前書き
文章要約タスクにおいて、ICML2020で発表されたPEGASUSというモデルがあったので理解を深めるために紹介記事を書いてみます。
論文情報
@article{zhang2019pegasus,
title={Pegasus: Pre-training with extracted gap-sentences for abstractive summarization},
author={Zhang, Jingqing and Zhao, Yao and Saleh, Mohammad and Liu, Peter J},
journal={arXiv preprint arXiv:1912.08777},
year={2019}
}
**PEGASUS(Pre-tranning with Extracted Gap-sentenses for Abstractive Summarization)**モデルはTransformerベースのモデルで、**GSG(Gap Sentences Generation)**という新しいSelf-supervised Objectiveを設定することで、文章要約に特化した抽象型要約モデルを作成し、文章要約における12のベンチマークでSOTAを達成しています。
PEGASUSの基本的な仮説
BERTを代表とする事前学習モデルでは、**MLM(Masked Language Model)**と呼ばれる学習方式を使っています。MLMは文章中に出現された全単語の中、一部の単語をマスキング(masking)し、残りの単語を入力した時に、マスキングされた単語を予測するモデルを作ることで、文章中の該当単語の文脈情報(context information)を抽出可能にします。
さらに各自然言語タスクでは上記の**事前学習(pre-training)**で得られた単語の表現を使い、事前学習されたモデルをベースにfine-tuningすることで良い性能を持つモデルを作成して行きます。(Pre-trainingに関して)
既存のアプローチに対して、本論文では以下のような仮説を立てています。
closer the pre-training self-supervised objective is to the final downstream task, the better the fine-tuning performance
つまり、事前学習で学習されるべき対象は応用先タスクに近いほど、良い性能を出すはずということです。この仮説を考えると、文章要約は長い文章を短い文章で情報の漏れがなく簡潔にまとめるタスクであって、入力も出力も文であることから、事前学習対象として、単語よりは**文(sentence)**にした方が良いとのことになります。
Gap Sentences Generation(GSG)
上記仮説を元に、PEGASUSは文章の中、単語ではなく、文をマスキングし、残りの文からマスキングされた文を予測するようにモデル学習を行います。(つまり、文単位でのMLM方式になります。)

PEGASUS学習イメージ from Google AI Blog
文予測モデルの学習により、元文章の情報をより理解してあろう情報が文の表現から得られることが期待できます。さらに、学習対象となる文(マスキングされた文)が文章の中で重要な文章である場合、より良い文章情報がキャッチできることが考えられます。
PEGASUSは、学習のためにマスキングされる文をGap Sentenceを呼び、Gap Sentenceを連結した文章を要約文とみなし、学習を行います。従って、学習に使われるGap Sentenceの選択が重要になって来ます。
GSGの選択
Gap Sentenceの選択において、PEGASUSはROUGE1-F1という指標を使います。ROUGE1-F1は二つの文章に共通するn-gramの割合を計算する手法で、通常文章予約モデルから生成された要約文と人間による要約文の類似度を測ることで、文要約モデルの性能評価をします。(ROUGEに関するまとめ文章: ROUGEを訪ねて三千里:より良い要約の評価を求めて)
論文では、ある文と残りの文章のROUGE1-F1を計算することで、該当文が全文章における重要度を図り、ROUGE1-F1値が高い文をGap Sentenceとして選択します。つまり、自分を除いた文章全体と類似度が高いほど、文章の情報を多く持つ重要な文とみなされるとのことです。
勉強不足かもしれませんが、ROUGE1-F1計算で使うn-gramを単語埋め込み表現などを使って類似単語までカウンティングするようにするとどうなるか気になりました。論文上には言及がなかったです。
具体的なGap Sentence選択手法
- Ind: 各文を独立なものとみなし、(選択文、残り文章)のROUGE1-F1値を計算し、スコアの高い順でGap Sentenceとして選択
- Seq: (すでに選択された文 + 選択文、残り文章)のROUGE1-F1値を計算し、スコアが最大となる文を順次的に選択
Seq(順次的選択アルゴリズム)

S : 選択された文の集合
x_i : 計算対象文
D : 全体文の集合
さらに、ROUGE1-F1の計算において、n-gramを重複なしでカウンティングする(Uniq)か、出現頻度をそのまま使うか(Orig)によって、バリエーションを設けています。
モデル全体図
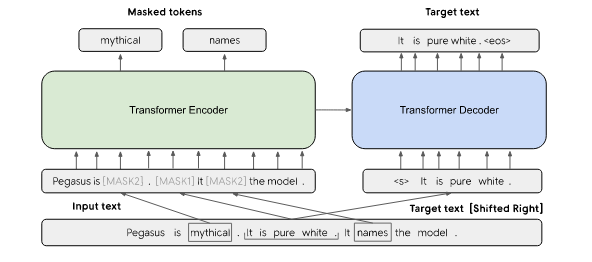
PEGASUSモデル図 from 論文
最終的にPEGASUSモデルのベースアーキテクチャーは上記のようになります。左側でMLM、右側でGSGを導入し、二つの学習方式を同時にとることになります。
実験
実験では、学習で使われるコーパスの影響、GSG・MLMの有効性、従来手法との比較、人力要約文との比較などを行っています。
学習に使われるコーパスの影響
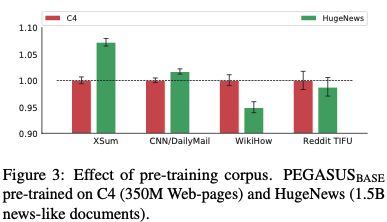
学習では3億5000万件のweb pageからなるデータ:C4 と 15億件のニュース文章からなるデータHugeNewsを使っています。
結果、C4の場合、同じウェブページデータであるWikiHow、RedditTIFUの方が良い性能を、HugeNewsの場合、同じニュース文章であるCNN、XSumが良い性能を出していることから、事前学習で使われるデータとタスクで使われるデータが似たドメインの場合より良いモデル性能が出ることが分かります。
学習方法の有効性
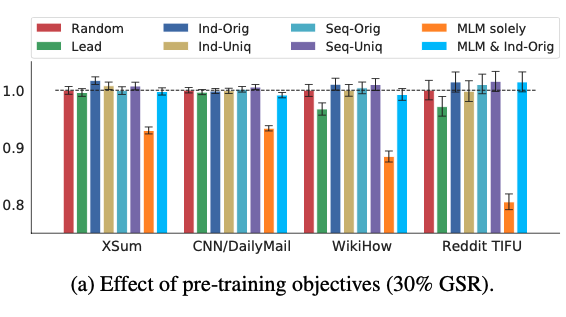
全体文章の30%の文をGap Sentenceとして設定し、各種Gap Sentenceの選択手法を試した結果、n-gramの出現頻度を使って文ごとにROUGE1-F1値を計算し、高い順に選択するInd-Orig手法が一番効果的であることが分かります。
さらに、GSR + MLM + Ind-Origで学習させた場合、GSR + Randomと似たような性能で、GSR + Ind-Origよりは低い性能を出していることからMLMとGSRの組み合わせは有効でないことが分かります。
論文によると、GSR + MLM + Ind-OrigとGSR + Ind-Origを比較すると、前者の方が学習ステップに対する(100k-200k checkpoints)性能向上率が早い一方で、後半になって性能向上がなく、最終的にはGSR + Ind-Origよりは悪い結果になっているようです。
Interestingly, when comparing MLM & Ind-Orig to Ind-Orig, we empirically observed MLM improved fine-tuning per- formance at early pre-training checkpoints (100k - 200k steps), but inhibited further gains with more pre-training steps (500k).
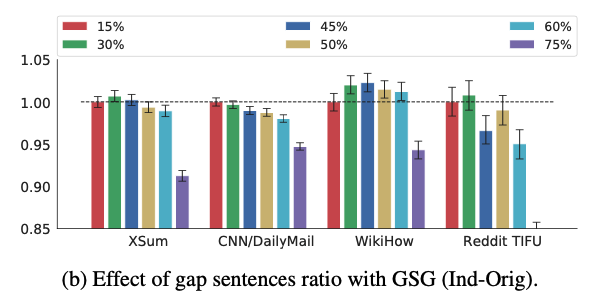
また、全文章におけるGap Sentence割合(Gap Sentences Ratio: GSR)を調整してみた結果、各種データに対してGSR値が50%まではそこそこ良い性能を維持し、その後激減することが分かります。
他モデルとの比較
性能
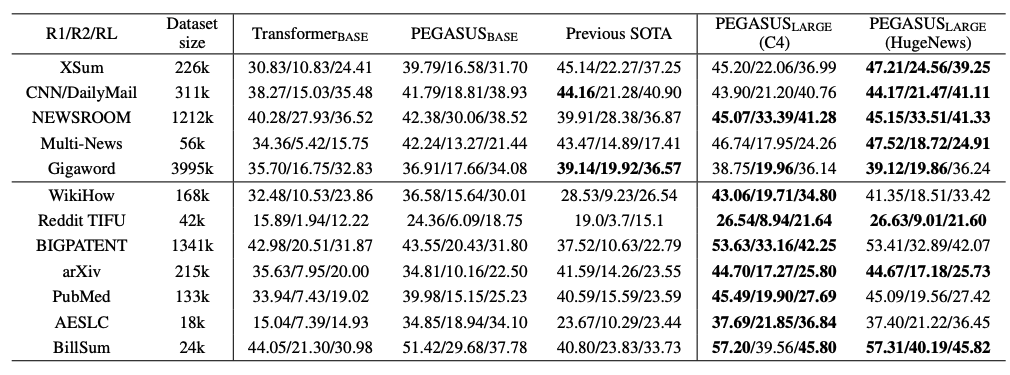
12件のベンチマークデータにおいてSOTAを達成しています。
学習データ量
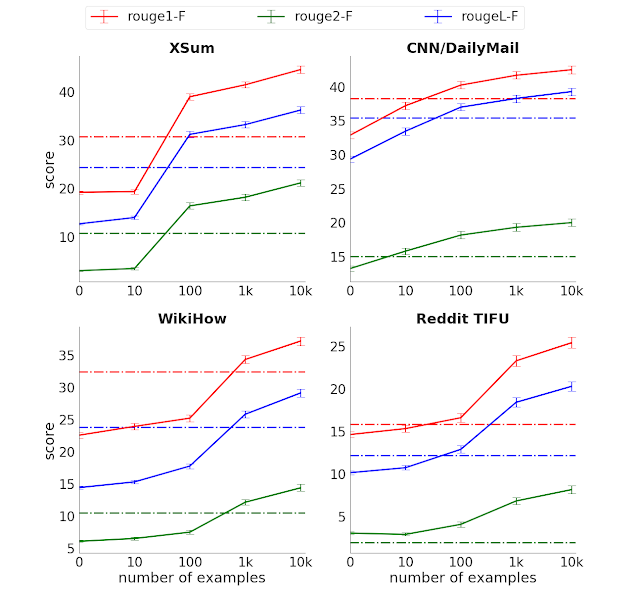
学習データ量におけるモデル性能 from Google AI Blog
1000サンプルぐらいの学習データで性能面で従来のSOTA手法を上回っていることが分かります。
人力要約文との比較

論文には載っていないですが、Google AI Blogの紹介記事によると人力要約とPEGASUSによる要約を人に評価してもらった時、両方を区別できない場合もあったようです。
We performed the experiment with 3 different datasets and found that human raters do not consistently prefer the human summaries to those from our model.
抽象的要約性能について
最後にPEGASUSが生成した要約文は単に文章中の重要な単語を並んだ要約ではなく、ちゃんと意味を理解した上で要約していることを確かめるために、extractive coverage と extractive densityという指標を使って、abstractivenessを評価しています。
抽象的な要約文ほど、学習文章から抽出した単語数が少なく使われ、学習文章で出現したスパンが少ないとのことになります。
More abstractive summaries have smaller extractive coverage (more novel words) and smaller extractive density (smaller spans copied from inputs).
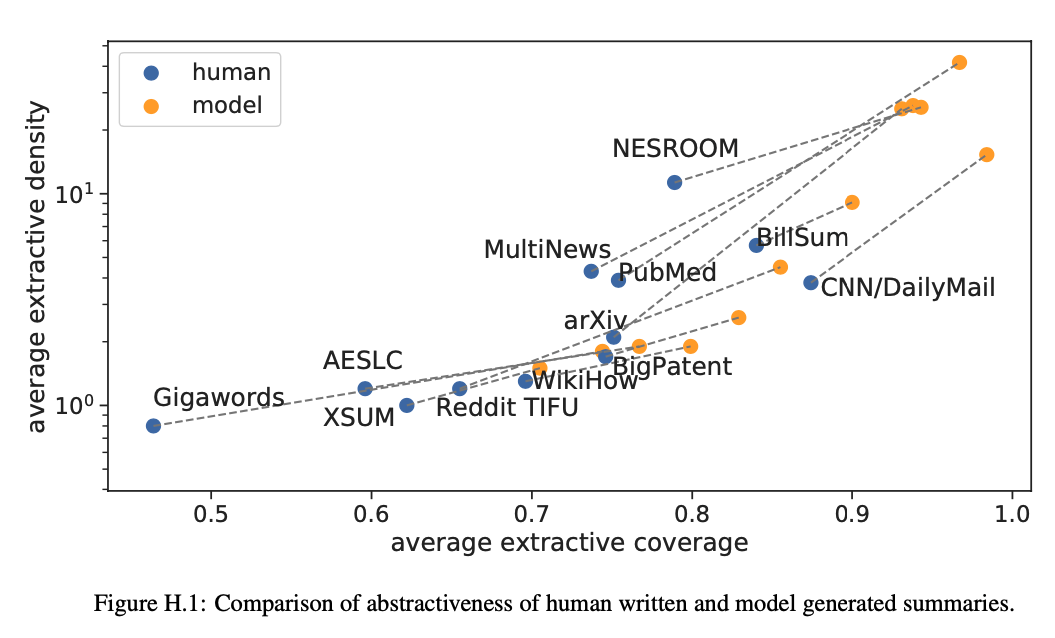
結果的には全てのデータにおいて、人間ほどの抽象度にはなっていないですが、抽象要約には成功しているようです。上図からは数値的に見えないですが、Google AI Blogにあげたデモ例を見ると、軍艦の名前を四つ羅列した文章をまとめた時に、ちゃんと四つの軍艦という学習データにもなかった単語でまとめているようです。
まとめ
文章要約モデルPEGASUSを調べながら書いてみました。
他の紹介記事にも書いてあるように、本論文の基本仮説が「他の教師なし学習モデル(self-supervised)でもタスクに特化した学習方式(pre-training objective)を採用すれば、性能向上につながるであろう」可能性を開けたことに非常に価値を感じました。
closer the pre-training self-supervised objective is to the final downstream task, the better the fine-tuning performance
さらに、他ではあまり強調していなかったですが、(専門家にはごく当たり前に感じたからかもしれないが)、個人的にはコーパスの影響を測る実験で、タスクに似たようなコーパスデータで学習させた方が良い結果が得られるとの結論からも得ることがありました。
最後に、いろいろ調査しながら本文を書いてはありますが、まだTransformerもBERTも理解度が浅いので、とこか間違ったことを書いていれば指摘してくださると幸いです。
参考文献
*Pegasus: Pre-training with extracted gap-sentences for abstractive summarization
*A package for automatic evalua- tion of summaries. In Text Summarization Branches Out
*PEGASUS: A State-of-the-Art Model for Abstractive Text Summarization