
こんにちわ!石田です。たまたま仕事でSTTのカスタマイズの機会があって、Qiitaの記事をみたら「STT入門」的なものは多いけれど、カスタマイズの方法に具体的に言及しているものは割と少なかったので、いまさらながら記事にしました。「AKB関連の発言や用語だけは異常な高精度で認識するSTT」でも「ドリルすな/せんのかいの発話だけを認識できるSTT1」でも、皆様のビジネス要件と趣味ご嗜好にあわせた「俺の・私のSTT」を作ってみたらいかがでしょうか。(簡単ですよ)![]()
要は(TL;DR;)
- STTとは音声(オーディオ)を文字に変換するWatsonの「文字起こし」サービス
- 素の(=IBM提供の)STTが知ってるのは一般的な日本語(一般的な辞書)だけ
- 固有名詞(ex. 会社名・商品名)や業界/趣味/専門用語・独自のいい回しなどは「素の」STTでは認識できないが、簡単に教えることができる。これをモデルのカスタマイズと呼ぶ。要は、簡単に「俺のSTT」モデルを作れる
- カスタマイズは①音響モデル ②言語モデルの2通りの方法があり、併用も可能
- カスタマイズ作業自体はUIは無いがREST APIでもWatsonのSDK(ヘルパー)でもできる。プログラムの雛形があればカンタンな作業
- ただし無償のライトプランではカスタマイズはできない(PAYG/スタンダートで月100分の無償枠あり)
- PythonのSTTカスタマイズの体験キットを用意したので、ご興味あれば使ってみてください
![]() (2019/09/11追記) 当体験キット、Watson SDKがV4になって名前がibm-watsonに変更になったりしたんで、改めてV4環境で動くものにアップデートしました。
(2019/09/11追記) 当体験キット、Watson SDKがV4になって名前がibm-watsonに変更になったりしたんで、改めてV4環境で動くものにアップデートしました。
![]() (2020/02/07追記) 当体験キット、知らない間にSTTのSDKの認証方式が変更になってたので、動くように直しました。
(2020/02/07追記) 当体験キット、知らない間にSTTのSDKの認証方式が変更になってたので、動くように直しました。
なぜSTTをカスタマイズするのか
WatsonのSTTとは、音声(Audio)を文字に変換する「文字起こし」機能です。IBM側で事前にディープ・ラーニングを使ってトレーニングした変換モデルを、ユーザーは手軽に使うことができ、日本語にも対応してます。ただ、素の(生の)STTでは標準的な日本語は認識できますが、固有名詞や業界/専門用語・独自のいい回しなどは学習していないので認識できません。素のままのSTTでは「一般的な日本語」しか知らないので、特定のドメイン(ITとか映画とか金融とか)の用語(発話)は音を聞いても解釈できなかったり、誤って解釈したりします。

例えば自社の会社名や製品名の発話を間違って表記されてはビジネス利用では困りますよね。STTでは利用者が素のモデルに簡単に様々な言葉を教えることができるようになっています。これがSTTの「カスタマイズ」機能です。カスタマイズ機能を適用することで、音声の認識精度の改善が期待できます。要は「俺のSTT」を簡単に作れる、ってことですね。
STTの提供するカスタマイズ機能
![]() (2019/04/05追記) 追加資料としてThink2019のセッション資料「IBM Watson Speech to Text: A Training Guidebook for Technologists」(IBMIDでログイン要)が詳しいのでおススメします。
(2019/04/05追記) 追加資料としてThink2019のセッション資料「IBM Watson Speech to Text: A Training Guidebook for Technologists」(IBMIDでログイン要)が詳しいのでおススメします。
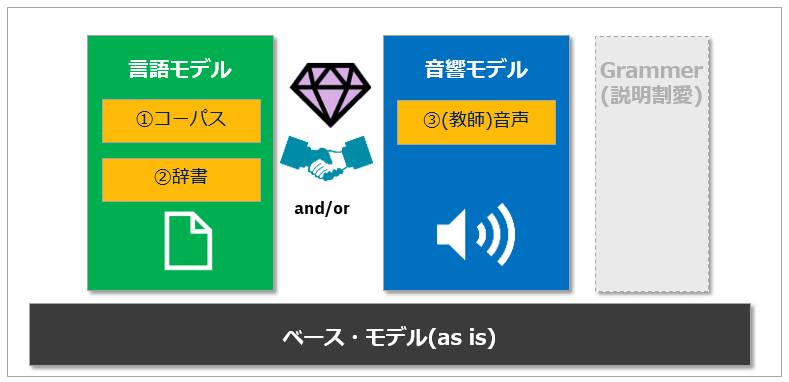
STTでは①言語モデルと②音響モデルの2通りのカスタマイズ方法を提供しています。(Grammerってのもありますが、今は説明割愛します)
- 言語モデルは当該ドメインのコーパスとなるような文章群や個別の単語を「テキスト」形式で入力して、独自のモデルを構築できます
- 音響モデルは教師データとなる**音声データ(サンプル)**を入力して独自モデルを構築できます
- いずれもコンテンツを与えてから「トレーニング」を起動しますが、数分から数十分で終わります。(かかる時間は、与えるコンテンツの量次第で変動)
- 言語モデルと音響モデルは各々に得意分野があるので、いずれかだけでもいいですし併用も可能です

上記は使い分けのガイドですが、言葉的なカスタマイズは言語モデル、雑音などの音的な面でのカスタマイズは音響モデルが適していることがおわかりいただけるかと思います。
STTをカスタマイズするために用意するコンテンツ
カスタマイズのためには以下を用意する必要がありますが、ややこしいことはなく、一般のエンドユーザー様でも準備可能かと思います。
(言語モデル) コーパス
その分野のことが書いてあるテキストや文章群。STTはこれらのテキストを教師データとして、当該分野の言葉や表現を学習します
- マニュアル、法規、記事、パンフレット、本などなんでも
- 要はその分野の言葉がたくさん書いてあるといい
- 教師データとする音声の文字起こしの文章(トランスクリプト)があるとベスト
![]() ちなみに、どれくらいの量のコンテンツを用意すればいいのかな?と思ってたのですが前述のThinkのプレゼンによると「Best Practiceとしては10-50時間分」とのこと。そんなにいるんですかあ。。。。orz
ちなみに、どれくらいの量のコンテンツを用意すればいいのかな?と思ってたのですが前述のThinkのプレゼンによると「Best Practiceとしては10-50時間分」とのこと。そんなにいるんですかあ。。。。orz
プレゼン抜粋

(言語モデル) 用語の辞書
特定の単語の発話と読み方を登録したJSON形式のファイル。sounds_likeにはカタカナで発音を複数登録できます。display_asは、そういう発話があった時の文字での表記の仕方を指定します。
{
"words":[
{"word":"200","sounds_like":["ニヒャク"],"display_as":"200"},
{"word":"ペタフロップス","sounds_like":["ペタフロップス"],"display_as":"ペタフロップス"},
{"word":"並列度","sounds_like":["ヘイレツ"],"display_as":"並列度"},
{"word":"ノード","sounds_like":["ノード"],"display_as":"ノード"},
{"word":"Power9","sounds_like":["パワーナイン"],"display_as":"Power9"},
{"word":"コア","sounds_like":["コア"],"display_as":"コア"},
{"word":"SMT","sounds_like":["エスエムティ"],"display_as":"SMT"},
{"word":"GPU","sounds_like":["ジーピーユー"],"display_as":"GPU"},
{"word":"NVIDIA","sounds_like":["エヌビディア"],"display_as":"NVIDIA"}
]
}
![]() コーパスと用語辞書はどちらかだけでも結構です。両方あったほうが精度があがるでしょうが、両方が必須、というわけではありません。
コーパスと用語辞書はどちらかだけでも結構です。両方あったほうが精度があがるでしょうが、両方が必須、というわけではありません。
(音響モデル) お手本となるオーディオ音声
実際に認識させる予定の音声に似たオーディオファイルを入力すると、STTは音の波形や雑音の状況などを学んで、音声認識をそのファイルの音に最適化します。
- 最低でも10分間の時間が必要
- サイズはMAX 100MBまで
- このオーディオファイルに一致する文字起こし(トランスクリプト)があると、両方から学習するのでベスト
カスタマイズの方法・手順
![]() STTのカスタマイズ機能は無償のLiteプランではご利用いただけません。 StandardのPAYGのプランでインスタンスを作る必要があります。ただし毎月100分の無償枠があるので、その範囲なら課金はされません。
STTのカスタマイズ機能は無償のLiteプランではご利用いただけません。 StandardのPAYGのプランでインスタンスを作る必要があります。ただし毎月100分の無償枠があるので、その範囲なら課金はされません。
カスタマイズはUIこそありませんが、お作法に則ってAPI経由で上記のコンテンツを登録すればいいだけです。雛形を使えばとても簡単です。(他社様の同等サービスだとややこしい作業が必要になることもあるそうですが、Watsonではメチャ楽です)
APIの呼び出し方法は他のWatsonサービスと同じく
- ①(curl等使って) RESTでAPIをたたく
- ② Watson SDKのヘルパーを使う
のいずれでも可能です。ネットの文献では①を使ったものが多いのですが、個人的にはIAMの認証とか楽ですしプログラムもシンプルなので②SDKをおススメします。SDKの使い方はGithub上に公開されている言語別のSDKとサンプルで情報入手できます。以下、私の好みでPython SDKでのやり方をご説明しますが他の言語でも大筋は同じです。
【文献】:
![]() Watson Python SDK
Watson Python SDK
![]() Speech To Textのサンプル
Speech To Textのサンプル
![]() Speech To TextのSDK本体(コメントに細かいドキュメントあり)
Speech To TextのSDK本体(コメントに細かいドキュメントあり)

上記が各モデル別のAPIの呼び出しの「お作法」です。ここでは細かい話はしませんが、大筋は
- ①STTのインスタンスを作成する
- ②言語モデルまたは音響モデルを作成する
- ③各モデルで必要なコンテンツ(調整のネタ)を追加する
- ④トレーニングする
- ⑤トレーニングしたモデルを使って音声認識する
の流れです。②で作ったカスタム・モデルのIDが返るので、あとはそのIDを引き回していきます。カスタマイズはほぼ同じ流れなので、雛形があれば楽勝でしょう。
ということで雛形/カスタマイズ体験キットを作りました
Jupyter Notebook上でPython SDKを使ったサンプルプログラム/カスタマイズ体験のキットをGithubにご用意しました。cloneしてご自由にご活用ください。

- Jupyter Notebookで通常/言語モデル/音響モデルをトレーニングして、実際にサンプル音声を認識させ、精度の改善を体験します
- このIBMQの動画を使ったサンプルコンテンツ(mp3ファイル、コーパス、用語辞書)を同梱してありますので、STTのCredentialを変更するだけでカスタマイズを動かしながら体験いただけます
実際にはこの30秒の音声が以下のように文字起こしされました。(意図的に固有名詞の多い発話部分を選びました)
1. 正解(教師)データ
で200ペタフロップスなんですけれども、並列度っていう観点から見れば、1台のノードを見てみるとPower9のプロセッサーが二つ、それぞれ22コアの4SMTのやつプラス一台にGPU、NVIDIAのGPUが六枚刺さってます。でそれぞれ5120コアという凄い並列度ですけれども、ですから1ノードで三万を超える並列度があります。
2. 素のSTT ~ぜんぜんアカンやん。。
ええ、役立たフロックスなんですけれども並列度っていう観点から見ればええええ一台の濃度を見てみるとD_エー買わないのプロセッサーが二つD_エーそれぞれ二十二個D_アノー四名選定のやつプラス一台にええええCTUエミリア文字で言えば六枚です刺さってますでそれぞれD_エー五千百二十個というD_エー凄い並列のですけれどもですから一ノードで三万を超える平熱道があります
3. 言語モデルのカスタマイズ後 ~お、いい感じ。
ええ、200ペタフロップスなんですけれども並列度載ってる観点から見ればええええ一台のノードを見てみるとD_エーPower9プロセッサーが二つD_エーそれぞれ二十二コアの四SMTのやつプラス一台にええええGPUNVIDIA文字で言えば六枚刺さってますでそれぞれD_エー五千百二十個というD_エー凄い並列度のですけれどもですから一ノードで三万を超える並列度道があります
4. 言語モデル+音響モデルのカスタマイズ後 ~今回は音響モデルはあまり効果ないか。。
D_エー200ペタフロップスなんですけれども並列度載ってる観点から見ればええええ一台のノードを見てみるとD_エーPower9プロセッサーが二つD_エーそれぞれ二十二コアの四SMTのやつプラス一台にGPUNVIDIA文字で言えば六枚刺さってますでそれぞれD_エー五千百二十個というD_エー凄い並列度のですけれどもですから一ノードで三万を超える並列度道があります
てな感じのことが体験できますし、コンテンツを代えても、殆どそのまま動くと思います。
若干のご説明/補足をば
Notebookのコードを見ていただけばほぼ自明ではあるのですが、自分で引っかかったところ含め、いくつかご説明/補足しておきます。
1. カスタマイズ作業にJupyter Notebookは超便利!
ご存知のとおりJupyter Notebookはセル単位でお好みのコードを実行できますので、お勉強モードで処理の流れを確認しながら順番に実行するのに適してますし、トレーニングの完了状態を一定間隔で照会するなどの操作も容易です。
2. 登録やトレーニングは非同期なので、STATUSを確認要
STTのカスタマイズではコンテンツの登録やトレーニングは基本的に非同期処理です。すなわち、処理を要求したらいったん「受け付けたよ」というコード(HTTP201)が返って、あとはそのステータスをreadyやavailableになるまで一定間隔で照会する必要があります。

上の例ではセル In[36]:でトレーニングを要求し、エラーが無ければ{}のみが即座に返ってきます。あとは裏でトレーニングが進行しますのでセル In[37]:を適当な間隔で手で何度も実行し、statusがavailableになるのを待ちます。こういう時、Jupyterは便利です。
3. SDKではコンテンツはファイル名ではなくストリームで与える
REST APIではコーパス/辞書や音声のファイルは**--data @file-name** のように引数にファイル名自体を指定しますが、
curl -k -X POST ... --data @hoge.mp3 ...
SDKではファイル名をそのまま渡してもうまくいきません2。
![]()
stt.recognize( audio="hoge.mp3", content_type=..
そうではなくて以下のようにファイルを開いてストリームで渡します。(これに気付くのに結構悩みました。。。サンプルをよく読めばよかったのですがね。)
with open("hoge.mp3",'rb') as audio_file:
return stt.recognize(
audio=audio_file,
content_type= ...
4. 用語辞書はリストで渡す. REST APIの時と形がちょっと違う
REST APIでは辞書ファイルは以下の形で、ディクショナリーのキー "words"のバリューとして[ {"word":...},{"word":...},{"word":...}]形式のリストを格納した形のファイルであり、これをcurl .. --data @words.jsonのように指定します。
{
"words":[
{"word":"200","sounds_like":["ニヒャク"],"display_as":"200"},
{"word":"ペタフロップス","sounds_like":["ペタフロップス"],"display_as":"ペタフロップス"},
{"word":"並列度","sounds_like":["ヘイレツ"],"display_as":"並列度"}
]
}
SDKでは用語をまとめて複数登録するならadd_words(複数形)3を使いますが、その引数のwords=はREST APIの場合と違って"words"のバリューである[ {"word":...},{"word":...},{"word":...}]形式のリストを渡す必要があります。ので、以下の例ではjson.load(f)["words"]で、バリューであるリストを入手してwords=に引き渡しています。
with open(TRANSCRIPT_JSON,'r',encoding="utf-8") as f:
custom_words = json.load(f)["words"]
stt.add_words(
customization_id=language_customization_id,
words=custom_words).get_result()

言葉で説明するとややこしいのですが、要はREST APIなら赤い矢印が起点だがSDKでは青い矢印を起点にする必要あり4、ということです。
5. SDKの仕様はソース見るのも一案
下記API ReferenceにSDKの場合の説明もあるんですが、よくわからなければSDKのソースを見てしまうのもいいと思います。コメント欄に引数の細かい説明などもありますし。前出の「4. 用語辞書はリストで渡す.」もエラーになって、困ってソース見たら

となってたので「ああ、リスト渡すのね」とわかった次第。SDKのSTTのヘルパーのソースは1ファイルだし全部で5500行程度。そのうち半分はコメントなので、迷うことは無いはずですよ。
文献(STTドキュメント)
【ドキュメント】
![]() The customization interface
The customization interface
![]() Creating a custom language model
Creating a custom language model
![]() Creating a custom acoustic model
Creating a custom acoustic model
【API Rerefence】
![]() Create a custom language model
Create a custom language model
![]() Create a custom acoustic model
Create a custom acoustic model
【SDK】
![]() Python SDK
Python SDK
 改定履歴
改定履歴
| 版 | 日付 | 変更内容 |
|---|---|---|
| 1.0 | 2019-03-11 | 初版公開 |
| 1.1 | 2019-04-05 | Thinkのセッション資料のご紹介を追加 |
| 1.2 | 2019-09-11 | Python SDK V4対応でURLやGithubのサンプルを入れ替え |