SIGNATE プラクティスコンペ
機械学習を始めて一ヶ月経つのでアウトプットとしてSIGNATEの練習問題に取り組んでみました。
【練習問題】銀行の顧客ターゲティング
この内容は、ある銀行においてコールセンター運用を目的として顧客情報や過去のデータなど
18個の変数を元にしてキャンペーンで顧客が口座を開設するかを予測します。
今回の分析に使ったコードはこちらに載せています。
データ数
顧客データ数はサンプルデータが27128件、テストデータが18083件
変数は以下の18個で全て欠損値はありませんでした。変数の意味については以下の通りです。
| 変数 | 意味 |
|---|---|
| id | 通し番号 |
| age | 年齢 |
| job | 職種 |
| marital | 未婚/既婚 |
| education | 教育水準 |
| default | 債務不履行があるか |
| balance | 年間平均残高(€) |
| housing | 住宅ローン |
| loan | 個人ローン |
| contact | 連絡方法 |
| day | 最終接触日 |
| month | 最終接触月 |
| duration | 最終接触時間(秒) |
| campaign | 現キャンペーンにおける接触回数 |
| pdays | 経過日数:前キャンペーン接触後の日数 |
| previous | 現キャンペーン以前までに顧客に接触した回数 |
| poutcome | 前回のキャンペーンの成果 |
| y | 定額預金申し込み有無 |
目的変数の分布
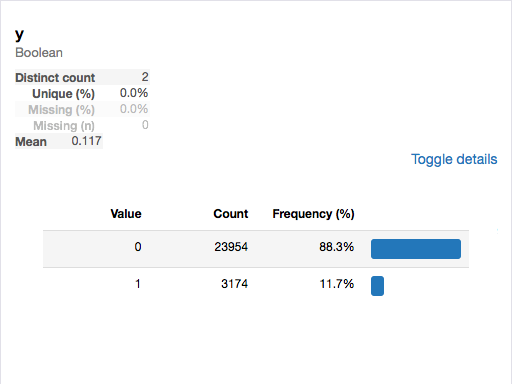
学習データでは口座開設をしなかった人が口座開設者の約8倍であるため、キャンペーンの結果口座開設に至る人は10%程度とやはり低めです。そのためどのような条件の人が口座開設に踏み切っているのかを見極める必要がありそうです。
説明変数の分布
年齢(age)
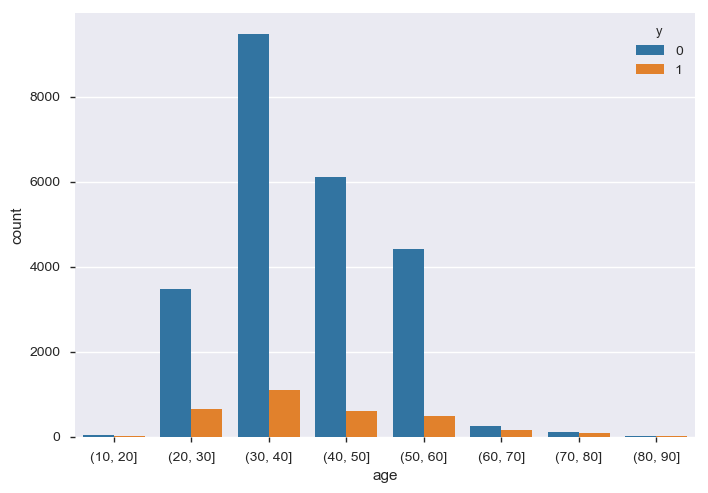
顧客の年齢を10歳刻みで分割しました。ヒストグラムを見ると20~60歳の人の割合が高いことがわかります。一方で20歳以下と60歳以上の人達は顧客数は少ないものの口座開設率は高いことが読み取れます。
また、20歳以下の若者については大学生になりアルバイトを始める際に口座を開設するだろうと考えられるので、職種(job)も含めた分布を見てみます。
# 各年齢、職種に対する口座開設者の割合を求める
# 10歳毎にビニング
age_bining = pd.cut(trainX['age'],list(range(10,100,10))) #trainXは教師データの説明変数
# 各年代の全体数
age_job = pd.crosstab(age_bining,trainX['job'],margins=True)
# 口座開設者を抽出(y=1)
open_account = train[train['y']==1] #trainは教師データ
# 各年代に対して口座開設者(y=1)が何人いるか
age_job_open = pd.crosstab(age_bining,open_account['job'],margins=True)
graph = age_job_open/age_job
graph.index = ['10代','20代','30代','40代','50代','60代','70代','80代','All']
graph
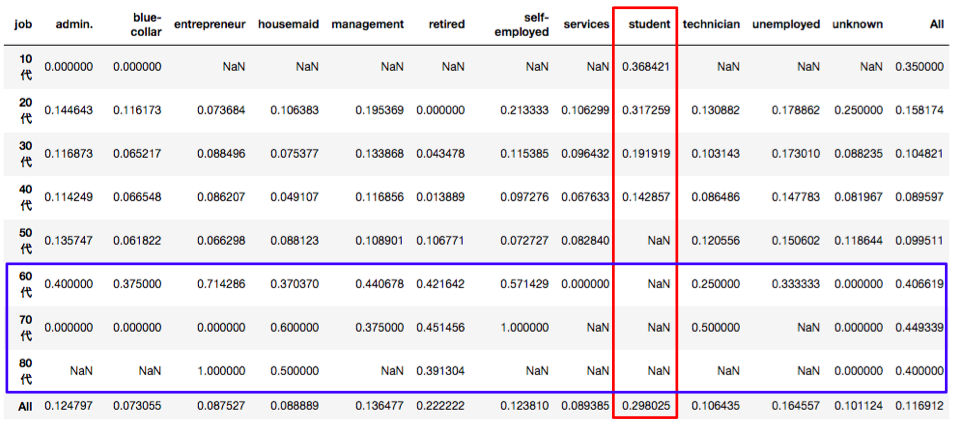
これを見ると30歳以下の人では学生かそうでないかで開設率に大きく差があるようです。特に30歳以下の学生に関しては3割近くが開設するという他の属性と比較すると非常に割合が高くなっています。以上を踏まえて今回は社会人(ここでは60歳以下かつ学生ではない人とする)かそうでないかで分けて考えることにします。
最終接触月(month)
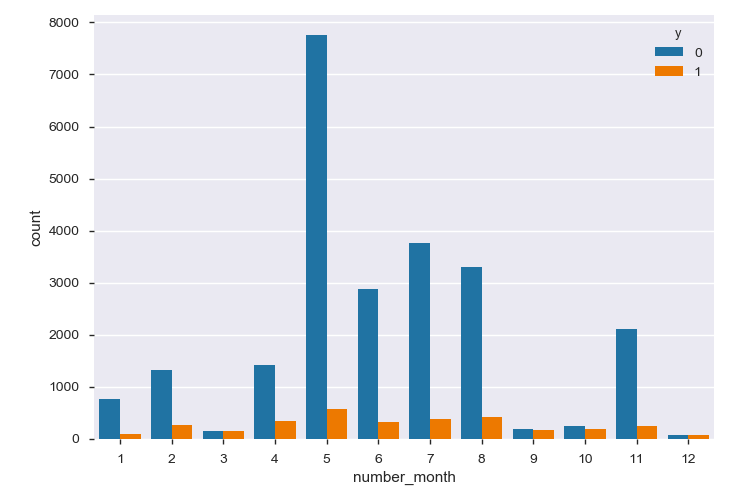
3,9,10,12月は顧客への接触の全体数が少なく、新規顧客の獲得率も高くなっています。日付も含めてもう少し詳しく見てみます。

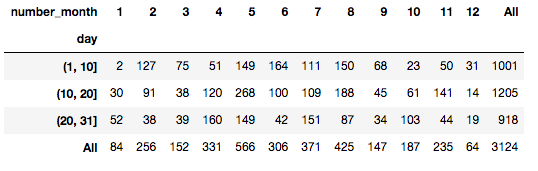
2つの表は1年を36分割(4月上旬など)した時の各ブロックにおける接触顧客数(下図)に対する口座開設者数の割合(上図)を表しています。これを見ると目安として各ブロックの10日間中で顧客への接触数が400件以内の(1日平均40件)場合の口座開設率が高い傾向にあります。確かに1日200件も300件も電話かけてたら疲れてパフォーマンスも落ちますね(笑)
最終接触時間(duration)
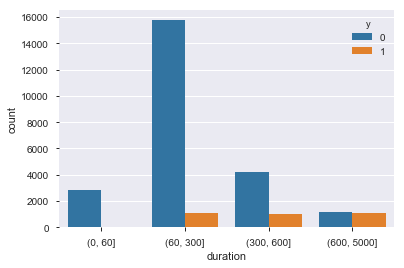
顧客との接触時間を1,5,10分で区切って見るとやはり長い時間話している方が理解を得やすいようです。
1分以内は「あ、そういうのいいです。」
5分以内は「なるほど、ちょっと検討してみます(方便)。」
10分以上「なるほど確かに確かに。」
といったリアクションの違いになるような気がします。
前回キャンペーンで接触してからの日数(pdays)
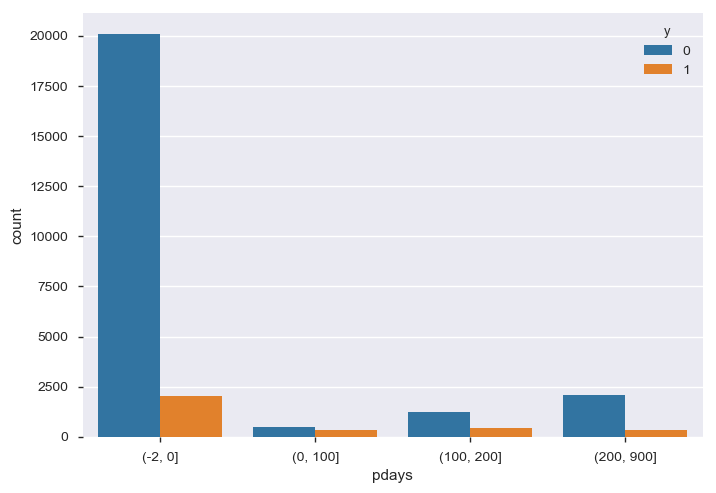
-1とは前回のキャンペーンで接触しなかった人です。前回のキャンペーンから100日以内に再び接触している人が口座開設している傾向にあります。
残高(balance)
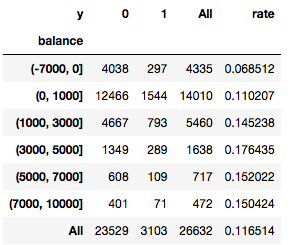
'rate'の行を見ると(顧客数に対して口座開設者の割合)、概ね残高が高いほど口座開設を取り付けられている傾向にあります。
前回キャンペーンの成果(poutcome)
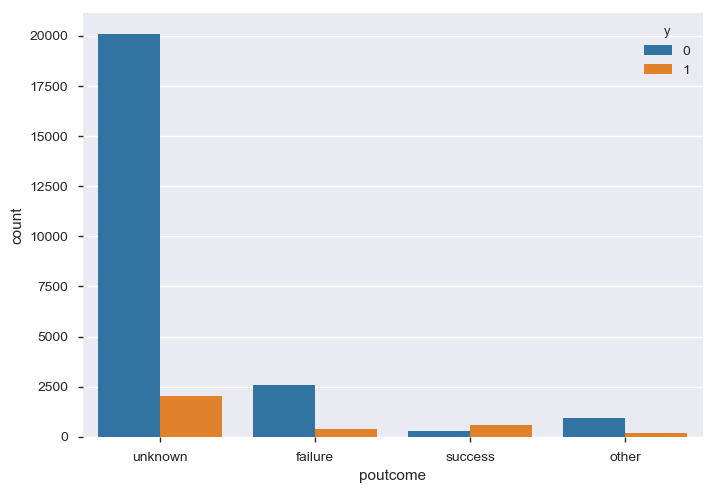
明らかに前回キャンペーンで口座開設してくれた人の方が今回のウケもよく優良顧客としてターゲティングする必要がありそうです。なので前回キャンペーンが成功したかその他かで分けることにします。
前処理
データの可視化を元に以下のポイントで前処理を行いました。
- 学生('student')かその他('not-student')でマッピング
- 日付を上旬(1~10日)、中旬(11~20日)、下旬(21~31日)に分割してシーズン(例えば4月上旬)の接触数全体が少ない(400以下)場合とそうでない場合でマッピング
- 前回キャンペーンの結果は成功かそうでないかで場合分けをする
# 日付を上旬、中旬、下旬に分割
for i in range(0,len(trainX)):
if trainX.loc[i,'day']>=1 and trainX.loc[i,'day']<=10:
trainX.loc[i,'season']='上旬'
elif trainX.loc[i,'day']>10 and trainX.loc[i,'day']<=20:
trainX.loc[i,'season']='中旬'
else:
trainX.loc[i,'season']='下旬'
for i in range(0,len(testX)):
if testX.loc[i,'day']>=1 and testX.loc[i,'day']<=10:
testX.loc[i,'season']='上旬'
elif testX.loc[i,'day']>10 and testX.loc[i,'day']<=20:
testX.loc[i,'season']='中旬'
else:
testX.loc[i,'season']='下旬'
# ○月上旬という変数(allseason)を作る
trainX['allseason'] =trainX['month']+trainX['season']
testX['allseason'] =testX['month']+testX['season']
# ○月□旬の接触人数が400人以上か以下かで場合分け
for i in range(0,len(trainX)):
if trainX['allseason'].value_counts()[trainX.loc[i,'allseason']]<=400:
trainX.loc[i,'allseason'] = 1
else:
trainX.loc[i,'allseason'] = 0
for i in range(0,len(testX)):
if testX['allseason'].value_counts()[testX.loc[i,'allseason']]<=400:
testX.loc[i,'allseason'] = 1
else:
testX.loc[i,'allseason'] = 0
# 学生('student')かその他('not-student')でマッピング
for i in range(0,len(trainX)):
if trainX.loc[i,'job']=='student':
trainX.loc[i,'job']=='student'
else:
trainX.loc[i,'job'] = 'not-student'
for i in range(0,len(testX)):
if testX.loc[i,'job']=='student':
testX.loc[i,'job']=='student'
else:
testX.loc[i,'job'] = 'not-student'
データの取り出し・グリッドサーチ・学習
特徴量は以下の6つを抽出して学習させました。
# 学習に使うデータを用意
parameters = ['student_elder','balance','allseason','duration','pdays','poutcome']
trainX_1 = trainX.loc[:,parameters]
testX_1 = testX.loc[:,parameters]
# ダミー変数化
trainX_1 = pd.get_dummies(trainX_1)
testX_1 = pd.get_dummies(testX_1)
# 不要な変数を落とす
trainX_1 = trainX_1.drop(columns=['student_elder_B','poutcome_failure','poutcome_unknown','poutcome_other'])
testX_1 = testX_1.drop(columns=['student_elder_B','poutcome_failure','poutcome_unknown','poutcome_other'])
また今回はアンサンブル学習であるランダムフォレストを用いて、使用する変数の数と枝の数をグリッドサーチで探索を行いました。
# 調整したいパラメータを指定
param_grid = {'n_estimators': [100],
'max_features': [1,'auto',None],
'min_samples_leaf': [3,4,5,6],
'n_jobs':[-1]}
# グリッドサーチで探索
gcv = GridSearchCV(RFC(),param_grid,cv=5)
gcv.fit(trainX_1,y)
特徴量の重要度を可視化すると以下のようになりました。
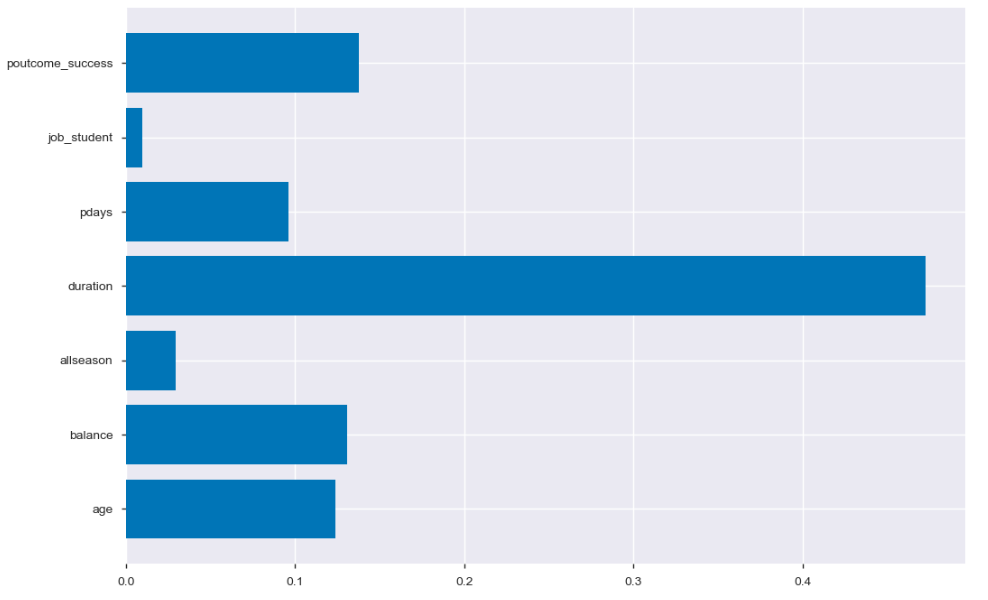
結果としては最も目的変数に影響を与えたのは顧客との接触時間でした。また、新しく作った特徴量はそこまで機能していなかったようです。特に学生か否かの基準がここまで重要度が低いのは年齢に情報が含まれてしまっているということかもしれません。
結果
この学習モデルを使って予測すると0.88881で802/1442位でした。
顧客が口座開設に踏み切るのにもっとも重要な要素は顧客との接触時間でした。やはり一人に時間をかけて営業する方が理解を得られやすいのでしょう。
また今後の顧客のターゲティングを考えると前回キャンペーンで反応のよかった人や残高の多い人にターゲットを絞ることで、「数撃ちゃ当たる」方式ではなく接触数の絶対数を減らして集中的に営業をかけることで効率的にできるのではないでしょうか。
このモデルからコールセンターへの運用を念頭にすると以下の提言ができます。
1.接触を試みる顧客の属性の優先順位は
残高の高い人 > 前回キャンペーン営業が成功した人 > 60際以上の高齢者 > 学生
2.前回キャンペーンを成功している人については100日以内に再度営業をかける
3.ブロック(10日間)の顧客接触数を400件いない程度に抑える
ちなみに最も精度の良い結果が得られたのは
parameters = ['age','balance','month','day','duration','pdays','poutcome_success']
という既存の特徴量を抽出する方法で、この学習モデルを用いると0.92872で290/1428位でした。どうして月日を合わせてはいけないのでしょうか。疑問です。
また、今回は月日のみしかわからなかったので全てのサンプルが同じ年と仮定して曜日も求めてみましたが特徴的な傾向は得られませんでした。
# 試しに月日から曜日を考えてみる
# 年がわからないので絶対的な曜日はわからないが、相対的な曜日関係は掴める(ひとまず2011年と仮定)
import datetime
for i in range(0,len(trainX)):
train.loc[i,'interval'] = datetime.date(2011,train.loc[i,'number_month'],train.loc[i,'day'])- datetime.date(2011,1,1)
train.loc[i,'interval'] = train.loc[i,'interval'].days
train['date'] = train['interval'] % 7
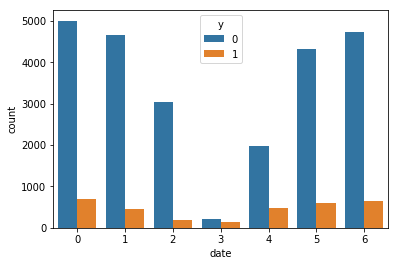
このグラフは仮に2011年として1月1日を基準とした時に顧客の接触月日の曜日が何日分離れているかというグラフです。(例えば2011年1月1日を月曜日とすれば、グラフの3は木曜日)
仮にサンプル毎に年が違うと曜日が変わってきてしまうので例えば土日は数が少ないといった傾向が出てくるかもしれないですね。また年まで分かればがわかれば前回キャンペーンの経過日数(pdays)から過去についても正確に考察することができるのでより情報量を増やせるのではないでしょうか。
今回は時間の関係で出来ませんでしたがもう少し変数を減らせるなら柔軟性の高いSVMも試してみたいです。