この記事は Classi Advent Calendar 2019の20日目の記事です。
こんにちは。データAI部に所属しデータサイエンティストをしている @yosuke_ohara です。
Classiは学校教育のICT活用を支援するクラウドサービスを提供する会社ですが、教育分野におけるデータサイエンス領域ではしばしば学習者の能力値が関心の対象になります(学習者の状態を把握しないと適切な学習に導けないので、当然っちゃ当然です)。そこで、能力値推定において度々利用されるItem Response Theoryという手法を紹介しようと思います。
目次
Item Response Theoryとは
Item Response Theory(IRT:項目応答理論)は、主にテスト結果から能力値を推定するときに使われる手法で、TOEICがIRTを利用した試験として有名です。
IRTの最大のメリットは、テストをまたいだ能力値の推定を行うことができる点です。センター試験などのように受験の機会が限られているテストが現状だと大半ですが、IRTを利用することで異なるテストを受けた受験者同士も共通の評価を行うことができるようになります。そのため、タイミングを選んでテストを受けることができることが受験者にとって嬉しい点です。
ただし、テストをまたいだ推定を行うには等化と呼ばれる処理が必要になります。等化とは、異なったテストの結果を共通の原点と単位に揃える処理を指します。等化を行うためには比較テストに共通の問題(「アンカー問題」と呼びます)を入れておく必要があり、等化をどのように行うかなどを含めた設計はテストデザインと呼ばれています。
また、能力値だけでなく項目(テストにおける問題)についてもパラメータを定義して推定することが特徴です。具体的には、能力値と正答確率との間にロジスティックモデルを仮定し、項目のパラメータによってロジスティックの形が変わることで、問題毎の正答確率の違いを表現しています。ロジスティックモデルは1パラメータモデルから4パラメータモデルまで存在しますが、今回は最もよく使われる2パラメータロジスティックモデルを例に出します。
p(θ) = \ \frac{1}{1+e^{-Da(θ-β)}}…(1)\\
θが能力値、p(θ)が正答確率です。Dは積分して1にするための定数であり、項目パラメータで特に重要なのがα(識別度)とβ(難易度)です。αとβによって正答確率がどのように変わるのか具体的に見てみましょう。
1-1. 識別度とは

識別度とは、「受験者の能力をどの程度識別できるか」を表すパラメータです。言い換えると、「その問題の正誤によってどの程度能力を判定できるか」を表す値になります。
上のグラフを見ると、αが大きい曲線(緑)は、中心付近で急激に正答確率が上がっているのが見て取れます。言い換えると正答確率が50%付近となる能力値の範囲が狭く、「この問題を正解した場合は能力値が高い」と判定しやすくなります。
一方でαが小さい曲線(青)はなだらかな曲線になっており、正答確率が50%付近となる能力値の範囲が広くなっております。即ち、「この問題を正解したとしても能力値が高い」とは言いきれなくなります。
1-2. 難易度とは
 難易度は言葉の通り、項目の難しさを表します。βが大きいほど曲線がx軸の正方向に平行移動している様子が見て取れます。即ち、各曲線に対して同じ能力で正答確率を比較した場合、難易度パラメータが大きいほうが正答確率が低くなる傾向が見て取れます。
難易度は言葉の通り、項目の難しさを表します。βが大きいほど曲線がx軸の正方向に平行移動している様子が見て取れます。即ち、各曲線に対して同じ能力で正答確率を比較した場合、難易度パラメータが大きいほうが正答確率が低くなる傾向が見て取れます。
2. パラメータの推定方法
メジャーな推定方法を整理してみました(ベイジアン拡張など細かく書くとキリがないので、大きめの粒度です)。
|推定方法 |概要 |
|---|---|---|
|最尤推定法 |能力値・項目パラメータいずれかが既知であり、もう一方を推定する際に用いる方法 |
|同時最尤推定法 |能力値・項目パラメータを同時に推定する方法。尤度関数に対して「①能力値で偏微分して解く」「②項目パラメータで偏微分して解く」を繰り返すことで推定する |
|周辺最尤推定法 |同時推定において項目パラメータを推定する際に能力値パラメータで周辺化し積分消去し推定する方法。 EMアルゴリズムを用いて計算する |
最尤推定は正答確率を式(1)で定義し尤度関数を作るシンプルな方法ですが、片方のパラメータが求められているという前提になります。
同時推定はそれぞれのパラメータを一度に求めることができる方法ですが、項目パラメータの推定量が一致性を満たさないという問題があります。そのため推定精度を上げるために標本数を増やしても精度が上がらないという欠点があります。
その問題を解決するために、項目パラメータの推定時に能力値パラメータを周辺化した方法が周辺推定法であり、現在はこの方法が望ましい推定とされているようです。ただし、周辺化した際の尤度関数は陽に解くことができないため、EMアルゴリズムを用いて数値計算によって推定を行っています。
周辺最尤法によるパラメータ推定
IRTを用いた分析ができるパッケージを調べてみたところ、Pythonだとpyirt、Rだとltmやlazy.irtxが使えるようです。今回はpyirtパッケージを用いて周辺最尤法によるパラメータ推定を行ってみたいと思います。
データセットはKDDCUPで使用されたalgebra_2005_2006を使用します。DataShop@CMUは教育関連の様々なpublic_dataが用意してあり、おすすめです。また、必要なデータはBigQueryにアップロードした状態にしてあるのでpandasのread_gbqを使って読み込んでいます。
%reload_ext autoreload
%autoreload 2
import itertools
import numpy as np
import pandas as pd
from pandas.io import gbq
from pyirt import irt
# BigQueryからデータ抽出するクエリを管理しているモジュール
import queries
from tqdm import tqdm
_train = pd.read_gbq(queries.train_agg(), PROJECT_ID, dialect='standard', location="asia-northeast1")
# pyirtの場合、下記のカラム名に統一し、 [(user_id, item_id, ans_boolean)]という構造(タプルのリスト)にする必要がある
train = _train.rename(columns={
"anon_student_id": "user_id",
"question_unique_key": "item_id",
"is_correct": "ans_boolean"
})
item_param, user_param = {}, {}
problem_hierarchies = train["problem_hierarchy"].unique()
# problem_hierarchy毎にデータを分け、周辺最尤法により推定
for _problem_hierarchy in tqdm(problem_hierarchies, position=0):
train_by_problem_hierarchy = train.query("problem_hierarchy == @_problem_hierarchy").drop("problem_hierarchy", axis=1)
train_by_problem_hierarchy = train_by_problem_hierarchy[["user_id", "item_id", "ans_boolean"]].values
#irtが推定用の関数
_item_param, _user_param = irt(train_by_problem_hierarchy)
item_param.update(_item_param)
user_param.update(_user_param)
能力値(user_param),項目値(item_param)はこのように辞書形式で返されます。


BigQueryに結果を蓄積したいので、データフレームに変換してgbq.to_gbqで送ります。
user_param_df = pd.DataFrame(user_param.items(), columns=["anon_student_id", "theta"])
item_param_dict = []
for tmp_question_unique_key, param_dict in item_param.items():
item_param_dict.append({
"question_unique_key": tmp_question_unique_key,
"alpha": param_dict["alpha"],
"beta": param_dict["beta"],
"c": param_dict["c"]
})
item_param_df = pd.io.json.json_normalize(item_param_dict)
# 推定結果をBigQueryに送る
gbq.to_gbq(item_param_df,'{}.item_param'.format(DATASET), project_id=PROJECT_ID, if_exists='append', location="asia-northeast1")
gbq.to_gbq(user_param_df,'{}.user_param'.format(DATASET), project_id=PROJECT_ID, if_exists='append', location="asia-northeast1")
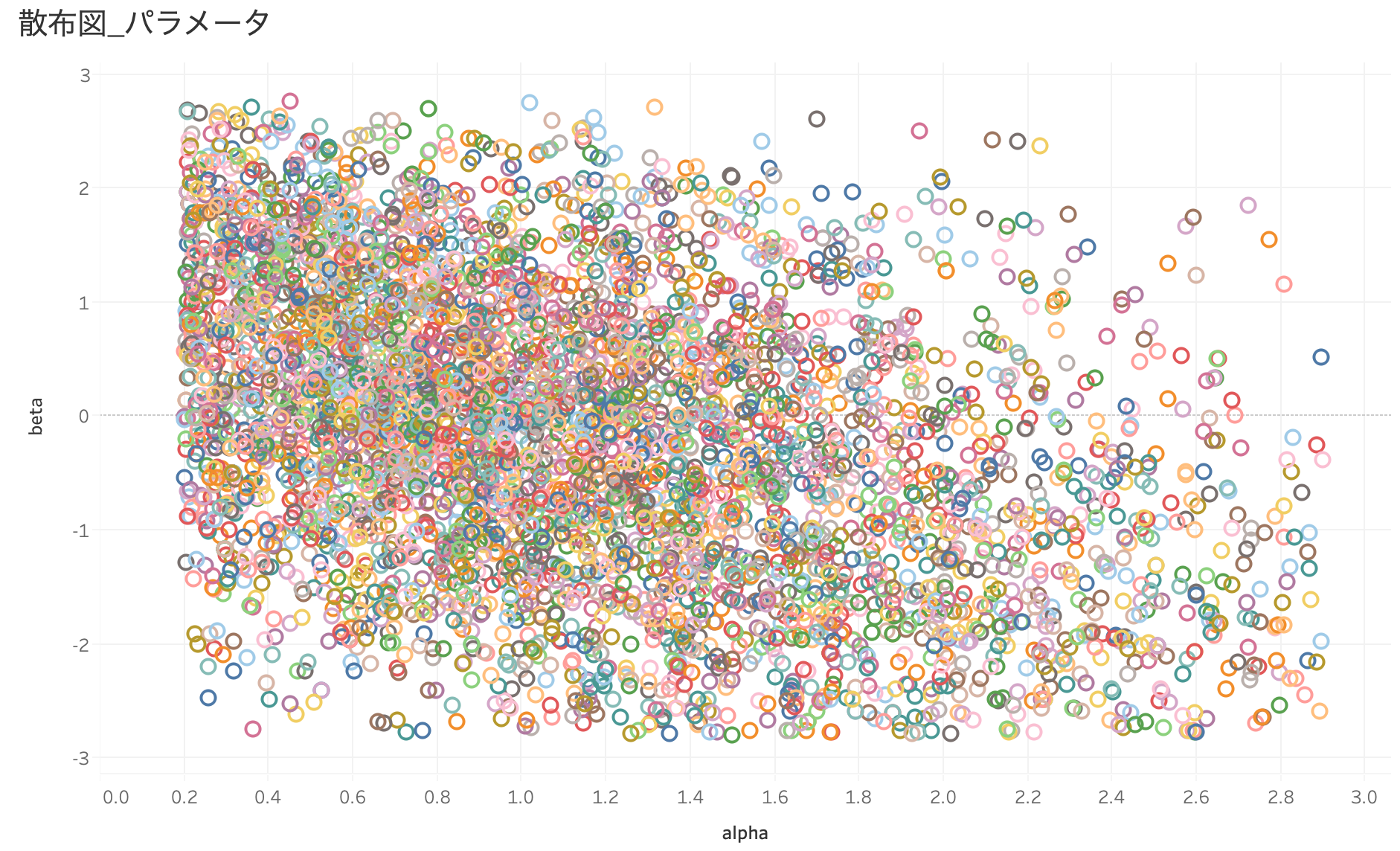
問題毎に識別度×難易度で散布図を作ってみると、識別度は0 ~ 3の範囲で、難易度は-3 ~ 3の範囲で問題毎に推定されている様子が確認できます。
IRTの課題
IRTはテストのように能力値が変化しない状況での推定には適していますが、時系列的なシチュエーション(例えば、自習などのように学習によって能力値が逐次変化していく場合)における推定は適していないという課題があります。
そこで、識別度への時間パラメータの導入や状態空間モデルで能力値の変化を記述する方法など、時系列的な拡張が行われています。
また、能力値推定の方法としてKnowledge Tracingと呼ばれる方法も頻繁に用いられています。Knowledge Tracingは能力値の推移に隠れマルコフモデルを仮定したモデルであり、遷移間の確率を条件付き確率として定義し、条件付き確率から能力値を推定することが特徴です。Knowledge Tracingを行うパッケージはpypiでは見つけられませんでしたが、pyBKT(BKT…Bayesian Knowledge Tracing)というパッケージがGitに上がっているので、試してみようと思います。
最後に
今回はIRTについての話がメインでしたが、能力値推定の分野はまだまだ歴史が浅く、他分野の手法の横転の余地がある分野だと思います。既存の方法に囚われずに、問題の定式化の仕方を変えてみたり柔軟なアプローチをしていかなければいけないとシミジミと感じます。能力値推定についてもっと知りたい方は2019年のEDM(Educational Data Mining)でAwardを受賞したこちらの論文の導入部が参考になるので是非読んでみてください。
明日は@kitaharamikiyaさんです!!