はじめに
今まで一般的なWeb開発はしてきたけど高速化についてあまり考慮せずに実装してきたエンジニアの方に向けて、筆者のデータ ( 7億-8億レコード ) 加工処理高速化の経験を基に、本番実行で何を目指すかということと、それまでに実際にどのようなアプローチがあるのかを提案できればと思います。
あくまで提案なので、「こうしたらもっと高速になるよ」的な箇所は多々あるかと思います。
コメントなどでご指摘いただければ幸いです。
本記事における前提条件
本記事における前提条件を筆者の経験した環境を参考に記載します。
本プロジェクトの背景及び要件
- 既存サービスで蓄積されたデータを外部のシステムに連携して有用活用するにあたってのPoVを実施する。
- 既存サービスで蓄積されたデータの一部を匿名化 (ハッシュ化) したものをCSVに書き出し、外部のシステムにPOSTする。
- 本番実行までの実装及び検証は短期間 (2-4週間程度) である。
- 加工処理はできるだけ早く完了させる
採用したテクノロジー
- Ruby on Rails API mode
- AWS
- EC2, RDS, Elasticache Redis, CloudWatch
データ加工処理高速化のアプローチ
本対応における極意
- 塵も積もれば山となる
- 加工処理は要件を満たす範囲内で最速のロジックを追求する
- 外部接続回数は最小限に抑える
- 使用するデータサイズをできるだけ小さくする
- 使いまわせるデータは使いまわす
- マシンスペックを最大限活用する
実装レベル
計測
高速化実装は実行時間を計測してロジックをチューニングしながら進めます。
今回はRuby標準の benchmark というライブラリを採用しました。
benchmarkの使用方法については細かく解説しないので、以下のような記事を参考にしていただければと思います。
並列実行
今回のようなデータ量を直列で加工していてはいつまでたっても処理が完了しません。
複数スレッド/プロセスに作業を分担して並列実行します。
今回はRuby Gemsの Parallel を採用しました。
# Parallel.processor_countでCPUのコア数が取得できる
csv_data += Parallel.map(records, in_processes: Parallel.processor_count) do |record|
# some process
end
このような記述にすると、 records の要素が record としてブロックに渡され、各プロセスで加工処理できるようになります。
今回のケースにおいて in_thread と in_processes は計測の結果、プロセスに処理させる方が多少高速だったため in_processes を採用しました。
in_thread を使用し、 #some_process 内でDB接続する部分がある場合は、コネクションプールを使用して高速化することも検討できます。
加工処理の高速化
分割抽出
大量なデータを一度にDBから取得しようとするのは非常に非効率です。
find_in_bataches で細切れにデータを取得して高速化を図ります。
SomeModel.find_in_batches(batch_size: Constants::Batch::BATCH_SIZE) do |records|
# some process
csv_data += Parallel.map(records, in_processes: Parallel.processor_count) do |record|
# some process
end
# some process
end
-
Constants::Batch::BATCH_SIZEは独自に宣言した定数です。最終的に100_000で設定しました。
必要な属性のみ抽出
今回CSVには必要な属性のみ書き出すため、抽出する属性も最小限に絞ります。
また、加工対象のテーブルがパーティショニングされている場合は、 SomeModel の部分にパーティションが渡されるような実装になるかと思います。
SomeModel.select_csv_columns.find_in_batches(batch_size: Constants::Batch::BATCH_SIZE) do |records|
# some process
csv_data += Parallel.map(records, in_processes: Parallel.processor_count) do |record|
# some process
end
# some process
end
scope :select_csv_columns, -> do
select([
:some_colum,
...
])
end
加工に使用されるアルゴリズムなどのチューニング
今回特定の属性を匿名化するため、最初は SHA-512 でハッシュ化していました。
Digest::SHA512.hexdigest("#{string}")
今回ハッシュ化のセキュリティレベルに関して特段指定がなかったため、より高速な SHA-1 に変更しました。
Digest::SHA1.hexdigest("#{string}")
インフラレベル
全体像
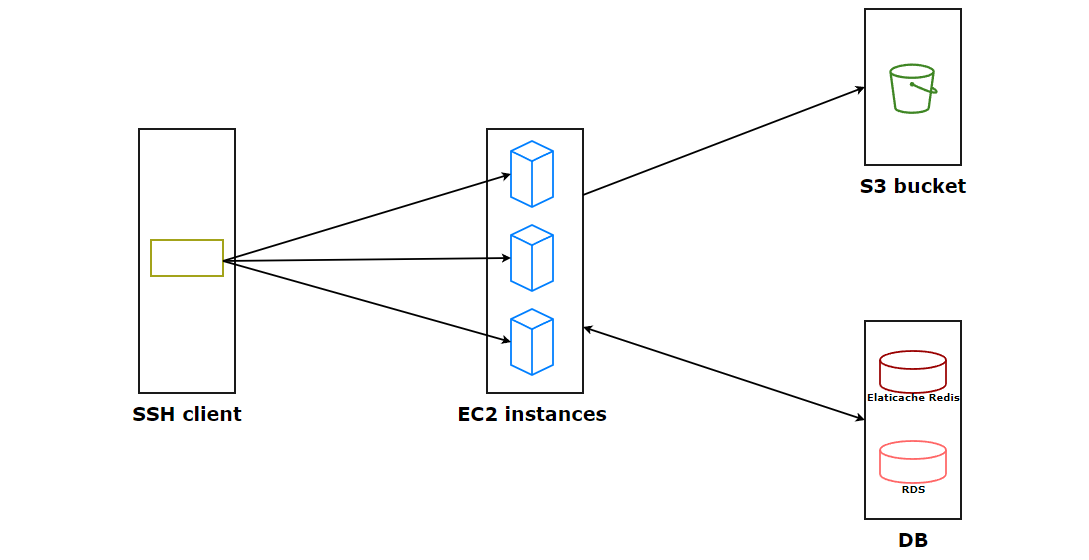
各EC2インスタンスにssh接続し、それぞれのインスタンス内でrakeタスクを実行する形で構成されています。(ここは正直時間が足りず...改善点は多々あると思っています)
Rakeタスクのパラメータにデータ抽出のオフセット値を渡し、処理対象を分散するようになっています。
対象テーブルの加工時に、他テーブルへの参照が必要な場合ループ単位で外部参照のSQLが発行されてしまいます。
できる限りDB接続を減少させるため、一度参照したKVはRedisにストアし、値がセットされている場合はそちらを使用します。
また、rakeタスク実行時にはCloudWatchでメモリ使用率やIOPSを監視し、異常が発生したらすぐに対応できる体制を整えます。
さいごに
今回全体での処理経過時間は9時間程度でした。 (EC2 a1.4xlarge:8台, RDS db.t3.medium:1台, Elasticache t2.small:1台)
実行方法に関しての検討はタイムアップで脳筋実行になってしましたが、
処理単位を分割したタスクをキューイングし、各インスタンスがタスクを拾いにくる、という形を作ると処理効率を最大化できそう
というアドバイスをいただいたので、次回このような機会があったときには試してみたいと思っています。
その他より良い方法がある方はご意見いただけると幸いです。