
当記事、要は(TL;DR;)
STTのカスタマイズ・デモのためにお客様のWebサイトからScrapyでテキスト一式ぶっこ抜いたんだけど
- WebサイトをSTTのテキスト・コーパスの入力にするなら、色々と考慮点があるよ
- 例えばスクレイピング後のコーパスでは無効な文字のチェックをしたほうがいいよ
- カスタム用語のリストを作るのが目的ならjanomeやExcelで用語の抽出作業を効率化できるかもよ
てなことが書いてあります。
はじめに(背景)
こんにちわ!石田です。先般、あるお客様にWatson Speech to Textをデモする機会がありました。どうせなら「素」のSTTではなく少しはお客様のドメインの用語を学習させたほうがいいだろう、と思いましたがPOCほど「がっつり」ではないので本格的なコーパスをもらうわけにもいきません。ということで、セカンダリー・ベストとしてお客様のWebサイトからテキストを抜いてコーパスとしてSTTに学習させ、すこし賢くしようと思いました。で、あれこれやってみて学んだことが当記事のネタです。
STTカスタマイズの前提知識
具体的なカスタマイズの方法は以前 ![]() 「WatsonのSpeech To Text(STT)をカスタマイズすれば「俺のSTT」を作れるよ」という記事にしましたのでよろしければご参照ください。1
「WatsonのSpeech To Text(STT)をカスタマイズすれば「俺のSTT」を作れるよ」という記事にしましたのでよろしければご参照ください。1
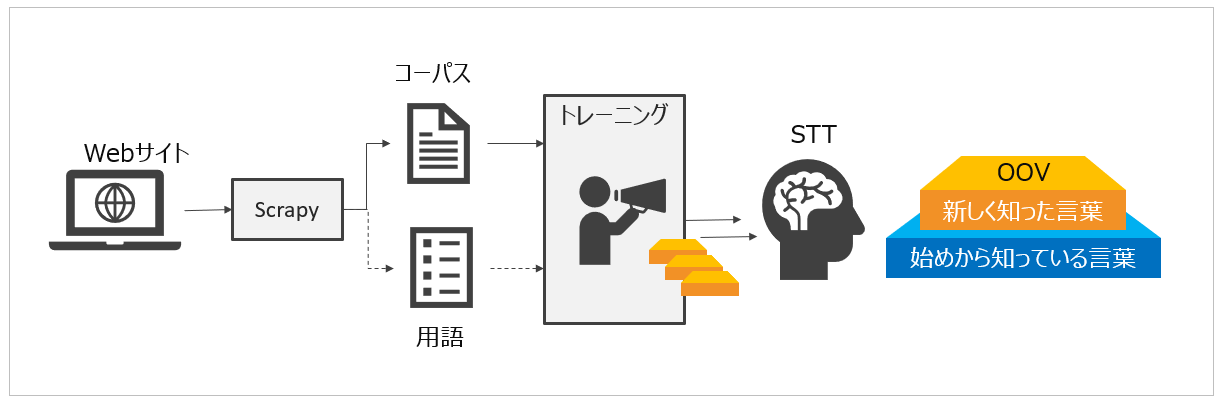
STTのカスタマイズは大きく言語モデル と音響モデルの2つの方法で行えます。さらに言語モデルをカスタマイズする際の入力は**コーパス(corpora)と用語(words)**があります。2 STTのカスタム言語モデルにコーパスやカスタム用語を入力してトレーニングすることにより「STTが今まで知らなかった単語(OOV)3」を理解できるようにするわけです。 なおコーパスとカスタム用語の使い分けですが、推奨はコーパス(文章)です。ただ、それでも認識がイマイチだったり、独特の発音のため認識されなかったり、という場面をカスタム用語で補完するって感じです。( カスタム用語の場合は「読み方」と「表記」の両方を指定するので、より正確な認識ができるのです)
以下、ドキュメントの一部抜粋をお示しします。
コーパス(corpora): カスタム言語モデルに単語を取り込む手段として推奨されるのは、1 つ以上のコーパスをモデルに追加することです。 コーパスを追加すると、サービスがそのファイルを分析し、検出した新しい単語を自動的にカスタム・モデルに追加します。 コーパスをカスタム・モデルに追加することで、サービスはコンテキストに応じて分野に固有の単語を抽出でき、書き起こし結果の改善に役立ちます。
個別の単語(Individual words): 個別のカスタム単語を直接モデルに追加することもできます。 サービスはコーパスまたは文法で検出した単語を追加する場合と同じように、単語をモデルに追加します。 単語を直接追加すると、複数の発音を指定し、単語の表示方法を示すことができます。 また、既存の単語を更新して、コーパスまたは文法から抽出された定義を変更したり、拡張したりできます
単語の追加方法に関わらず、サービスはカスタム言語モデルに追加したすべての単語をモデルの単語リソースに格納します。
コーパス(Corpora)
コーパスはテキストのファイルで一文=1行の形式が望ましいです。文字起こしのテキストなどがあるとベストです。STTの言語モデルは一般的な日本語の学習が済んだ状態で提供されていますが、お客様の会社名・製品名などの固有名詞やビジネス・ドメインでの専門用語など、STTが知らない単語がたくさんありますので、それらを教え込むための入力としてコーパスを使います。以下、ドキュメントのコーパス作成のガイドライン的な記述の抜粋をお示しします。
 [コーパス・テキスト・ファイルの準備](https://cloud.ibm.com/docs/services/speech-to-text?topic=speech-to-text-corporaWords&locale=ja#prepareCorpus)
[コーパス・テキスト・ファイルの準備](https://cloud.ibm.com/docs/services/speech-to-text?topic=speech-to-text-corporaWords&locale=ja#prepareCorpus)
コーパス・テキスト・ファイルを準備するには、以下のガイドラインに従ってください。
- プレーン・テキスト・ファイルに非 ASCII 文字が含まれている場合は、UTF-8 でエンコードされたファイルを用意します。 このサービスはそのような文字を検出すると、UTF-8 エンコードされたものと想定します。
- コーパス・テキスト・ファイルの文字エンコードを確認してください。 サービスはテキスト・ファイルで検出したエンコードを保持します。 カスタム言語モデルで単語を処理する場合は、このエンコードを使用する必要があります。 詳しくは、文字エンコードを参照してください。
- コーパス内の単語には、一貫性のある大文字化を使用してください。 単語リソースでは大/小文字が区別されます。 大文字と小文字を混ぜて、大文字化は意図する場合にのみ使用します。
- コーパスのそれぞれの文を 1 行に含め、各行を復帰で終了します。 複数の文を同じ行に含めると、正確度が低下する可能性があります。
- 個別の行で個人名を不連続ユニットとして追加します。 個別の行で名前の単語を個別のカスタム単語として追加したり、コーパスの同じ行に複数の名前を含めたりしないでください。 次のサンプルは、3 つの名前の認識の正確度を向上させる正しい方法を示しています。
Gakuto Kutara
Sebastian Leifson
Malcolm Ingersol
可能な場合は、Doctor Sebastian Leifson や President Malcolm Ingersol などの追加のコンテキスト情報を含めます。 すべての単語と同様に、可能な場合は名前を異なるコンテキストで複数回複製すると、認識の正確度を向上させることができます。- タイプミスに注意してください。 サービスでは、タイプミスは新しい単語と見なされます。 モデルをトレーニングする前に修正しない限り、サービスによりタイプミスがモデルの語彙に追加されます。 Garbage in, garbage out! (信頼できないデータからの結果は信頼できない) という格言を忘れないでください。
文が多いほど、正確度が高まります。 ただし、サービスはモデルのすべてのソースからの単語数の合計を最大 1,000 万語、OOV 語を 9 万語に制限します。
[コーパス・ファイル追加時の動作](https://cloud.ibm.com/docs/services/speech-to-text?topic=speech-to-text-corporaWords#parseCorpus)
日本語の解析
- すべての文字が全角文字に変換されます。
- 各数字はそれに対応する単語に変換されます。例えば、**500 は 五百 になり、**0.15 は 〇・一五 になります。
- 記号を含むトークンは対応するストリングに変換されません。例えば、100% は 百% になります。
- 句読点は自動的に削除されません。 IBM では、アプリケーションが口述筆記ベースではなく書き起こしベースである場合は句読点を削除することを強くお勧めします。
カスタム用語(Words)
コーパスを用いたカスタマイズだけでは精度が不足したり誤認識する場合に、それを補完・訂正するために使います。お客様の会社名・製品名・社内用語・略語などの(主に)固有名詞を正しく認識させるための調整で使うことが多いです。カスタム用語は以下のような形式のJSONファイルとして与えます。
用語辞書はこんな形のjsonファイルです4
{"words":[
{"word":"AI","sounds_like":["エーアイ"],"display_as":"AI"},
{"word":"凸版印刷","sounds_like":["トッパンインサツ"],"display_as":"凸版印刷"}
]}
やったこと・学んだこと
Webサイトからのテキスト抽出
とにかくテキスト全部、ぶっこ抜く方法
当記事はScrapyのご紹介ではないので具体的な説明は省きますが、今回は以下のようにScrapyを使って特定のページのh1~h5やpタグ、aタグなどからテキストを一気に抜きました。結果、各タグのテキスト群はPythonのリストとしてScrapyのPipelineのクラスにそのまま渡ります。「コーパスは一文=一行が望ましい」のでPipeline側ではリストの各要素を一文としてファイルに書き出しました。
# -*- coding: utf-8 -*-
import scrapy
from urls.items import UrlsItem
class UrlSpiderSpider(scrapy.Spider):
name = 'url_spider'
allowed_domains = ['www.ibm.com']
start_urls = ['https://www.ibm.com/jp-ja']
def parse(self, response):
l = response.xpath('//h1/text()|' \
'//h2/text()|' \
'//h3/text()|' \
'//h4/text()|' \
'//h5/text()|' \
'//p/text()|' \
'//a/text()|' \
'//span/text()').getall()
yield UrlsItem(
url=response.url,
text=l
)
for href in response.xpath('//a/@href').getall():
if "/jp-ja/" in href:
yield scrapy.Request(response.urljoin(href), self.parse)
- 一つの要素内に複数の文章を含む場合もあるので、その場合はPipelineのロジックにて「。」で区切ってさらに分割します
(例)<p>~~~~。~~~~。~~~~~~~。</p> - 逆に1つの文章が複数の要素に分割されている場合もありますが、そこをうまく連結するロジックが作れないのでそのまま放置しました
(例)<p>~~~~</p><p>~~~~</p><p>~~~。</p>
Webサイトは書き言葉。STTは話し言葉。
アタリマエなんですが、Webサイトは固い書き言葉が中心ですが、STTは発話をテキスト化するので話し言葉が中心です。Webサイトのテキストは話し言葉ではまず出てこないような表現・表記にあふれています。そういう意味で、そもそもWebサイトのテキストって話し言葉のためのコーパスとして向いているのかな?という素朴な疑問があるといえばあります。(とはいえ固有名詞やドメインの専門用語にあふれているので、勿論意味はありますけれど。要はそこにギャップがあるってことは意識しておきましょう、って話です。)
Webサイトの文字や表記は話し言葉では出てこないもの多し
Webサイトのテキストでは以下のような表現・表記は普通ですが、話し言葉の文字起こし(変換)では、まずでてきません。
- 日本語と英語のちゃんぽん(例. 英語の製品名を含む記述など)
- 話し言葉の文字起こしではまず出てこない文字
- 箇条書きのための「・」
- 発言を示す「」(カッコ)
- メインタイトルとサブタイトルを繋ぐ「-」(ハイフン)
- ①②③+*〒℡などの特殊な文字
- 修飾のための線
- 絵文字・顔文字
STTはコーパス追加時に有効な文字をチェックしている
STTでのコーパスの追加はAPI的にはadd_corpusでファイルを追加してtrain_language_modelでトレーニングを行いますが、「UTF-8ならいいんでしょ」ということでスクレイピングした結果のテキストから不適な文字を除去せずにそのままadd_corpusに入力したら、train_language_modelで以下のようなエラーになりました。具体的なルールは公開されていないのですが、文字のチェックをしているようです。
ApiException: Error: Fix errors in the following words:
[①, ①②, ①②⑤, ①②⑤⑧, ①③, ①⑥, ②, ②③, ②③④, ②⑥, ③, ③④, ④, ④⑤, ④⑥, ⑤, ⑥, ⑦, ⑦⑧, ⑧, ⑧⑨, ⑨,
んー, オーバーレイー, ソリューションー, ンー, 一号ー, 三ー, 九号ー, 保険ー, 十号ー, 可能性ー, 同盟ー, 変動ー, 編ー, tー]
before training, Code: 400 , X-global-transaction-id: b7253fbf61f5a6098878fa47dee086ac`
これらはUTF-8としては有効な文字ですが、ユーザーの実際の発話からの書き起こしでは、まず出てくるはずのない文字と言えます。(①や②は明白ですね。「ー」は「アー」のような長音としてはSTT的に有効です。引っかかっているのは「メインタイトルーサブタイトル」のようなパターン。さらにややこしい事情として、「ー」は様々な文字コードのものがあったり、元のファイルには「三ー」という表現が存在しないので少しずつ絞り混んでいったら電話番号の3-の部分が全角変換されてメッセージに出力されていたり、元々のページ上の「手」という漢字のUTF-8コードが日本語のX'E6898B'ではなくて康煕部首のX'E2BCBF'であったり、、単に「引っかかったらエディターのchange allで直す」では済まない事情があります)
Webサイト上のテキストにどんな文字が含まれているか、はまったく保証がありません。よって今回はScrapyのpipelineクラスで「一文字ずつチェックしてひらがな・カタカナ・英数字・CKJ統合漢字以外の文字は空白に置換する」ことにしました。またドキュメントでの推奨に従い、句読点も除去しました。
import re
"""
想定した範囲の文字ならOK 想定外ならSTTのチェックに引っかかるので空白にする
https://note.nkmk.me/python-re-regex-character-type/
https://sites.google.com/site/michinobumaeda/misc/unicodecodechars
"""
def check_range(c):
"""
U+3040..U+3093 -> ひらがな
U+30A0..U+30FF -> カタカナ
U+4E00 - U+9FFF -> CKJ統合漢字
"""
p = re.compile('[\u3041-\u3093|\u30A0-\u30FF|\u4E00-\u9FFF|a-zA-Za-zA-Z|0-90-9|。]')
if p.fullmatch(c):
return c
else:
return " "
また長音ハイフンかどうかの判定は一文字前を保管しておき、チェックしました。(同時にハイフンの文字を統一)
"""
長音のハイフンはOKだが、タイトルの後ろにあるハイフンなどはSTTのチェックに引っかかるので空白にする
https://qiita.com/ryounagaoka/items/4cf5191d1a2763667add
"""
def check_hypen(c, save_c):
if c in ("ー","―","‐","-","-"):
char_list = "アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホ" \
"マミムメモヤイユエヨラリルレロワイウエヲガギグゲゴザジズゼゾダジヅデド" \
"バビブベボパピプペポォュェャァィ"
# 直前の文字がカタカナなら長音なのでオーケー
if save_c in char_list:
return "ー"
# そうでないなら空白にする
else:
return " "
else:
return c
サイトのヘダー、フッターの除外
Webサイトには通常、ヘダーやフッターにメニュー項目があります。これらを抜いてしまうと数が多くてややこしいので、スクレイピング時にできるだけ除外しました。一般用語が多いでしょうからカスタムのコーパスという意味で不適ですし、出現回数の多い用語は重要と見なされてしまうので、そのような誤解を回避する意味もあります。(「お問い合わせ」/「プライバシー」/「ご利用条件」/「アクセシビリティ」/「フィードバック」といった言葉はそのドメインで重要でしょうか?)
そのサイト、実はキーワードや短文と画像の羅列で、長いきちんとした文章が少ないかも
Webサイトはサイトの性質や目的によってはトップから数レベルはインデックス的な役割=見出しと短文程度しかない場合も多いです。その場合はそもそものコーパスとなるべき文章があまり抜けない、てなこともありえます。今回はIBMさんの日本サイトをスクレイピングしてみたのですが、メインのサイトは製品名やキーワードと画像から構成されているページが多く、実際のがっつりした文章は結構少ないことに気が付きました。(ScrapyのDEPTH_LIMITの設定をもっと大きくしないとダメだったかな。。実際の本文はpdfになってたりする場合もあり。) もちろん、サイトの目的や性格にもよるので一概には言えませんが。(IBMさんでもdeveloper系のサイトや製品ドキュメントのKnowledge Centerとかはがっつり文章あります)
カスタム用語について
前述しましたが、基本、コーパスを入れれば未知の単語(OOV)を抽出してくれるはずですが、認識がイマイチだったり、独特の発音のため認識されなかったり、という場面ではカスタム用語が威力を発揮します。で、Webサイトからお客様固有の用語、特に固有名詞を抜く方法として、形態素解析エンジンの利用を思いつきました。janome(や mecab) などのエンジンでは文章をパースできますが、その中に固有名詞を識別する機能があります。よってコーパスを一文づつパースして品詞が固有名詞かどうかを判定すれば、用語の候補を作れると思いました。
from janome.tokenizer import Tokenizer
t = Tokenizer()
noun = {}
i_all = "./ibm.txt"
o_words = "./words.txt"
with open(i_all, "r", encoding="utf-8") as f_in, \
open(o_words, "w", encoding="utf-8") as f_out:
while True:
line = f_in.readline()
if not line:
break
# 辞書登録候補の用語(固有名詞)を抜き出す
for token in t.tokenize(line, stream=True):
if token.part_of_speech.split(',')[0] == "名詞":
if token.part_of_speech.split(',')[1] in ("固有名詞", "組織名", "地名", "人名"):
k = token.surface
if k in noun:
noun[k] += 1
else:
noun.update({k: 1})
for k, v in noun.items():
f_out.write(k + "," + str(v) + "\n")
結果、以下のようなCSVができるので、あとはExcelで並べ替えなど駆使しつつ取捨選択して形を整えます。
IBM,3955
PC,61
オムロン,10
Watson,518
クラウド・コンピューティング,181
アナリティクス,203
コマース,189
...
たとえばこんな感じで整えました。
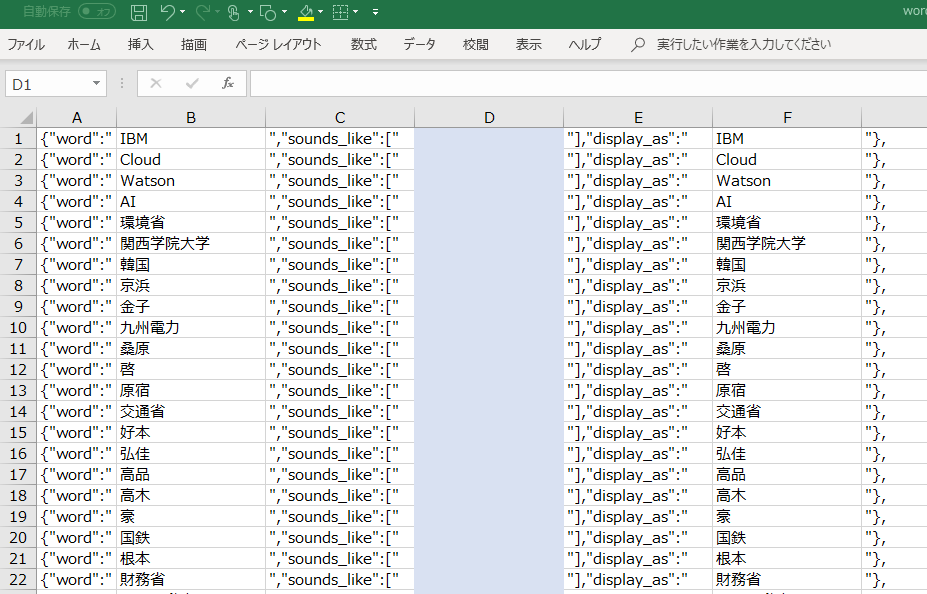
あとはsounds_likeに読み仮名(カタカナ)を入れればいいわけですが、手で入れるのは大変です。ここで普通にExcelで読み仮名を振る方法を検索するとPHONETIC関数がヒットしますが、これってデータを手で入力した場合に使えるものであり、コピペや今回のようにCSVから直読みした場合には(元々のフリガナがないので)使えません。でもこの方の記事はじめ、Application.getphoneticをユーザーfunctionとしてVBAマクロ化する方法がありまして、これを使うと読み仮名を組み立ててくれます
Function getphonetf(a)
getphonetf = Application.getphonetic(a)
End Function
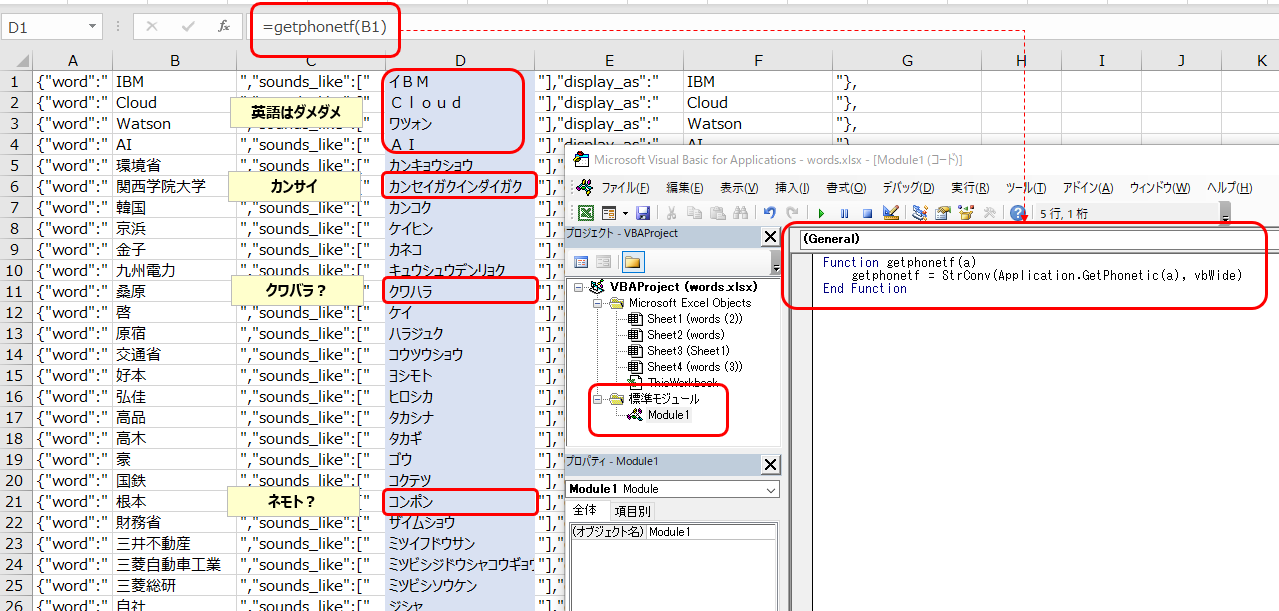
VBAマクロ getphonetfを登録してセルの該当箇所から関数として呼び出せばカタカナがセットされます。(ただし例でもわかるように完全ではないのでチェックは必要です)

最終的にはExcelをテキストにコピペしてTabを空白に置き換えて整形すれば上記のようなカスタム用語登録要のjsonが手に貼ります。
トレーニングの起動について
最初、例外メッセージの意味が???だったので書いておきます。
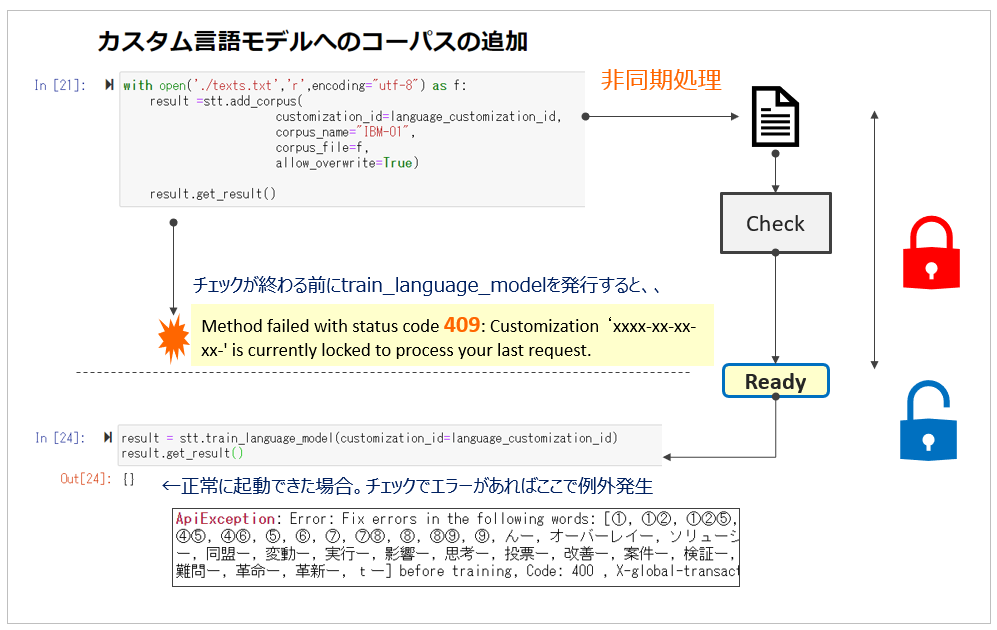
コーパスのトレーニングはAPIでadd_corpusにてファイルを追加してからtrain_language_modelでトレーニングを起動しますが、コーパスが大量の場合、アップロードおよび内容のチェックに数分~数十分の時間がかかります。add_corpusは非同期APIなので裏でモデルをロックして、アップロードとチェックの処理を進めつつ、制御自体はすぐに返ってきます。トレーニングをJupyter Notebookで行っている場合等は、すぐにtrain_language_modelを発行できますが、前の処理が終わるまではモデルはロックされているため、409のエラーになります。もし409が返った場合はしばらくお待ちください。なお、add_corpusは逐次化が必要であり、一度に1つしか実行できません。(=同一のカスタム・モデルに対して同時に複数のadd_corpusは実行できません)
Method failed with status code 409: Customization ‘xxxx-xx-xx-xx-' is currently locked to process your last request.
トレーニングの評価について
STTのにおける言語モデルのカスタマイズの評価は突き詰めれば「(事業ドメインに適した)知らない単語をいくつ覚えさせたか?」ですが、list_corporaのout_of_vocabulary_wordsの数字で判断できます。
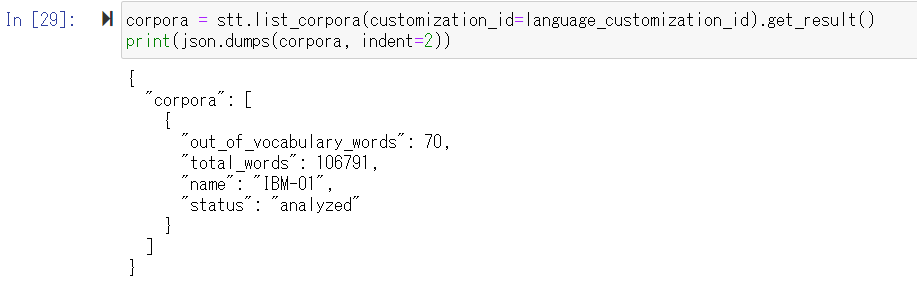
ちなみに単語のほうはlist_wordsで見られます。
以上です。1つでも皆様のお役に立つ情報があったらうれしいです。Enjoy STT !