
概要
SUUMOにて割安な賃料物件を探しました。
調査の流れ
調査は以下の3つに分割しました。
モデル作成
使用データ
データ探索
被説明変数である賃料と、説明変数である建物種別、築年数、総戸数、階建て、公示地価、駅関連の情報、間取り、専有面積、階数のデータを探索する。
(説明数変数についてすべて記事にすると長くなってしまうので代表的なものに絞った。)
(同様の理由で今回探索するのは三軒茶屋のデータである。)
賃料

賃料の分布は右裾の長いものであった。
変動係数を計算すると0.491であった。
そこで分布の散らばりを抑えるためにlog(賃料/専有面積)という変換を施す。
log(賃料/専有面積)
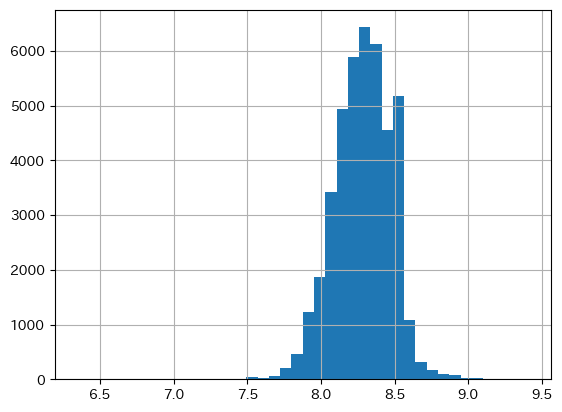
log(賃料/専有面積)の分布の形状は正規分布のようになった。
変動係数を計算すると0.0232となり、賃料に比べるとデータの散らばりを小さくすることができた。
今回のモデルの被説明変数はlog(賃料/専有面積)(以下log_平米単価と表記)に設定する。
建物種別
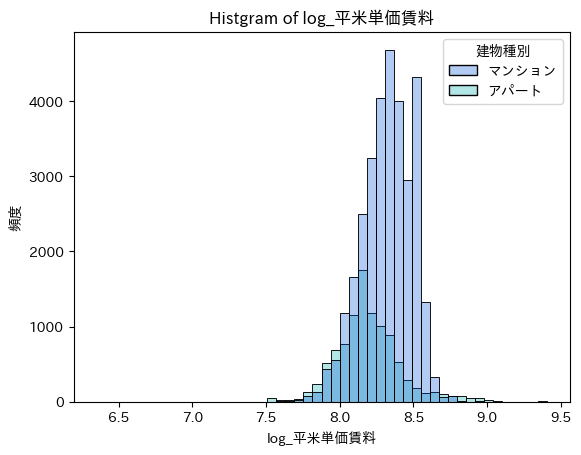
マンションとアパートでlog_平米単価の分布を比較した。
マンションは8.3あたりに、アパートは8.1あたりに集中しておりマンションの方が平均して賃料が高いことということがわかる。
築年数

横軸が築年数で、縦軸をlog_平米単価として散布図を描画した。
見ての通り、右肩下がりであり築年数が大きいほどlog_平米単価は下がるということがわかる。
相関係数を計算すると-0.58であった。
総戸数
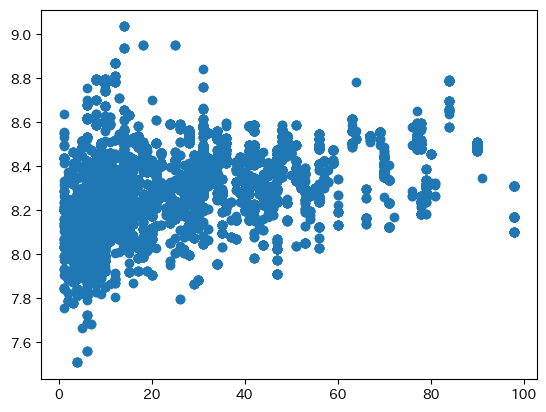
横軸が総戸数で、縦軸をlog_平米単価として散布図を描画した。
外れ値があり、両者の関係が見えづらくなっていたので総戸数<100という制約を加えている。
傾きは小さいが、若干右肩上がりになっている。(相関係数は0.381)
建物の規模が大きくなれば部屋の大きさも比例して大きくなり、その分賃料が上がるのは自然である。
階建て
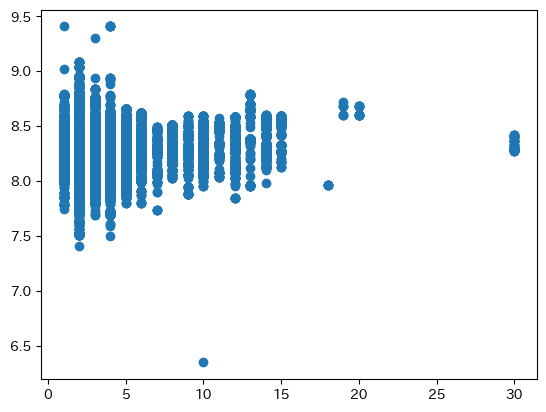
横軸が階建てで、横軸をlog_平米単価として散布図を描画した。
こちらも総戸数と同様の理由で若干賃料と比例することが推測できる。(相関係数は0.265)
公示地価
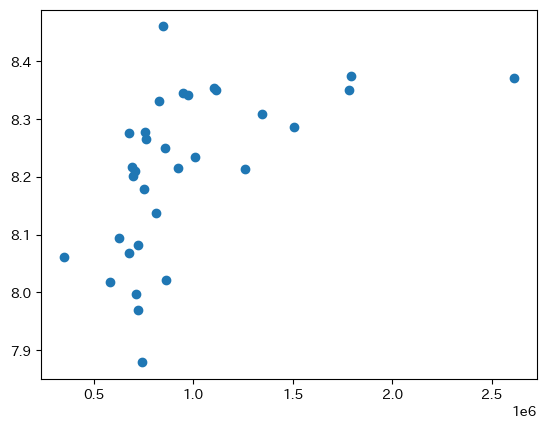
町村以前の住所ごとの公示地価とlog_平米単価の平均を求めた。
横軸が公示地価で、横軸をlog_平米単価として散布図を描画した。
両者は右方上がりの関係であり、公示地価は賃料に影響を与えることがわかる。
土地の価格が高ければその上に立つ建物の賃料が上がるのも自然である。
相関係数は0.534であった。
最寄り駅の一日の平均乗客数
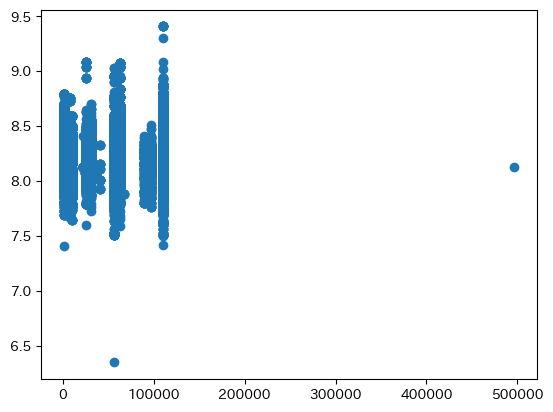
横軸が最寄り駅の一日の平均乗客数で、縦軸をlog_平米単価として散布図を描画した。
図を見るとばらつきが大きく、一日の平均乗客数と賃料とはあまり関係ないように見える。
相関係数は0.062であった。
最寄り駅と新宿駅との距離
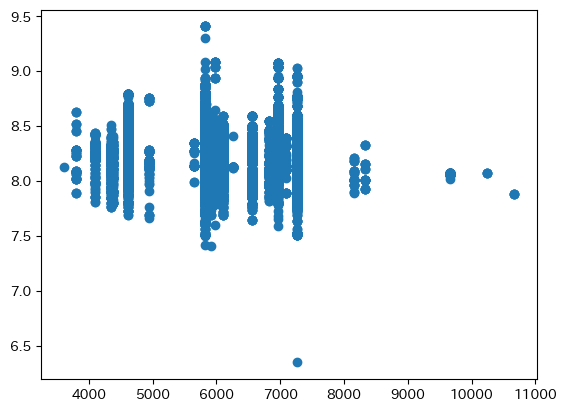
横軸が最寄り駅と新宿駅との距離で、縦軸をlog_平米単価として散布図を描画した。
図を見ると最寄り駅の一日の平均乗客数と同様に、ばらつきが大きく賃料とはあまり関係ないように見える。
相関係数は-0.128であった。
間取り
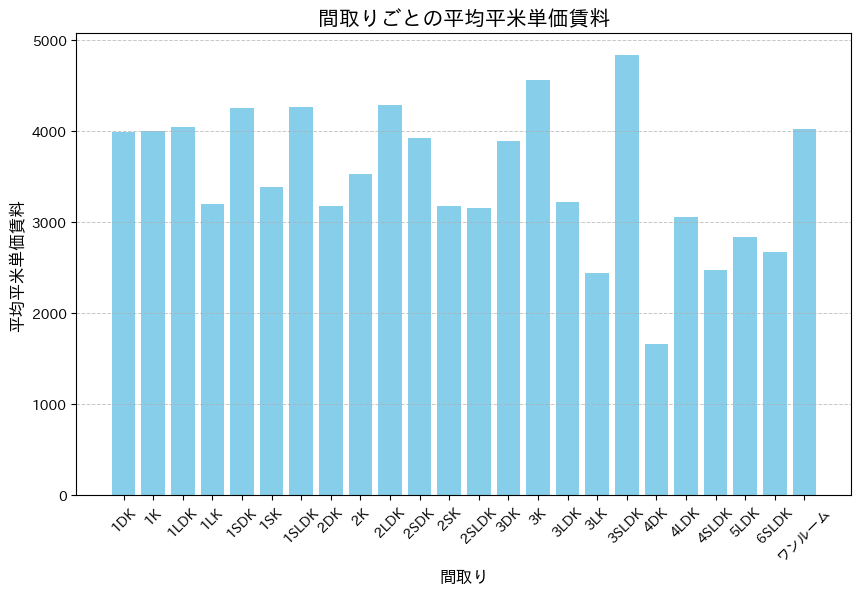
間取りごとの平米単価賃料を棒グラフで可視化した。
グラフから部屋数に応じて平米単価賃料は下がる傾向が読み取れる。特にワンルームとベッドルームが4つ以上のものを比較すると明らかである。
階数
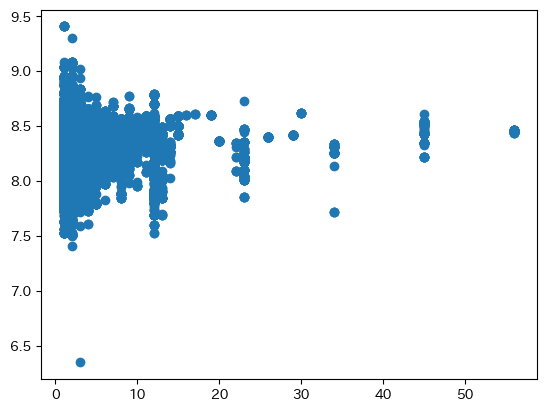
横軸が階数で、縦軸をlog_平米単価として散布図を描画した。
ばらつきが大きく、あまり両者に関係性は見受けられない。
相関係数は0.169であった。
予測
-
使用モデル
- catboost
-
全データ数
- 22339件
-
学習データ
- 14296件
-
検証データ
- 4468件
-
テストデータ
- 3575件
特徴量重要度

散布図や相関係数から被説明変数との強い関係が読み取れるものが上位にランクインしていたので納得のできるものとなった。
学習曲線

イテレーション数に応じて学習データと検証データでの誤差が縮まっているので過学習は起こしていないと考えられる。
テストデータによるモデル評価
-
MAPE
- 0.0036
- ばらつきが小さくなるように変換した影響もあると思うが、かなり誤差の小さいモデルが作成できた。
- 0.0036
-
決定係数
- 0.92
- 説明変数が57個ある影響もあると思うが、誤差も小さいので説明力の高いモデルが作成できた。
- 0.92
被説明変数の変換を解いて再度テストデータによるモデル評価
-
MAPE
- 0.029
- 変換前の10倍となっているが依然高い精度を出した。
- 0.029
-
決定係数
- 0.98
- MAPE同様に依然高い精度を出した。
- 0.98
-
誤差率のプロット
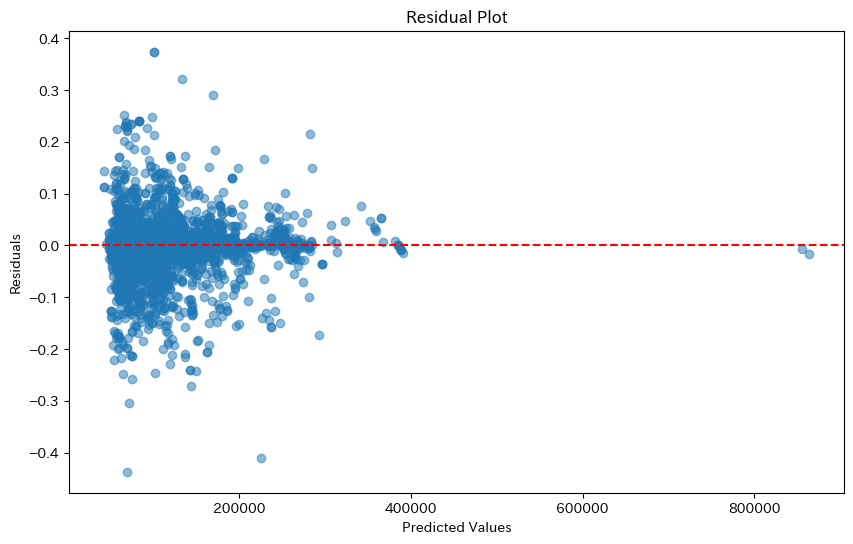
-
予測値が大きくになるにつれて、誤差率は減少しているように見える。
- 特徴量と誤差率が負の相関関係にある可能性がある。
-
誤差率が0.029以下である割合:82%
次回の記事
モデルの予測根拠を可視化するアプリを作成します。