この記事は、 NTT Communications Advent Calendar 2022 3日目の記事です。
Whisperとは
概要
OpenAI が2022年9月に発表した音声認識モデルです1 。68万時間もの大規模データセットを用いて学習されており、多言語音声認識や、機械翻訳・音声区間検出等のマルチタスクにも対応しています。
オープンソースで簡単に動かせる上に、日本語の音声認識精度も高いことで話題になりました。
OpenAIの公式ブログにて、4種類の音声データに対するデモを確認することができ、人間でも正確に聞き取るのが難しいような音声でもきれいにテキスト化できています。
Hugging Faceにもデモがあり、こちらは自分でしゃべった音声を試してみることができますが、後述する複数のモデルのうち "small" のモデルを使用しているので少し物足りなく感じるかもしれません。
余談ですが、Whisper という名称は WSPSR: Web-scale Supervised Pretraining for Speech Recognition からきているとのことです。(ちょっと無理があるような...)
Whisper モデル一覧
公開されているWhisperのモデルは5種類のサイズがあり、それぞれ英語のみのモデルと多言語モデルがあります。
モデルのサイズが大きくなるほど認識精度がよくなりますが、その分多くのメモリが必要になり計算時間も長くなります。
基本的には"large"モデルを使用するのがよさそうです。
| Size | Parameters | English-only model | Multilingual models | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | ~1x |
Whisper の性能①(英語音声認識)
多言語音声認識モデルといえど、学習データの65%は英語ですし、機械翻訳も Any -> English のみに対応しているため、Whisperは英語が中心のモデルと言えます。
英語音声認識タスクでよく使われているコーパスの LibriSpeech2 において、現在最も良い結果が単語誤り率(Word Error Rate; WER)1.4% であるのに対して、Whisper の large モデルは WER 2.7% であり、数値だけを見ると従来手法に劣っています3。
しかし、LibriSpeech の音声認識タスクを人間が解いた時のWER4は5.8% であるという研究報告もあるため、Whisperも十分な性能を出していると考えられます。
Whisperはそのうえで、その他の13種類の音声認識タスクでも従来手法よりも高い性能を出しており、特定のデータセットに特化したようなモデルではなく、頑健性が高い優れたモデルであることを示しました5。
現論文より、Table 2。 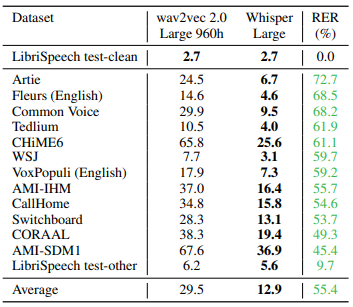
縦軸中央の数値はWER(%)で、縦軸右端のPER(%)はWERが wav2vec2.0 からどれくらい減っているかを表したものです。
比較対象の wav2vec2.0 は昨年のアドベントカレンダーで紹介した記事がありますので、興味がある方はご参照ください。
Whisper の性能②(多言語音声認識)
Whisperは99言語の音声認識に対応していますが、それほどの多言語に対応した音声認識モデルはなかったようで、論文中で比較評価しているデータセット・手法は14言語に対応したものでした。
上記に加えて、Fleurs データセット6を用いて各言語のWERとBleu 指標が論文の付録にまとめられています。
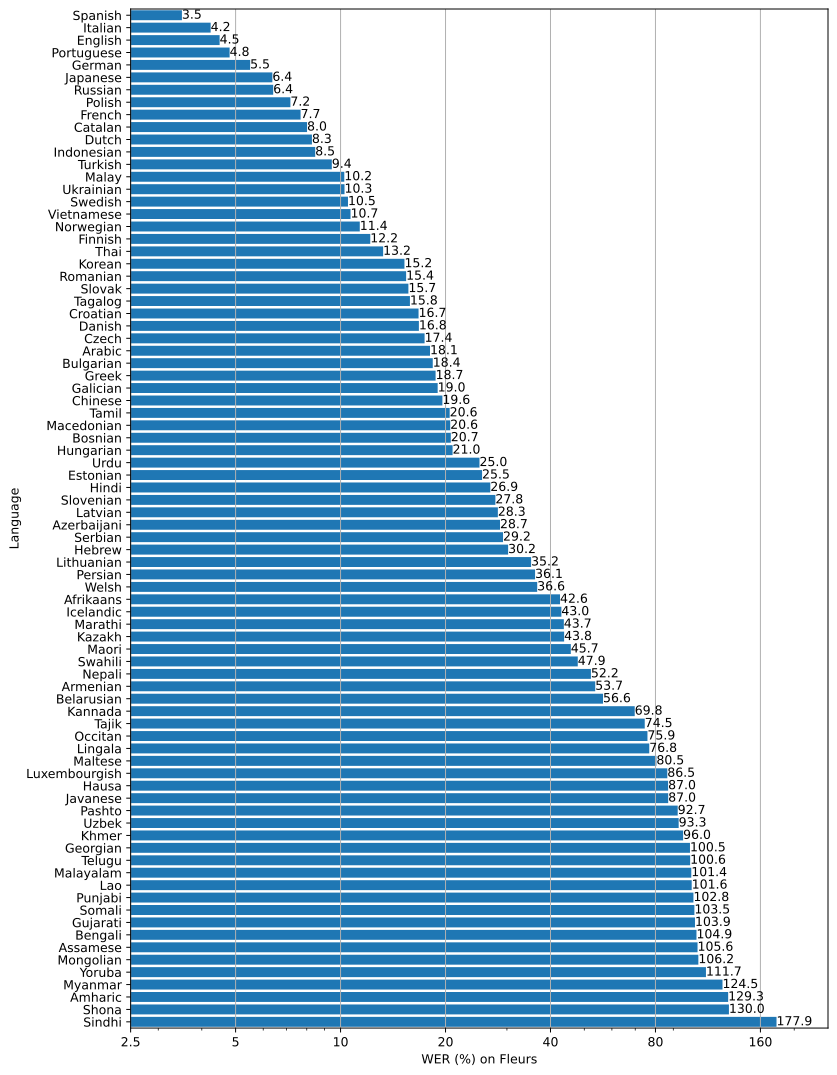
上記画像はFleursデータセットのWERのスコアが低い順に言語を並べたものです。(こちらより引用)
言語によって大分ばらつきがありますが、学習に使用したデータが多い言語ほど性能が良い傾向があるという、かなり直感的な分析がなされていました7。
wav2vec 2.0 との違い
昨年紹介した wav2vec 2.0 と、今回の Whisper はどちらもオープンソースで高い精度を誇る音声認識モデルですが、どのような違いがあるのでしょうか。筆者の主観でいくつか挙げようと思います。
-
学習データの違い
wav2vec 2.0 では、書き起こし文がセットになった学習データ(ラベル付きデータ)を大量に用意することが困難であるという背景から、書き起こし文がない音声データ(ラベルなしデータ)を学習に使用する「自己教師あり学習」というアプローチをとっています。対して Whisper では、ラベル付きデータを大量に用意するという力業とも言えるアプローチをとっています。 -
学習データのサイズの違い
wav2vec 2.0 では、960時間のラベルなしデータ + 少量のラベル付きデータで学習を行っているのに対し、Whisper では68万時間(英語だけでも40万時間超)のデータで学習を行っています。桁違いにも程があります。(wav2vec 2.0が少ないのではなく、Whisperが多すぎる) -
汎用モデルかどうか
wav2vec 2.0 は、事前学習されたモデルに対して、少量のデータでファインチューニングを行うことで、用途に適したモデルを構築することができるという点がポイントでした。これに対して、Whisper では、公開されているモデルに手を入れることもなく高い精度で多言語音声認識が実現可能ですし、背景雑音にも頑健な汎用的な音声認識モデルとなっています。もちろん Whisper をファインチューニングする意義は大いにあると思いますが、それをしなくとも十分な汎用性を持っていると言えます。
実際に動かしてみよう
実際のところは、どれくらいの精度が出るのか、実際に試してみましょう。
手を動かしたい場合は Google Colaboratory 上で簡単に動かせるので、こちらのチュートリアルを参考にいろいろ試してみるとよいかと思います。
今回は、Fleurs データセットの中身も確認してみたいので、Fleurs データセットから音声データを抜粋してテキスト化してみます。
ライブラリのインストール
公式リポジトリの案内に従って、Whisperのパッケージをインストールします。
Fleursデータセットのために、datasetsパッケージもインストールします。
pip install git+https://github.com/openai/whisper.git
pip install datasets
必要なモジュールのインポート
import whisper
from datasets import load_dataset
Fleurs データセットの用意
Fleurs データセットのうち日本語だけ持ってきます。
fleurs_asr = load_dataset("google/xtreme_s", "fleurs.ja_jp")
print(fleurs_asr)
DatasetDict({
train: Dataset({
features: ['id', 'num_samples', 'path', 'audio', 'transcription', 'raw_transcription', 'gender', 'lang_id', 'language', 'lang_group_id'],
num_rows: 2292
})
validation: Dataset({
features: ['id', 'num_samples', 'path', 'audio', 'transcription', 'raw_transcription', 'gender', 'lang_id', 'language', 'lang_group_id'],
num_rows: 266
})
test: Dataset({
features: ['id', 'num_samples', 'path', 'audio', 'transcription', 'raw_transcription', 'gender', 'lang_id', 'language', 'lang_group_id'],
num_rows: 650
})
})
train/val/test 全部合わせて 3208 ファイルあるようです。
今回は test データから10ファイルほど抜粋してみます。
書き起こし文の確認
transcriptions = fleurs_asr["test"][0:10]["transcription"]
for t in transcriptions:
print(t)
技術決定論のほとんどの解釈は 2つの一般論を共有しています 1つは技術の発展自体が文化的 政治的な影響を大きく超えた道をたどっていること もう1つは技術が社会的に条件づけられたものではなく むしろ内在する社会に 影響 を与えることです
地殻が薄いため 近い方には海が多くなることがあります 溶岩が浮上しやすくなっていました
都市はモロッコのスルタンによってダルル バディアとして再建され 貿易拠点を設立したスペイン人貿易商によってカサブランカと名付けられました
都市はモロッコのスルタンによってダルル バディアとして再建され 貿易拠点を設立したスペイン人貿易商によってカサブランカと名付けられました
上空の澄んだ美しい空と 周囲の多くの山々以外には何も見えません 洞窟の中からは 外界はほとんど見えず 外界の音も聞こえません
上空の澄んだ美しい空と 周囲の多くの山々以外には何も見えません 洞窟の中からは 外界はほとんど見えず 外界の音も聞こえません
上空の澄んだ美しい空と 周囲の多くの山々以外には何も見えません 洞窟の中からは 外界はほとんど見えず 外界の音も聞こえません
北マリアナ諸島の危機管理室emoによると 全国的に被害は報告されていないとのことです
北マリアナ諸島の危機管理室emoによると 全国的に被害は報告されていないとのことです
北マリアナ諸島の危機管理室emoによると 全国的に被害は報告されていないとのことです
同じ文章がありますが、異なる話者が読み上げているようです。
こちらに対応する音声データを Whisper にてテキスト化してみます。
Whiperによる文字起こし
woptions = whisper.DecodingOptions(language="ja", without_timestamps=True)
wmodel = whisper.load_model("large")
options = whisper.DecodingOptions()
audio_inputs = fleurs_asr["test"][0:10]["audio"]
for audio_input in audio_inputs:
audio = whisper.load_audio(audio_input["path"])
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(wmodel.device)
result = whisper.decode(wmodel, mel, options)
print(result.text)
技術決定論のほとんどの解釈は、2つの一般論を共有しています。1つは技術の発展自体が文化的・政治的な影響を大きく超えた道をたたっていること。もう1つは技術が社会的に条件付けられたものではなく、むしろ内在する社会に影響を与えることです。
近い方には海が多くなることがあります。ウォーガンが浮上しやすくなっていました。
都市はモロッコのスルータンによってダルルバリアとして再建され貿易拠点を設立したスペイン人貿易省によってカサブランカと名付けられました
都市はモロッコのスルタンによってダルルバリアとして再建され、貿易拠点を設立したスペイン人貿易省によってガサブランカと名付けられました。
上空の澄んだ美しい空と、周囲の多くの山々以外には何も見えません。洞窟の中からは下界はほとんど見えず、下界の音も聞こえません。
上空の澄んだ美しい空と、周囲の多くの山いま以外には何も見えません。洞窟の中からは下界はほとんど見えず、下界の音も聞こえません。
上空の澄んだ美しい空と、周囲の多くの山々以外には何も見えません。洞窟の中からは大海はほとんど見えず、大海の音も聞こえません。
北マリアナ諸島の危機管理室EMOによると、全国的に被害は報告されていないとのことです。
北マリアナ諸島の危機管理室EMOによると、全国的に被害を報告されていないとのことです。
北マリアナ諸島の危機管理室EMOによると、全国的に被害を報告されていないとのことです。
「たどって」-> 「たたって」
「山々」-> 「山いま」
「外界」-> 「下界」「大海」
などなど、いくつかミスはありますがほぼ正確に認識できているのではないでしょうか。
モデルを "small" に変更すると、このようになりました。
技術決定路のほとんどの解釈は、2つの一般路を共有しています。一つは技術の発展自体が文化的、政治的な影響を大きく超えた道をたたっていること、もう一つは技術が社会的に条件付けられたものではなく、むしろ内在する社会に影響を与えることです。
近くが薄いため、近い方には海が多くなることがあります。溶岩が浮上しやすくなっていました。
年はモロッコのスルーターによってダルルバリアとして再建され、貿易拠点を設立したスペインジン貿易賞によってカサブランカと名付けられました。
都市はモロッコのスルタンによってダルルバリアとして再検され、防液拠点を設立したスペイン人防液省によってガサブランカと名付けられました。
超空の寸田は美しい空と周囲の多くの山々以外には何も言えません。洞窟の中からは、下海をほとんど見えず、下海の音も聞こえません。
上航の住んだ美しい空と周囲の多くの山いまいがには何も見えません。洞窟の中からは、下海をほとんど見えず下海の音も聞こえません。
上空の住んだ美しい空と周囲の多くの山々以外には何も見えません。洞窟の中からは大海はほとんど見えず、大海の音も聞こえません。
北マリアナ諸島の危機管理室EMOによると、全国的に被害は報告されていないとのことです。
北マリアナ諸島の危機管理室EMOによると、全国的に被害を報告されていないということです。
北マリアの諸島の危機管理室EMOによると、全国的に被害を報告されていないとのことです。
けっこうミスが目立つようになりました。
おわりに
Whisper という最近話題になった音声認識モデルの解説を行いました。
これほど大規模な学習データを収集・整理し、モデルを学習するためには大変な労力があったことは想像に難くありません。
wav2vec 2.0 もかなり手軽に触れるフレームワークでしたが、Whisperは公開モデルをそのまま使えるレベルの汎用性を持っています。このような大規模データセットを必要とするモデルが誰でも使える状態になっているということに感謝しながら、活用していきたいですね。
無料版のGoogle Colaboratory上でも意外と動かせる8ので、是非試してみてください。
それでは、明日の記事もお楽しみに。
NTT Communications Advent Calendar 2022
参考
- 無料でOpenAIの「Whisper」を使って録音ファイルから音声認識で文字おこしする方法まとめ
https://gigazine.net/news/20220929-openai-whisper-install-and-usage/ - OpenAIの音声認識モデル Whisperの解説 / Fine Tuning 方法
https://zenn.dev/kwashizzz/articles/ml-openai-whisper-ft - Whisper : 日本語を含む99言語を認識できる音声認識モデル
https://medium.com/axinc/whisper-%E6%97%A5%E6%9C%AC%E8%AA%9E%E3%82%92%E5%90%AB%E3%82%8099%E8%A8%80%E8%AA%9E%E3%82%92%E8%AA%8D%E8%AD%98%E3%81%A7%E3%81%8D%E3%82%8B%E9%9F%B3%E5%A3%B0%E8%AA%8D%E8%AD%98%E3%83%A2%E3%83%87%E3%83%AB-b6e578f55c87
-
LibriVoxというフリーのオーディオブックのデータを用いて作成されたコーパスらしいです。詳細はこちら。Librispeech の中にもいくつか種類があり、今回話しているのは LibriSpeech test-clean というものです。完全に余談ですが日本語でも青空朗読という取り組みがありますね。コーパスにならないかなぁ ↩
-
こちらから各手法のスコアが確認できます。 https://paperswithcode.com/sota/speech-recognition-on-librispeech-test-clean ↩
-
human-level error rate とか human-level performance とか呼ばれるやつ。機械学習をやるにあたって、そのタスクは人間ならどれくらい解けるの?というのを考えるのは大切。人間といってもいろいろな人がいるので値を定めるのは難しい。 ↩
-
論文には、LibriSpeech 以外の13タスクを人間が解いた場合のWERとWhisperのWERがほぼ同じであるという旨の記述もありましたが、詳細まで読み切れず、よくわかりませんでした。 ↩
-
102個の言語を含むデータセット。今年の5月に発表されている。Whisperの発表が9月なのでタイムリー。https://paperswithcode.com/dataset/fleurs ↩
-
学習時に使用したデータセットの分布をみると、中国語のデータ量は多いのですが、Fleurs のWERは比較的悪くなっています。Blueのスコアを見ると、日本語と同じくらいの値で比較的良い結果になっているので、この結果はいろいろ注意してみた方がいいかもしれません。 ↩
-
マシンリソースの制約が厳しくなってきているので、ガッツリ動かすなら有料版じゃ無いと厳しいかも ↩