この本について
本書では、Pytorchを使って、KaggleのHouse Priceを解いていきます。
最終的な精度は0.18367です。
この本を読むことによって
データの正規化
回帰の仕方
早期終了
深層学習での回帰の仕方
が学べます。
実行環境
OS:macOS 10.15.7
開発環境:Nova(Python対応テキストエディタならOK)
パッケージのinstall:Anaconda 4.9.2
Python:3.8.3
必要なパッケージ
本書では、以下のライブラリがインストールされているとして話を進めていきます。
torch==1.6.0
numpy==1.19.2
pandas==1.1.5
scikit_learn==0.24.1
お問い合わせ
内容に関する質問は
mailto:deepblack.inc@gmail.com
までお願いします。
データの読み込み
まずは、Pandasを用いて、タイタニックのCSVを読み込みます。
import pandas as pd
data = pd.read_csv("data/train.csv")
用いる特徴量を決める、教師を確定する
次に、用いる特徴量と教師を確定します。
今回は、数値が最初から入っている、特徴量を用いました。
他の特徴量を用いて見たい場合は、この本が終わった後に自分で試してみてください。
X = data[["MSSubClass", "LotFrontage", "LotArea", "OverallQual", "OverallCond", "YearBuilt", "YearRemodAdd", "MasVnrArea", "BsmtFinSF1", "BsmtFinSF2", "BsmtUnfSF", "TotalBsmtSF", "1stFlrSF", "2ndFlrSF", "LowQualFinSF", "GrLivArea", "BsmtFullBath", "BsmtHalfBath", "FullBath", "HalfBath", "BedroomAbvGr", "KitchenAbvGr", "TotRmsAbvGrd", "Fireplaces", "GarageYrBlt", "GarageCars", "GarageArea", "WoodDeckSF", "OpenPorchSF", "EnclosedPorch", "3SsnPorch", "ScreenPorch", "PoolArea", "MiscVal", "MoSold", "YrSold"]].fillna(data.mean()).values
y = data["SalePrice"].values
MinMaxScalerによる正規化とは
以下の式による 0 ~ 1 の範囲への変換
scikit-learnによる正規化
以下の式で簡単に正規化が可能となる。
実に、簡単だ。
# データの正規化
mm = preprocessing.MinMaxScaler()
X = mm.fit_transform(X)
訓練とEarlyStoppng用のデータに分ける
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X, target, test_size=0.33, random_state=42)
モデル
Deep Learningのモデルは以下のように書けます。
自分自身で、層を増やしたり、減らしたりして試してみてください。
import torch
from torch import nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(36, 10)
self.linear2 = nn.Linear(10, 10)
self.linear3 = nn.Linear(10, 1)
def forward(self, x):
batch_size = x.shape[0]
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
out = self.linear3(x)
return out
PytorchのDatasetとDataLoader
この章では、PytorchのDatasetとDataLoaderについて解説していきます。
この章はhttps://gotutiyan.hatenablog.com/entry/2020/04/21/182937 を参考に記述されています。
Pytorchでは、DatasetとDataLoaderを用いることで、簡単にミニバッチ化をすることができます。
Datasetの実装
DataSetを実装する際には、クラスのメンバ関数として__len__()と__getitem__()を必ず作ります。
len()は、len()を使ったときに呼ばれる関数です。
getitem()は、array[i]のように[ ]を使って要素を参照するときに呼ばれる関数です。これが呼ばれる際には、必ず何かしらのindexが指定されているので、引数にindexの情報を取ります。また、入出力のペアを返すように設計します。
以上を踏まえて、Datasetを作成してみましょう。
class DataSet:
def __init__(self):
self.X = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 入力
self.t = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] # 出力
def __len__(self):
return len(self.X) # データ数(10)を返す
def __getitem__(self, index):
# index番目の入出力ペアを返す
return self.X[index], self.t[index]
さて、実際にこのDataSetがどのような振る舞いをするか試してみましょう。
dataset = DataSet()
print('全データ数:',len(dataset)) # 全データ数: 10
print('3番目のデータ:',dataset[3]) # 3番目のデータ: (3, 1)
print('5~6番目のデータ:',dataset[5:7]) # 5~6番目のデータ: ([5, 6], [1, 0])
DataLoaderの実装
バッチサイズを2、訓練時のデータのシャッフルをFalseとした実装は以下のようになります。
# さっき作ったDataSetクラスのインスタンスを作成
dataset = DataSet()
# datasetをDataLoaderの引数とすることでミニバッチを作成.
dataloader = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=False)
これでミニバッチ学習をする準備が整いました。
ミニバッチ用のデータはfor文で取り出すことができます。
for data in dataloader:
print(data)
'''
出力:
[tensor([0, 1]), tensor([0, 1])]
[tensor([2, 3]), tensor([0, 1])]
[tensor([4, 5]), tensor([0, 1])]
[tensor([6, 7]), tensor([0, 1])]
[tensor([8, 9]), tensor([0, 1])]
'''
上記のdataloaderを用いて、10epoch学習をする場合には以下のように書けます。
epoch = 10
model = #何かしらのモデル
for _ in range(epoch):
for data in dataloader:
X = data[0]
t = data[1]
y = model(X)
# lossの計算とか
PytorchのDatasetとDataloaderについての説明は、以上になります。
House PriceのDataset
import torch
class DataSet(torch.utils.data.Dataset):
def __init__(self, data, reg):
self.data = data
self.reg = reg
self.length = len(data)
def __len__(self):
return self.length
def __getitem__(self, index):
data = self.data[index]
reg = self.reg[index]
return data, reg
Early Stopping
この章は深層学習 (アスキードワンゴ) と https://github.com/Bjarten/early-stopping-pytorch を参考に書かれています。
十分な表現要領を持つ大きなモデルを訓練して、あるタスクに対して学習するとき訓練誤差は減少するが、検証誤差が再び増加し始めることがあります。
そこで、検証誤差が改善されるたびに、モデルを保存することにします。
一定のエポック数検証誤差が改善されない場合、学習は終了します。
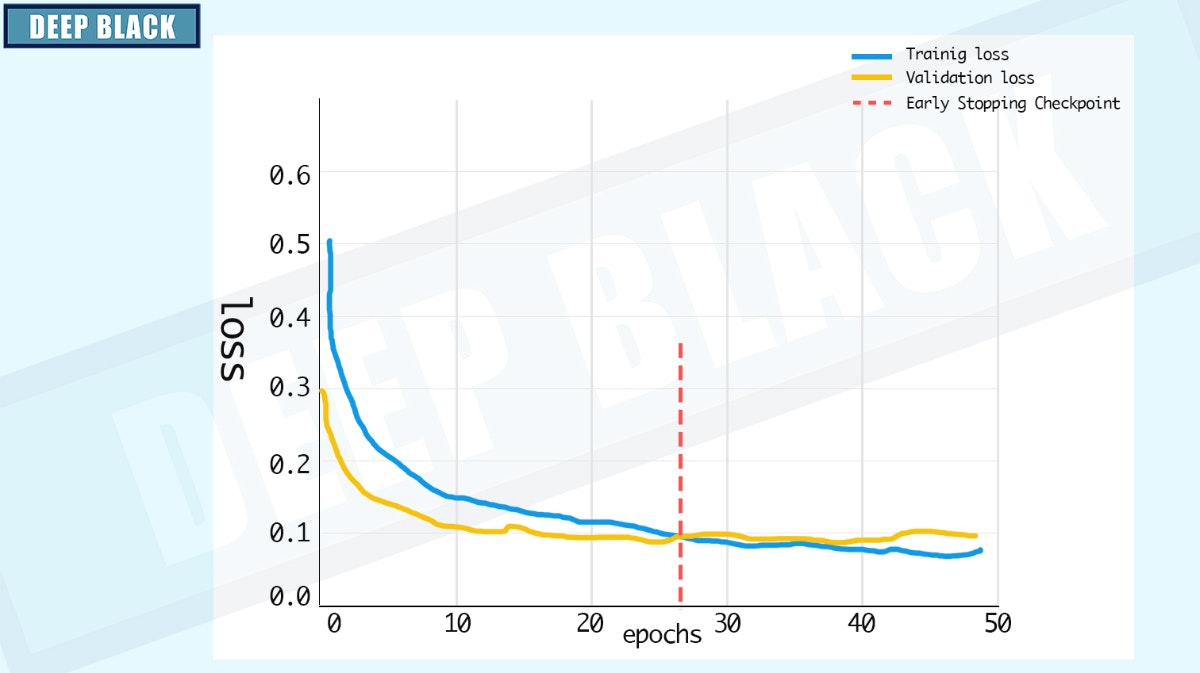
コードは以下のようになります。
以下のコードをearlystopping.pyとして保存してください。
import numpy as np
import torch
class EarlyStopping:
def __init__(self, patience=7, verbose=False):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.force_cancel = False
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score:
self.counter += 1
print(
f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
if self.verbose:
print(
f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), 'models/model.pth')
self.val_loss_min = val_loss
Deep Learningモデルの訓練
Deep Learningの訓練は以下のようになります。
for epoch in range(EPOCHS):
train_loss = 0
total = 0
model.train()
for data in trainloader:
optimizer.zero_grad()
output = model(data[0].float())
target = data[1].float()
loss = criterion(output.squeeze(), target)
train_loss += loss.item()
total += data[1].size(0)
loss.backward()
optimizer.step()
train_loss = train_loss / total
model.eval()
vali_total = 0
vali_loss = 0
for data in validloader:
with torch.no_grad():
out = model.forward(data[0].float())
target = data[1].float()
loss = criterion(out.squeeze(), data[1])
vali_loss += loss.item()
vali_total += data[1].size(0)
vali_loss = vali_loss / vali_total
earlystopping(vali_loss, model)
if earlystopping.early_stop:
print("Early stopping")
break
訓練のCode
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import pickle
import torch
from torch import nn
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from model import Model
from earlystopping import EarlyStopping
from data_loader import *
# HyperParameter
LEARNING_RATE = 0.0001
TRAIN_BATCH_SIZE = 10
VALID_BATCH_SIZE = 5
EPOCHS = 1000000
PATIENCE = 100
data = pd.read_csv("data/train.csv")
X = data[["MSSubClass", "LotFrontage", "LotArea", "OverallQual", "OverallCond", "YearBuilt", "YearRemodAdd", "MasVnrArea", "BsmtFinSF1", "BsmtFinSF2", "BsmtUnfSF", "TotalBsmtSF", "1stFlrSF", "2ndFlrSF", "LowQualFinSF", "GrLivArea", "BsmtFullBath", "BsmtHalfBath", "FullBath", "HalfBath", "BedroomAbvGr", "KitchenAbvGr", "TotRmsAbvGrd", "Fireplaces", "GarageYrBlt", "GarageCars", "GarageArea", "WoodDeckSF", "OpenPorchSF", "EnclosedPorch", "3SsnPorch", "ScreenPorch", "PoolArea", "MiscVal", "MoSold", "YrSold"]].fillna(data.mean()).values
target = data["SalePrice"].values
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
X_train, X_valid, y_train, y_valid = train_test_split(X, target, test_size=0.33, random_state=42)
model = Model()
earlystopping = EarlyStopping(PATIENCE)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE)
trainset = DataSet(X_train, y_train)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=TRAIN_BATCH_SIZE, shuffle=True)
validset = DataSet(X_valid, y_valid)
validloader = torch.utils.data.DataLoader(
validset, batch_size=VALID_BATCH_SIZE, shuffle=True)
for epoch in range(EPOCHS):
train_loss = 0
total = 0
model.train()
for data in trainloader:
optimizer.zero_grad()
output = model(data[0].float())
target = data[1].float()
loss = criterion(output.squeeze(), target)
train_loss += loss.item()
total += data[1].size(0)
loss.backward()
optimizer.step()
train_loss = train_loss / total
model.eval()
vali_total = 0
vali_loss = 0
for data in validloader:
with torch.no_grad():
out = model.forward(data[0].float())
target = data[1].float()
loss = criterion(out.squeeze(), data[1])
vali_loss += loss.item()
vali_total += data[1].size(0)
vali_loss = vali_loss / vali_total
earlystopping(vali_loss, model)
if earlystopping.early_stop:
print("Early stopping")
break
with open('models/scaler.pkl', 'wb') as f:
pickle.dump(scaler, f)
テストのCode
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import pickle
import torch
from torch import nn
from sklearn import preprocessing
from model import Model
from data_loader import *
with open('models/scaler.pkl', 'rb') as f:
scaler = pickle.load(f)
data = pd.read_csv("data/test.csv")
X = data[["MSSubClass", "LotFrontage", "LotArea", "OverallQual", "OverallCond", "YearBuilt", "YearRemodAdd", "MasVnrArea", "BsmtFinSF1", "BsmtFinSF2", "BsmtUnfSF", "TotalBsmtSF", "1stFlrSF", "2ndFlrSF", "LowQualFinSF", "GrLivArea", "BsmtFullBath", "BsmtHalfBath", "FullBath", "HalfBath", "BedroomAbvGr", "KitchenAbvGr", "TotRmsAbvGrd", "Fireplaces", "GarageYrBlt", "GarageCars", "GarageArea", "WoodDeckSF", "OpenPorchSF", "EnclosedPorch", "3SsnPorch", "ScreenPorch", "PoolArea", "MiscVal", "MoSold", "YrSold"]].fillna(data.mean()).values
ids_lst = list(data["Id"].values)
X = scaler.transform(X)
model = Model()
model.load_state_dict(torch.load("models/model.pth"))
res = model(torch.tensor(X).float()).squeeze().detach().numpy()
for i in range(0, len(ids_lst)):
ids_lst[i] = int(ids_lst[i])
sub_df = pd.DataFrame([ids_lst, res]).T
sub_df = sub_df.rename(columns={0:"Id", 1:"SalePrice"})
sub_df["Id"] = sub_df["Id"].round().astype(int)
sub_df.to_csv("sub.csv", index=False)