要旨
本記事では以下のような内容を手短にお伝えしようと思います。
- エンタープライズのデータ活用基盤の中で機械学習も含めてシステム作りしていくときの話
- その中で特にデータ活用基盤の視点で考えることのベーシックな部分
- その中で特にストリーム処理との組み合わせについての考え方
なお、本記事では機械学習からの視点ではなく、データ活用基盤からの視点で記載してみます。
背景
エンタープライズのデータ活用基盤内で機械学習を用いていくときに、初めはデータそのものの分析、モデルを作り学習させること、本格的に学習させて使い物にさせること、などの分析と学習に重きが置かれると思います。
一方で「さあ、本格的に本番適用していくぞ」となったときに、データ活用基盤として課題になることの例として
- データの取り回しかた
- 推論処理をどう取り込んでいくのか
という点が挙げられます。ここでは、この2点に絞って考えます。
データの取り回し方
歴史のあるエンタープライズのシステムというのは本当に複雑で、
データの流れ方を必ずしも単純に表現できないことが多いかと思います。
いわゆる「サイロ化」された状態と表現されることもありますが、
程度問題こそあれ多くの組織でそういった状況になっていることは多いのではないでしょうか。
とはいえ、複雑な様子を分解していくと、大雑把には以下のような流れを組み合わせでできていることが多いかと思います。
■データ収集を発端としたデータ活用基盤でのデータの流れ
収集 -> 蓄積 -> 加工 -> 活用
このとき、データの取り回し方という観点から整理すると、
データ発生源からデータ活用基盤にデータを持ってくる方式、データ活用基盤内での処理方式によって、大まかに
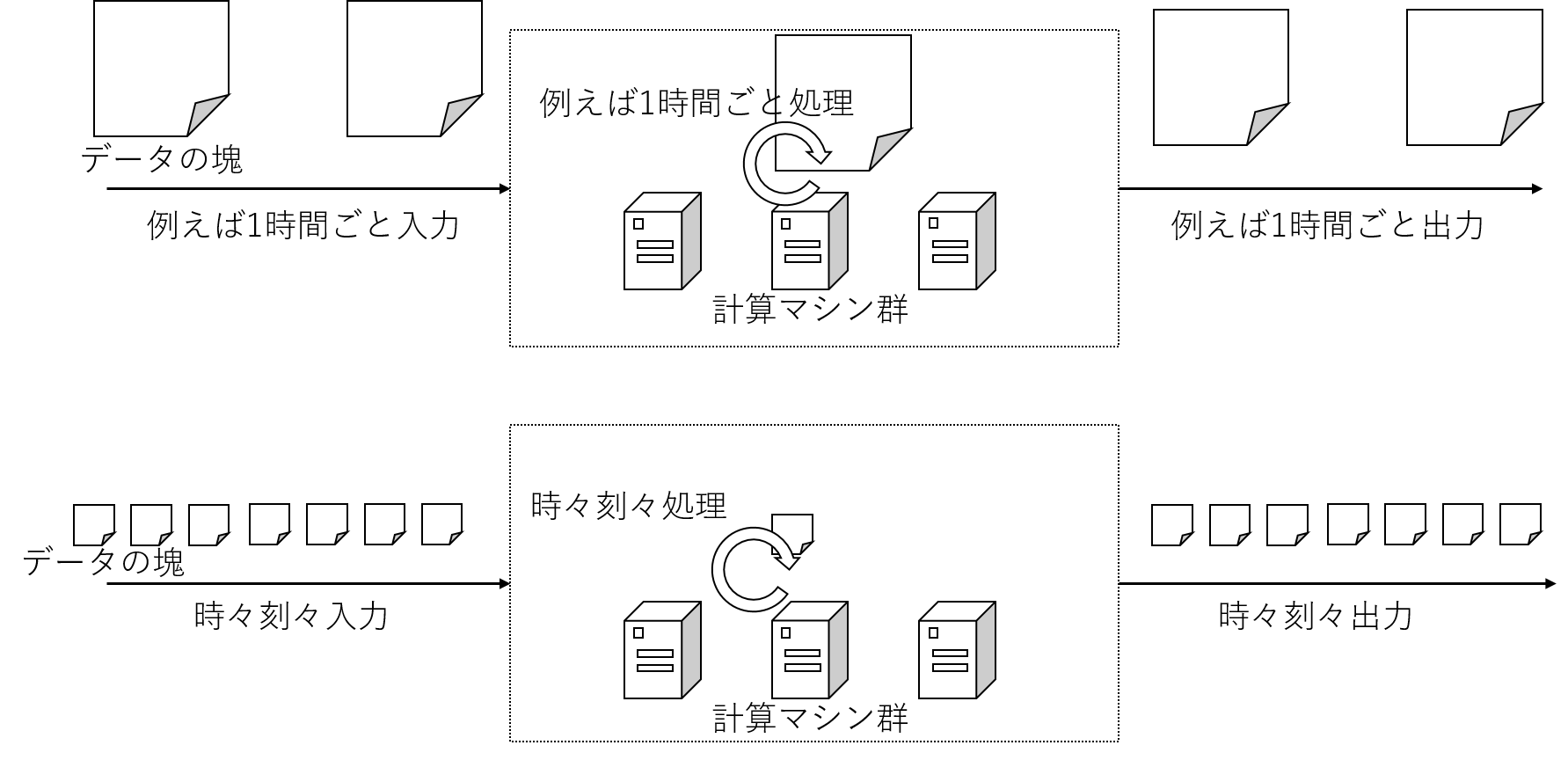
- バッチ処理方式:
- 1時間単位で取られるスナップショットデータを連係する場合など、ある程度まとまって処理をすることを前提とする方式
- ストリームデータ処理方式
- 時々刻々と生成されるデータをミリ秒〜分単位で連係する場合など、できるだけ短い遅延・処理単位で扱うことを前提とする方式
の2種類が考えられます。
ただし、ストリームデータ処理方式も、実態としては小さな単位でデータをまとめこんで処理しているケースがあり、
必ずしも発生源での情報単位(ここではメッセージと表現する)で取り扱っていない実装もあります。
ここでは大まかな区分と考えるのが良いでしょう。
データ活用基盤視点での推論処理の位置づけ
さて、ここで機械学習の推論処理というのは、上記の「データ収集を発端としたデータ活用基盤でのデータの流れ」で言うと、
「加工」や「活用」の際のいち処理と考えることができます。
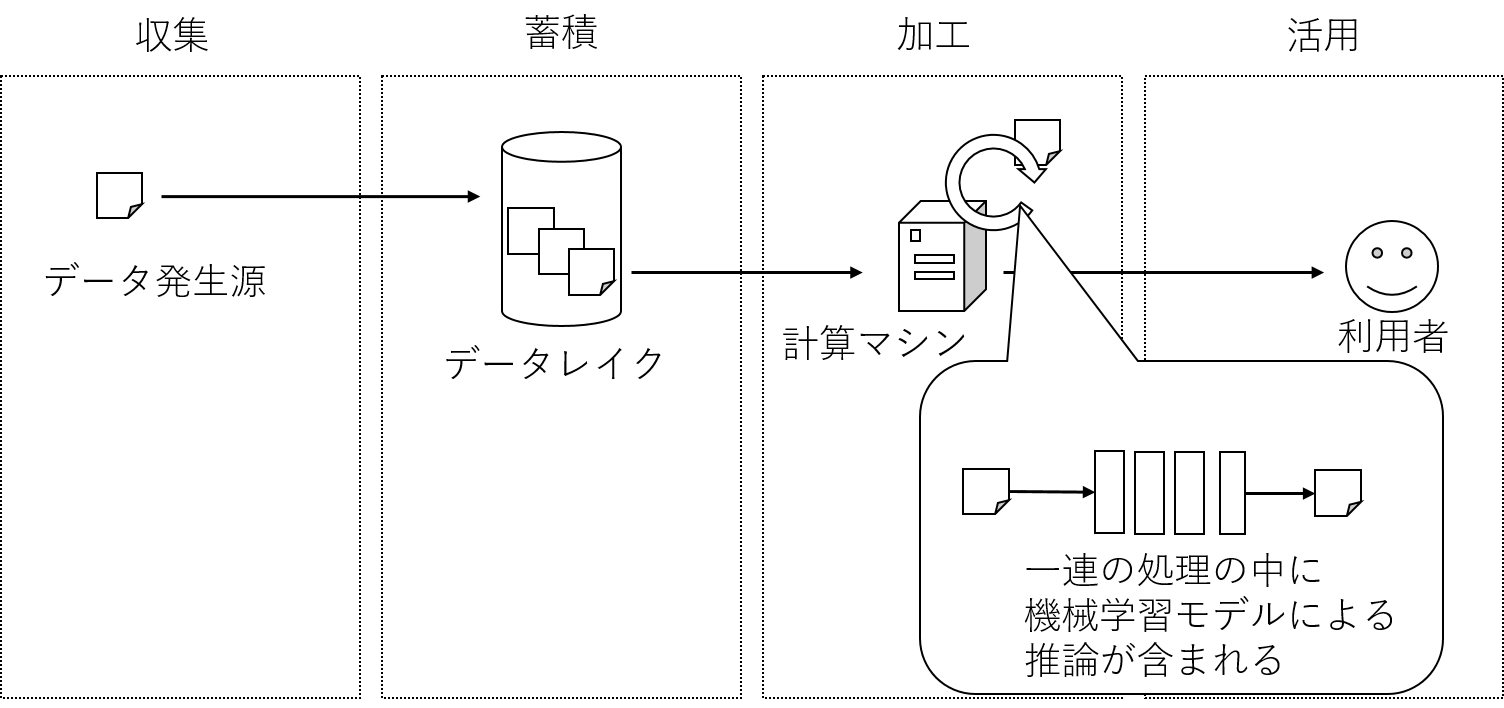
収集されてきたデータや蓄積されたデータを、一連の処理にかけ、得られた結果をシステムや人が見るビューに渡します。
その「一連の処理」の中のひとつに推論処理が含まれる、と考えます。
なお、一連の処理と表現したのは、実際のケースでは推論用の機械学習モデルにデータを入力して結果を得る処理の他に、
多くの処理が必要となるケースが多いからです。
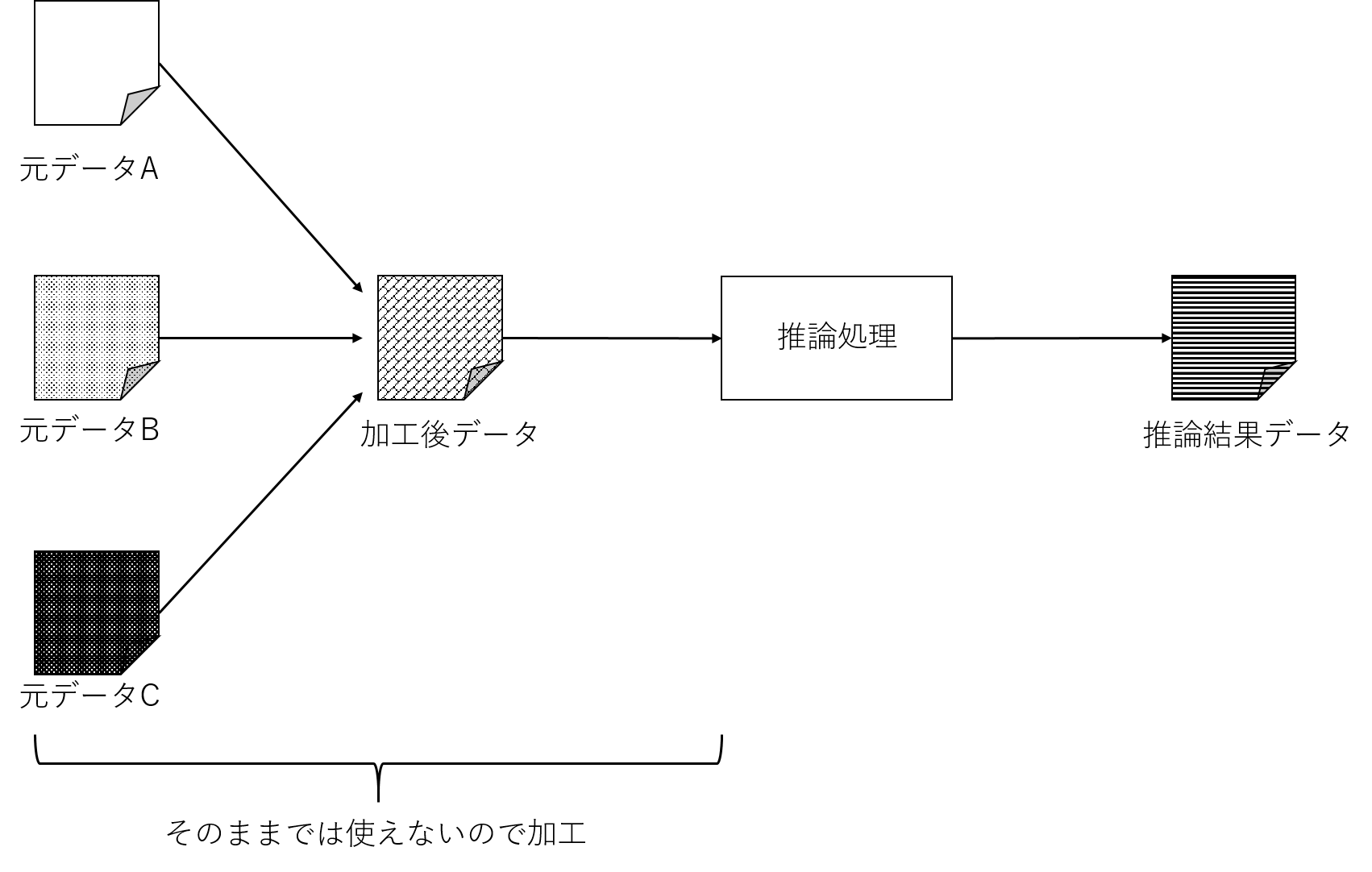
例えば、データの取り回し方で述べたように、サイロ化されたシステム群から得られるデータは発生源のデータそのものでは使えず、
複数の発生源から得られたデータを組み合わせ(結合し)たり、不要な部分を取り除いたり、など加工しないとならないケースが多々あります。
(ここでは前処理と表現してみます)
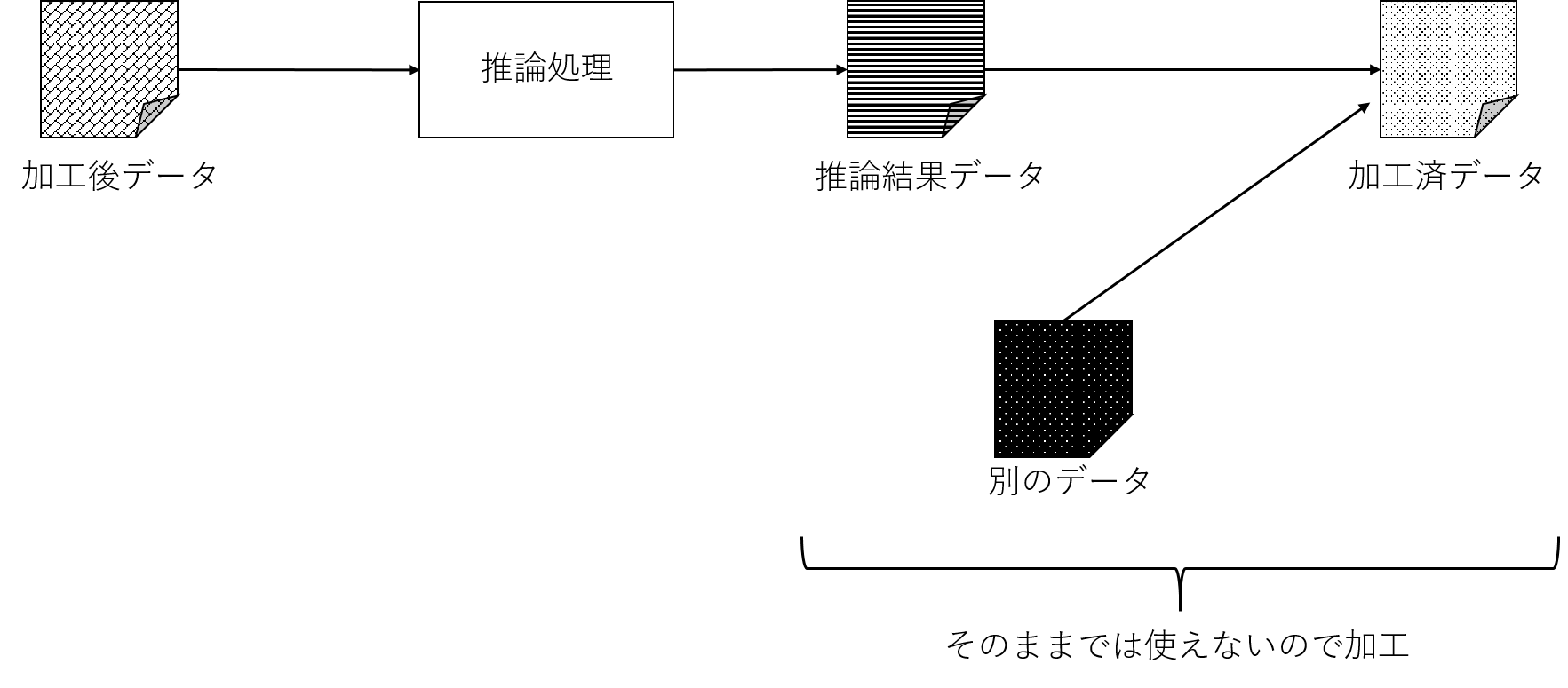
また、推論用の機械学習モデルから出力されたデータをそのまま使うだけでなく、他の方法を用いて算出されたデータと混ぜる、などの処理を行ったり、最終的なサービスで求められる形式に変換したり、などの処理を行うこともあるでしょう。(ここでは後処理と表現してみます)
ちなみに、私の経験の中でも、処理用のアプリケーションのうち、この前処理と後処理が大半を占めるケースも少なくありません。実は一連の処理全体のフローを感が見えることが大切です。
また、特に大規模データを取り扱う際には、前後も含めた一連の処理の流れ全体を見て、基盤をチューニングしたり、アプリケーションをリファクタリングするようにしています。想定外のデータの偏りがないか、不必要なI/Oを発生させていないかなど。
さて、以上をもとにデータ活用基盤視点で「収集」をスタートとして「バッチ処理方式」や「ストリームデータ処理方式」に当てはめて考えることができます。
ここで、もうひとつ「活用」をスタートとしたパターンが存在するので触れておきます。
「活用」視点から見ると、バッチ処理方式やストリームデータ処理方式のように、スケジュールに則って機械的に処理していくパターンの他にも、
オンデマンドでデータを入力して結果を見たいケースが存在します。
ここでは「オンデマンド活用方式」と呼ぶことにしましょう。
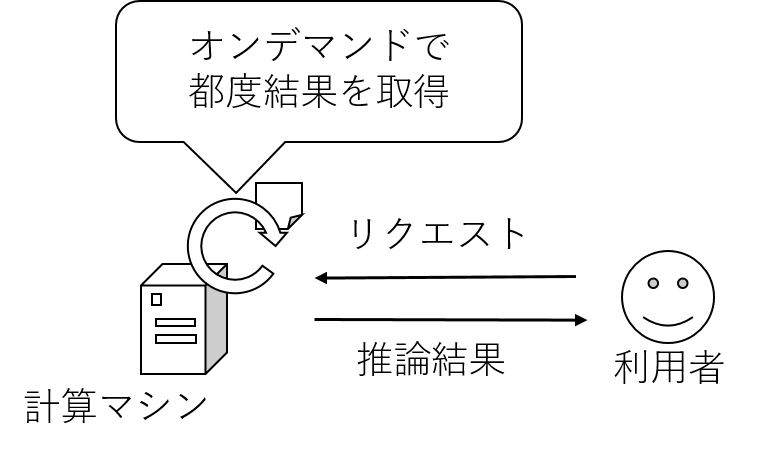
以上を踏まえると、データ活用基盤における機械学習の推論処理の位置づけとしては、
- バッチ処理方式のデータ処理に組み込むパターン
- ストリームデータ処理方式のデータ処理に組み込むパターン
- オンデマンド活用方式のデータ処理に組み込むパターン
の3種類で考えることができそうです。
推論処理の組み込み方
「データ活用基盤視点での推論処理の位置づけ」で整理したように、推論処理はデータ活用基盤のいくつかの処理パターンの中に組み込むことができます。
ここで推論処理の結果をどう得て、どう前後処理と連係させるのか、という推論処理の動かし方のパターンの視点で考えます。
機械学習ライブラリ、フレームワークにはどういったものがあるでしょうか。
例えばTensorFlow、PyTorch、Deeplearning4j、scikit-learn、Apache SparkのSpark MLlib(以降MLlib)等が挙げられます。ほかにも多々あります。
これらはそれぞれ学習したモデルを保存し、別なアプリケーションでロードして用いられるようになっています。
ライブラリやフレームワークによって独自の方式で保存することもあるし、汎用的な表現形式で保存・利用可能な場合もあります。
例:MLlibでモデルを出力する例(引用元 https://spark.apache.org/docs/latest/ml-pipeline.html )
// Now we can optionally save the fitted pipeline to disk
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
これらをアプリケーションから利用する場合は、関連ライブラリをインポートし、モデルをロードする処理を実装した上で活用していきます。
ここでは、直接モデルロードパターンと表現することとします。
また最近では、上記のような方法で出力された機械学習モデルを管理し、
入力データを与えると結果データを取り出せるウェブサービスのような方式で機械学習モデルを取り合わす技術もいくつか見られるようになってきました。
例えば、TensorFlow Serving、Clipper、Polyaxon、Seldon等が挙げられるでしょう。
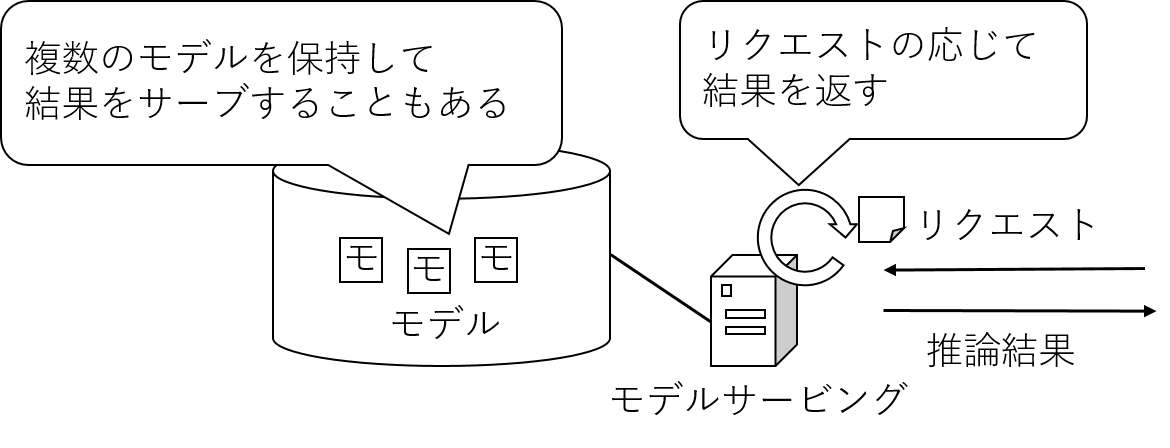
これらをアプリケーションから利用する場合は、アプリケーション内部から提供されているサービス方式(例:REST APIなど)に合わせてアクセスし、推論結果を受け取って内部利用することになります。
ここでは、サービングシステム利用パターンと表現することとします。
以上から、推論処理の位置づけと推論処理の動かし方のパターンを踏まえ、組み込み方のパターンを考えることができます。

それぞれ特徴があるのですが、ここではいくつか簡単に述べます。

どれか単一の方式が優れているというよりは、トレードオフがあると考えると良いでしょう。
実際のシステム開発では、これらのパターンと業務要件を踏まえつつ、将来性を考慮して選択していくことになります。
ストリームデータ処理方式で直接モデルロードパターンを用いる例
ストリームデータの処理エンジンとしては、昨今様々なものが登場しています。
例えば、Apache SparkのSpark Streaming(Structured Streaming)、Apache Kafka(以降Kafka)のKafka Streams、Apache Flink、等が挙げられます。
またストリームデータを取り扱う際には、ストリームデータを取り回すハブとなる「メッセージングシステム」と組み合わせて用いることが多いでしょう。
メッセージングシステムとしては、KafkaやApache Pulsar等が挙げられます。
ここでは代表的なメッセージングシステムとしてKafka、ストリームデータの処理エンジンとしてKafka Streamsを用いる例を考えましょう。
(Kafkaだけでストリームデータ処理のパイプラインを構成できるので話を単純化しやすいことをここでは考慮)
今回試す例の全体イメージは以下の通りです。
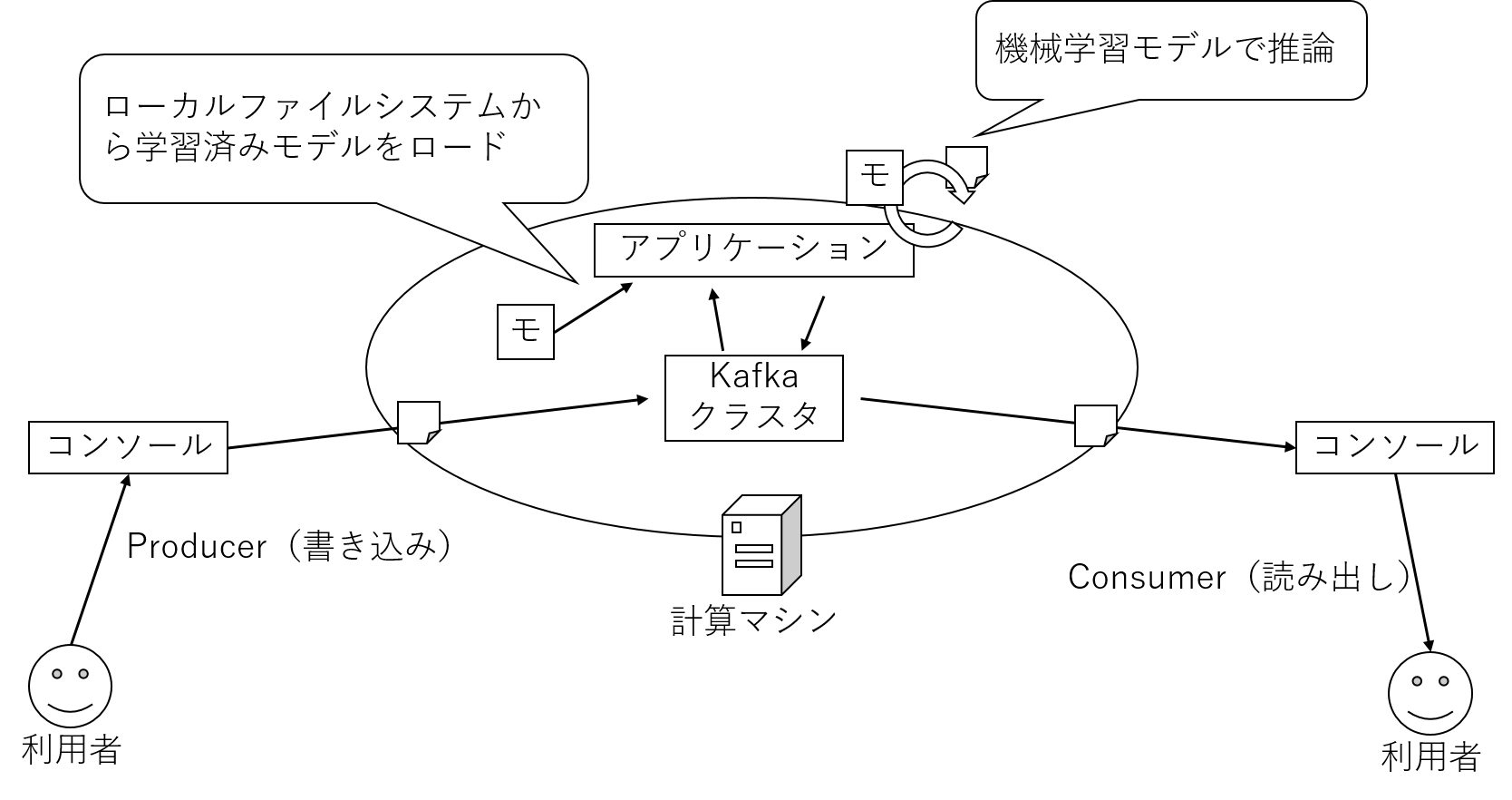
実際の業務や研究で利用する際には、ここに記載されている他の要素が機能面、非機能面ともに重要となりますのでご注意ください。
ここではイメージを掴んでいただくため、本記事のエッセンスに極力閉じて紹介したいと思います。
前提:実行環境
- 私は手元のCentOS7で試しました。
- JDKも予め導入しておいてください。私の手元では1.8で試しました。
- Mavenも予め導入しておいてください。
準備:Kafka環境の作成
まずは簡易的にKafkaを起動します。
Kafkaの簡易的な構築と起動については、 Kafka公式ドキュメントのクイックスタート を参照してください。
今回は簡単な動作確認なので、Broker1台構成で良いです。
起動が完了したら、予めKafkaのトピック(注釈)を作成しておきましょう。
Kafkaを起動したマシンのターミナルを開き、以下のようなコマンドを実行し、トピックを作成します。
注釈:
Kafkaでメッセージを保持する論理的な単位と考えてください。本記事では、大雑把にはデータセットのことだと考えていただけると良いです。
実行例:
$ ./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic input
$ ./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic output
今回用いる機械学習モデルとKafka Streamsアプリケーションについて
今回は著名なIrisのデータを用いた例とします。
Irisデータとその判定については Irisデータに関するwikipedia記事 を参照してください。
今回使用するKafka StreamsはJavaを用いてアプリケーションを実装します。
そのため、Javaで取り扱いやすい機械学習ライブラリ、フレームワークを利用すると簡潔に実装できます。
TensorFlowのJava API、Deeplaernig4j、BigDL等がそれに該当するでしょう。(注釈)
注釈:
実際には、試行錯誤の際に利用したいライブラリ、フレームワークと本番適用の際に利用したいものが一致しないケースもあるかと思います。
特に分析者とシステム開発・運用者の間で、手に馴染んだ技術や考え方が一致しないことも多々あります。
これをどう解決するのか、という点での議論がありますが、本記事では省略します。
さて、ここではDeeplearning4jを用いて学習されたモデルをロードし用いる例を紹介します。
なお、モデルは予め、 deeplearning4j-examples あたりを参考に学習させて出力しておいてください。
学習については、 CSVExample が参考になりますし、モデルの出力については、 SaveLoadMultiLayerNetwork が参考になります。
アプリケーションの作成
Kafkaからデータを読み込み、処理するためのKafka Streamsアプリケーションを作成します。
Kafka Streams自体については公式ドキュメントが簡潔でわかりやすいので Kafka公式ドキュメントのKafka Streams を参照してください。
本記事では、 Kafka公式ドキュメントのKafka Streams を参考に、ベースとなる雛形を作成します。
mvn archetype:generate \
-DarchetypeGroupId=org.apache.kafka \
-DarchetypeArtifactId=streams-quickstart-java \
-DarchetypeVersion=2.4.0 \
-DgroupId=streams.examples \
-DartifactId=streams.examples \
-Dversion=0.1 \
-Dpackage=streamml
今回は雛形として生成された、 streamml.Pipe を修正して用います。
ここではポイントのみ記載します。
main冒頭のプロパティを定義している個所はそのまま流用します。
つづいて前述の通り、本記事の例では予め学習させておいたDeeplearning4jのモデルをロードして用いることにします。
モデルの保存とロードについては、Deeplearning4jのサンプルである SaveLoadMultiLayerNetwork を参照してください。
ここでは以下のように実装します。
File modelZip = new File("src/main/resources/IrisModel.zip");
boolean saveUpdater = true;
MultiLayerNetwork model = MultiLayerNetwork.load(modelZip, saveUpdater);
つづいて、Kafka Streamsのトポロジーを定義するためのビルダーを定義します。
final StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("input");
streamメソッドの引数は入力トピック名なので、予め生成しておいたトピックを利用してください。
なお、本記事では、入力として 5.4,3.9,1.7,0.4 のようにカンマ区切りの4個の数値の文字列を入力することとします。
つづいて、入力トピックから得られたメッセージをカンマ区切りで分割し、モデルに入力して推論結果を得る処理を定義します。
// 今回はKeyを使用せず、Valueのみ扱うので mapValues メソッドを利用し、
// メッセージごとの処理を定義
KStream<String, String> result = source.mapValues(value -> {
// 文字列を変換し、モデルが期待する形式である2次元配列を生成
// ただし、この例では1メッセージずつ処理するので、実際のところ含まれる配列はひとつ
String[] strArray = value.split(",");
double[] doubleArray = Arrays.stream(strArray)
.mapToDouble(Double::parseDouble)
.toArray();
double[][] inputArray = {doubleArray};
// Deeplearning4jで取り扱うデータ形式に変換
INDArray inputNDA = Nd4j.create(inputArray);
// モデルにデータを入力し、推論結果を得る
INDArray outputNDA = model.output(inputNDA);
// 今回は出力は文字列とする
return outputNDA.toString();
});
上記のように、Kafka Streamsによるストリームデータ処理のアプリケーションは単純なJavaアプリケーションであるため、ロードしたモデルを素直にメッセージ処理の中で利用すれば良いだけなのでわかりやすい。
最後に、得られた結果を出力トピックに書き出す。
result.to("output");
それ以降は雛形のとおりです。
つまり、トポロジーをビルドし、Kafka Streamsによるストリームデータ処理を開始します。
アプリケーションの実行と動作確認
つづいてアプリケーションを実行してみましょう。
コンパイルして以下のように実行します。
$ mvn clean package
$ mvn exec:java -Dexec.mainClass=streamml.Pipe
アプリケーションが起動したら、サンプルデータを入力し、出力を確認してみましょう。
ここでは上記図のように、Kafkaに付属しているコンソール経由でデータを入出力するツールを利用し、動作確認します。
先程アプリケーションを起動したターミナルとは別のターミナルを立ち上げながら、まずは出力用のツールを起動します。
$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic output --from-beginning
続いて、もうひとつターミナルを立ち上げ入力用のツールを起動し、試しにサンプルデータを入力します。
入力例:
$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic input
> 5.4,3.9,1.7,0.4
> 5.7,2.5,5.0,2.0
> 5.0,3.0,1.6,0.2
>
さて、先程起動しておいた出力用のツールのターミナル上に、判定結果が表示されたでしょうか?レコードごとに判定すべき3種類のクラスの各Probabilityが表示されたら成功です。
出力例:
[[ 0.0067, 0.9882, 0.0051]]
[[ 0.0001, 0.0057, 0.9941]]
[[ 0.0066, 0.9906, 0.0028]]
まとめ
本記事では、データ活用基盤の中に機械学習の推論処理を組み込んでいく際の考え方、簡単な例を紹介しました。
実際のシステムはより複雑ですが、ひとつひとつの要素を分解していったときに見えてくる流れ、パターンに着目して考えるのが単純化の第一歩だと考えます。