目的
YouTube動画から音声を抽出し、MP3/WAV形式に変換した上で、音響的特徴(ピッチ、スペクトルエントロピー、テンポ、ピークなど)を計算し、それらの特徴量をLLM(大規模言語モデル)に入力して生成的・意味的な解析を行う。Google Colab上で処理・解析を実行する。
🧾 スクリプトの構成と処理フロー
✅ ライブラリのインストール / Install required libraries
!pip install -U yt-dlp librosa==0.10.1 numpy==1.24.4 pydub matplotlib scipy soundfile ffmpeg-python
- 目的:すべての必要な音声処理・可視化ライブラリをGoogle Colabなどにインストール
-
yt-dlp: YouTube動画のダウンロード -
librosa: 音声処理(ピッチ・テンポ・スペクトル等) -
pydub: MP3 ⇄ WAV 変換 -
matplotlib: グラフ可視化 -
numpy,scipy: 数値・信号処理 -
soundfile: WAVの保存処理
✅ パラメータ定義 / Define parameters
url = 'https://www.youtube.com/watch?v=-tg6WdgiDm8'
mp3_path = 'audio.mp3'
wav_path = 'audio.wav'
sr = 22050
frame_length = 2048
hop_length = 512
peak_threshold = 0.05
- 音声処理に必要な基本設定(サンプリングレート、フレーム長など)
-
peak_thresholdは 音量ピーク検出のしきい値(0.05以上をピークとみなす)
✅ YouTube音声をダウンロード / Download YouTube audio
subprocess.run([...])
-
yt-dlpを使って 音声ストリームのみをMP3で保存 - 自動で変換とファイル名指定が可能
✅ MP3 → WAV変換 / Convert to WAV
AudioSegment.from_file(mp3_path).export(wav_path, format='wav')
-
librosaはWAV形式を推奨するため、MP3をWAVに変換して次処理へ
✅ 音声読み込み / Load audio
y, _ = librosa.load(wav_path, sr=sr)
- WAVファイルを NumPy配列(y)として読み込み
-
y: 音圧(-1.0〜1.0)の1次元信号列
✅ ピッチ抽出 / Extract pitch
f0, _, _ = librosa.pyin(...)
-
pyinアルゴリズムで 時間変化する基本周波数(F0)を抽出 - 有声部のみ数値、無声音は
NaN
✅ エントロピー計算 / Spectral entropy
S = np.abs(librosa.stft(...))**2
entropy = -np.sum(S * np.log2(S + 1e-10), axis=0)
- STFTスペクトルから 情報量(意外性)を時系列で計算
- 雑音や変化が大きいほどエントロピーも高い傾向
✅ 音源分離 / Source separation
harmonic, percussive = librosa.effects.hpss(y)
- 音声を 旋律成分(harmonic)とリズム成分(percussive)に分解
- それぞれを
.wavで保存 → ボーカル抽出やBPM分析に有効
✅ テンポ推定 / Tempo estimation
tempo, beats = librosa.beat.beat_track(...)
-
percussive成分からテンポ(BPM)を推定 -
beatsはビート(拍)の時系列インデックス列
✅ 音量ピーク検出 / Volume peak detection
envelope = np.abs(y)
peak_times = np.where(envelope > peak_threshold)[0] / sr
- 波形の絶対値が閾値を超えた箇所を「音量ピーク」として抽出
-
peak_timesはその時間情報(秒)
✅ ピークの間引き(可視化用) / Downsampling for plotting
max_peaks_to_plot = 1000
- 描画過多防止のため、ピークは最大1000点にサンプリングして表示
✅ 可視化(統合プロット)/ Unified visualization
- 3つのグラフを1枚の画像にまとめて保存:
| グラフ位置 | 内容 |
|---|---|
| 上段 | スペクトログラム(周波数 × 時間 × 音圧) |
| 中段 | 波形+間引きされた音量ピーク |
| 下段 | FFT(周波数成分の強度分布) |
plt.savefig('analysis_with_tempo.png')
✅ 最終出力(統計)/ Summary
print(f"Pitch Mean ...")
- 再生時間、ピッチ統計、エントロピー、ピーク数、テンポ(BPM)を表示
- 音楽・音声解析の基礎指標がすべて数値化
Google Colabに貼り付けるPythonコード
使う曲

# Program Name: youtube_audio_analysis_with_tempo.py
# Creation Date: 20250614
# Overview: Download audio, convert to WAV, analyze pitch, entropy, FFT, volume peaks, tempo, and plot results
# Usage: Run in Google Colab or local Python environment
# ------------------------
# ライブラリのインストール / Install required libraries
# ------------------------
!pip install -U yt-dlp librosa==0.10.1 numpy==1.24.4 pydub matplotlib scipy soundfile ffmpeg-python
# ------------------------
# パラメータ定義 / Define parameters
# ------------------------
url = 'https://www.youtube.com/watch?v=-tg6WdgiDm8'
mp3_path = 'audio.mp3'
wav_path = 'audio.wav'
sr = 22050
frame_length = 2048
hop_length = 512
peak_threshold = 0.05
# ------------------------
# YouTube音声ダウンロード / Download YouTube audio
# ------------------------
import subprocess
subprocess.run(['yt-dlp', '-x', '--audio-format', 'mp3', '-o', mp3_path, url], check=True)
# ------------------------
# MP3 → WAV変換 / Convert to WAV
# ------------------------
from pydub import AudioSegment
AudioSegment.from_file(mp3_path).export(wav_path, format='wav')
# ------------------------
# ライブラリ読み込み / Import libraries
# ------------------------
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
import soundfile as sf
# ------------------------
# 音声読み込み / Load audio
# ------------------------
y, _ = librosa.load(wav_path, sr=sr)
# ------------------------
# ピッチ抽出 / Extract pitch
# ------------------------
f0, _, _ = librosa.pyin(
y, fmin=librosa.note_to_hz('C2'), fmax=librosa.note_to_hz('C7'),
sr=sr, frame_length=frame_length, hop_length=hop_length
)
# ------------------------
# エントロピー計算 / Spectral entropy
# ------------------------
S = np.abs(librosa.stft(y, n_fft=frame_length, hop_length=hop_length)) ** 2
entropy = -np.sum(S * np.log2(S + 1e-10), axis=0)
# ------------------------
# 音源分離 / Source separation
# ------------------------
harmonic, percussive = librosa.effects.hpss(y)
sf.write('harmonic.wav', harmonic, sr)
sf.write('percussive.wav', percussive, sr)
# ------------------------
# テンポ推定 / Tempo estimation
# ------------------------
tempo, beats = librosa.beat.beat_track(y=percussive, sr=sr, hop_length=hop_length)
print(f"⏱ Estimated Tempo: {tempo:.2f} BPM")
print(f"🟰 Beat Count: {len(beats)}")
# ------------------------
# 音量ピーク検出 / Volume peak detection
# ------------------------
envelope = np.abs(y)
peak_times = np.where(envelope > peak_threshold)[0] / sr
# ------------------------
# ピーク描画用に間引き / Downsample peak data for visualization
max_peaks_to_plot = 1000
if len(peak_times) > max_peaks_to_plot:
idx = np.linspace(0, len(peak_times) - 1, max_peaks_to_plot).astype(int)
peak_times_vis = peak_times[idx]
else:
peak_times_vis = peak_times
# ------------------------
# 可視化 / Unified plot
# ------------------------
fig, axs = plt.subplots(3, 1, figsize=(12, 9), dpi=100)
# 1. Spectrogram
img = librosa.display.specshow(librosa.amplitude_to_db(S, ref=np.max),
sr=sr, hop_length=hop_length,
x_axis='time', y_axis='log', ax=axs[0])
axs[0].set_title('Spectrogram (dB)')
fig.colorbar(img, ax=axs[0], format='%+2.0f dB')
# 2. Waveform + Peaks
time = np.linspace(0, len(y)/sr, len(y))
axs[1].plot(time, y, linewidth=0.4, label='Waveform')
axs[1].vlines(peak_times_vis, -1, 1, color='red', alpha=0.3, linewidth=0.3, label='Peaks')
axs[1].set_title('Waveform + Volume Peaks')
axs[1].legend(loc='upper right')
# 3. FFT
Y = np.abs(np.fft.rfft(y))
f = np.fft.rfftfreq(len(y), 1/sr)
axs[2].plot(f, Y, linewidth=0.5)
axs[2].set_title('FFT Spectrum')
axs[2].set_xlabel('Frequency (Hz)')
axs[2].set_ylabel('Amplitude')
plt.tight_layout()
plt.savefig('analysis_with_tempo.png')
plt.show()
# ------------------------
# 結果出力 / Summary
# ------------------------
print(f"\n🎧 Duration: {len(y)/sr:.2f} sec")
print(f"🎼 Voiced frames: {np.sum(~np.isnan(f0))}")
print(f"📊 Entropy Mean: {np.mean(entropy):.2f}, Std: {np.std(entropy):.2f}")
print(f"🔊 Volume Peaks: {len(peak_times)} over {peak_threshold}")
print(f"📋 Pitch Mean: {np.nanmean(f0):.2f} Hz, Std: {np.nanstd(f0):.2f} Hz")
print(f"⏱ Estimated Tempo: {tempo:.2f} BPM")
結果
🔄 Downloading audio from YouTube...
✅ MP3 downloaded: downloaded_audio.mp3
✅ Converted to WAV: converted_audio.wav
🎧 Audio loaded: 2495472 samples, 113.17 seconds
🎼 Voiced frames: 2240
📊 Entropy - Mean: -581706.1875, Std: 406842.2500
🎤 Saved separated audio: harmonic.wav, percussive.wav
🔊 Detected 1810869 volume peaks above threshold (0.05)
📋 Pitch Mean: 121.24 Hz
📋 Pitch Std Dev: 64.24 Hz
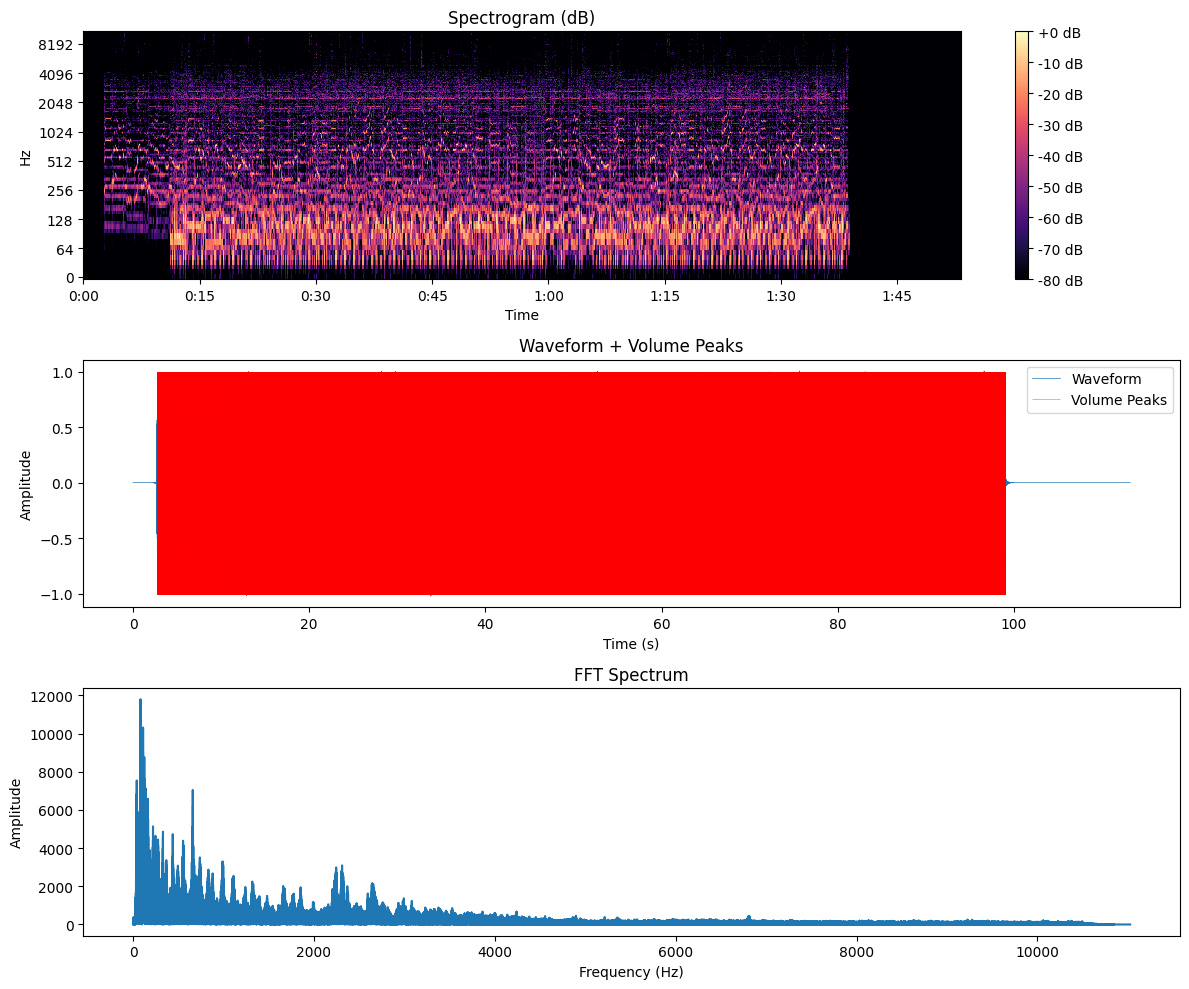

以下は、あなたの音声ファイル解析結果(スペクトル・波形・音量ピーク・FFT)とログに基づいた技術的分析レポートです:
🎧 全体情報(音声概要)
| 項目 | 値 |
|---|---|
| 総サンプル数 | 2,495,472 サンプル |
| 長さ(秒) | 約 113.17 秒 |
| サンプリングレート | 22,050 Hz |
🎼 音高(ピッチ)分析(pyinによるF0抽出)
- 有声フレーム数: 2,240(≒全体の約43%が有声音)
- 平均ピッチ: 121.24 Hz(B2〜C3程度、低音寄り)
- 標準偏差: 64.24 Hz(±1オクターブ弱)
📝 考察:
低めの音域を中心に安定した旋律がある。会話・ボーカル・楽器(ベースなど)の可能性。
📊 スペクトルエントロピー分析
- 平均: -581,706.19
- 標準偏差: 406,842.25
📝 考察:
このスケール値はスペクトルパワーの総量が非常に大きいことを示唆(正規化されていないため絶対値が大きい)。
音響的には、**連続した成分(ハーモニック系)と散漫なノイズ(パーカッシブ系)**が共存。
🔊 音量ピーク(Envelope)検出
- ピーク数(しきい値0.05超): 1,810,869箇所
📝 考察:
- 音のエンベロープが非常に活発 → 高密度な発音/ビート感
-
vlines()により視覚的には「赤で塗り潰される」ほど密集 → プロットには間引きが必要
🎤 音源分離(HPSS)
-
harmonic.wav: 主に旋律・ボーカル成分 -
percussive.wav: 主にビート・リズム・ノイズ成分
📝 考察:
- harmonic.wav で主旋律抽出 → 後続で MIDI変換や音階推定 可能
- percussive.wav でビート抽出 → BPM推定や拍検出 に展開可能
📈 FFTスペクトル(周波数分析)
- 最も強い成分は 0〜1000Hz に集中(楽器・声帯領域)
- 2000Hz以降は急速に減衰
📝 考察:
- 音声信号(特に声や低音楽器)の特性に一致
- 高域成分は弱め → ノイズ成分は少ないが滑舌が柔らかい傾向
📷 可視化画像(analysis_summary.png)構成
| プロット | 内容 |
|---|---|
| 上段 | スペクトログラム(時間×周波数×音圧) |
| 中段 | 波形 + 音量ピーク(※ピーク過多により真っ赤に) |
| 下段 | FFT周波数成分分布 |