2024年9月、IBMの音声認識サービスであるWatson Speech to Text (STT) にて、これまでの前世代・次世代モデルとは大きく異なるLSMモデルがリリースされました。
今回はこのLSMモデルを実際に試し、STTのポイントであるカスタム機能についても勘所をつかんでみましたので共有します。
また、後日公開予定の記事では、このカスタム機能を更に楽に利用する方法についても共有したいと思います。
Watson STTとは
IBM Watson Speech to Text (STT) は、企業独自のデータによるカスタマイズ機能をそなえた音声認識サービスです。
ポイントはなんと言ってもカスタマイズ機能です。ベースとなる音声認識モデルをカスタマイズすることで、従来は書き起こしが難しかった言い回しや特定業務の用語、特定製品名への対応など、さまざまな業務要件に適応することができます。

→ STTのカスタマイズ機能の詳細については、既に他の方が執筆されたQiita記事がございますのでそちらをご覧下さい。
参考例:https://qiita.com/ishida330/items/ecdaf246022c8e2cb1a4
STTのLSMモデル
2024年9月、IBMはWatson STTの新たなモデルとして、LSM (Large Speech Model) モデルの日本語版での正式リリースを発表しました。
参考:https://www.ibm.com/blogs/solutions/jp-ja/watson-speech-to-text-new-japanese-next-generation-telephony-model/
このモデルの特徴は、LLMにも用いられているTransformerアーキテクチャを採用していることです。大量の音声データで学習することで、高い精度での書き起こしを実現します。
IBMが英語モデルで実施した比較では、OpenAI Whisperと比較しても、特に短文での誤認識率 (単語誤り率) が低く、優秀な結果を残しています。
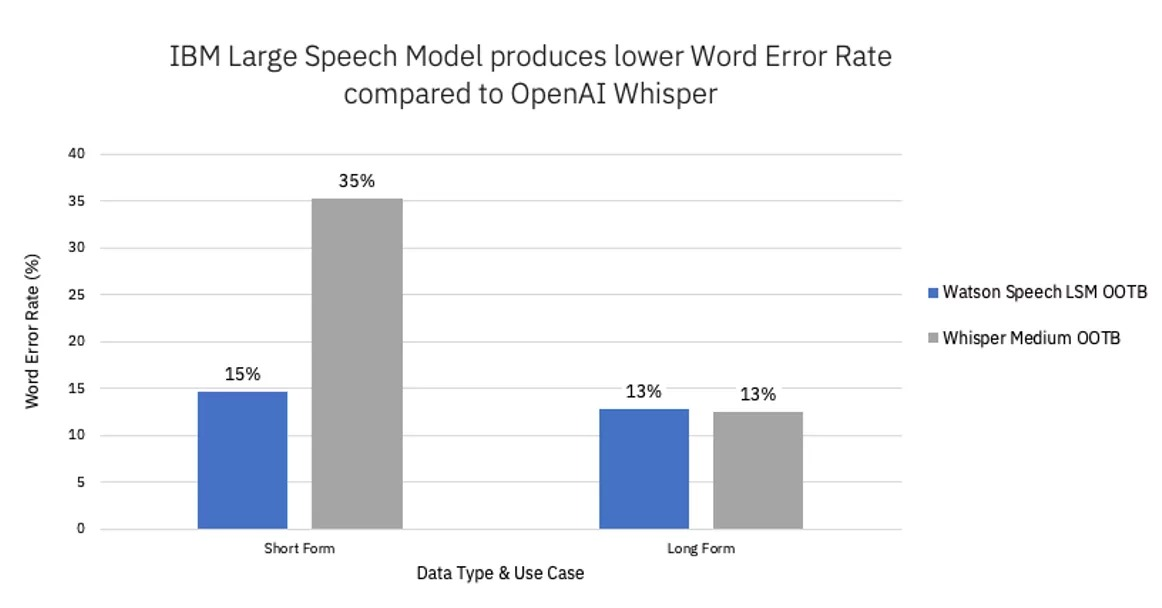
画像引用元:https://www.ibm.com/new/announcements/ibms-new-watson-large-speech-model-brings-generative-ai-to-the-phone
上記の結果では、長文ではあまり差が付いていないように見えますが、ポイントはSTTのモデルが軽量かつ動作もサクサクである点です。上記ブログ時点ではモデルサイズが約5分の1でありながらWhisperと同程度、または上回る性能を出している、と言及されています。
実際、Transformerアーキテクチャがベースとは言っても、課金形態は今まで通りの従量課金で、お値段は据え置きの1分あたり$0.02です! (月100万分未満の場合)
そしてカスタマイズ機能にはコスト不要です。更に本機能はファインチューニングのように大がかりなものでは無く、規模にもよりますが数分程度で終わりますので、非常にお手軽に書き起こしやカスタマイズをお試しできます。
https://cloud.ibm.com/catalog/services/speech-to-text
これまでのモデルから大きく変わった点として挙げられるのが、発話環境の違いなどへの対応力が上がったことです。従来、音質の違いによってモデルも2つに分かれていましたが、LSMでは単一のモデルでこれらの違いに対応出来るようになりました。
同様の理由から、カスタマイズ方式としては「文書登録」「単語登録」だけとなり、音響モデルのカスタムは無くなりました。あくまでユーザーは文書・単語レベルでのカスタムに集中するだけで良くなり、これまでよりチューニングポイントが明確になったと言えます。
LSMの挙動はどうなの?
(本項はIBM公式の見解では無く、個人の見解となります)
従来、Watson STTの日本語モデルの挙動としては、「ベースのままでの判定性能はそこそこ、文章 (コーパス) や単語を辞書でカスタムすると大幅に個別ケースでの認識性能が上がる」というものでした。
LSMモデルでは、この基本特性は踏襲しつつ、ベースでの性能が上がっているようです。
具体的なデータの追加例などについては公表されていないようですが、日本語における固有名詞のデフォルト辞書の拡充などによって、表現力が上がっているようです。
とはいえSTTの肝はモデルのカスタムです。以下、カスタムにおける具体例とその勘所を見ていきます。
LSMモデルをカスタムするための勘所 〜文書登録と単語登録の使い分け〜
カスタムの前提
一般的には、STTにおける文書登録ならびに単語登録によるカスタムは、以下の様な効果が得やすいと言われています。
- 文書登録は、文脈ならびに新しい単語を学習し、特定の場面や表現に寄せる (確率を上げる)
- 単語登録は、新しい単語の読み方や表記を正確に定義し、書き起こしの解像度を高める
具体的な改善例
そんなLSMモデルですが、やはり最大限性能を引き出すには文書ならびに単語の辞書を登録し、カスタムした上で個別業務へ特化させて利用するのが良さそうです。
STTのカスタマイズ方式とその用途は以下の様に分類されるのですが、これは実際にはどう読み解けばいいのでしょうか?それぞれ実例で確認してみたいと思います。

特有の用語 (製品名称など)
製品名称などの固有名詞などを解釈させる場合、音声認識の観点では大きく2パターンに分かれます。
固有名詞が、全く新しい言葉である場合 (もしくは一部に全く新しい言葉を含む場合)
例えば、
Aspera (アスペラ)
というIBM製品がありますが、これは英語や日本語には存在しない単語のため、「アスペラ」という言葉を含む音声をSTTに読み込ませた場合、事前に学習されていない限りは、
「アスペラ」「明日ペラ」などと表記されてしまい、単語としては認識できず書き起こしが出来ない可能性があります。
→ これを正しく「Aspera」と認識させたい場合には本項のようなチューニングが必要です。
結論:
このような場合、文書登録 + 単語登録の両方を行うのが有効です。
- 文書登録: そもそも「Aspera」という表記が文章中に登場し、どのような文章構造の場合にこの単語が登場するのか、というチューニングに有効。
- 単語登録:「アスペラ」という読みの言葉が読まれた場合、これを「Aspera」と表記される確率を高める、とチューニングするのに有効
→ これらを合わせて、「アスペラ」という音声を「Aspera」と表記することが出来るようにチューニングされます。
固有名詞が、一般名詞から構成される複合語の場合
例えば、
WebSphere
というIBM製品がありますが、これは
Web + Sphere
という、一般名詞を一語としただけの複合語です。STTのモデルは、そもそも一般名詞は学習していますので、何もチューニングしなくても
「web sphere」もしくは「ウェブ スフィア」
のように書き起こされることは期待できます。しかし、これは一般名詞として各単語を認識しているに過ぎません。
→ 表記の観点で「WebSphere」という製品名に寄せたい場合には本項のようなチューニングが必要です。
※ 一般名詞に加えて、アルファベット1文字の組み合わせで構成される場合もこれに含まれます。
例えばSPSS (エスピーエスエスと発音) のように、SPSS = S + P + S + Sとアルファベット1文字ずつを構成要素とする場合も、本項の一般名詞の複合語として考えられます。
結論:
このような場合、文書登録 + 単語登録の両方を行うのが有効です。
- 文書登録: 文字を書き起こす際、デフォルトでは「ウェブ」「スフィア」で単語を切るのが最適だと判断されてしまうが、そうではなく「ウェブスフィア」をまとめて一語として認識して欲しい、というチューニングに有効。
- 単語登録:文書登録のおかげで「ウェブスフィア」という読みの言葉がある、と認識できるようになるが、これを「WebSphere」と表記してほしい、とチューニングするのに有効
→ これらを合わせて、「ウェブスフィア」という音声を「WebSphere」と表記することが出来るようにチューニングされます。
特有の言い回し
STTの活用例においては、日本語の表現には含まれるものの、平均的な会話では登場しない言い回しを書き起こしたい場面があります。例えば「もしもし」という言葉は、日本語としては聞きなじみがある表現ではあるのですが、通常の会話では出てこない表現です。
しかし、もしコールセンターにおける書き起こしであれば、この表現が必然的に使われることになりますので、この書き起こしに寄せる (確率を上げる) 必要があります。
結論:
このような場合、文書登録を行うのが有効です。
文書登録: 文字を書き起こす際、「もしもし」という表現が通常より登場しやすく、書き起こしを寄せていく (確率を上げる)、というチューニングに有効。
同音異義語
例えば「登場する」「搭乗する」という単語は、いずれも日本語の会話の中で普通に登場する言葉です。ただ、例えば航空企業における会議の書き起こしであれば、「搭乗する」という単語のほうが頻出のはずであり、過去の会議の文脈などを元に、単語の登場確率などをデフォルトから更新する必要があります。
結論:
このような場合、文書登録を行うのが有効です。
文書登録: 文字を書き起こす際、過去の文脈を学び、「搭乗する」という表現が通常より登場しやすく、書き起こしを寄せていく (確率を上げる)、というチューニングに有効。
注意点:チューニングをしたモデルでは、必然的に「搭乗する」に書き起こされる確率が上がります。ただ、専門性が求められない会話 (例えば航空業務に関わらない会議) の書き起こしなど、全ての場合の書き起こしに使ってしまうと回答が不必要に寄せられてしまう可能性があります。
→ このような場合には、モデルを複数作成し使い分ける、などの工夫が必要です。(チューニングが万能薬という訳ではない)
住所の聞き取り
結論:
LSMでは、ある程度日本の住所の書き取り性能が上がっているため、デフォルトのままでも書き起こしが出来る可能性があります。ただ、そのままで書き起こしがうまくいかない場合、文書登録 + 単語登録が有効です。
- 文書登録: 文字を書き起こす際、特定の住所が登場する文脈や新しい住所を単語として学び、その表現に寄せていく (確率を上げる)、というチューニングに有効
- 単語登録:文書登録のおかげで特定の住所が登場する文脈・単語を認識できるようになるが、これを正しい住所表記で表記してほしい、とチューニングするのに有効
発話スタイル
例えば会議の書き起こしと一口に言っても、お客様との打ち合わせでは「ですます調」、社内のくだけたミーティングでは「〜ですよね」など、語尾が変わるようなケースがあります。とくにくだけた会話の場面では、これらをチューニングする必要があります。
結論:
このような場合、文書登録を行うのが有効です。
- 文書登録:文字を書き起こす際、過去の文脈を学び、例えばくだけた表現などが通常より登場しやすく、書き起こしを寄せていく (確率を上げる)、というチューニングに有効
注意点:同音異義語のケースでの注意点同様、異なる発話スタイルの会議を一つのモデルで書き起こしすると、チューニングが逆効果となる可能性があります。このような場合、やはりモデルを複数作成し使い分ける、などの工夫が必要です。(チューニングが万能薬という訳ではない)
方言
例えば関西弁などにおいては、「〜やねん」「こそばい」などの固有の単語があります。これらは表現によってはデフォルトで判定できるものもあるのですが、平均的には登場確率が低いため書き起こし精度が低い可能性があります。また、マイナーな方言についてはそもそも書き起こし出来ない可能性があります。
結論:
このような場合、文書登録 +辞書登録を行うのが有効です。
- 文書登録:文字を書き起こす際、過去の文脈を学び、方言が通常より登場しやすく、書き起こしを寄せていく (確率を上げる)、というチューニングに有効
- 単語登録:方言の中には新規に定義される単語が含まれる可能性があります。これらの単語の表記を正しく示すためのチューニングに有効
まとめ
Watson STTのポイントはチューニング機能ですが、その機能を使いこなすにはいくつかのポイントもあります。ぜひ本記事をご参考いただければ幸いです。