はじめに
将棋ウォーズの棋譜情報を取得したい人もいるかもしれないので作ってみる。
あまりよくないかなーと思ったけど、さらに応用して何か作れる人にとっては大した内容ではないと思うので記事にしてみる。
使用は自己責任でお願いします!
サーバに負荷を掛けないように過度な要求は控えましょう!
スクレイピングとは
htmlを解析して、抽出したい情報を集めること。ざっくりこういう意味で合ってるはず。
これ自体は違法ではないけど、AmazonとかXだと明示的に禁止されている。自分の好きなWebサイトに迷惑を掛けない範囲で利用しましょう。
動作環境
EC2 amazon linux 2023ってデスクトップ環境がないので、自分のパソコン(Windows10)から実行する。
(EC2 amazon linux 2023でも出来るんじゃないかなとは思う)
・pythonをインストールする (今の最新は3.12。最新じゃなくても3系ならたぶんOK)
・必要ライブラリselenium と chromedriver_binary をインストールする。以下コマンド
pip install selenium
pip install chromedriver_binary
・google chrome を入れてなければインストールしておく
参考にした記事
起動中ブラウザを使えばなんとかなりそう。
以下の記事を参考にした。
chromeパスは以下だった。
C:\Program Files\Google\Chrome\Application\chrome.exe
chromeのデータがいっぱいできても良い場所は以下とした。
D:\py\syogi_wars\data
Batファイル1
上記記事を参考にして作るBatファイルは以下となった。
Batファイルやpythonプログラムは D:\py\syogi_wars\ の中に置くことにする。
rem ブラウザを全て落とした状態で実行しないと、うまく取れないっぽい!
"C:\Program Files\Google\Chrome\Application\chrome.exe" -remote-debugging-port=9222 --user-data-dir="D:\py\syogi_wars\data"
Pythonプログラム
勢いで書いたプログラム
from selenium import webdriver
import chromedriver_binary
#
import re
import time
import csv
from datetime import datetime
# 将棋ウォーズの自分のID
WARS_ID = 'xxxxx'
# 取得モード 10分 or 3分 or 10秒 のどれかにしてね
WARS_MODE = '3分'
# 現在時刻から何時間前までの情報を取得するか
# 例. 今が19時だとして
# 1 なら 18時~19時
# 24 なら 昨日の19時 ~ 19時
# 0 なら おおよそ30日分全部
TARGET_INTERVAL_HOUR = 24
# 指定戦法のみ取得したい場合のリスト (囲いも同じ扱い。「船囲い」とかも指定できるよ)
#TARGET_TACTICS = [] ← 全指定
#TARGET_TACTICS = ['原始棒銀']
#TARGET_TACTICS = ['原始棒銀', '角換わり棒銀']
TARGET_TACTICS = ['原始棒銀']
# URL関係
WARS_BASE_URL= 'https://shogiwars.heroz.jp/games/history?{}&page={}&user_id={}'
WARS_URL_PART = {
'10分' : 'local=ja',
'3分' : 'gtype=sb',
'10秒' : 'gtype=s1'
}
def main():
wars_infos = []
for i in range(1, 1000):
# 起動時にオプションをつける。(ポート指定により、起動済みのブラウザのドライバーを取得)
# なんか知らんけど2ページ目以降で以下例外が発生するので、オプション設定はfor文の中に入れる
# urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host='localhost', port=xxxxx): Max retries exceeded with url
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(options=options)
# URLを編集して情報取得
target_url = WARS_BASE_URL.format(WARS_URL_PART[WARS_MODE], i, WARS_ID)
print(target_url)
driver.get(target_url)
# 内容解析
info, final = analysis_summary(driver.page_source)
driver.quit()
wars_infos.extend(info)
if final:
break
# 運営に迷惑を掛けてはいけない!!必ずスリープすること!
time.sleep(3)
# csvファイルに書き込み
put_csv(wars_infos)
# 大雑把に解析
def analysis_summary(text):
wars_infos = []
for i, x in enumerate(text.split('<div class="game_category">')):
# 初回ブロックは結果情報ではないので飛ばす
if i == 0:
continue
# 1件分を解析
add_info, chk_tac = analysis_detail(x)
# 時間指定ありの場合は、指定時間より遡ったら終了
if TARGET_INTERVAL_HOUR != 0:
# 今回取得した対局時刻をエポック秒にする
date_object = datetime.strptime(add_info['対局日時'], "%Y/%m/%d %H:%M")
target_seconds = int(date_object.timestamp())
# 終了判定エポック秒の計算(指定時間を引く)
epoch_seconds = time.time() - TARGET_INTERVAL_HOUR * 3600
if target_seconds < epoch_seconds:
return wars_infos, True
# 戦法フィルタが指定されていて、今回取得した戦法の中に1つもない場合は対象外
if TARGET_TACTICS:
if not any(element in chk_tac for element in TARGET_TACTICS):
continue
# リストに追加
wars_infos.append(add_info)
# 最後か判定(最後のボタンがないということは、そのページが最後)
final = False
if not '最後' in text:
final = True
return wars_infos, final
# 1件分を解析
# memo : ごちゃごちゃしそうなので、引き分けの判定してない!(笑) どっちもloseになるみたいよ
def analysis_detail(text):
print('解析中...')
teban_chk = 0
tactics = '' # 戦法の格納文字
chk_tac = [] # 戦法フィルタチェック
text_lines = text.splitlines()
for i, x in enumerate(text_lines):
# 対局時刻
if '<div class="game_date">' in x:
wk = text_lines[i+1] # 次行が対局時刻
# 直近の時刻は以下のような表記なので括弧の前後を取る
# 例. 5時間前 (2024/05/12 11:20)
if '(' in wk:
wk = wk.split("(")[1].strip()
wk = wk.split(")")[0].strip()
battle_date = wk.strip()
if 'player"' in x:
teban_chk += 1
wk = text_lines[i+2] # 2行先にプレイヤー情報
if not ' ' + WARS_ID in wk:
rival_player = wk.strip()
# 勝敗
pattern = f'player.*{WARS_ID}'
if re.search(pattern, x):
if '"win_player"' in x:
result = '勝ち!' # 一覧で見易いように!をつける
else:
result = '負け'
# 手番 (先に表示されるのが先手)
if teban_chk == 1:
teban = '先手!'
else:
teban = '後手'
# 戦法
if 'hashtag_badge"' in x:
wk = x.split('>#')[1].strip()
wk = wk.split('</a>')[0].strip()
chk_tac.append(wk)
if tactics:
tactics += '、'
tactics += wk
# 自分IDのURL
if "appAnalysis('" in x:
wk = x.split("'")[1].strip()
wars_url = 'https://shogiwars.heroz.jp/games/' + wk
# 他人IDのURL
if 'a href="/games/' in x:
wk = x.split('a href="/games/')[1].strip()
wk = wk.split('?')[0].strip()
wars_url = 'https://shogiwars.heroz.jp/games/' + wk
add = {
'対局日時' : battle_date,
'結果' : result,
'手番' : teban,
'相手' : rival_player,
'戦法' : tactics,
'URL' : wars_url
}
return add, chk_tac
# 取得結果をcsvファイルに出力する
def put_csv(wars_infos):
if TARGET_INTERVAL_HOUR:
save_interval = str(TARGET_INTERVAL_HOUR) + '時間'
else:
save_interval = '最大時間'
# 保存名称は現在時刻、取得モード、フィルタ戦法、取得件数から決める
if TARGET_TACTICS:
combined_tactics = "_".join(TARGET_TACTICS)
else:
combined_tactics = '全戦法'
now = datetime.now()
save_name = now.strftime(f'%Y年%m月%d日_%H時%M分%S秒_{save_interval}_{WARS_MODE}切れ負け_{combined_tactics}_{len(wars_infos)}件.csv')
# CSVファイルに書き込み
with open(save_name, 'w', newline='', encoding='utf_8_sig') as csvfile:
fieldnames = ['対局日時', '結果', '手番', '相手', '戦法', 'URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in wars_infos:
writer.writerow(row)
if __name__ == "__main__":
main()
Batファイル2
上記pythonプログラムを実行するBatファイルも作る。実行する人がなるべく楽なように
rem batファイルがあるフォルダへ移動してから実行
cd /d %~dp0
python wars_scraping.py
pause
フォルダ構成
つまりフォルダ構成はこんな感じ
実行してみる!
Batファイルのコメントにも書いたけど、chromeが起動している状態で実行するとうまく取得できないときがある。よく分からない。まとめると以下手順
① chromeをいったん全部終了する
② wars_scraping1.batを実行してchromeを起動させる
③ 起動したブラウザを操作して、将棋ウォーズのWebサイトにアクセスしてログインする
(初めて起動するときだけ)
④ wars_scraping2.batを実行して少し待つ
同じフォルダの中にcsvファイルが出来た!
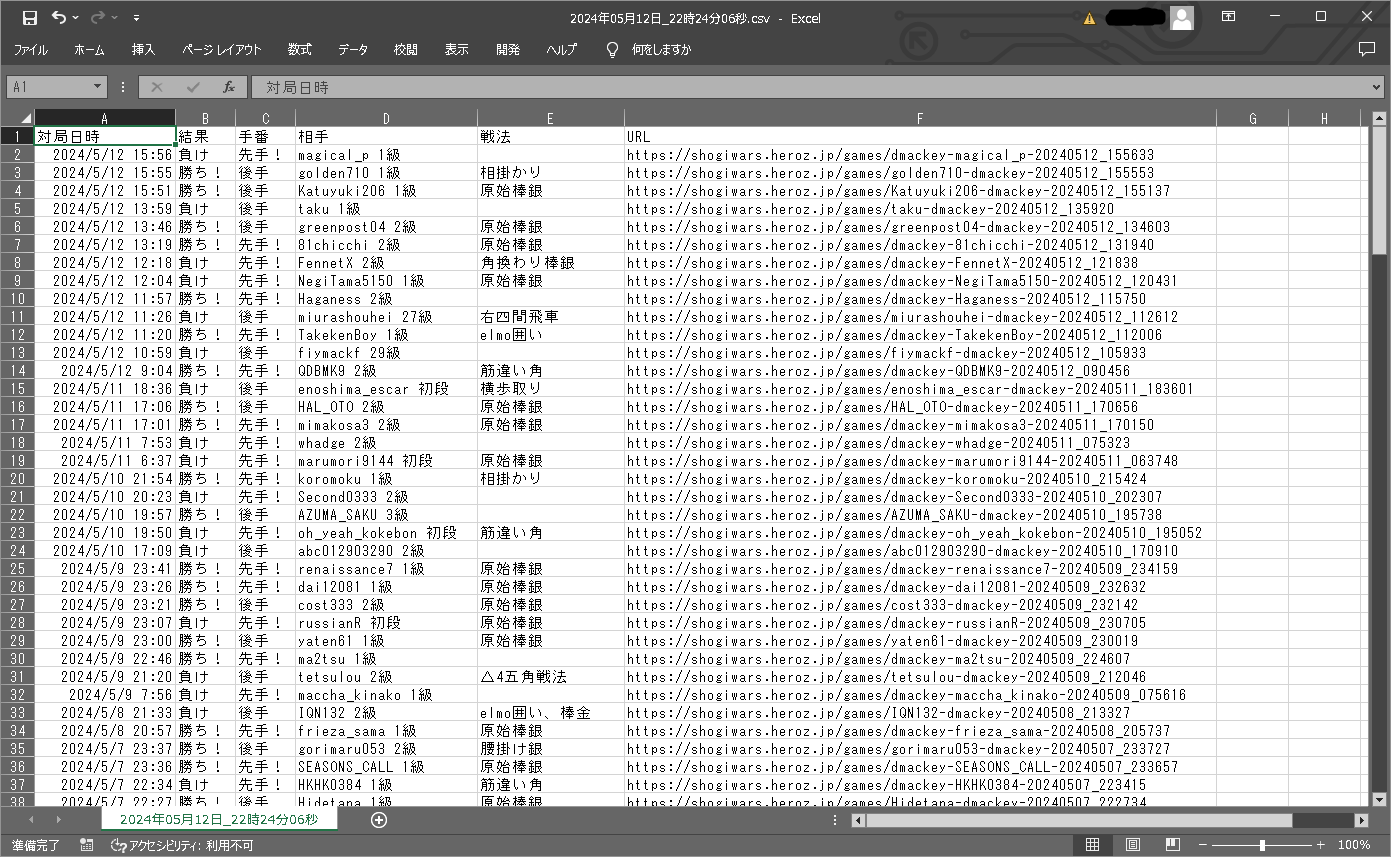
出力するcsvファイルの名前
実行時刻_取得範囲_対戦モード_戦法_取得件数.csv
をファイル名称にしてみた。後で気付いたけど、戦法じゃなくて囲いも同じ扱いだった。。
戦法より、「エフェクト」が正しい気がする。まあいっか
プログラムの中で指定するもの
・自分の将棋ウォーズID
・10分切れ負け or 3分切れ負け or 10秒切れ負け
・現在時間から何時間分を取得したいか
・戦法リスト
Windows以外で動かしたいとき
Batファイルの書き方は違うと思いますが、やってることは簡単だと思います!
pythonのプログラムはたぶんそのまま動くと思います!
応用
AWS EC2やGoogle GCPなどのクラウドサーバーを用意すれば完全自動化も出来るとは思う。
ブラウザを入れればいいだけだろうから
追記. 全期間取得バージョン
よーく観察してみると、ちょっと変えたら全局取得できた。
前との違い
・時間ではなく何か月分を取得するかを指定する
・戦法フィルタはしない
・引き分け判定もちゃんとする
当然、遊んだ回数が多いと10分とか20分とか時間が掛かる。「戦法でフィルタして2回実行」するより「全局取得した結果をgrepするなどして戦法でフィルタする」 の方が短時間で済むので戦法フィルタは無くした。あとWebサイトへの負担も減るしね
from selenium import webdriver
import chromedriver_binary
#
import re
import time
import csv
from datetime import datetime
# 将棋ウォーズの自分のID
WARS_ID = 'xxxxx'
# 取得モード 10分 or 3分 or 10秒 のどれかにしてね
WARS_MODE = '3分'
# 何か月分を取得するか
# 例. 今月のみ ⇒ 0, 今月と先月 ⇒ 1, 全部 ⇒ 999(=80年以上)
WARS_GET_MONTH = 999
# URL関係
WARS_FIRST_URL= 'https://shogiwars.heroz.jp/games/history?{}&page={}&user_id={}'
WARS_BASE_URL= 'https://shogiwars.heroz.jp/games/history?{}&is_latest=false&month={}&page={}&user_id={}'
WARS_URL_PART = {
'10分' : 'local=ja',
'3分' : 'gtype=sb',
'10秒' : 'gtype=s1'
}
def main():
# 対局履歴の初回ページをスクレイピングして、遊んだ年月インデックスを取得
play_months = first_scraping()
wars_infos = []
for play_month in play_months:
for i in range(1, 1000):
# 起動時にオプションをつける。(ポート指定により、起動済みのブラウザのドライバーを取得)
# なんか知らんけど2ページ目以降で以下例外が発生するので、オプション設定はfor文の中に入れる
# urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host='localhost', port=xxxxx): Max retries exceeded with url
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(options=options)
# URLを編集して情報取得
target_url = WARS_BASE_URL.format(WARS_URL_PART[WARS_MODE], play_month, i, WARS_ID)
print(target_url)
driver.get(target_url)
# 内容解析
info, final = analysis_summary(driver.page_source)
driver.quit()
wars_infos.extend(info)
if final:
break
# 運営に迷惑を掛けてはいけない!!必ずスリープすること!
time.sleep(1)
# csvファイルに書き込み
put_csv(wars_infos)
# 対局履歴の初回ページをスクレイピングして、遊んだ年月インデックスを取得
def first_scraping():
# 起動時にオプションをつける。(ポート指定により、起動済みのブラウザのドライバーを取得)
options = webdriver.ChromeOptions()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(options=options)
target_url = WARS_FIRST_URL.format(WARS_URL_PART[WARS_MODE], 1, WARS_ID)
print(target_url)
driver.get(target_url)
# プルダウンメニューの年月部分取り出し
html_src = driver.page_source
html_src = html_src.split('表示する月を選択</option>')[1].strip()
html_src = html_src.split('</select>')[0].strip()
driver.quit()
# 遊んだ月をリストにする
play_month = []
for i, text_line in enumerate(html_src.splitlines()):
if '勝' in text_line or '負' in text_line:
wk = text_line.split('"')[1].strip()
play_month.append(wk)
# 指定月回数に終わったら抜ける
if i >= WARS_GET_MONTH:
break
# 運営に迷惑を掛けてはいけない!!必ずスリープすること!
time.sleep(1)
return play_month
# 大雑把に解析
def analysis_summary(text):
wars_infos = []
for i, x in enumerate(text.split('<div class="game_category">')):
# 初回ブロックは結果情報ではないので飛ばす
if i == 0:
continue
# 1件分を解析
add_info, chk_tac = analysis_detail(x)
# リストに追加
wars_infos.append(add_info)
# 最後か判定(最後のボタンがないということは、そのページが最後)
final = False
if not '最後' in text:
final = True
return wars_infos, final
# 1件分を解析
def analysis_detail(text):
print('解析中...')
teban_chk = 0
draw_chk = 0
tactics = '' # 戦法の格納文字
chk_tac = [] # 戦法フィルタチェック
text_lines = text.splitlines()
for i, x in enumerate(text_lines):
# 対局時刻
if '<div class="game_date">' in x:
wk = text_lines[i+1] # 次行が対局時刻
# 直近の時刻は以下のような表記なので括弧の前後を取る
# 例. 5時間前 (2024/05/12 11:20)
if '(' in wk:
wk = wk.split("(")[1].strip()
wk = wk.split(")")[0].strip()
battle_date = wk.strip()
if 'player"' in x:
teban_chk += 1
wk = text_lines[i+2] # 2行先にプレイヤー情報
if not ' ' + WARS_ID in wk:
rival_player = wk.strip()
# 勝敗
pattern = f'player".*{WARS_ID}'
if re.search(pattern, x):
if '"win_player"' in x:
result = '勝ち!' # 一覧で見易いように!をつける
else:
result = '負け'
# 手番 (先に表示されるのが先手)
if teban_chk == 1:
teban = '先手!'
else:
teban = '後手'
if '"lose_player"' in x:
draw_chk += 1
# 戦法
if 'hashtag_badge"' in x:
wk = x.split('>#')[1].strip()
wk = wk.split('</a>')[0].strip()
chk_tac.append(wk)
if tactics:
tactics += '、'
tactics += wk
# 自分IDのURL
if "appAnalysis('" in x:
wk = x.split("'")[1].strip()
wars_url = 'https://shogiwars.heroz.jp/games/' + wk
# 他人IDのURL
if 'a href="/games/' in x:
wk = x.split('a href="/games/')[1].strip()
wk = wk.split('?')[0].strip()
wars_url = 'https://shogiwars.heroz.jp/games/' + wk
# どちらも負けなら引き分け
if draw_chk == 2:
result = '引き分け'
add = {
'対局日時' : battle_date,
'結果' : result,
'手番' : teban,
'相手' : rival_player,
'戦法' : tactics,
'URL' : wars_url
}
return add, chk_tac
# 取得結果をcsvファイルに出力する
def put_csv(wars_infos):
save_month = str(WARS_GET_MONTH) + 'か月分'
# 保存名称は現在時刻、取得モード、取得件数から決める
save_name = datetime.now().strftime(f'%Y年%m月%d日_%H時%M分%S秒_{save_month}_{WARS_MODE}切れ負け_{len(wars_infos)}件.csv')
# CSVファイルに書き込み
with open(save_name, 'w', newline='', encoding='utf_8_sig') as csvfile:
fieldnames = ['対局日時', '結果', '手番', '相手', '戦法', 'URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in wars_infos:
writer.writerow(row)
if __name__ == "__main__":
main()
10分切れ負けの全局取得
3744件の情報を取得できた。実行時間は覚えてないけど・・20~40分くらいかな??
実行中にBatから起動したchromeを使うと結果がおかしくなっちゃうので、chromeを使いたいときはデスクトップに置いてある普段のchromeを使う。
おわりに
ID名には級位も表示されているので、自分の情報も出力すればいつ昇級したか分かることに後から気付いたけどもういいや!(笑)
あと、1手1手の棋譜情報も取得 ⇒ ソフト解析 ⇒ -1000点以上の悪手を自動通知
とかも頑張ればできそう。大変そうなのでやらないけど。
角換わり棒銀って、表記は「角換わり棒銀」なのに加藤先生が写っている画像の中では「棒銀」なのに気付いて驚愕している。棒銀って角換わりが前提なのか・・? 不一致はこれだけ?なんか歴史的な理由があるんだろうか・・