プロローグ
最近、久しぶりに「プログラミングをがんばってみよう欲」が高まってきた。
形から入るタイプの僕は、オライリーの技術書が欲しくなった。
「よし、まずは立ち読みだ!」
オライリー本の取扱店を探してみる。
居住地1にある本屋にないことはわかっている。
素直に池袋のジュンク堂書店に行くべきではあるが、いかんせん、暑い。
少しでも近くにないものか?
そんな疑問を解決するためにScrapyを触ってみたお話。
ちなみに、python触るのは4年ぶりくらいで文法もあやふやですが、10分そこそこで動きました。めちゃ簡単。
成果物
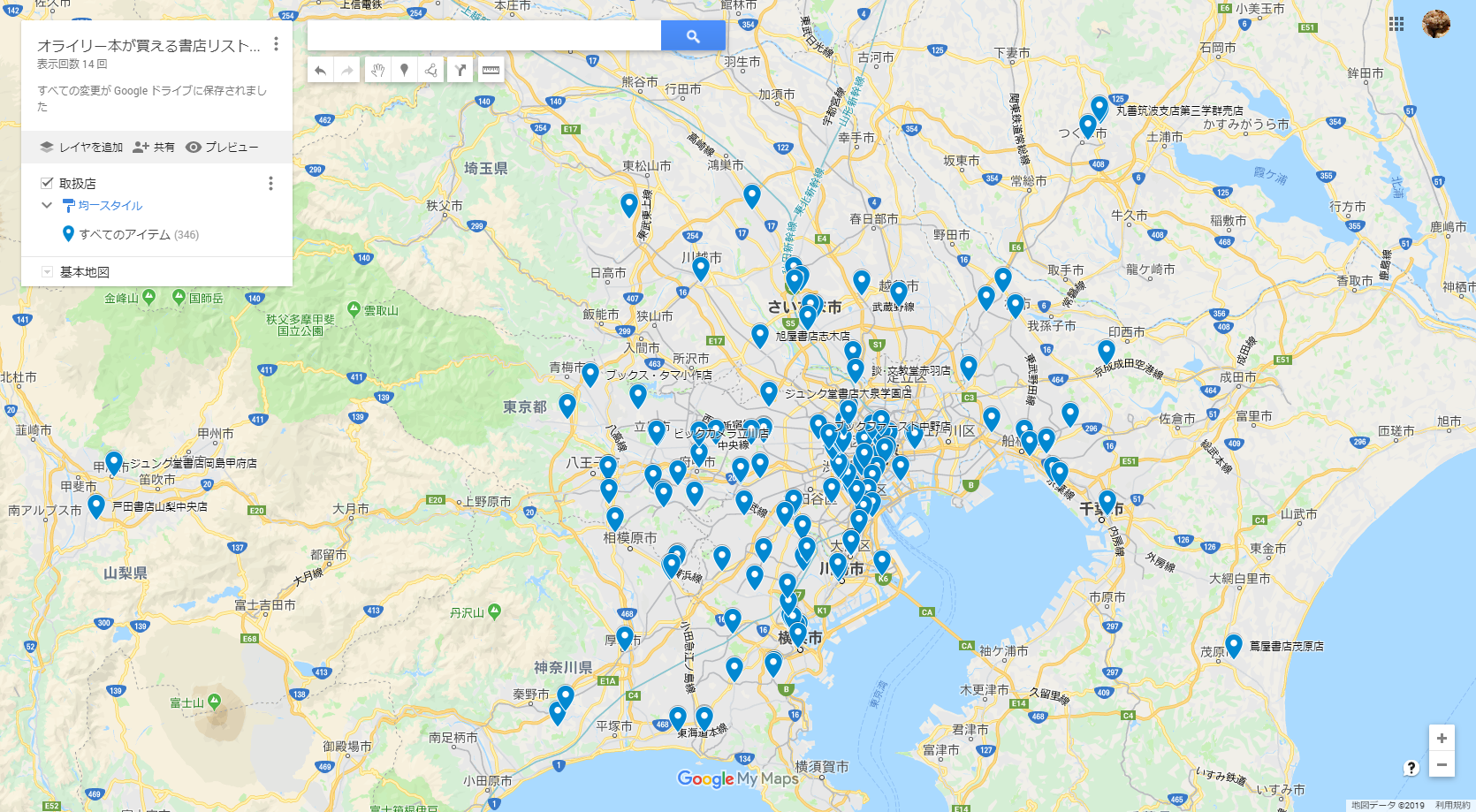
やったこと
手順1.pythonのインストール(3.7.4)
インストーラ叩いてインストール
手順2.Scrapyのインストール
PowerShellでコマンド実行
pip install scrapy
手順3.Scrapyのプロジェクト作成
PowerShellでコマンド実行
scrapy startproject GetOreilly
手順4.Scrapyのスパイダー作成
PowerShellでコマンド実行
cd GetOreilly
scrapy genspider bookstore www.ohmsha.co.jp
手順5.itemクラスの実装
実質6行
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class GetoreillyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
書店名称 = scrapy.Field()
郵便番号 = scrapy.Field()
住所 = scrapy.Field()
電話番号 = scrapy.Field()
url = scrapy.Field()
都道府県 = scrapy.Field()
手順6.spiderクラスの実装
実質22行
bookstore.py
# -*- coding: utf-8 -*-
import scrapy
from GetOreilly.items import GetoreillyItem
import re
class BookstoreSpider(scrapy.Spider):
name = 'bookstore'
allowed_domains = ['www.ohmsha.co.jp']
start_urls = ['https://www.ohmsha.co.jp/bookstore/?catid=70&cmid=748#dnn_ctr748_ModuleContent']
def parse(self, response):
prefectures_pattern = '(東京都|北海道|(?:京都|大阪)府|.{2,3}県)*'
for bookstore in response.css('.ViewProductList .storeBox'):
yield GetoreillyItem(
書店名称 = bookstore.css('H3::text').get(),
郵便番号 = bookstore.css('.firstLine .post::text').get(),
住所 = bookstore.css('.firstLine .address::text').get(),
電話番号 = bookstore.css('.secondLine .tel .spTel::text').get(),
url = bookstore.css('.secondLine .shopMapBtn span a.externalLink::attr(href)').get(),
都道府県 = re.match(prefectures_pattern, bookstore.css('.firstLine .address::text').get()).group(),
)
next_link = response.css('#dnn_ctr747_ModuleContent div ul li.Next a::attr(href)').get()
if next_link is None:
print("END OF LIST")
return
yield scrapy.Request(next_link, callback=self.parse)
手順7.実行
PowerShellでコマンド実行
scrapy crawl bookstore -o shoplist.csv
手順8.GoogleMapのマイマップにCSVをインポート
ブラウザでshoplist.csvをインポート
感想
たった10分そこそこで、アウトプットがちゃんと作れるってすごい!!
実装行数28行、8つの手順で公開までできちゃうのは感動しました。
ていうか、もっと凝ったサービス作れそうなので、引き続き、研究してみる予定。
オチ
我が家から最も近い取扱店は、「くまざわ書店武蔵小金井店」らしいのですが、
サクッとプログラムできた喜びで祝杯をあげ、昼寝して、結局、行ってません(おい)
-
東京都東久留米市(2019/8/10にアド街で紹介されました!) ↩