで他は全てboundedElastic-1というスレッドで出力しています。もし、もう一個の新しいsubscribeが発生するとboundedElastic-2というスレッドが作られてそこで新しいsequenceのupstreamが始まる事になるでしょう。
(2) いつ-publishOn()
-
publishOn()のdownstreamがデータを処理するスレッドを新しいスレッドにします。 - sequence内でどこでも何個でも使えます。
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.doOnNext(data -> log.info("# doOnNext: {}", data))
.doOnSubscribe(subscription -> log.info("# doOnSubscribe"))
.publishOn(Schedulers.parallel())
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(500L);
// [main] INFO - # doOnSubscribe
// [main] INFO - # doOnNext: 1
// [main] INFO - # doOnNext: 3
// [parallel-1] INFO - # onNext: 1
// [main] INFO - # doOnNext: 5
// [main] INFO - # doOnNext: 7
// [parallel-1] INFO - # onNext: 3
// [parallel-1] INFO - # onNext: 5
// [parallel-1] INFO - # onNext: 7
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter10/Example10_2.java
-
publishOn()がdownstreamであるsubscribeがデータを処理するスレッドを新しいスレッドにしています。 - 結果では、
doOnSubscribe()とdoOnNext()がmainスレッドでsubscriberのonNext()がparallel-1のスレッドで出力するようになります。
(3) いつ-parallel().runOn()
-
parallel().runOn()のdownstreamがデータを処理するスレッドを物理スレッドにします。物理スレッドを複数に設定した場合、その数分のスレッドが作成され各々の物理スレッドにデータが一個一個分散処理されます。前述のとおり、Reactorでは基本的にdownstreamがupstreamのスレッドをそのまま利用します。つまり、upstreamが物理スレッド上でデータを一個処理した後に、そのdownstreamはupstreamの物理スレッドをそのまま利用して自分の処理をする事になります。 - 今までのmainスレッドや
subscribeOn()が作るスレッド、publishOn()が作るスレッドは全て論理スレッドでした。物理スレッドと論理スレッドの重要な違いは本当に同時にデータを処理するのかどうかです。物理スレッドは本当の意味で同時にデータを処理してくれます。(これをparallelismと言います)しかし、論理スレッドはこの物理スレッドを交互に使って処理をしていますので本当の意味で同時にデータを処理するのではありません。ただ、その速度が速くて同時に処理するように見えるだけです。(これをconcurrencyと言います)
Flux.fromArray(new Integer[]{1, 3, 5, 7, 9, 11, 13, 15, 17, 19})
.parallel(4)
.runOn(Schedulers.parallel())
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(100L);
// [parallel-4] INFO - # onNext: 7
// [parallel-3] INFO - # onNext: 5
// [parallel-1] INFO - # onNext: 1
// [parallel-2] INFO - # onNext: 3
// [parallel-4] INFO - # onNext: 15
// [parallel-3] INFO - # onNext: 13
// [parallel-1] INFO - # onNext: 9
// [parallel-2] INFO - # onNext: 11
// [parallel-1] INFO - # onNext: 17
// [parallel-2] INFO - # onNext: 19
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter10/Example10_4.java
-
parallel()は引数を指定しないと全ての物理スレッドを利用します。このコードでは四つにしています。また、parallel()は自分のupstreamからemitされたデータを複数の物理スレッドに分けることを担当しているのでdownstreamを物理スレッドにするためにはrunOn()でSchedulerを指定する必要があります。 - 結果では、parallel-1, parallel-2, parallel-3, parallel-4の四つの物理スレッドでsubscriberの
onNext()が本当の意味で同時に出力することがわかります。
(4) どのScheduler-Schedulers.immediate()
- スレッドを新しく作るのではなくupstreamのスレッドをそのまま利用するとき使えます。
- 前述のとおり、基本的にupstreamのスレッドを利用するのでこれはいらないのではないかと思うかもしれません。しかし、Schedulerを引数として渡せるAPIがあって開発者がそのAPIを利用するとき、あるsequenceの部分を(下記のコードの
map()以下)upstreamのスレッドのまま利用したい場合にこれが使えるのです。
Flux.fromArray(new Integer[] {1, 3, 5, 7})
.publishOn(Schedulers.parallel())
.filter(data -> data > 3)
.doOnNext(data -> log.info("# doOnNext filter: {}", data))
.publishOn(Schedulers.immediate())
.map(data -> data * 10)
.doOnNext(data -> log.info("# doOnNext map: {}", data))
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(200L);
// [parallel-1] INFO - # doOnNext filter: 5
// [parallel-1] INFO - # doOnNext map: 50
// [parallel-1] INFO - # onNext: 50
// [parallel-1] INFO - # doOnNext filter: 7
// [parallel-1] INFO - # doOnNext map: 70
// [parallel-1] INFO - # onNext: 70
参考:https://github.com/bjpublic/Spring-Reactive/blob/main/part2/src/main/java/chapter10/Example10_9.java
- 結果では、一個目の
publishOn()で新しく作ったparallel-1のスレッドがdownstreamにも使われて、二個目のpublishOn()の後にあるdoOnNext()やsubscriberのonNext()がparallel-1のスレッドをそのまま利用して出力しています。
(5) どのScheduler-Schedulers.single()
- sequenceが複数生成されてもdownstreamを共通する一つのスレッドで処理するようにします。
public static void main(String[] args) throws InterruptedException {
doTask("task1")
.subscribe(data -> log.info("# onNext: {}", data));
doTask("task2")
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(200L);
}
private static Flux<Integer> doTask(String taskName) {
return Flux.fromArray(new Integer[] {1, 3, 5, 7})
.filter(data -> data > 3)
.doOnNext(data -> log.info("# {} doOnNext filter: {}", taskName, data))
.publishOn(Schedulers.single())
.map(data -> data * 10)
.doOnNext(data -> log.info("# {} doOnNext map: {}", taskName, data));
}
// [main] INFO - # task1 doOnNext filter: 5
// [main] INFO - # task1 doOnNext filter: 7
// [single-1] INFO - # task1 doOnNext map: 50
// [main] INFO - # task2 doOnNext filter: 5
// [single-1] INFO - # onNext: 50
// [main] INFO - # task2 doOnNext filter: 7
// [single-1] INFO - # task1 doOnNext map: 70
// [single-1] INFO - # onNext: 70
// [single-1] INFO - # task2 doOnNext map: 50
// [single-1] INFO - # onNext: 50
// [single-1] INFO - # task2 doOnNext map: 70
// [single-1] INFO - # onNext: 70
- 結果では、
doOnNext(),filter()がmainスレッドで、その他はsingle-1というスレッドで出力しています。
(6) どのScheduler-Schedulers.newSingle()
- sequenceが生成される度に違うスレッドを作ってくれます。
public static void main(String[] args) throws InterruptedException {
doTask("task1")
.subscribe(data -> log.info("# onNext: {}", data));
doTask("task2")
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(200L);
}
private static Flux<Integer> doTask(String taskName) {
return Flux.fromArray(new Integer[] {1, 3, 5, 7})
.publishOn(Schedulers.newSingle("new-single", true))
.filter(data -> data > 3)
.doOnNext(data -> log.info("{} doOnNext filter: {}", taskName, data))
.map(data -> data * 10)
.doOnNext(data -> log.info("{} doOnNext map: {}", taskName, data));
}
// [new-single-1] INFO - # task1 doOnNext filter: 5
// [new-single-2] INFO - # task2 doOnNext filter: 5
// [new-single-1] INFO - # task1 doOnNext map: 50
// [new-single-2] INFO - # task2 doOnNext map: 50
// [new-single-1] INFO - # onNext: 50
// [new-single-2] INFO - # onNext: 50
// [new-single-1] INFO - # task1 doOnNext filter: 7
// [new-single-2] INFO - # task2 doOnNext filter: 7
// [new-single-1] INFO - # task1 doOnNext map: 70
// [new-single-2] INFO - # task2 doOnNext map: 70
// [new-single-1] INFO - # onNext: 70
// [new-single-2] INFO - # onNext: 70
- 一つ目の引数では新しく作るスレッドの名前を、二つ目の引数ではそのスレッドをdaemonスレッドにするかをbooleanで設定できます。daemonスレッドとはメインスレッドが終了すると自動的に終了するスレッドのことです。
- 結果では、指定した名前の通りnew-single-1, new-single-2のスレッドで各々のsequenceの
doOnNext(),onNext()が出力しています。
(7) どのScheduler-Schedulers.boundedElastic()
- Blocking作業(DBとのI/Oなど)を担当する専用のスレッドをcpuコア数*10の分作ります(この作られたスレッドを保存する場所をthread poolと言います)。スレッドを使い終わったらそのスレッドはthread poolに返却して再利用するようにします。もし、全てのスレッドが作業中だったら100,000個の作業まで作業queueに待機させることができます。
(8) どのScheduler-Schedulers.parallel()
- Non-Blocking作業に最適化されているスレッドを作成します。cpuのコア数分のスレッドを生成します。
(9) どのScheduler-Schedulers.fromExecutorService()
- 既に使っている
ExecutorServiceがあると、そこでSchedulerを生成する方法です。ちなみに、ExecutorServiceはスレッドを再利用するためのthread poolを生成、管理するinterfaceです。
(10) どのScheduler-Schedulers.newXXXX()
- 上で説明したSchedulerはReactorで提供しているもので、そのインスタンスを生成するとき利用できました。しかし、
Schedulers.newSingle,Schedulers.newBoundedElastic(),Schedulers.newParallel()のメソッドを利用してカスタムSchedulerインスタンスを生成することができます。(スレッド名、スレッドの個数、スレッドのidle time、daemonスレッドとしての動作などを指定します。)
最後に
今回はNon-Blocking・非同期処理について理解を深める良い機会になりました。
今後はReactorの知識をもとにWebfluxをどうすればよく活用できるかについて学んでいこうと思います。
参考
-
https://projectreactor.io/docs
(1). https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Mono.html
(2). https://projectreactor.io/docs/core/release/api/reactor/core/publisher/Flux.html -
https://github.com/bjpublic/Spring-Reactive
(1). https://github.com/bjpublic/Spring-Reactive/tree/main/part2/src/main/java/chapter8
(2). https://github.com/bjpublic/Spring-Reactive/tree/main/part2/src/main/java/chapter9
(3). https://github.com/bjpublic/Spring-Reactive/tree/main/part2/src/main/java/chapter10 - 황정식, 『스프링으로 시작하는 리액티브 프로그래밍』, 비제이퍼블릭, 2023.