前回は、LangGraphを使って分岐・ループ処理を含む対話エージェントのフローを構築しました。
詳しくは以下の記事をご参照ください。
LangGraphで分岐・ループ処理付きの対話エージェントを作ってみた
今回はこのエージェントに「ナレッジ(知識)の蓄積と再利用」の仕組みを加え、
ユーザーとの対話を通じて“学習”し、次回以降に活かせる構造を目指します。
コードは以下に格納しました。以下に則り説明します。
LangGraphDB
1. 今回加える変更点(ゴールの明確化)
前回は、下記の画像に示すような、ロジック構成を作成しました。
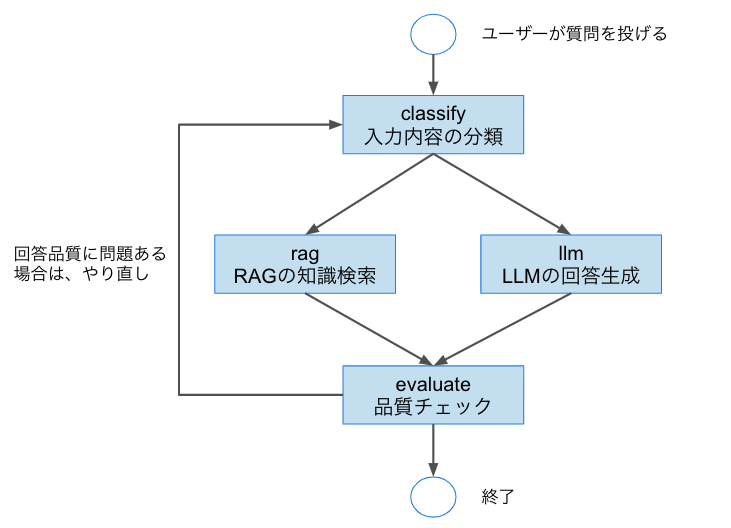
今回注目するのはragノード(知識検索)とllmノード(回答生成)のふたつです。
前回は、RAGの知識ソースがベタ書きされた変数であり、LLMの出力結果も一過性のものでした。
そこで今回は、以下のような変更を加えます。
- RAGノード:SQLiteを用いて知識ベースを構築し、データベースから検索して応答を生成
- LLMノード:ユーザーからの入力に対する応答を、ナレッジとしてデータベースに保存し、以後の検索対象とする
以下では、この実装の具体的なステップを解説していきます。
2. SQLiteでナレッジベースを構築
RAGノードで知識検索を行うために、まずはSQLiteで簡易的なナレッジベースを用意します。
以下のコードでは、knowledge.db というデータベースを作成し、title と content の2列を持つ knowledge テーブルを定義しています。
import sqlite3
# データベース作成&接続
conn = sqlite3.connect("knowledge.db")
c = conn.cursor()
# ナレッジテーブル作成
c.execute('''
CREATE TABLE IF NOT EXISTS knowledge (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT,
content TEXT
)
''')
# 初期ナレッジを挿入
c.executemany('''
INSERT INTO knowledge (title, content) VALUES (?, ?)
''', [
("LangChainとは", "LangChainはLLMのチェーン構築フレームワークです。"),
("RAGとは", "RAGはRetrieval-Augmented Generationの略で、検索と生成を組み合わせます。")
])
conn.commit()
conn.close()
作成したDBを読み込んで、RAGに活用するためのベクトル検索用に変換します。
ここでは、Chroma を使って文書をベクトルストアとして保持しています。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
# SQLiteからデータ取得
conn = sqlite3.connect("knowledge.db")
c = conn.cursor()
rows = c.execute("SELECT title, content FROM knowledge").fetchall()
conn.close()
# LangChain用ドキュメントに変換
documents = [Document(page_content=f"{title}\n{content}") for title, content in rows]
# 分割してベクトル化
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(documents)
embedding = OpenAIEmbeddings()
# ベクトルストア作成
vectorstore = Chroma.from_documents(docs, embedding, persist_directory="./chroma_db")
3. RAGノードの変更
上記で作成したベクトルストアを使って、入力に対して関連する知識を取り出す rag_node を定義します。
def rag_node(state):
query = state["input"]
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
retrieved_docs = retriever.invoke(query)
# もっとも関連性の高い文書を返却
retrieved_text = (
retrieved_docs[0].page_content if retrieved_docs else "該当する情報が見つかりませんでした。"
)
return {"response": f"[RAG] {retrieved_text}"}
4. LLMノードの変更
LLMからの回答を取得しつつ、その回答をナレッジベースに保存する処理を llm_node に追加します。
def llm_node(state):
user_input = state.get("input", "")
messages = [HumanMessage(content=user_input)]
response = llm.invoke(messages)
answer = response.content
# LLMの出力をナレッジベースに追加
conn = sqlite3.connect("knowledge.db")
c = conn.cursor()
c.execute("INSERT INTO knowledge (title, content) VALUES (?, ?)", (user_input, answer))
conn.commit()
conn.close()
return {"response": answer}
注意:実運用を想定する場合は、ユーザー入力のバリデーションや意図しない内容の保存に対するフィルタリングなど、安全面にも配慮する必要があります。
5. 次回への課題
今回の構成により、「ナレッジの蓄積と再利用」の基本的な仕組みが完成しました。
次回以降、以下のような改善・拡張を検討しています。
- 検索精度の向上:現状は単純なベクトル検索であるため、質問の意図と少しずれた文脈は拾えない可能性があります。これを、LLMベースの意味的類似検索などに変更していく予定です。
- ナレッジの重複検出:類似した情報が重複してDBに蓄積される問題を防ぐため、Cosine類似度やクラスタリングによる重複チェック機能を検討中です。
- ナレッジのメタ管理:登録日時や情報源などの属性を保持することで、鮮度や信頼性の高い知識を優先表示する構造に改善します。
- ユーザー評価の導入:対話に対してユーザーから「参考になった/ならなかった」などのフィードバックを取得し、ナレッジの重要度スコアとして反映する仕組みも検討中です。