前回はLangGraphについて、チュートリアル的にシステムを構築して動かしてみました。
LangGraphを動かして理解する|簡単なLLMアプリでノードと遷移を体験
本記事はその続編として、前回作成したシステムを発展させ、RAG(Retrieval-Augmented Generation)を活用して過去の知識を参照する仕組みを組み込んだコードをご紹介します。
1. 本記事で作成するシステム構成
本記事では以下のような対話フローに基づいて、LangGraphを用いたシステムを構築します。
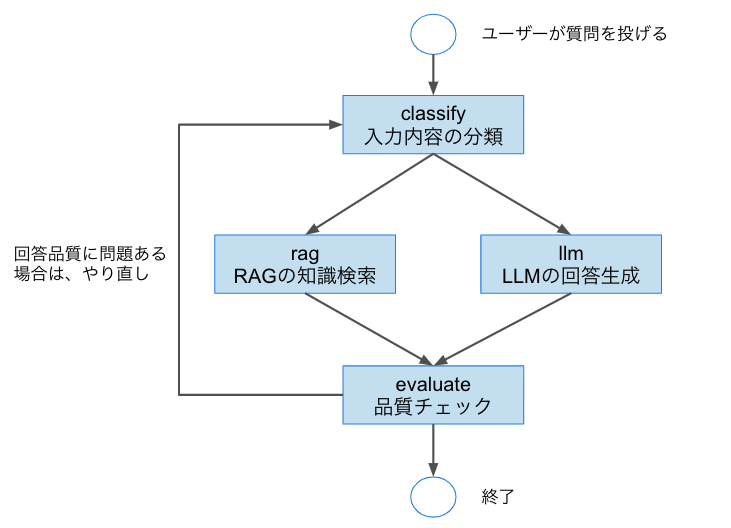
本コードでは、「ユーザーの入力に応じて、RAGを用いて過去の知識を参照し、最適な応答を返す対話エージェント」 を実装します。
登場するノードは以下の4つです。
-
classify:入力クエリがRAGで対応できる内容か、LLMによる生成が必要かを分類するノード -
rag:RAG(過去の知識ベース)から関連情報を検索し、回答を返すノード -
llm:ChatGPT APIなどを使って新たに回答を生成するノード -
evaluate:生成された回答の品質をチェックし、不十分な場合はclassifyに戻すノード
2. 環境構築
コードの説明に入る前に、まずは環境構築を行います。今回も前回と同様、**Google Colaboratory(以下「Colab」)**を使用します。
必要なPythonパッケージを以下のようにインストールしてください。
!pip install chromadb
!pip install -U langchain-community langchain langchain-openai langgraph==0.2.22
また、LangGraphの一部処理でOpenAIのChatGPT APIを利用するため、以下のように環境変数 OPENAI_API_KEY を設定してください。
import os
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
YOUR_API_KEYには自身のOpenAI APIキーを入力してください。Colabでは.envファイルではなくos.environを使うと便利です。
3. 実行コード: LangGraph
今回作成したコードは以下のGithubに格納しています。
本実行コード
3.1 ライブラリの準備
必要なライブラリをインポートします。
# LangGraph(ステート管理)、LangChain Core、およびOpenAI関連のライブラリをインポート
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
from langchain_core.runnables import RunnableLambda
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from typing import TypedDict, Literal, Optional
3.2 LLMの設定およびRAG用の知識データの準備
llm = ChatOpenAI(model="gpt-4o-mini")
# 仮のドキュメント群(検索対象)
docs = [
Document(page_content="LangGraphはLangChain製のLLM向けステートマシングラフライブラリです。"),
Document(page_content="LangChainはマルチステップ処理を管理するためのフレームワークです。"),
Document(page_content="RAGは検索と生成を組み合わせた手法です。")
]
# 分割とベクトル化
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
split_docs = text_splitter.split_documents(docs)
embedding = OpenAIEmbeddings()
# Chromaによるインデックス作成
vectorstore = Chroma.from_documents(split_docs, embedding)
3.3 状態の定義
class State(TypedDict):
input: str
intent: Optional[Literal["rag", "llm"]]
response: Optional[str]
quality_ok: Optional[bool]
- LangGraphでやり取りされる状態(State)の構造を定義します。
- ユーザーの入力や処理フローの中間情報をここで一括管理します。
3.4 各ノードの関数定義
それぞれのノードは以下の役割を持ちます。
- classify_intent → 質問の内容から「RAG」か「LLM」かを判定
- rag_node → ベクトル検索による文書検索
- llm_node → LLMによる回答生成
- evaluate_answer → 回答の品質を評価(ループ用)
# 入力文から「RAG」か「LLM」かを判定するノード
def classify_intent(state):
query = state["input"]
state["intent"] = "rag" if "資料" in query else "llm"
return state
# RAG用ノード:ベクトル検索を行い、最も類似する文書の内容を返す
def rag_node(state):
query = state["input"]
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
retrieved_docs = retriever.invoke(query)
retrieved_text = (
retrieved_docs[0].page_content if retrieved_docs else "該当する情報が見つかりませんでした。"
)
return {"response": f"[RAG] {retrieved_text}"}
# LLMで回答を生成するノード
def llm_node(state):
user_input = state.get("input", "")
messages = [HumanMessage(content=user_input)] # HumanMessageはLangChain Coreで定義されているユーザー発言のラッパー
response = llm.invoke(messages)
return {"response": response.content}
# 応答の品質を評価(ループ制御用)
def evaluate_answer(state):
resp = state["response"]
# 仮の品質評価ロジック: 括弧が含まれていたら低品質とみなす
state["quality_ok"] = False if " (" in resp else True
return state
# 応答の品質によって次のステップを判定する
def loop_or_end(state):
# quality_okがFalseなら"再度意図判定(classify)"へ、それ以外は"end"
return "classify" if not state["quality_ok"] else "end"
3.5 グラフの構築と遷移設定
# LangGraphのステートグラフを初期化
workflow = StateGraph(State)
workflow.set_entry_point("classify")
# ノード登録
workflow.add_node("classify", RunnableLambda(classify_intent))
workflow.add_node("rag", RunnableLambda(rag_node))
workflow.add_node("llm", RunnableLambda(llm_node))
workflow.add_node("evaluate", RunnableLambda(evaluate_answer))
# 条件分岐とエッジ設定(状態遷移)
workflow.add_conditional_edges("classify", lambda s: s["intent"], {
"rag": "rag",
"llm": "llm"
})
workflow.add_edge("rag", "evaluate")
workflow.add_edge("llm", "evaluate")
workflow.add_conditional_edges("evaluate", loop_or_end, {
"classify": "classify", # qualityが低ければ再判定
"end": END
})
# グラフのコンパイル(実行可能状態に変換)
app = workflow.compile()
- グラフ構築では、どのノードをどの順に実行するかを設定します。
-
loop_or_endにより、品質が低ければ再度意図判定からやり直します。
3.6 実行と結果の出力
# 入力状態を用意してステップ実行
input_state = {"input": "資料をください"}
for s in app.stream(input_state):
print(s) # 各ステップの状態を順に出力
app.stream() を使うことで、ノードごとの状態遷移を逐次的に確認できます。
各ステップでどう状態が変化していくのかを視覚的に追うのに便利です。
3.7 実際の出力例
{'classify': {'input': '資料をください', 'intent': 'rag'}} {'rag': {'response': '[RAG] RAGは検索と生成を組み合わせた手法です。'}} {'evaluate': {'input': '資料をください', 'intent': 'rag', 'response': '[RAG] RAGは検索と生成を組み合わせた手法です。', 'quality_ok': True}}
4. LangGraphの対話フローを可視化する
前回と同様に、今回のコードでも対話フローを可視化してみましょう。
以下のように必要なパッケージをインストールし、グラフを表示します。
# 必要なパッケージをインストール
!apt-get install -y graphviz libgraphviz-dev pkg-config
!pip install pygraphviz
from IPython.display import Image
# グラフの描画
Image(app.get_graph().draw_png())
実行結果は以下の通りです。

この図から、classifyノードで入力意図を判定し、ragまたはllmノードに分岐。その後、evaluateノードで品質を評価し、必要に応じて再びclassifyに戻るループ構造になっていることがわかります。
5. 次の展開
今回は、LangGraphを活用して、RAG(Retrieval-Augmented Generation)と通常のLLM生成を切り替える対話フローを構築しました。
今後は、RAGの中身をさらに作り込んでいく予定です。
たとえば以下のような方向性を検討しています。
- 外部データベースやファイル検索によるRAGの拡張
- LLMから得た情報をRAG用知識として格納する仕組みの実装
- LangGraphを活用した、柔軟で再利用可能な対話設計にもチャレンジしていきます。