概要
AWSのQuickSightでS3に格納したCSVファイルを可視化する方法をまとめていきます。
すでに調べればいろいろと出てくるかと思いますが、とりあえず自分で実施した内容をまとめてみました。
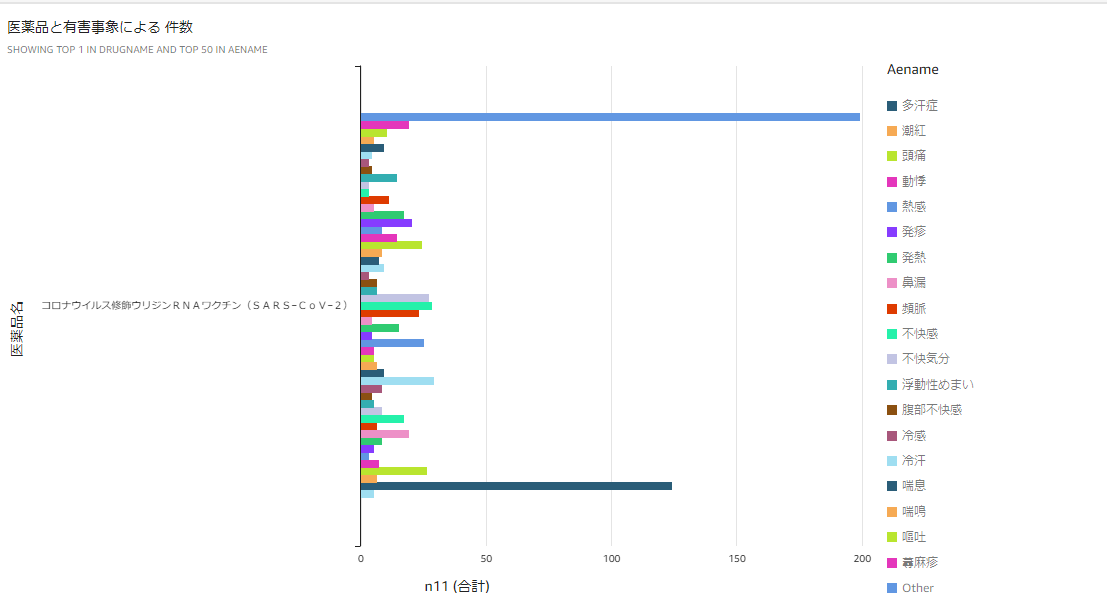
2021年7月のJADERのデータから被疑薬、相互作用の医薬品について一般名と有害事象の関係を事前に計算したファイルを使用しています。
S3バケットの作成
- CSVファイルを格納するS3バケットを作成します。
- ファイルを格納するフォルダも作成してその中にファイルを格納します。
- フォルダを作成しないと後述のAthenaのところでクエリに失敗しました。
- Athenaの結果を格納するバケットも作成します。
AWS Glue
-
AthenaでS3上のファイルにクエリを実行する場合、その情報をカタログに登録する必要があります。そのためまずはGlueを使ってカタログを作成します。
- テーブルを一から作成することも可能ですが今回はクローラーを使います。
-
コンソールからAWS Glueを開いてクローラーの追加を行います。

-
名前は任意に設定します。

-
次の画面ではそのまま次へを押下します。

-
読み込ませたいCSVファイルが入っているパスを選択します。
- フォルダまで選択します。前述したとおりここでフォルダの中にファイルを入れていないと後述のAthenaのところでエラーになります。

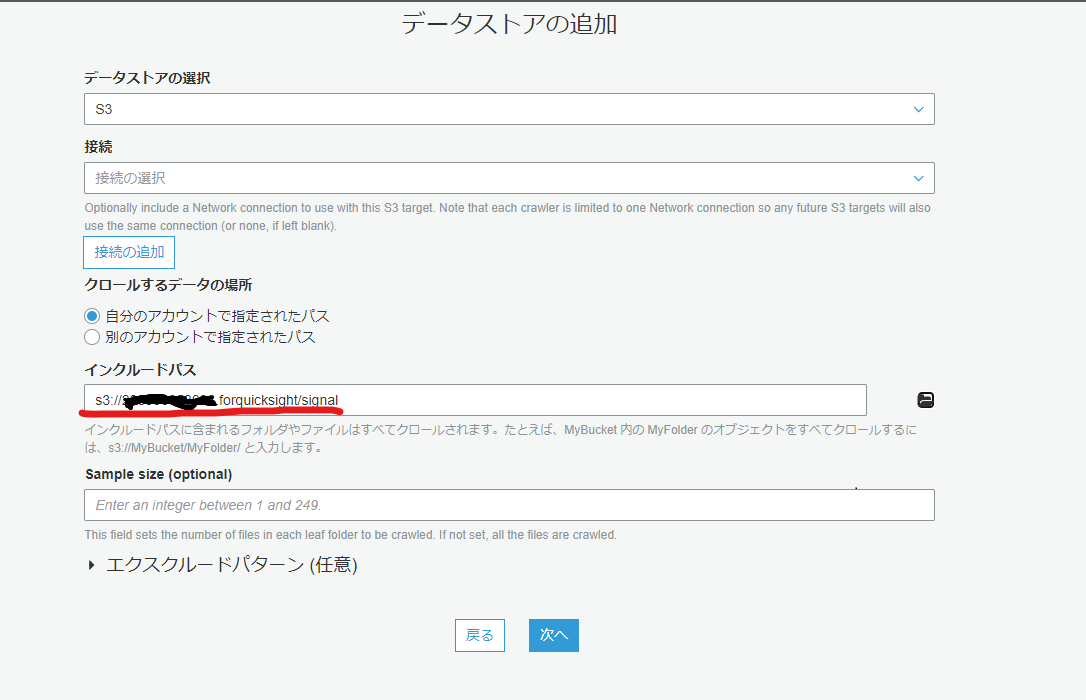
- フォルダまで選択します。前述したとおりここでフォルダの中にファイルを入れていないと後述のAthenaのところでエラーになります。
-
別のデータストア追加の部分はいいえのまま次へ

-
ロールの選択では作成をします。
- 一度作った後既存のロールを使いたくなるかもしれませんが、アクセスするバケットの権限がないとエラーになるので都度作るのがよさそうです。
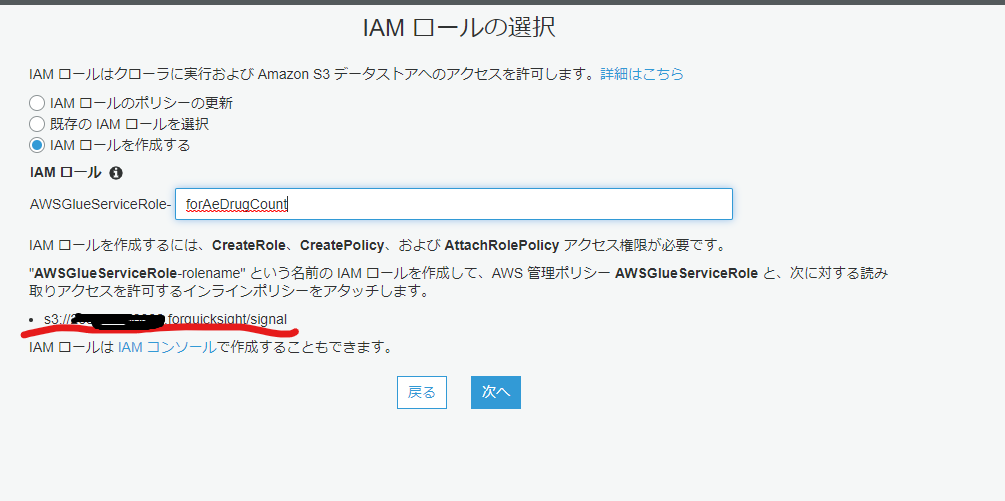
- 一度作った後既存のロールを使いたくなるかもしれませんが、アクセスするバケットの権限がないとエラーになるので都度作るのがよさそうです。
-
クローラのスケジュールはオンデマンドで実行にします。
- 日次など定期的に動かしたいときは状況に合わせて設定します。
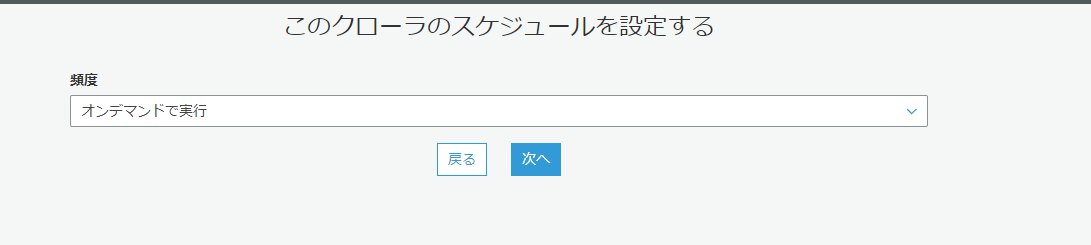
- 日次など定期的に動かしたいときは状況に合わせて設定します。
-
出力先を指定するところでデータベースの追加を押下して任意の名前を設定します。

-
最終的には以下のようになります。


-
作成したクローラを選択してクローラの実行を押下すれば以下のように画面が進みデータを取得します。
- 成功すると追加テーブルに追加された件数が表示されます。
- 失敗した場合はCloudWatchLogsにログが出力されるのでそちらを確認します。
- またCloudTrailにも情報は出るので何かあったらこの弐つを見ましょう。


-
データの型を変更したいときはスキーマの編集を押下して型を変更することができます。

Athena
-
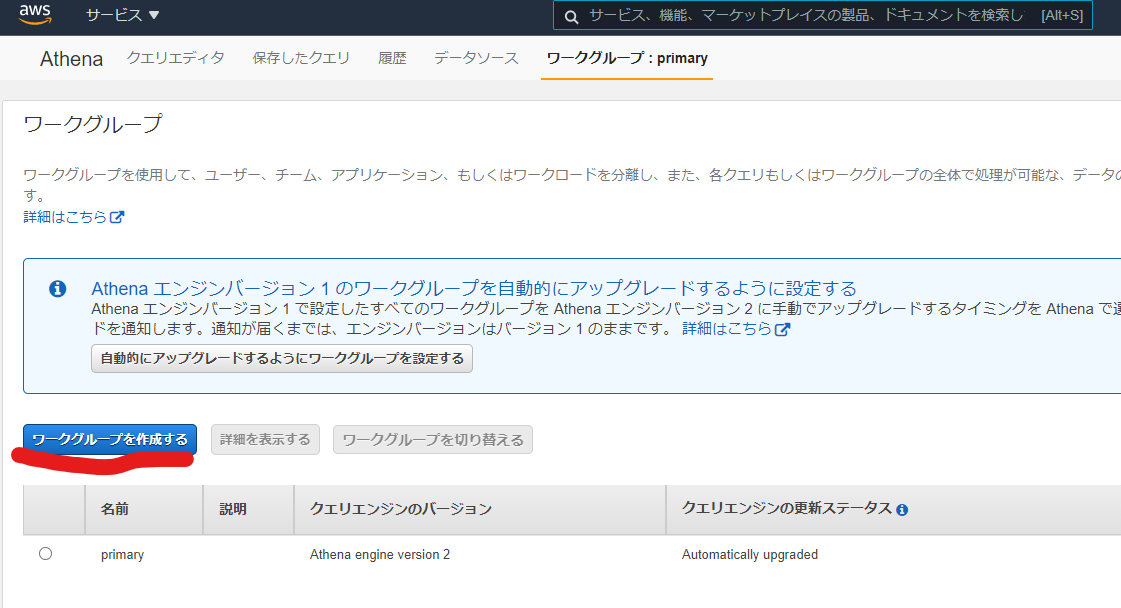
ワークのグループの作成を行います。

-
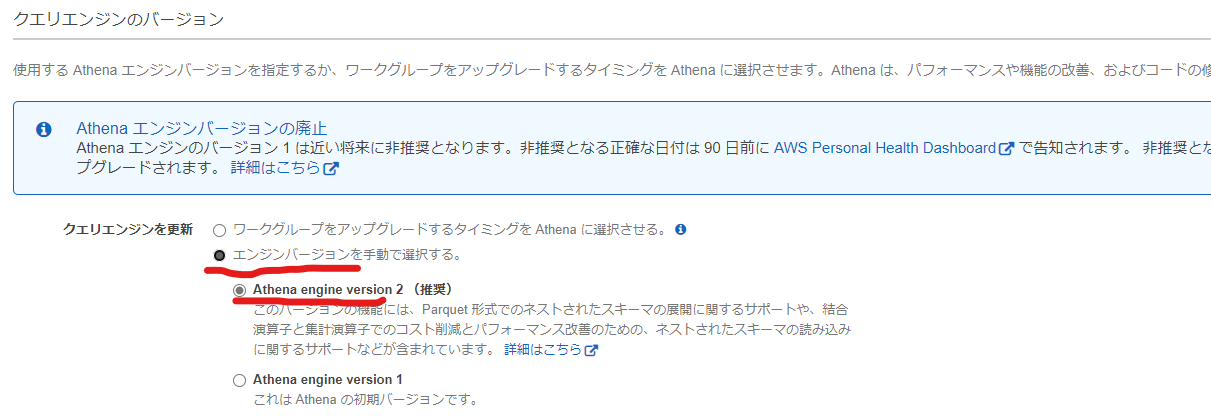
Athena engineはversion2を選択します。
-
作成すると以下のようにワークグループができるのワークグループを切り替えるボタンを押下します。

-
クエリエディタを押下しデータソースはAwsDataCatalog データベースはGlueのところで作成したものを選択します。
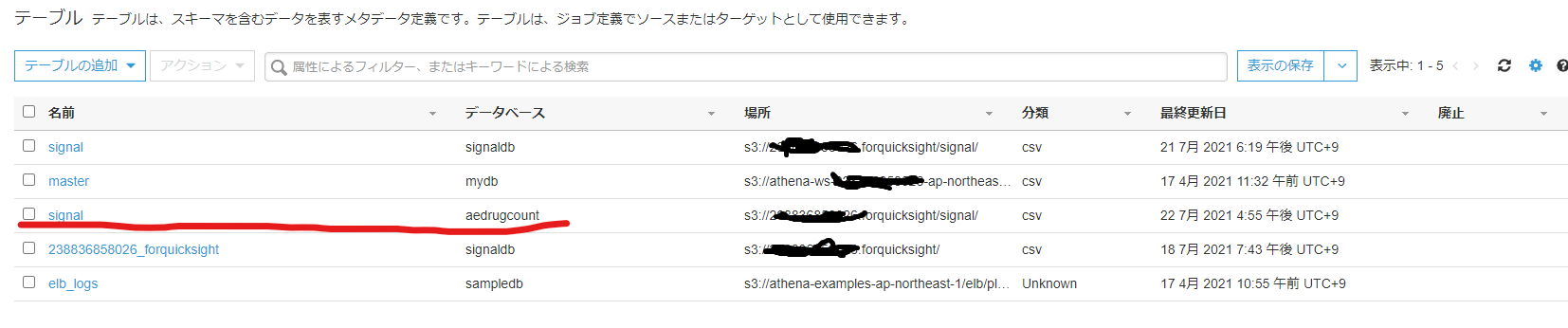
- クローラで読み込んだテーブルが出ることを確認します。
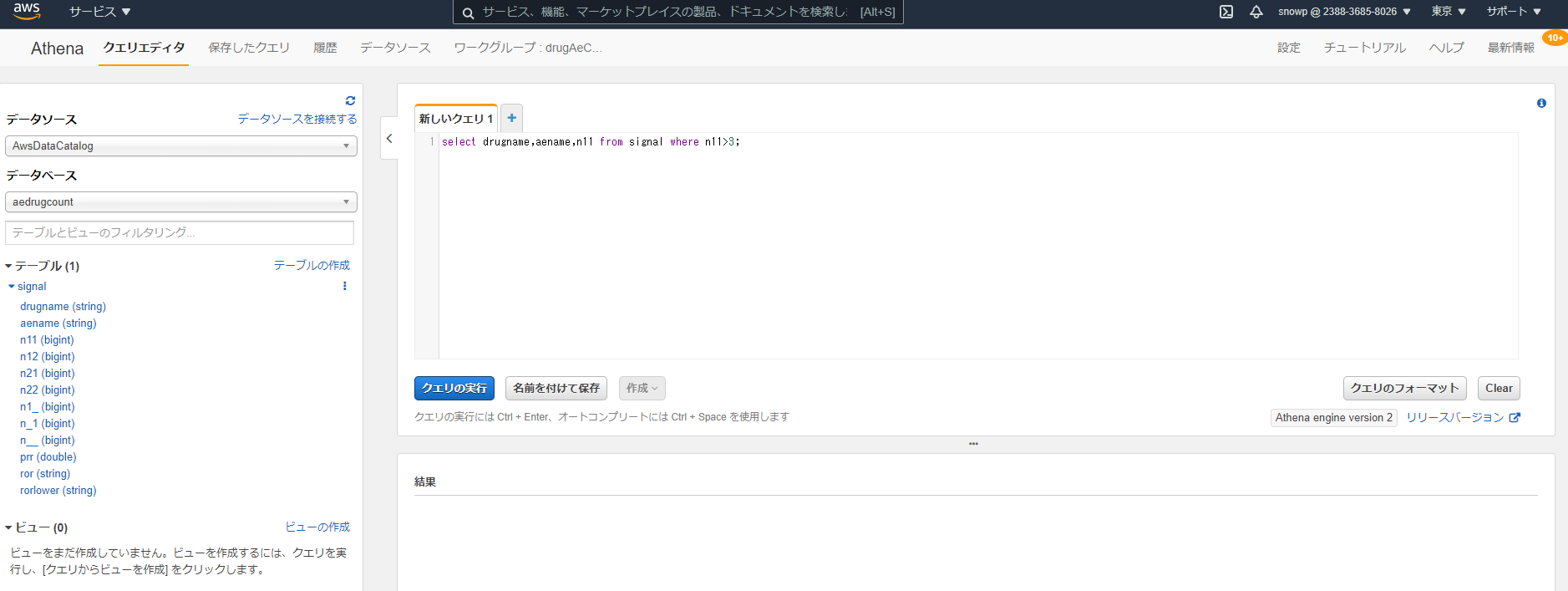
- クローラで読み込んだテーブルが出ることを確認します。
-
クエリのところにはSQLを書けるので抽出したい内容に合わせます。
- 今回は1ファイルだけですが、DynamoDBの内容と結合したり、ほかのファイルと結合するなどRDBのようにjoinなどができます。
- クエリ実行を押下すると以下のように結果がでます。
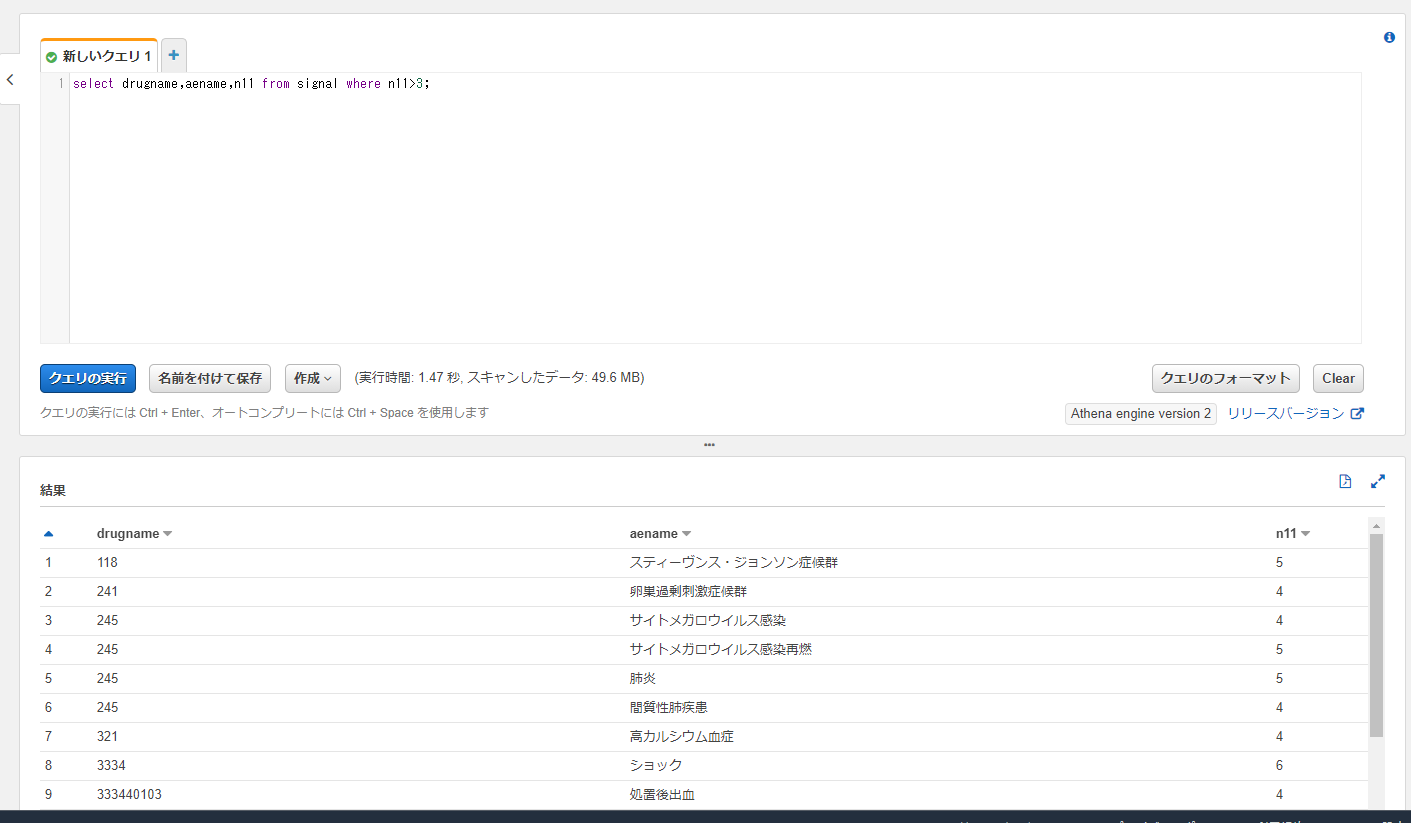
QuickSight
- QuickSightで取り込むと以下のように可視化することができます。
- 今回は棒グラフですが表や円グラフなど用途に応じていろいろ選択できます。
- QuickSightの設定は後日記載予定