この記事について
前回はNSGA-IIを説明しました。今回はもう一方の代表的な多目的最適化アルゴリズムである MOEA/D(Multi-objective Evolutionary Algorithm based on Decomposition)を説明します。
NSGA-IIが「非劣解ランクで解を評価する」のに対して、MOEA/Dは全く異なるアプローチを取ります。
一言で言うと「多目的問題を複数の単目的問題に分解して解く」という発想です。
単目的をやられてる方々からはおそらく、「単目的問題をたくさん解く」という方向性が馴染みやすいかと思います。
多目的最適化入門シリーズの他の記事はこちら。
| 記事 | 内容 |
|---|---|
| ① | 多目的最適化とは?基礎概念 |
| ② | NSGA-IIの説明 |
| ③(本記事) | MOEA/Dの説明 |
| ④ | ベンチマーク問題の説明 |
MOEA/Dの基本アイデア
問題の分解(Decomposition)
MOEA/Dの核心は「多目的問題を複数の単目的問題に分解する」という考え方です。
どうやって分解するかというと、重みベクトル(weight vector) を使います。
例えば2目的問題($f_1$, $f_2$ を最小化)があったとき、
w^{(1)} = (0.0, 1.0), \quad w^{(2)} = (0.3, 0.7), \quad w^{(3)} = (0.5, 0.5), \quad w^{(4)} = (0.7, 0.3), \quad w^{(5)} = (1.0, 0.0)
のような複数の重みベクトルを用意して、それぞれの重みに対応するスカラー化問題を作ります。
それぞれの重みが「この目的関数をどれくらい重視するか」を表しています。
$w^{(3)} = (0.5, 0.5)$ なら $f_1$ と $f_2$ を同じくらい重視し、$w^{(1)} = (0.0, 1.0)$ なら $f_2$ だけを重視するわけです。
なぜこれでパレートフロントが得られるのか?
重みを少しずつ変えながら複数の単目的問題を解けば、パレートフロント上の色々な点が得られるということになります。
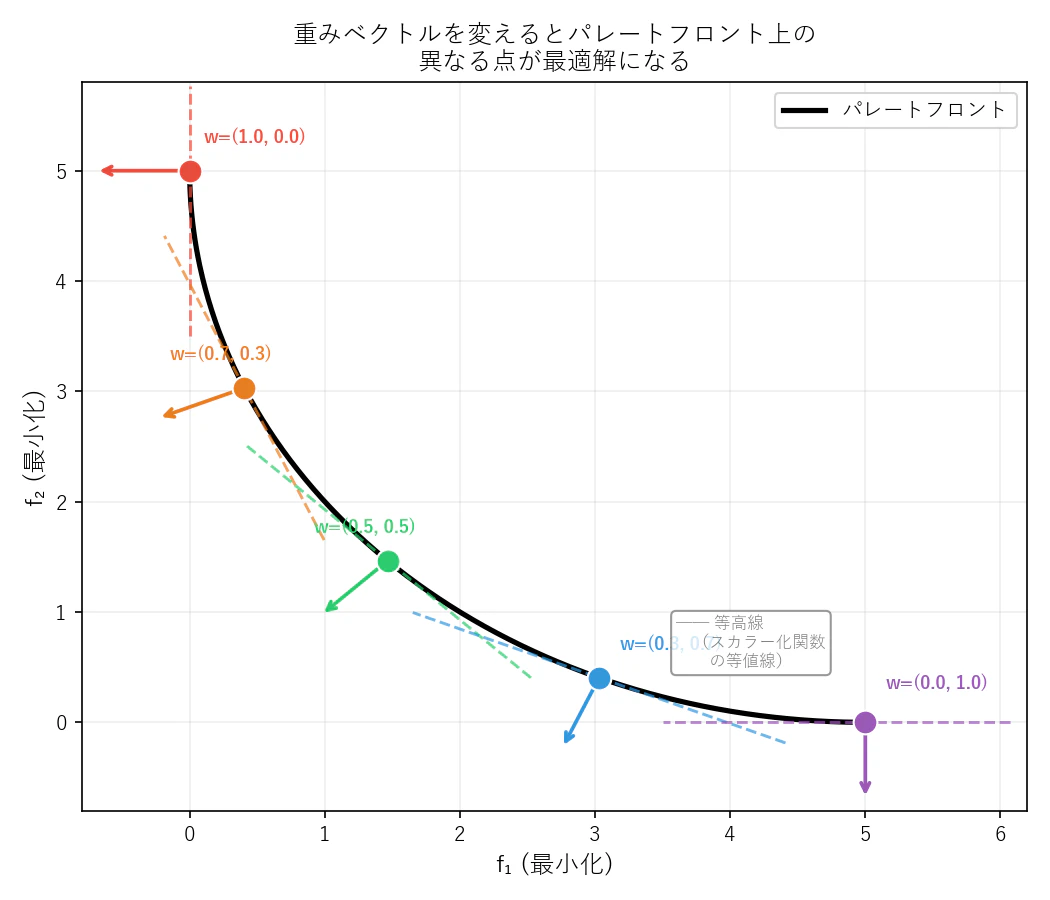
- 各色の点が、それぞれの重みベクトルで最適化したときの解
- 矢印が重みベクトルの方向(その目的を重視する向き)
- 破線が等高線(スカラー化関数の等値線)で、各点でパレートフロントに接している
$w=(1.0,\ 0.0)$ なら $f_1$ のみを最小化 → パレートフロントの左端($f_1$ が最小の点)が最適解になります。
重みを少しずつ $f_2$ 側にずらすにつれて、最適解もフロント上を右へ移動していきます。
これが分解ベースのアプローチの直感的なイメージです。
スカラー化関数(Scalarization Function)
多目的問題を単目的に変換するスカラー化関数には複数の選択肢があります。
重み付き和(Weighted Sum)
最もシンプルなスカラー化関数です。
f^{\text{WS}}(\mathbf{x} | \mathbf{w}) = \sum_{i=1}^{m} w_i f_i(\mathbf{x})
ここで $\mathbf{w} = (w_1, \ldots, w_m)$ は重みベクトルで、$\sum_i w_i = 1$ を満たします。
長所:シンプルで計算が速い
短所:パレートフロントが凸(convex)でない場合、重み付き和では到達できない点があります。
例えば凹型のパレートフロントの場合、どんな重みを設定しても中間部分の解が得られないことがあります。
PBI(Penalty-based Boundary Intersection)
重み付き和の限界を克服するために、よく使われる関数が PBI です。
f^{\text{PBI}}(\mathbf{x} | \mathbf{w}, \mathbf{z}^*) = d_1 + \theta \cdot d_2
ここで各量を説明します。
まず、理想点 $\mathbf{z}^*$(各目的関数の最良値)を基準として考えます。
\mathbf{z}^* = (z_1^*, z_2^*, \ldots, z_m^*)
\quad \text{where} \quad z_i^* = \min_{\mathbf{x} \in X} f_i(\mathbf{x})
$d_1$ は重みベクトル方向への投影距離(パレートフロントへの近さを示す)、$d_2$ は重みベクトルからの垂直距離(重みベクトル方向からのずれを示す)を表します。
d_1 = \frac{|(\mathbf{f}(\mathbf{x}) - \mathbf{z}^*)^T \mathbf{w}|}{||\mathbf{w}||}
d_2 = ||\mathbf{f}(\mathbf{x}) - \mathbf{z}^* - d_1 \frac{\mathbf{w}}{||\mathbf{w}||}||
$\theta$(ペナルティパラメータ)は $d_2$ の重みで、大きいほど「重みベクトルの方向からずれる解」に強くペナルティをかけます。
PBIの直感的なイメージ
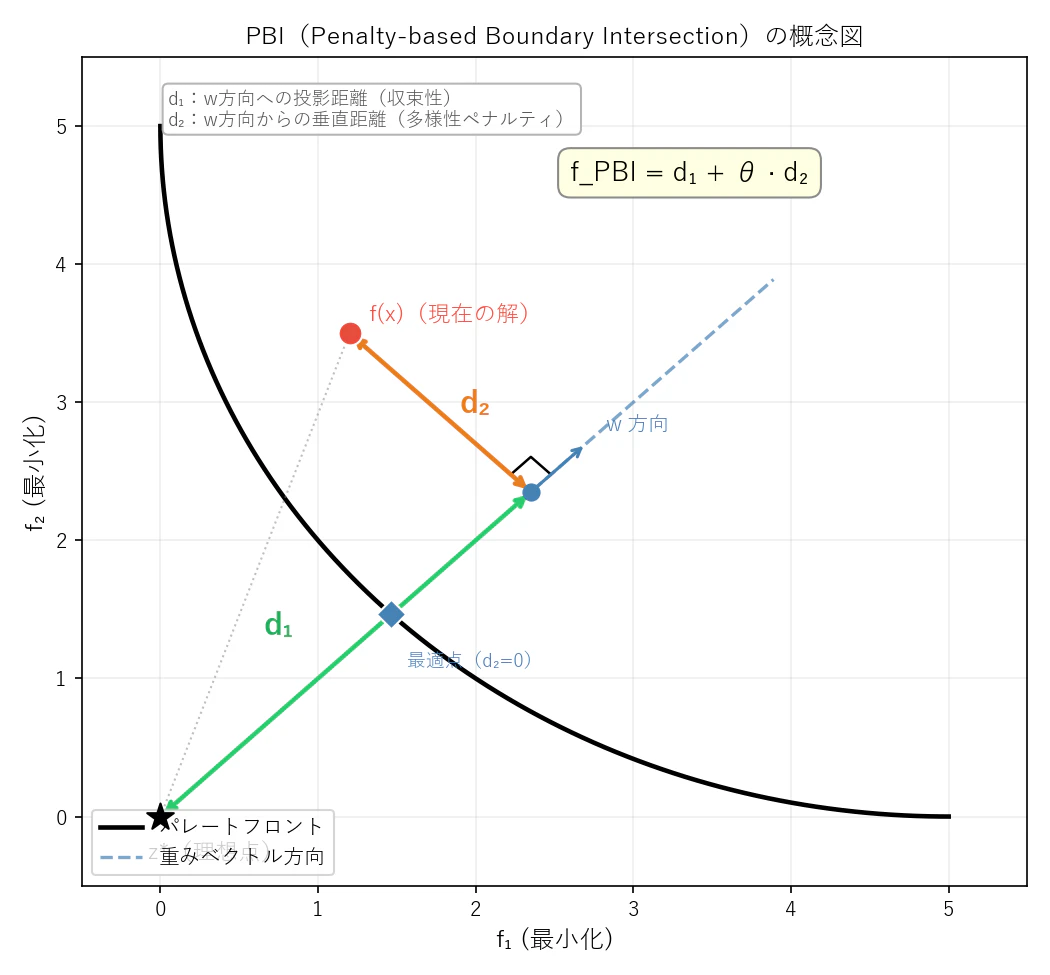
- d₁(緑):理想点 z* から重みベクトル方向への投影距離 → パレートフロントへの収束を評価
- d₂(オレンジ):重みベクトル方向からの垂直距離 → 担当エリアからのずれをペナルティとして評価
- 菱形(◆):この重みベクトルに対応するパレートフロント上の最適点(d₂=0 の点)
- θ が大きいほど d₂ のペナルティが強くなり、解が重みベクトルの担当方向に絞り込まれます
PBIを最小化することで、「重みベクトルが担当するパレートフロント上の点」に収束していきます。
import numpy as np
def pbi(f, w, z_ideal, theta=5.0):
"""
PBIスカラー化関数
f: 目的関数値ベクトル
w: 重みベクトル (正規化済み)
z_ideal: 理想点
theta: ペナルティパラメータ
"""
f_shifted = f - z_ideal # 理想点を基準にシフト
w_norm = w / np.linalg.norm(w) # 重みベクトルの正規化
# d1: 重みベクトル方向への投影距離
d1 = np.dot(f_shifted, w_norm)
# d2: 重みベクトルからの垂直距離
d2 = np.linalg.norm(f_shifted - d1 * w_norm)
return d1 + theta * d2
近傍関係(Neighborhood)
MOEA/Dのもう一つの重要な概念が近傍関係です。
重みベクトルが近い(ユークリッド距離が近い)分割問題同士は、最適解も似ているはずだという直感に基づいています。
MOEA/Dでは各分割問題について「近傍の分割問題の解」を使って交叉・更新を行います。これにより、近くの重みに対応した良い解を参考にしながら効率的に探索できるわけです。
def compute_neighborhoods(weight_vectors, T):
"""
重みベクトル間の近傍関係を計算
weight_vectors: 重みベクトルのリスト
T: 近傍サイズ
"""
N = len(weight_vectors)
neighborhoods = []
for i in range(N):
# 他の重みベクトルとのユークリッド距離を計算
distances = []
for j in range(N):
dist = np.linalg.norm(
np.array(weight_vectors[i]) - np.array(weight_vectors[j])
)
distances.append((dist, j))
# 距離が近いT個を近傍とする
distances.sort()
neighborhood = [idx for _, idx in distances[:T]]
neighborhoods.append(neighborhood)
return neighborhoods
MOEA/Dのアルゴリズム全体
① 重みベクトル W = {w^1, w^2, ..., w^N} を用意
② 近傍関係 B(i)(各重みの近傍インデックス集合)を計算
③ 初期集団 P をランダムに生成
④ 理想点 z* を初期化(各目的の最良値)
⑤ 以下を繰り返す:
各分割問題 i = 1, ..., N に対して:
a. 近傍 B(i) からランダムに2つの解を選択
b. 交叉・突然変異で子解 y を生成
c. 理想点 z* を更新(y の目的関数値が改善していれば)
d. 近傍 B(i) 内の各解 j に対して:
スカラー化関数 f(y | w^j) < f(P[j] | w^j) ならば
P[j] を y で置き換える
⑥ 十分な更新回数を経たら終了
重みベクトルに対応した解が近傍の情報を共有しながら更新されていくというのが、MOEA/Dの探索の核心です。
def moea_d(problem, N=100, T=20, n_generations=500, theta=5.0):
"""
MOEA/Dのメインループ
problem: 多目的最適化問題
N: 集団サイズ(分割問題数)
T: 近傍サイズ
"""
# 重みベクトルの生成(2目的の場合)
weight_vectors = [(i/(N-1), 1-i/(N-1)) for i in range(N)]
# 近傍関係の計算
neighborhoods = compute_neighborhoods(weight_vectors, T)
# 初期集団の生成・評価
population = [problem.initialize_one() for _ in range(N)]
objectives = [problem.evaluate(x) for x in population]
# 理想点の初期化
z_ideal = np.min(objectives, axis=0)
for gen in range(n_generations):
for i in range(N):
# 近傍からランダムに2つ選んで交叉
j, k = np.random.choice(neighborhoods[i], 2, replace=False)
y = crossover(population[j], population[k])
y = mutation(y)
# 目的関数値を計算
f_y = problem.evaluate(y)
# 理想点の更新
z_ideal = np.minimum(z_ideal, f_y)
# 近傍の解を更新
for neighbor_idx in neighborhoods[i]:
w = np.array(weight_vectors[neighbor_idx])
current_f = np.array(objectives[neighbor_idx])
# PBIでスカラー化して比較
if (pbi(f_y, w, z_ideal, theta) <
pbi(current_f, w, z_ideal, theta)):
population[neighbor_idx] = y
objectives[neighbor_idx] = f_y
return population, objectives
NSGA-IIとMOEA/Dの比較
| 特徴 | NSGA-II | MOEA/D |
|---|---|---|
| 基本アプローチ | パレート支配ベース | 分解ベース |
| 多様性の保ち方 | 混雑距離 | 重みベクトルの均一配置 |
| 目的数が増えたとき | 性能が大きく落ちる | 比較的安定 |
| パラメータ | ほぼなし | ペナルティ $\theta$、近傍サイズ $T$ |
| 凹型パレートフロント | 対応できる | 重み付き和では対応できない(PBIなら可能) |
| 計算効率 | $O(mN^2)$ | $O(mNT)$($T \ll N$ なら速い) |
個人的にはMOEA/Dの「問題を分解して解く」というアイデアが数理最適化的な発想と親和性が高いと思っています。
一方で、NSGA-IIは多目的最適化の基本原理に従っているのでこれはこれで重要なアルゴリズムかなという感触です。
正規化の重要性
実は、MOEA/Dを使う際に見落としがちですが非常に重要な問題があります。それが目的関数の正規化です。
例えば $f_1 \in [0, 1]$、$f_2 \in [0, 1000]$ のように目的関数のスケールが大きく異なる問題を考えてみましょう。
この場合、重みベクトル $(0.5, 0.5)$ としても、実質的には $f_2$ の影響が1000倍強くなってしまいます。
PBIの計算でも、スケールの大きい目的関数が支配的になってしまい、重みが意味をなさなくなります。
これを防ぐために、目的関数値を $[0, 1]$ に正規化する処理が必要です。
def normalize_objectives(objectives, z_ideal, z_nadir):
"""
目的関数値を正規化 [0, 1] スケールへ
z_nadir: nadir点(各目的の最悪値)
"""
normalized = []
for f in objectives:
f_norm = (np.array(f) - z_ideal) / (z_nadir - z_ideal + 1e-10)
normalized.append(f_norm)
return normalized
ただし、この正規化にも課題があって、「目的関数の範囲が探索中に変わる」「nadir点の推定が難しい」など、なかなか一筋縄ではいかないんですよね。。。
この正規化の問題はMOEA/Dの研究において重要なテーマの一つで、次回のベンチマーク問題の記事でも少し触れます。
まとめ
今回はMOEA/Dを説明しました。
- 分解アプローチ:多目的問題を重みベクトルを使った単目的問題に分解して解く
- スカラー化関数:重み付き和とPBI(Penalty-based Boundary Intersection)が代表的
- 近傍関係:重みが近い分割問題同士で情報を共有して効率よく探索
- NSGA-IIに比べて目的数が多い場合に強いが、正規化が重要
次回はベンチマーク問題(DTLZ・WFG)とHypervolume指標について説明します。
参考にした記事や本、論文等
- Q. Zhang and H. Li, "MOEA/D: A multiobjective evolutionary algorithm based on decomposition," IEEE Trans. on Evolutionary Computation, vol. 11, no. 6, pp. 712-731, December 2007.
- H. Ishibuchi, K. Doi, and Y. Nojima, "On the effect of normalization in MOEA/D for multi-objective and many-objective optimization," Complex and Intelligent Systems, vol. 3, no. 4, pp. 279-294, 2017.