どうも、ドコモサービスイノベーション部ビッグデータ担当の依田です。AWS Professional、SAの方は失効しました。どう見てもスマブラ1 のやり過ぎです。
タイトル通り、Apache Spark on K8sで商用サービス展開しちゃってます。魔界2転生3してからこの2年半、切った貼ったの野良試合で流石に大変だったので、後輩に向けたハンズオン作りました。
(1) macで試すSparkとKubernetesの基礎 + 機械学習推論 それでもMacでやるんです (本編)
(2) SparkアプリケーションのビルドとAmazon EKSへのデプロイ マネージドK8sの劣等生(今冬執筆予定)
(3) Spark Streamingによる分散リアルタイム推論 ようこそ速度至上主義の教室へ(2021年執筆予定)
完結させたいのでチャンネル登録と高評価をよろしくお願いします!
1. 概要
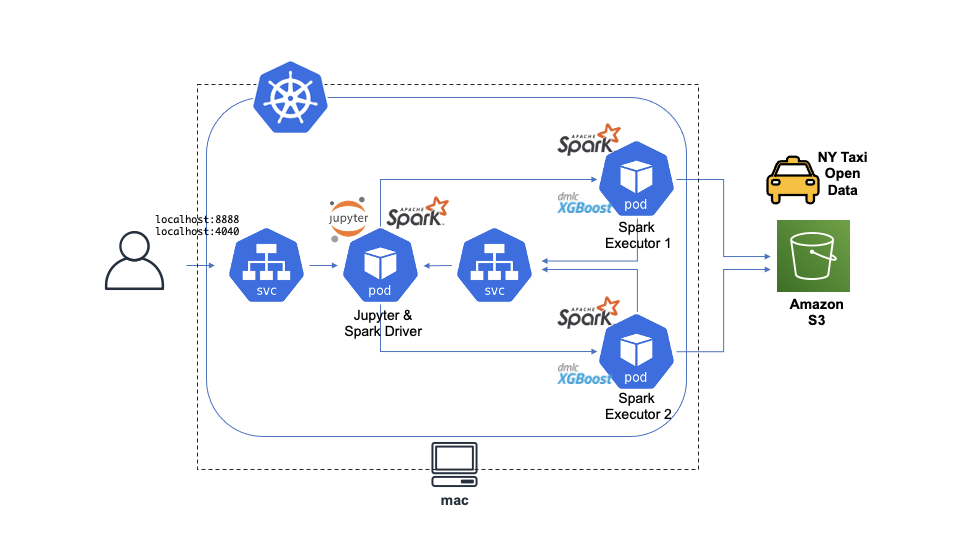
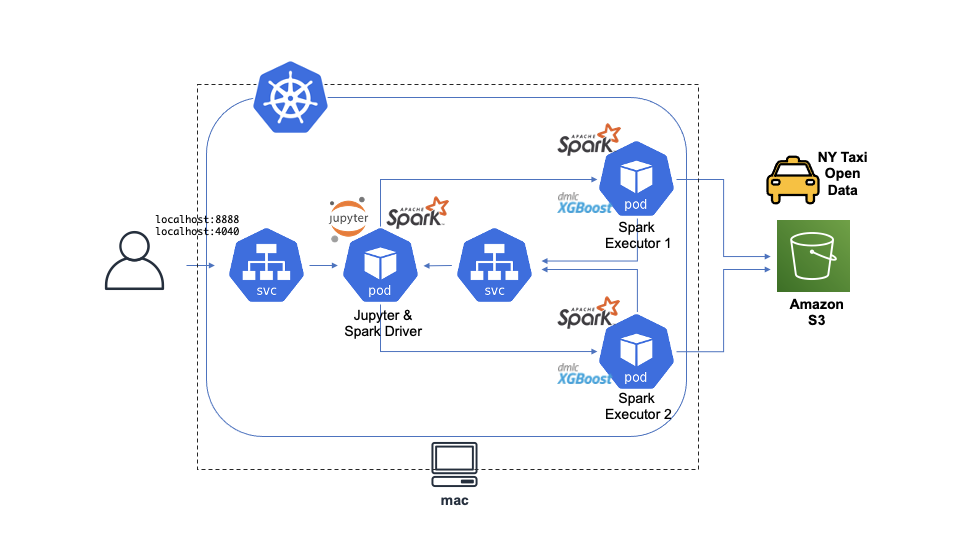
Docker for macに付属するKubernetes(K8s)の機能を使い、macにSparkクラスタを展開。
JupyterLab上からなんちゃって分散処理を体感しつつ、最終章に繋がる(予定の)XGBoostでの推論を行います。
利用言語はPython(PySpark)とScalaを交互に使いますが、SparkのAPIがよく出来ているので、意外と双方、違和感なく触れるかなと。
2. 準備
2.1. Docker for Mac with K8s
最低限、コレだけあれば大丈夫です。つまりM1 macはゴメンなさい、2020年12月現在本ハンズオンは対応していません。
(そもそもこの機能が将来、昨今話題のDepricate4等の影響で使えなくなったらこのハンズオン自体が紙きれですが。)
Docker for Macへの割り当てリソースですが、
- CPU: 4 core
- Memory: 4 GB
- Swap: 2 GB
を想定しています。余裕ある方は各項目増やせればハンズオンが捗るので増やしてみてください。DashBoardを開いて、Resources > Advancedで数を調整できます。
次に、https://docs.docker.com/docker-for-mac/#kubernetes を参考に、DashBoardからK8sをEnableにし、再起動しておきます。
2.2. kubectl
K8s を操作するのに利用するコマンドです。
Homebrewをmacにインストールしたのち
brew install kubectl
とするのが簡単かな、と思います。動作確認は、
kubectl cluster-info
とコマンドをうち、
Kubernetes master is running at https://kubernetes.docker.internal:6443
KubeDNS is running at https://kubernetes.docker.internal:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
と返ってくれば成功です。
https://kubernetes.docker.internal:6443がK8sへのリクエストを受ける、APIサーバーのFQDNになるので気に止めておいてください。
2.3. Scala/Java/Python
基本的にコンテナでアプリケーションを実行するので必ずしも必要ないのですが、ScalaやJavaもmacに入れておくと、ローカルで気になったことをお試しできるので便利と言えば便利。
- Scala: 2.12
- Java: 11
- Python: 3.8
で本ハンズオンを進めるので、揃えられればJavaだけでも。
3. ハンズオン
それではハンズオンの方を進めていきます。
3.1. Sparkイメージのビルド
定められたランタイムに従って動作する、コンテナと呼ばれる隔離環境6を管理することで、K8sはアプリケーションを制御しています。
そのためまずは、Sparkが走行するコンテナのイメージを、Dockerを用いてビルドしていきます。
SparkのDockerイメージのビルド方法はSparkのドキュメントに記されています。
- Sparkのライブラリをダウンロードページより入手
- そのライブラリ中に含まれるシェルスクリプトを、Dockerの動く環境で走行
することにより、イメージが作成されます。
ただしダウンロードできるライブラリは、今回の動作で必要のないもの(YARNなどK8s以外のリソース管理ツールのためのライブラリなど)が含まれていたり、逆に今回のハンズオンで利用したいライブラリ(Amazon S3などクラウドストレージに読み書きを行うライブラリなど)が含まれていなかったりします。
これではちと不便。
3.1.1. Sparkライブラリのビルド
なので手間と時間はかかりますが、Sparkをソースコードからビルドし、自分の欲しい機能を含んだパッケージを作ってしまいましょう。
ドキュメントに記載されているように、GitHubからソースコードをダウンロードし、シェルスクリプトを走行させればライブラリがビルドされます。
JavaやMavenを揃えてmac上でビルドしてもいいのですが、ここはせっかくなのでDockerを利用しその中でビルドしてみましょう。
適当に作業ディレクトリを作成し移動。
mkdir spark-images && cd spark-images
その中に下記のようなDockerfileを置いてください。
ARG JDK_VERSION
FROM maven:3.6.3-jdk-${JDK_VERSION} AS builder
ARG SPARK_VERSION
ARG HADOOP_VERSION
ARG HADOOP_BINARY_VERSION
ARG SCALA_BINARY_VERSION
WORKDIR /workdir
RUN git clone https://github.com/apache/spark.git
WORKDIR /workdir/spark
RUN git checkout v${SPARK_VERSION}
# From 3.0.0, default scala version is 2.12 so this will work in the case of v2.13
RUN dev/change-scala-version.sh ${SCALA_BINARY_VERSION}
RUN dev/make-distribution.sh \
--tgz \
-Dhadoop.version=${HADOOP_VERSION} \
-Pscala-${SCALA_BINARY_VERSION} \
-Phadoop-${HADOOP_BINARY_VERSION} \
-Phadoop-cloud \
-Pkubernetes \
-Pkinesis-asl
make-distribution.shに与えるオプション引数でビルド内容が変更されます。
ここではK8s、クラウドストレージ、Amazon Kinesisを利用できる様に指定してあります。
docker buildコマンドにより、SparkライブラリのビルドをDocker内で実行します。
JDK_VERSION="11"
SPARK_VERSION="3.0.1"
HADOOP_VERSION="3.2.0"
HADOOP_BINARY_VERSION="3.2"
SCALA_BINARY_VERSION="2.12"
docker build \
-f ./SparkLib.Dockerfile \
-t spark${SPARK_VERSION}-hadoop${HADOOP_VERSION}-libraries:java${JDK_VERSION} \
--build-arg JDK_VERSION=${JDK_VERSION} \
--build-arg SPARK_VERSION=${SPARK_VERSION} \
--build-arg HADOOP_VERSION=${HADOOP_VERSION} \
--build-arg HADOOP_BINARY_VERSION=${HADOOP_BINARY_VERSION} \
--build-arg SCALA_BINARY_VERSION=${SCALA_BINARY_VERSION} \
.
-tオプションに指定したように、spark3.0.1-hadoop3.2.0-libraries:java11のようなイメージが出来ているかと思います。
この中に、SparkのWebページからダウンロードできるようなtar.gzファイル(から必要のないライブラリを除いたり、AWSなどのパブリッククラウドのストレージを操作できるライブラリを加えたもの)が入っている状態です。
3.1.2. Sparkイメージのビルド
ビルド結果のtar.gzを取り出して、その中に含まれる、Dockerイメージビルド用のスクリプトを走行させます。
SPARK_LIB_IMAGE="spark3.0.1-hadoop3.2.0-libraries:java11" # 先ほどビルドしたイメージ名
SPRRK_LIB=$(docker create ${SPARK_LIB_IMAGE}) # イメージから一時的にコンテナを走行
docker cp ${SPRRK_LIB}:/workdir/spark/spark-${SPARK_VERSION}-bin-${HADOOP_VERSION}.tgz /tmp # macの/tmpディレクトリにtar.gzを取り出し
cd .. # spark-imagesの一つ上、作業ルートに行ってもらえれば大丈夫です。
mkdir spark-lib
tar -xvf /tmp/spark-${SPARK_VERSION}-bin-${HADOOP_VERSION}.tgz -C spark-lib
# KinesisをsourceにしたSpark Streamingジョブを実行したい場合、ライセンスの都合tar.gz内にパッケージされていないので、このタイミングでコピー。今回はやらなくてもいいです。
docker cp ${SPRRK_LIB}:/workdir/spark/external/kinesis-asl-assembly/target/spark-streaming-kinesis-asl-assembly_${SCALA_BINARY_VERSION}-${SPARK_VERSION}.jar spark-lib/spark-${SPARK_VERSION}-bin-${HADOOP_VERSION}/jars
docker rm -v ${SPRRK_LIB} # 不要なのでコンテナを停止
cd spark-lib/spark-${SPARK_VERSION}-bin-${HADOOP_VERSION}
./bin/docker-image-tool.sh # 簡単な実行例の表示
./bin/docker-image-tool.sh -t v3.0.1-java11 -b java_image_tag=11-jre-slim build # Java 11のDockerイメージをもとに、Sparkの走行イメージを作成
うまくいけばspark:v3.0.1-java11という名前のイメージができるハズ。
3.2. 参考:spark-shellによる動作確認
Java11をmacに入れていれば、起動確認が出来ます。
(この後Jupyter Notebookから見るのでやらなくても良いです)
先ほど解凍したライブラリ内に含まれる、spark-shellというコマンドを起動すると、Sparkとの対話実行モードのセッション(REPL)が開始します。これを用いて起動を確認します。
java -version # macにインストールされているJavaのバージョン確認、11である必要あるので注意
SPARK_IMAGE="spark:v3.0.1-java11"
cd /opt/spark/
./bin/spark-shell \
--master k8s://https://kubernetes.docker.internal:6443 \
--deploy-mode client \
--name spark-shell \
--conf spark.executor.instances=2 \
--conf spark.kubernetes.container.image=${SPARK_IMAGE} \
--conf spark.driver.extraJavaOptions=-Dio.netty.tryReflectionSetAccessible=true \
--conf spark.executor.extraJavaOptions=-Dio.netty.tryReflectionSetAccessible=true \
--conf spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider
いくつかののWarnログを経て
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.1
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.9.1)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
とScalaのREPLセッションが始まればとりあえずはうまく行っているはず。
ターミナルの別TABを開き、Pod一覧を参照してみましょう。
kubectl get pod
結果
NAME READY STATUS RESTARTS AGE
spark-shell-ad3fd57626459aa8-exec-1 1/1 Running 0 2m38s
spark-shell-ad3fd57626459aa8-exec-2 1/1 Running 0 2m38s
と、Executorが走行していればK8sとの疎通にも成功しています。
そのままREPLで、今後利用させてもらう、AWSの公開しているオープンデータを取得できるか試してみましょう。
val textFile = spark.read.textFile("s3a://nyc-tlc/misc/taxi _zone_lookup.csv").count
textFile: Long = 266
結果表示まで環境によっては少し時間はかかりますが、これで走行確認は成功です。
3.3. JupyterのK8sへのデプロイ
REPLもいいのですが、結果の保存やデータの可視化は少々苦手です。
ここはみんな大好きJupyterからSparkを操作できるようにしちゃいましょう。
そのままdocker runで起動もできるのですが、ここではK8sへとデプロイし、K8sの操作方法やリソース(の、ほんの一部)を体感してみましょう
3.3.1. JupyterLabイメージのビルド
https://hub.docker.com/r/jupyter/all-spark-notebook を利用します。
このイメージには、JupyterとSparkが同梱7されていて、JupyterからでSparkクラスタの操作も可能になっている……のですが、そのままだとS3へアクセスできません。
S3を触れるようにしたいのでここはちょっと乱暴に、同梱されているSpark関連ライブラリを丸ごと、先ほどビルドしたライブラリらに置換えます。
また適当に作業ディレクトリを作り、その中へ移動します
mkdir jupyter-lab && cd jupyter-lab
その中にDockerfileを書いて、
ARG SPARK_IMAGE
FROM ${SPARK_IMAGE} as spark
FROM jupyter/all-spark-notebook
COPY --from=spark /opt/spark/ /usr/local/spark/
RUN pip install s3fs xgboost --user # この後のステップで必要になるので入れておく
ビルドします。
docker build \
-f ./Jupyter.Dockerfile \
-t jupyter-allspark:v3.0.1-java11 \
--build-arg SPARK_IMAGE=${SPARK_IMAGE} \
.
3.3.2. JupyterLabのK8sへのデプロイ
下記のようなYAMLファイルを記述して
apiVersion: apps/v1
kind: Deployment
metadata:
name: jupyter-lab
labels:
app: jupyter-lab
spec:
replicas: 1
selector:
matchLabels:
app: jupyter-lab
template:
metadata:
labels:
app: jupyter-lab
spec:
containers:
- name: jupyter
image: jupyter-allspark:v3.0.1-java11
command: ["start-notebook.sh"]
args: ["--NotebookApp.password=sha1:323c126464df:a12dff0b86cf01c3110ce00a433dab7c9d438593"]
imagePullPolicy: Never
env:
- name: JUPYTER_ENABLE_LAB
value: "true"
ports:
- name: jupyter
containerPort: 8888
- name: spark-webui
containerPort: 4040
- name: spark-driver
containerPort: 51810
---
apiVersion: v1
kind: Service
metadata:
name: jupyter-lab
spec:
type: LoadBalancer
selector:
app: jupyter-lab
ports:
- name: jupyter
protocol: TCP
port: 8888
targetPort: 8888
- name: spark-webui
protocol: TCP
port: 4040
targetPort: 4040
---
apiVersion: v1
kind: Service
metadata:
name: spark-driver-headless
spec:
type: ClusterIP
clusterIP: None
ports:
- name: "spark-driver"
protocol: "TCP"
port: 51810
targetPort: 51810
selector:
app: jupyter-lab
kubectl applyコマンドで指定することで、JupyterLabが起動します。
kubectl apply -f jupyter-lab.yaml
deployment.apps/jupyter-lab created
service/jupyter-lab created
service/spark-driver-headless created
うまくいけばこの様な応答が返ってくると思います。
ブラウザから http://localhost:8888 にアクセスすると、Jupyterの画面が表示され、パスワードが求められるので、my-spark-on-k8sと入力すればJupyterにログインできます。
3.3.3. 簡単に解説: K8s
この辺りで???、となるかもしれませんが、とりあえずはコンテナと協調動作するリソースをYAMLで表現することで、簡単に柔軟に複数のコンテナの制御ができる、ということだけわかれば大丈夫。
このハンズオンだとmac一台しか使っていませんが、これが複数のマシンを並べた時でもYAMLとkubectlでアプリケーションのデプロイがカンタンにできるのが、K8sのうれしいトコロ。
作成したリソースについて軽く解説すると
-
Pod: Wokrloadリソース(計算するリソース)に属する最も小さなデプロイの単位。最小とはいっても、複数のコンテナをひとつのPodにまとめることができるからPod(クジラの群れ)という名称らしい。とはいえ環境変数を持たせたり、起動コマンドを指定したり、公開するポートを選択したりと、Docker単体で動かすのと同じイメージを持つと、YAML書くときは書きやすい。
-
Replicaset: Podをコピーして複数並列動作させるリソース。ただ今回はレプリカ数1なのであまり有効に働いてる実感はないかも。
-
Deployment: YAML上に記載したのはコレ。配下にReplicasetを、なのでさらに配下にPodを持つ。配下のPodの更新を、Deployment を使うとうまくローリングしながらアップデートできたりする。(他所だとどうか分かりませんが、うちのチームは基本デプロイの単位はコレ。名前Deploymentだし)
-
Service: 起動したコンテナを外部へと公開するためのリソース。K8sのPodらは基本的にはそのままでは外部からアクセスできないのですが、Serviceを作成することでユーザーがブラウザからアクセスするなどが可能にいなります。Serviceにもいくつか種類があり、今回はまずJupyterやSparkのWeb UIへアクセスするためのLoadBlancerを作成しています。さらにHeadless Serviceと呼ばれる、他のPodから対象となるPodへのFQDNによるアクセスを可能にServiceを起動しています。これを介し、SparkのExecutorがDriverであるJupyterコンテナへとアクセスを行っています(ExecutorからDriverへの通信はホスト名が必要となるため)。
記事の最初にも貼りましたが、こんな感じのイメージです。
kubectlについて、よく使う物を一通りさらっておきましょう。
kubectl get pod # Pod一覧の取得
NAME READY STATUS RESTARTS AGE
jupyter-lab-5ddfbc9db9-tvzqv 1/1 Running 0 2m49s
ローカルでの接続チェックをした人は先ほど打っていると思いますが、Podの一覧を取得するコマンドになります。明示的に指定しない限り、YAMLで指定した名称に乱数が付与された名前になっていると思います。
kubectl describe pod jupyter-lab-5ddfbc9db9-tvzqv # Podの詳細の表示。乱数はPod作成ごとに異なるのでコピペしない様注意
Name: jupyter-lab-5ddfbc9db9-tvzqv
Namespace: default
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> Successfully assigned default/jupyter-lab-5ddfbc9db9-tvzqv to docker-desktop
Normal Pulled 3m35s kubelet, docker-desktop Container image "jupyter-allspark:v3.0.1-java11" already present on machine
Normal Created 3m35s kubelet, docker-desktop Created container jupyter
Normal Started 3m35s kubelet, docker-desktop Started container jupyter
何か動作おかしいな、と思ったら、describe podの最後の項目、Podに発生したEventsを見てみるのが基本です。コンテナが起動しすぎていて、リソースが足りない、みたいなことはよくあります。
コンテナ自体は正常に動いている様に見える・・・というときは、Podのログを確認したり、Podに接続してコマンドを試してみたりします。
kubectl logs jupyter-lab-5ddfbc9db9-tvzqv # 標準出力にPodが出しているログを確認
kubectl exec -it jupyter-lab-5ddfbc9db9-tvzqv bash # Pod内部へ接続
Jupyterを止めたいときは、Deploymentごと消す様にしましょう。Podを消してもReplicasetの効果で再び立ち上がってきてしまいいます。また、作業自体を止めるのならServiceも消しておきましょう。
今は打たなくてもいいです。
kubectl delete deployments.apps jupyter-lab
kubectl delete -f jupyter-lab.yaml # YAMLに記載されていたリソースを全部削除
打っちゃった人はkubectl applyで再び立ち上げておいてください。
3.4. PySparkによるデータ操作
最近だと、データサイエンティストはPython(やR)を利用する人が多いかな、といった印象です。
先ほど起動したJupyterで、Sparkの開発言語たるScalaを操作も出来るのですが、ここではまずPythonを、つまりPySparkを利用してのデータ操作を体感してみましょう。
(この後見て貰えばわかりますがSparkのAPIはよくできているので、分析用途ならあんまり言語はこだわらなくて良いかな、と思います)
3.4.1 Executorの起動と動作確認
適当な名前でPythonのNotebookを作成し、最初のセルに
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.master('k8s://https://kubernetes.docker.internal:6443') \
.appName('pyspark') \
.config('spark.driver.extraJavaOptions', '-Dio.netty.tryReflectionSetAccessible=true') \
.config('spark.driver.host', 'spark-driver-headless.default.svc.cluster.local') \
.config('spark.driver.port', 51810) \
.config('spark.executor.extraJavaOptions', '-Dio.netty.tryReflectionSetAccessible=true') \
.config('spark.executor.instances', 2) \
.config('spark.hadoop.fs.s3a.aws.credentials.provider', 'org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider') \
.config('spark.kubernetes.container.image', 'spark:v3.0.1-java11') \
.getOrCreate()
sc = spark.sparkContext
と各種設定を入力し実行、初期化します。
-
masterの値にK8sのAPIサーバーのFQDNを設定。これにより、Jupyter(driver)が、Executor起動のコールを行えるようになる - Headless Serviceを経由しDriverへと通信できるように
driver.hostとdriver.portを指定 - 起動するExecutorコンテナ数は2つ
- パブリックなS3へとアクセスするために空値のクレデンシャルをセット
- Executorのイメージには、
spark:v3.0.1-java11を利用
というのが、抑えるべきポイントです。
またこのタイミングでPodを表示してみると、ExectorのPodが起動しているかなと思います。
kubectl get pod
NAME READY STATUS RESTARTS AGE
jupyter-lab-5ddfbc9db9-tvzqv 1/1 Running 0 40m
pyspark-6e181b764a13babe-exec-1 1/1 Running 0 22s
pyspark-6e181b764a13babe-exec-2 1/1 Running 0 21s
AWSがホストするオープンデータへアクセスし、動作しているか確認をとってみましょう
text_file = spark.read.text('s3a://nyc-tlc/misc/taxi _zone_lookup.csv')
text_file.count()
少し待ったのち、266と値が帰ってくれば成功です(ファイルをS3から取得するので時間がかかります)。
3.4.2. DataFrames操作
それではSparkを利用してデータの操作をしてみましょう。
SparkではRやPandasののように、テーブル形式で表現されたDataFramesを通じての操作が可能です。
(それよりも低レベルなデータ構造もいじれますが、今回ははこちらで大丈夫)
対象のデータとして、先ほど動作チェックで利用しましたが、AWSが公開データとしてホストしているNew York City Taxi and Limousine Commission (TLC) Trip Record Dataを利用します。
ニューヨークのタクシー乗降に関するデータを公開していて、AWSサービスのチュートリアルにもよく使われるデータかな、といった感じです。
タクシーの種類によっていくつかに分類されているのですが、映画でよく見る、マンハッタン内を主に走るイエロータクシーのデータが格納されたcsvを利用します(ググってみるとこの辺の経緯面白いです)。
CSVファイルのカラムの定義はここに記載された通り。コレに従い、まずは各列のデータ型、つまりスキーマを定義します。
from pyspark.sql.types import StructType, StructField, IntegerType, DoubleType, StringType, TimestampType
schema = StructType([
StructField('vendor_id', IntegerType() , True),
StructField('tpep_pickup_datetime', TimestampType() , True),
StructField('tpep_dropoff_datetime', TimestampType() , True),
StructField('passenger_count', IntegerType() , True),
StructField('trip_distance', DoubleType() , True),
StructField('rate_code_id', IntegerType() , True),
StructField('store_and_fwd_flag', StringType() , True),
StructField('pu_location_id', IntegerType() , True),
StructField('do_location_id', IntegerType() , True),
StructField('payment_type', IntegerType() , True),
StructField('fare_amount', DoubleType() , True),
StructField('extra', DoubleType() , True),
StructField('mta_tax', DoubleType() , True),
StructField('tip_amount', DoubleType() , True),
StructField('tolls_amount', DoubleType() , True),
StructField('improvement_surcharge', DoubleType() , True),
StructField('total_amount', DoubleType() , True),
StructField('congestion_surcharge', DoubleType() , True),
])
次に、S3上にあるデータを、定義したスキーマに従い、DataFramesへと変換します。
(データ量が少ない2020年のデータを利用、おそらくコロナのせい...)
df_yt_202006 = spark.read.format('csv').schema(schema) \
.option('delemiter', ',') \
.option('header', 'true') \
.option('timestampFormat', "yyyy-MM-dd HH:mm:ss") \
.load('s3a://nyc-tlc/trip data/yellow_tripdata_2020-06.csv')
Sparkでは実際にデータを読み込み始めるのは、そのデータが必要になってから(遅延評価)なので、この時点ではデータの読み込みは実は走っていません(Notebookのセルも一瞬で完了するかと思います)。下記に示すような操作を行ったタイミングで、初めてデータが読み込まれ(今回の場合はS3から取得され)ます。
df_yt_202006.show() # 最初の20行表示
df_yt_202006.show(50) # 行数指定
df_yt_202006.first() # 最初の1行
df_yt_202006.tail(10) # 末尾10行: 時間がかかる
df_yt_202006.filter(df_yt_202006['passenger_count'] >= 7).show() # 7人以上乗客。ミニバンとかならわかりますが…
対話的に実行している場合何度もデータ読み込みが走り遅く感じることもあるかと思います。メモリが潤沢であれば、メモリ上によく使うDataFramesをキャッシュすることで高速化を図ることも可能です。
遅延評価のため、キャッシュ命令後、対象のDataFramesに対し一度計算が走ったのち、初めてキャッシュを利用することが可能な点に注意。
# Jupyterなら、セルごとにわけ、%%timeを先頭行に挟めば実行時間計測ができます
df_yt_202006.filter(df_yt_202006['passenger_count'] >= 7).count() # 30秒くらい
df_yt_202006.cache() # キャッシュ命令。
df_yt_202006.filter(df_yt_202006['passenger_count'] >= 7).count() # 30秒くらい、この操作完了後にキャッシュされる
df_yt_202006.filter(df_yt_202006['passenger_count'] >= 7).count() # 300ミリ秒くらい、大幅短縮
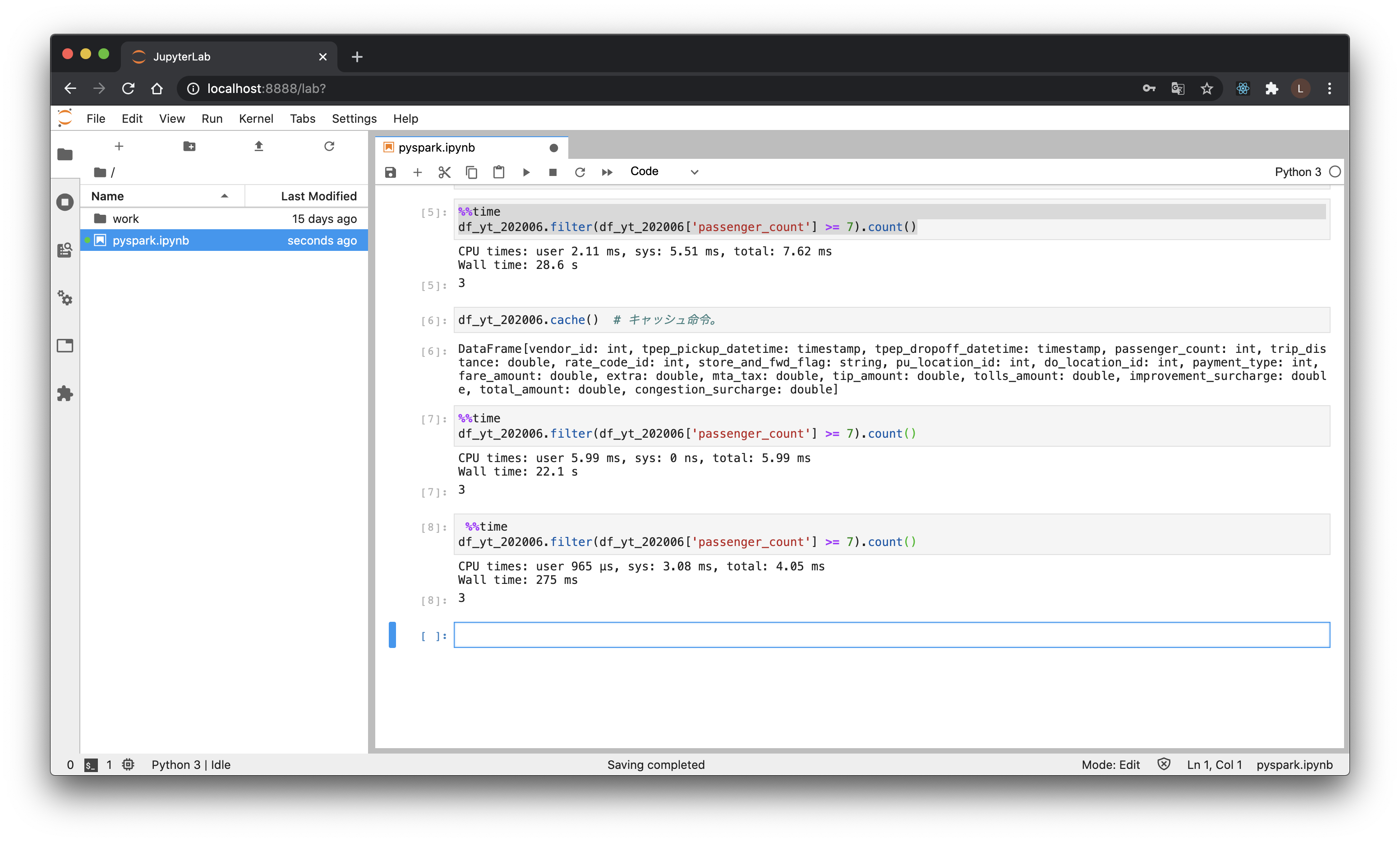
遅いのが嫌な人は、これ以後とりあえずdf_yt_202006をキャッシュに入れておいてください。
メモリが心許ない人は下記の手順で外しておきましょう。
df_yt_202006.unpersist() # パージ
from pyspark.sql import SQLContext
SQLContext.getOrCreate(sc).clearCache() # 全キャッシュ強制パージしたい場合はこちら
df_yt_202006.filter(df_yt_202006['passenger_count'] >= 7).count() # また30秒くらい
3.4.3 Spark SQLによる操作
より複雑な操作についても、SQLで表現、実行が可能です。この辺がSparkのすごいトコロ。
createOrReplaceTempView()のコールにより、そのセッション内で有効な、SQLを発行可能なテーブルが作成されます。
df_yt_202006.createOrReplaceTempView('yellow_tripdata_2020_06') # 引数に与えたのがテーブル名になる
乗車運賃の高い順に、時刻や距離を表示してみます。
df = spark.sql(
"""
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
trip_distance,
pu_location_id,
do_location_id,
total_amount
FROM
yellow_tripdata_2020_06
ORDER BY
total_amount DESC
LIMIT
10
"""
)
df.show() # 使い捨てDataFramesはコレ以後dfとしますので、ノートブックで実行するときは前後注意。
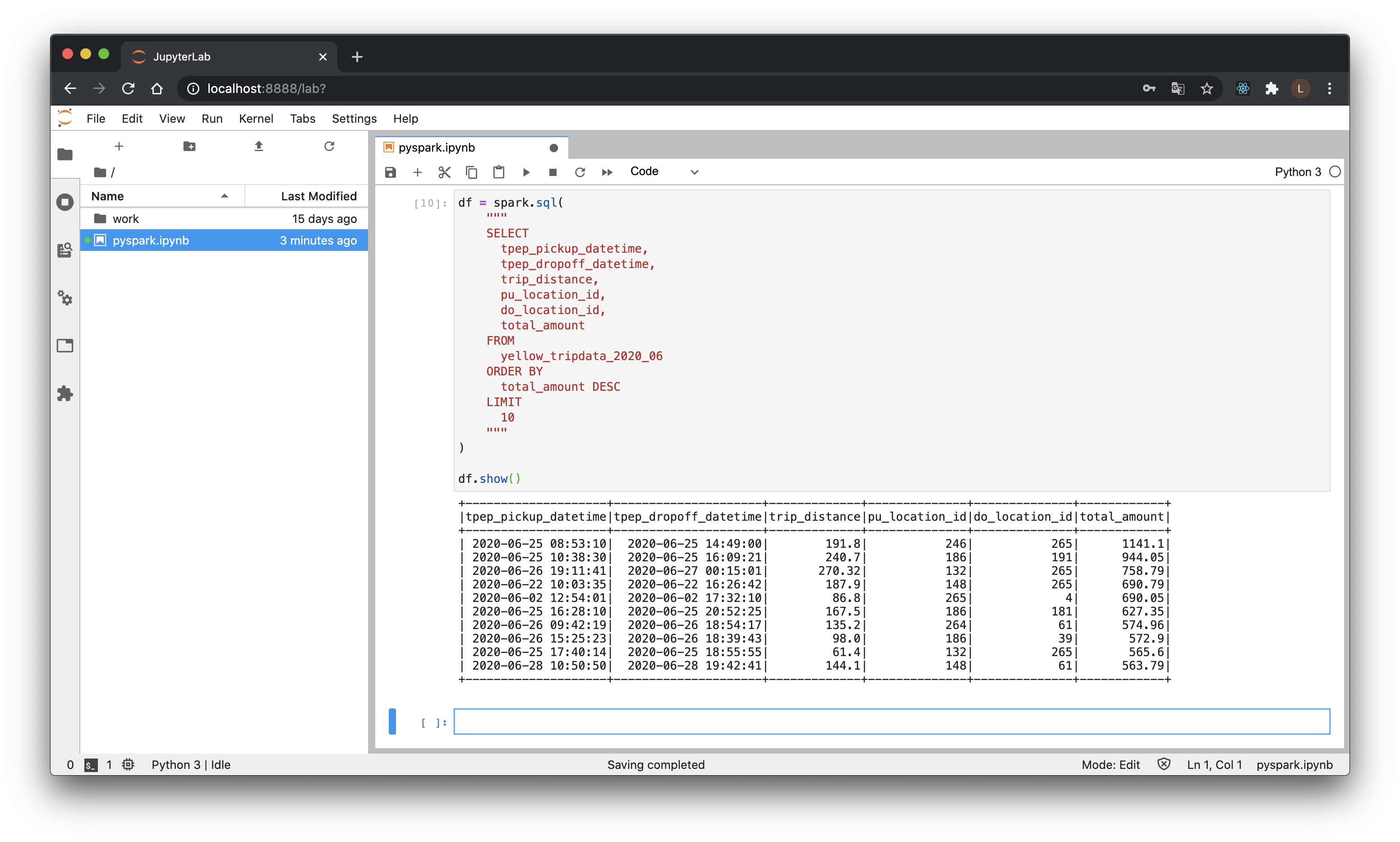
6時間、200マイル近く走って、合計約1100ドルってホントかよって感じですよね
PickUp/DropOffした場所がわからないので、別テーブルをロードしてJOINしてみましょう。
df_tzone_lookup = spark.read.format('csv') \
.option('delemiter', ',') \
.option('header', 'true') \
.option('inferschema', 'true') \
.load('s3a://nyc-tlc/misc/taxi _zone_lookup.csv')
inferschemaをONにするとスキーマを推定してくれます。使い捨てのときに便利。
(推定する都合少し時間がかかるのと、カラム名や型が、例えばGitHub上のコードからは見れなくなったりしてしまう点には注意)
df_tzone_lookup.createOrReplaceTempView('taxi_zone_lookup')
df_joined = spark.sql(
"""
SELECT
tpep_pickup_datetime,
tpep_dropoff_datetime,
trip_distance,
pu_location_id,
pu_lookup.Zone AS pu_zone,
do_location_id,
do_lookup.Zone AS do_zone,
total_amount
FROM
yellow_tripdata_2020_06
LEFT JOIN
taxi_zone_lookup AS pu_lookup
ON
pu_location_id = pu_lookup.LocationID
LEFT JOIN
taxi_zone_lookup AS do_lookup
ON
do_location_id = do_lookup.LocationID
ORDER BY
total_amount DESC
"""
)
df_joined.show()
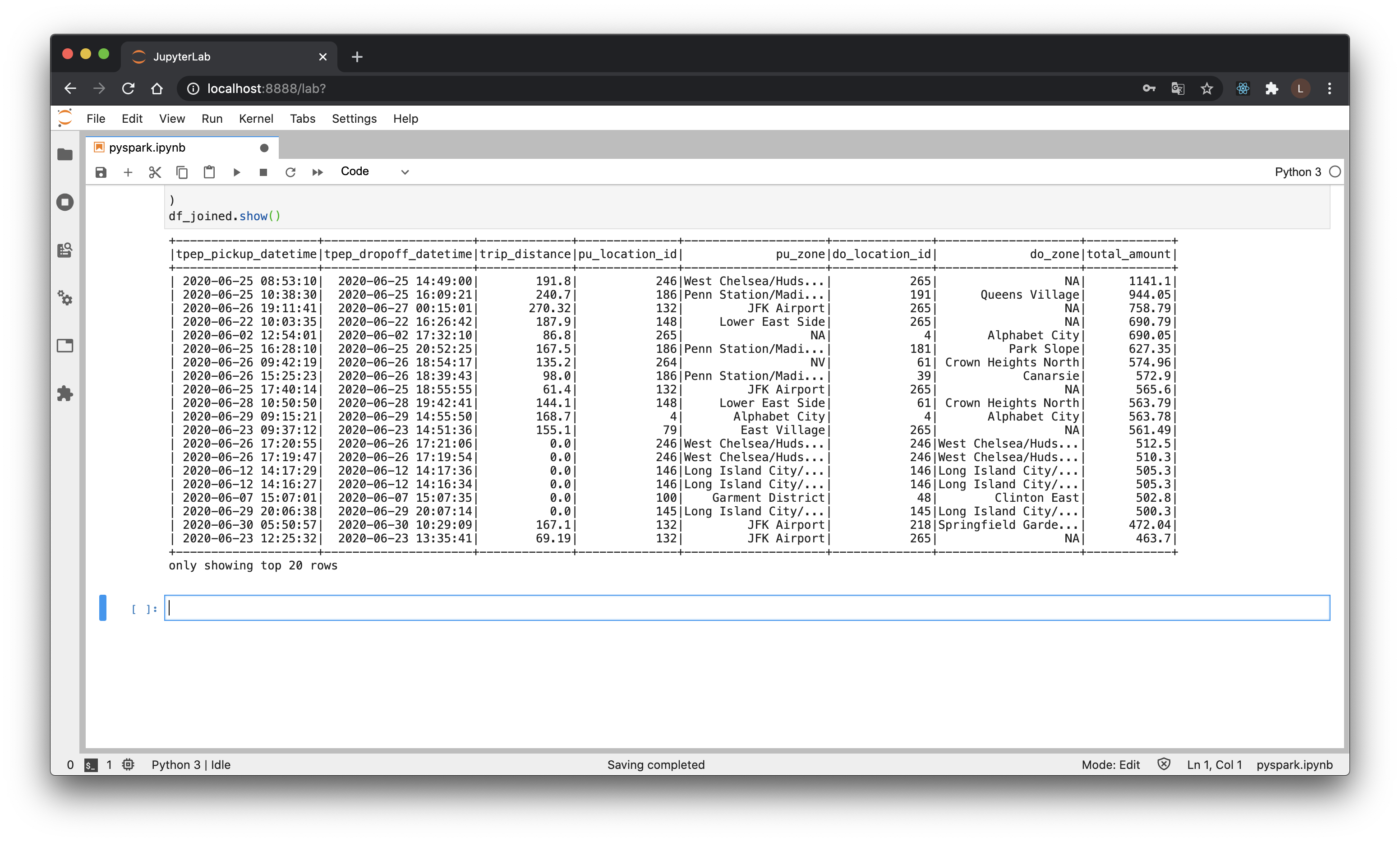
やはりというか、乗降場所がNAになっていますね。州外にでたか(行けるのか?)、外れ値か、でしょうか。
Pandasへの変換も可能なので、Jupyter上での可視化も可能です。サンプリングしたのちPandas Dataframeへ変換し、可視化してみます。(今回はBokehを使用)
df = df_joined.select(['trip_distance','total_amount']) \
.sample(fraction=(1000/df_joined.count())) \
.toPandas()
from bokeh.plotting import figure, output_notebook, show
output_notebook()
p = figure(
title='Trip Distance VS Total Amount',
x_axis_label='Trip Distance [Mile]',
y_axis_label='Total Amount [$]'
)
p.circle(df['trip_distance'], df['total_amount'])
show(p)
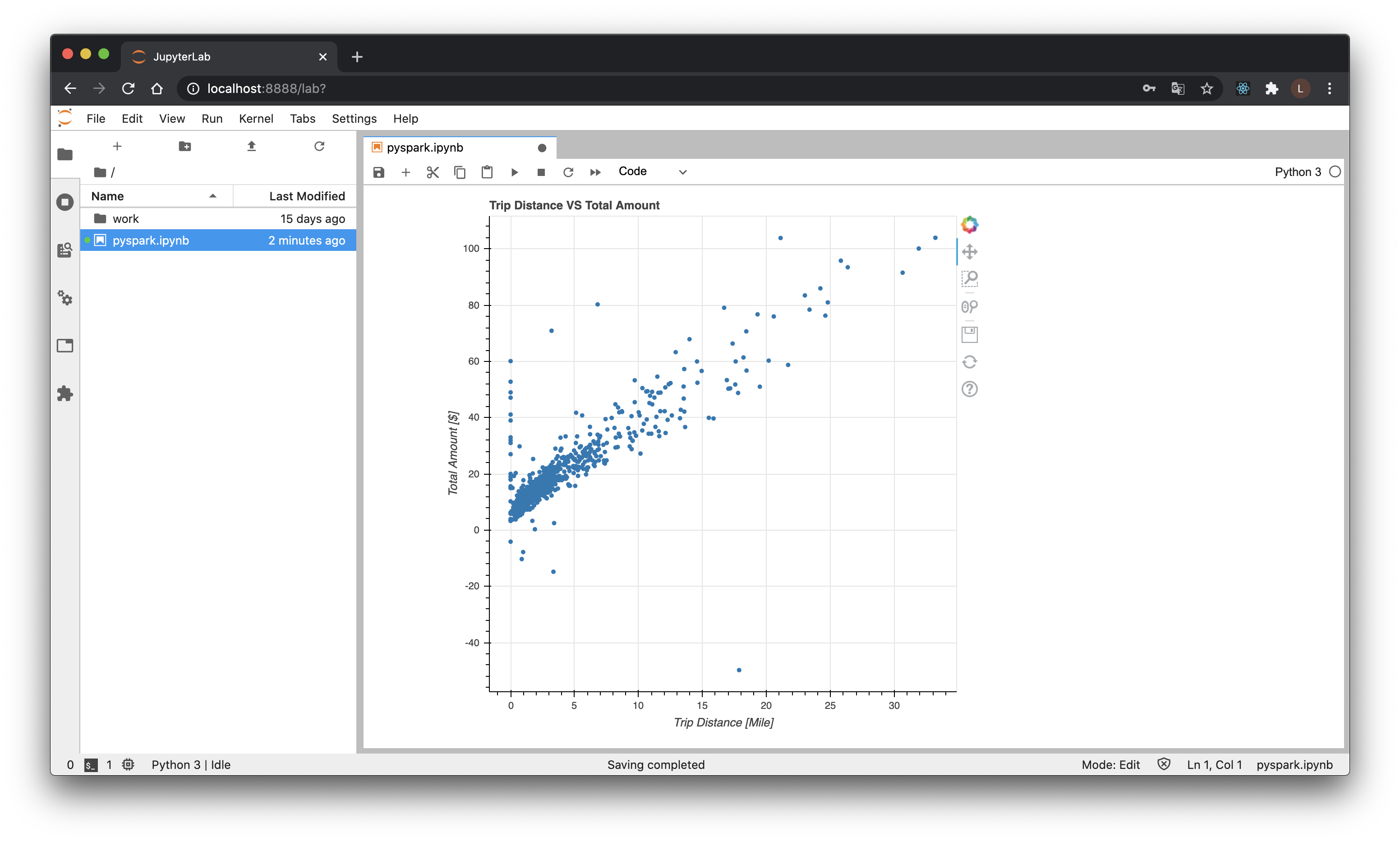
相関はありそうというのと、距離が0なのに課金されていたり、走行しているのにマイナス課金のものがあったりしそうですね。前処理必要そう(だがやらない)。
3.4.3. 複数ファイルの読み取り
macのメモリだと、あまりたくさんのデータを読むと大変なことになりますが一応紹介。
# リスト形式
df = spark.read.format('csv').schema(schema) \
.option('delemiter', ',') \
.option('header', 'true') \
.option('timestampFormat', "yyyy-MM-dd HH:mm:ss") \
.load([
's3a://nyc-tlc/trip data/yellow_tripdata_2020-04.csv',
's3a://nyc-tlc/trip data/yellow_tripdata_2020-05.csv',
's3a://nyc-tlc/trip data/yellow_tripdata_2020-06.csv',
])
# パターンマッチ
df = spark.read.format('csv').schema(schema) \
.option('delemiter', ',') \
.option('header', 'true') \
.option('timestampFormat', "yyyy-MM-dd HH:mm:ss") \
.load('s3a://nyc-tlc/trip data/yellow_tripdata_2020-0{[4-6]*}.csv')
df.count()すると、1,136,124と出てくるはず。もしこれがもっと大量のファイルで、それを高速で処理したい時はどうすれば・・・というのがSparkと、K8sをを使う理由になっています。
完了したら、Notebook上のRestart the Kernelボタン(更新マーク)を押して、このセッションを切っておいてください(リソースを開けるため)。
ExecutorのPodも消えるとは思いますが念のため、kubectl get podを使って、Executorの存在をチェック、消えていないようならkubectl delete pod xxxで落としておいてください。
3.5. XGBoostによる推論
Sparkを利用すれば、分散しての機械学習関連のタスクも実行可能です。
データサイエンティストから提供されたモデル(Pythonで学習)を、DataFramesに対して適用し、Scalaで推論する…のようなタスクをイメージして進めます。
3.5.1. モデルの準備
Sparkを使えば分散しての学習も可能、だったりするのですがページ数増えちゃうのでここは簡単に、手元でモデルを用意しちゃいます。
2020年4月のデータを使ってtrip_distance, pu_location_id, do_location_id,を説明変数に、total_amountを予測する回帰モデルを作ってみます
そのままK8sで展開したJupyter上で実行する場合、メモリが足りなくなるかもしれません。その場合、
- 保存しておきたいNotebookをダウンロードするなどして保存した後、
kubectl delete -f jupyter-lab.yamlでJupyterを落とす。 -
docker run --rm -p 8888 jupyter-allspark:v3.0.1-java11 jupyter-labで、Jupyterを、Dockerに割り当てられているリソースを集中して当たるようにして起動、アクセス
するなどしてください。
下記適宜小分けにして、実行します。
from sklearn.model_selection import train_test_split
import pandas as pd
import xgboost as xgb
"""
パラメータ
"""
# ハイパーパラメータ、この後チューニングしていく
params = {
'max_depth':6,
'min_child_weight': 1,
'eta':.3,
'subsample': 1,
'colsample_bytree': 1,
'objective':'reg:squarederror',
}
params['eval_metric'] = 'mae' # 評価関数をMAEに
# 上記以外のパラメータ
num_boost_round=999 # 大きめの値を入れて最適化していく
early_stopping_rounds = 10 # 過学習回避のための打ち切り
nfold = 5 # 交差検証の回数
# 最適パラメータの格納先
best_params = {
'max_depth': None,
'min_child_weight': None,
'subsample': None,
'colsample_bytree': None,
'eta': None,
}
"""
データ準備
"""
df = pd.read_csv(
's3://nyc-tlc/trip data/yellow_tripdata_2020-04.csv'
)[['trip_distance', 'PULocationID', 'DOLocationID', 'total_amount']] \
.rename(columns={'PULocationID': 'pu_location_id', 'DOLocationID': 'do_location_id'})
# データ分割
X_train, X_test, y_train, y_test = train_test_split(
df.drop('total_amount', axis=1),
df['total_amount'].ravel(),
test_size=0.2
)
# XGBの扱うマトリクス形式に変換
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
"""
普通に学習(比較用)
"""
model = xgb.train(
params,
dtrain,
num_boost_round=num_boost_round,
evals=[(dtest, 'Test')],
early_stopping_rounds=early_stopping_rounds,
)
print('Best MAE: {:.2f} with {} rounds'.format(
model.best_score,
model.best_iteration+1
)) # ベストスコアと最適だったBoosting Round
"""
ハイパーパラメータチューニング
"""
# max_depth: 最大の木の深さ
# min_child_weight: 最小の重み
gridsearch_params = [
(max_depth, min_child_weight)
for max_depth in range(8,12)
for min_child_weight in range(5,9)
]
min_mae = float('Inf')
for max_depth, min_child_weight in gridsearch_params:
# 定義した値の範囲でグリッドサーチ
print('CV with max_depth={}, min_child_weight={}'.format(
max_depth,
min_child_weight
))
params['max_depth'] = max_depth
params['min_child_weight'] = min_child_weight
# 交差検証
cv_results = xgb.cv(
params,
dtrain,
num_boost_round=num_boost_round,
seed=42,
nfold=5,
metrics={'mae'},
early_stopping_rounds=10
)
mean_mae = cv_results['test-mae-mean'].min()
boost_rounds = cv_results['test-mae-mean'].argmin()
print('\tMAE {} for {} rounds'.format(mean_mae, boost_rounds))
# ベストスコアの保持
if mean_mae < min_mae:
min_mae = mean_mae
best_params.update(max_depth=max_depth, min_child_weight=min_child_weight)
# subsample: 行方向のデータの利用割合
# colsample: 列方向のデータの利用割合
gridsearch_params = [
(subsample, colsample)
for subsample in [i/10. for i in range(7,11)]
for colsample in [i/10. for i in range(7,11)]
]
min_mae = float('Inf')
for subsample, colsample in reversed(gridsearch_params):
# 降順でグリッドサーチ
print('CV with subsample={}, colsample={}'.format(
subsample,
colsample
))
params['subsample'] = subsample
params['colsample_bytree'] = colsample
# 交差検証
cv_results = xgb.cv(
params,
dtrain,
num_boost_round=num_boost_round,
seed=42,
nfold=nfold,
metrics={'mae'},
early_stopping_rounds=early_stopping_rounds,
)
mean_early_stopping_rounds = cv_results['test-mae-mean'].min()
boost_rounds = cv_results['test-mae-mean'].argmin()
print('\tMAE {} for {} rounds'.format(mean_mae, boost_rounds))
if mean_mae < min_mae:
min_mae = mean_mae
best_params.update(subsample=subsample, colsample_bytree=colsample)
# ETA: 学習率
min_mae = float('Inf')
for eta in [.3, .2, .1, .05, .01, .005]:
print('CV with eta={}'.format(eta))
params['eta'] = eta
%time cv_results = xgb.cv(params, dtrain, num_boost_round=num_boost_round, seed=42, nfold=nfold, metrics=['mae'], early_stopping_rounds=early_stopping_rounds)
mean_mae = cv_results['test-mae-mean'].min()
boost_rounds = cv_results['test-mae-mean'].argmin()
print('\tMAE {} for {} rounds\n'.format(mean_mae, boost_rounds))
if mean_mae < min_mae:
min_mae = mean_mae
best_params.update(eta=eta)
print(params)
params.update(
max_depth=best_params['max_depth'],
min_child_weight =best_params['min_child_weight'],
subsample=best_params['subsample'],
colsample_bytree=best_params['colsample_bytree'],
eta=best_params['eta'],
)
print(params)
"""
チューンしたパラメータで再学習
"""
model_t = xgb.train(
params,
dtrain,
num_boost_round=num_boost_round,
evals=[(dtest, "Test")],
early_stopping_rounds=early_stopping_rounds,
)
print('Best MAE: {:.2f} with {} rounds'.format(
model_t.best_score,
model_t.best_iteration+1
))
num_boost_round = model_t.best_iteration + 1
best_model = xgb.train(
params,
dtrain,
num_boost_round=num_boost_round,
evals=[(dtest, "Test")],
)
"""
保存
"""
best_model.save_model('xgb.model')
データサイエンティストの後輩にこれでいいの?と見せたら
- 最初の比較に対して、テストデータを学習時に利用するズルをしているので正確な比較にならない(実際スコアは比較用に作った奴の方がよかった)
- ハイパラチューンするなら全部の組み合わせ探索すべきでは?
とツッコミいただきました、ごもっともですモデル欲しいだけだから許してデデデに勝てねえよ。
保存できたら、Jupyter上でファイルを右クリック>Downloadで、xgb.modelをJupyterから取り出しておきます。
また、pip freeze| grep xgbで、xgboostのバージョンを確認しておきましょう(今回は1.2.1でした)
3.5.2. Sparkイメージのアップデート
XGBoostを走行するために、OpenMPをいれる必要があるため、先ほど作成したSparkイメージを元にライブラリを追加します。
ARG SPARK_IMAGE
FROM ${SPARK_IMAGE}
RUN apt-get update && apt-get install -y \
libgomp1
cd spark-images # 最初のSparkのDockerfileの横にでも、上記Dockerfileを置いてください
SPARK_IMAGE="spark:v3.0.1-java11" # 多分シェル変数消えてそうなんで再掲
docker build \
-f ./SparkXgb.Dockerfile \
-t spark:v3.0.1-java11-xgb \
--build-arg SPARK_IMAGE=${SPARK_IMAGE}
.
cd .. # 一応作業ルートに戻ておく
3.5.3. jarとモデルのアップロード
SparkでXGBoostを走行させるためのライブラリを入手します。Python側のXGBとバージョンを揃えると多分ベター(互換性ある程度はあるみたいですが)
wget https://repo1.maven.org/maven2/ml/dmlc/xgboost4j_2.12/1.2.1/xgboost4j_2.12-1.2.1.jar
wget https://repo1.maven.org/maven2/ml/dmlc/xgboost4j-spark_2.12/1.2.1/xgboost4j-spark_2.12-1.2.1.jar
Sparkを実行する際、jarやその他ファイルをExecutorにDriverから転送することができるので、その機能を利用しライブラリと、モデルを配布します。
(本当はOpenMPも配布できればよかったんですがさすがに大変そうだった)
Jupyterのノートブックを作成予定のディレクトリへ、ブラウザ経由でドラッグアンドドロップで、jarファイル2つとxgb.modelをアップロードしてください。
(こういうゆるふわなことできるのがNotebookのいいトコロ)
俺はCLIがいいんじゃ!という人は、kubectl cpコマンドを調べてやってみてください。
3.5.4. Sparkでの分散推論
さてやっと本題、spylon-kernelのNotebookを作成してください。
(spylon-kernel: Jupyter上でScalaを動かせるやつ。メンテされてなさそうなのになんでかSpark最新版を動かせる。Jupyterの配布するDocker内には同様に動かせるApache Toreeというプラグインもあったんですが、今現在は除外されている模様)
初期設定をしてSparkクラスタを起動します。
(この初期設定はPythonが呼ばれてる模様、Scalaじゃない点に注意)
%%init_spark
launcher.master = 'k8s://https://kubernetes.docker.internal:6443'
launcher.deploy_mode = 'client'
launcher.conf.set('spark.app.name', 'spark-from-jupyter')
launcher.conf.set('spark.driver.extraJavaOptions', '-Dio.netty.tryReflectionSetAccessible=true')
launcher.conf.set('spark.driver.host', 'spark-driver-headless.default.svc.cluster.local')
launcher.conf.set('spark.driver.port', 51810)
launcher.conf.set('spark.executor.extraClassPath', '/opt/spark/work-dir/xgboost4j_2.12-1.2.1.jar:/opt/spark/work-dir/xgboost4j-spark_2.12-1.2.1.jar')
launcher.conf.set('spark.executor.extraJavaOptions', '-Dio.netty.tryReflectionSetAccessible=true')
launcher.conf.set('spark.executor.instances', 2)
launcher.conf.set('spark.hadoop.fs.s3a.aws.credentials.provider', 'org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider')
launcher.conf.set('spark.kubernetes.container.image', 'spark:v3.0.1-java11-xgb')
launcher.jars = ['/home/jovyan/xgboost4j_2.12-1.2.1.jar', 'xgboost4j-spark_2.12-1.2.1.jar']
launcher.files = ['file:///home/jovyan/xgb.model']
必要なライブラリをimportしておきます。
import ml.dmlc.xgboost4j.scala.Booster
import ml.dmlc.xgboost4j.scala.XGBoost
import ml.dmlc.xgboost4j.scala.spark.XGBoostRegressionModel
import org.apache.hadoop.fs.FileSystem
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.types.{StructType, StructField, IntegerType, DoubleType, StringType, TimestampType}
XGBoostを呼び出すための黒魔術を唱えます。
(NotebookのようにREPLで処理をするためで、アプリケーションとして動かす場合はまともな方法でコールしますので安心してください)
import scala.reflect.runtime.{universe => ru}
val m = ru.runtimeMirror(getClass.getClassLoader)
val classXGBoostRegressionModel = ru.typeOf[XGBoostRegressionModel].typeSymbol.asClass
val cm = m.reflectClass(classXGBoostRegressionModel)
val ctor = ru.typeOf[XGBoostRegressionModel].decl(ru.termNames.CONSTRUCTOR).asTerm.alternatives(0).asMethod
val ctorm = cm.reflectConstructor(ctor)
val regressionModelRef = ctorm("model", XGBoost.loadModel("xgb.model")).asInstanceOf[XGBoostRegressionModel]
入力にするカラム名と、出力にするカラム名を設定しておきます。
val regressionModel = regressionModelRef
.setFeaturesCol("features")
.setPredictionCol("prediction")
先ほどのPySparkのときと同様に、DataFramesを作成します。
val schema = StructType(List(
StructField("vendor_id", IntegerType, true),
StructField("tpep_pickup_datetime", TimestampType, true),
StructField("tpep_dropoff_datetime", TimestampType, true),
StructField("passenger_count", IntegerType, true),
StructField("trip_distance", DoubleType, true),
StructField("rate_code_id", IntegerType, true),
StructField("store_and_fwd_flag", StringType, true),
StructField("pu_location_id", IntegerType, true),
StructField("do_location_id", IntegerType, true),
StructField("payment_type", IntegerType, true),
StructField("fare_amount", DoubleType, true),
StructField("extra", DoubleType, true),
StructField("mta_tax", DoubleType, true),
StructField("tip_amount", DoubleType, true),
StructField("tolls_amount", DoubleType, true),
StructField("improvement_surcharge", DoubleType, true),
StructField("total_amount", DoubleType, true),
StructField("congestion_surcharge", DoubleType, true),
))
val df = spark.read.format("csv").schema(schema)
.option("delemiter", ",")
.option("header", "true")
.option("timestampFormat", "yyyy-MM-dd HH:mm:ss")
.load("s3a://nyc-tlc/trip data/yellow_tripdata_2020-06.csv")
XGBoostへの入力に利用するデータを、連結したカラムを作成します。
(気になる方は.showを挟んでみてください。メモリが潤沢なら.cacheもしておくと楽。)
val vectorAssembler = new VectorAssembler()
.setInputCols(Array("trip_distance", "pu_location_id", "do_location_id"))
.setOutputCol("features")
val df_w_features = vectorAssembler.transform(df)
このまま推論もできるのですが、見やすくするためにカラムを絞ります。
val xgbInput = df_w_features.select("features", "total_amount")
最後に、推論を実行します。
val result = regressionModel.transform(xgbInput)
result.show
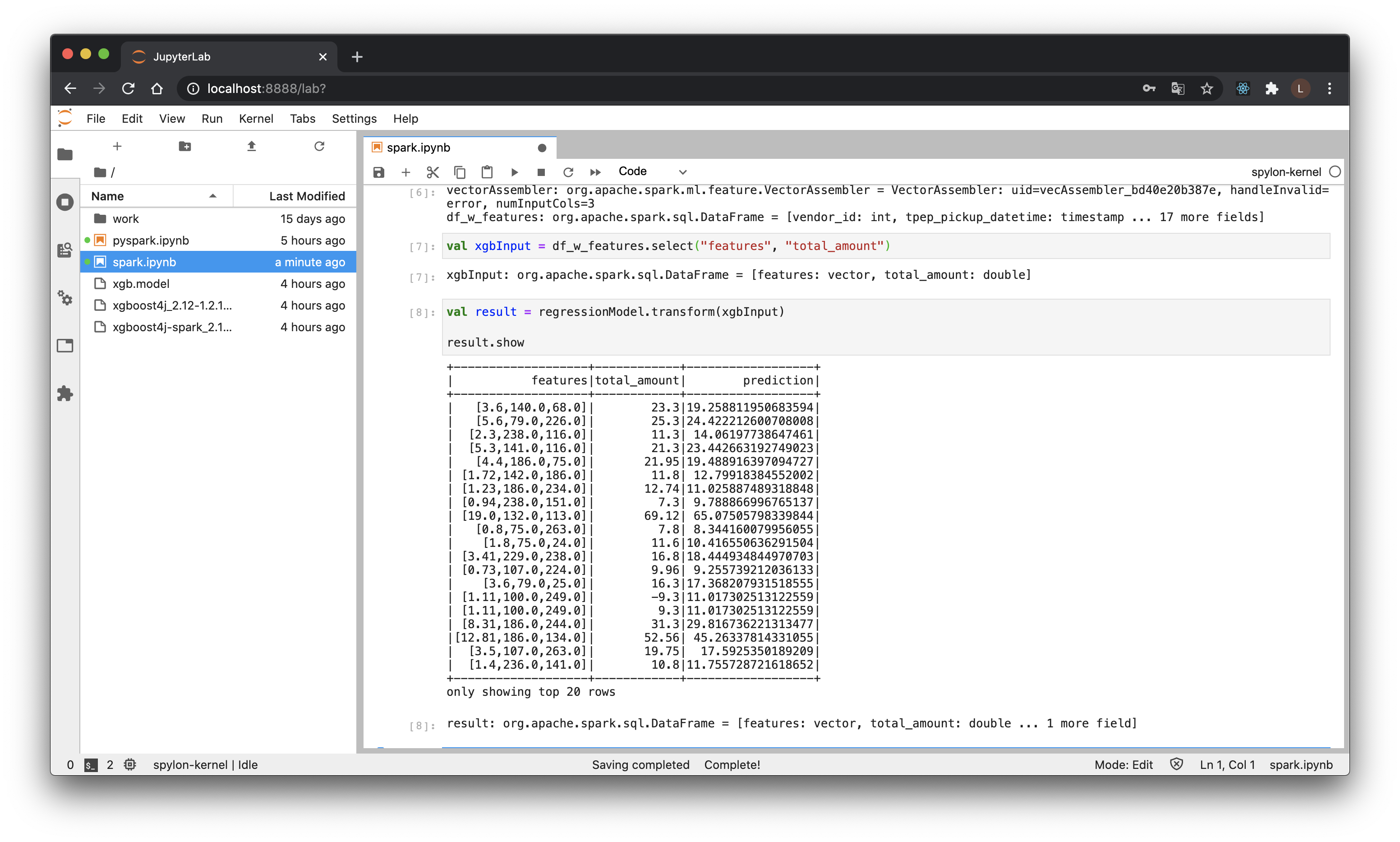
うまくいってそうですね。うちの周りだとみんなCDF描くので試してみます。雑に残差で累積度数を求めてみます。
import org.apache.spark.sql.functions.{abs, asc, row_number}
import org.apache.spark.sql.expressions.Window
val result_w_ar = result
.withColumn("abs_residual", abs(result("prediction")-result("total_amount")))
val windowSpec = Window.orderBy(asc("abs_residual"))
val result_cdf = result_w_ar
.withColumn("cdf", row_number.over(windowSpec)/result_w_ar.count)
result_cdf.select("abs_residual", "cdf").createOrReplaceTempView("cdf")
トリッキーではありますが、SparkでTempViewを作成し、Pythonのセルを作りPySparkに渡せばPandas DFにすることも、一応このノートブック内で可能です。
%%python
df = spark.sql("SELECT * FROM cdf").toPandas()
from bokeh.plotting import figure, output_file, show
output_file("cdf.html")
p = figure(
title='abs_residal cd',
x_axis_label='abs residal of total_amount prediction [$]',
y_axis_label='[%]',
)
p.line(df['abs_residual'], df['cdf']*100)
show(p)
bokehだと一度HTMLファイルにするしかなさそうです。残念。
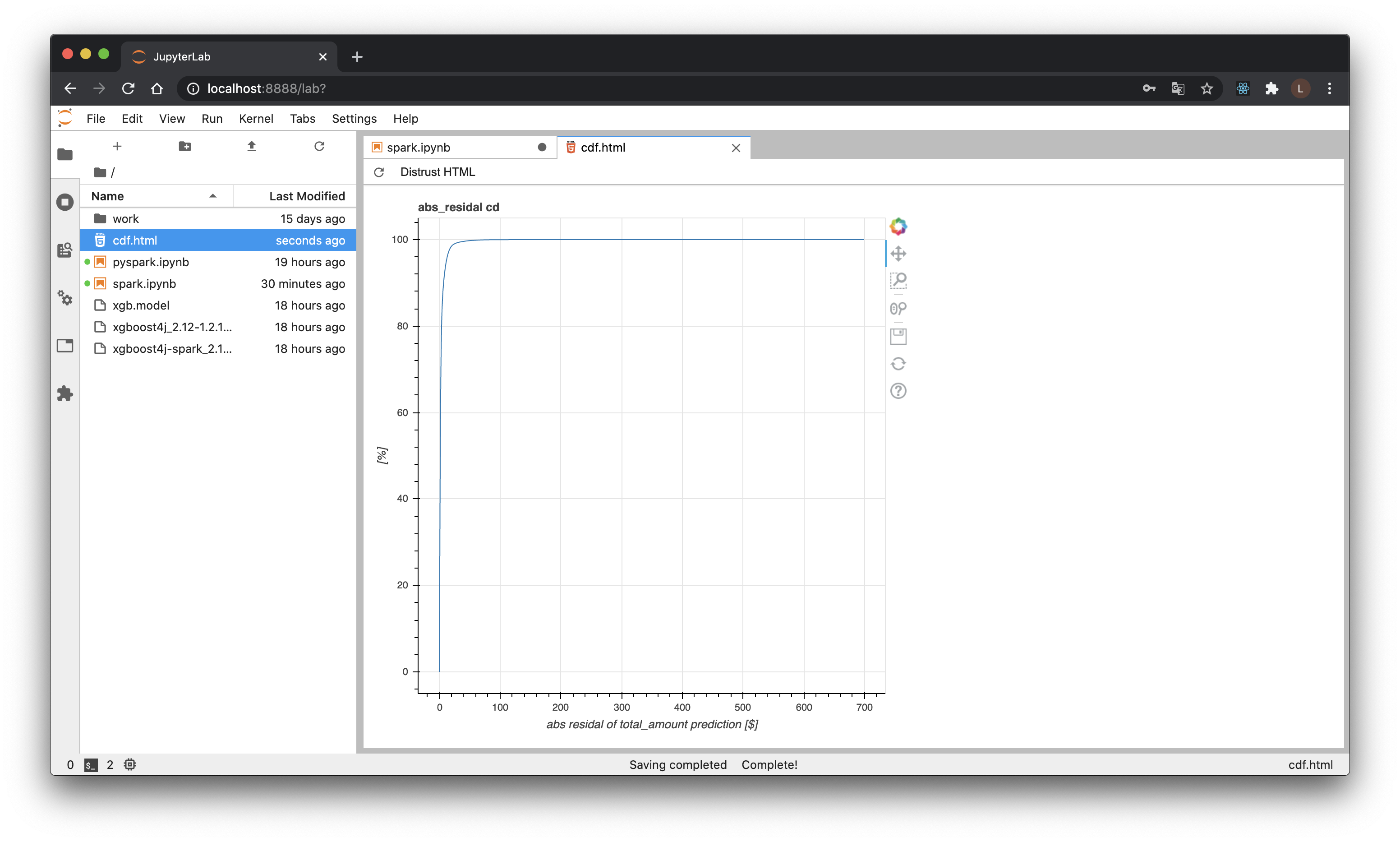
恐ろしく外しているやついそうですね(前処理やれって感じです)。
3.5.5. 簡単に解説: Spark
さて、ここまでとりあえず突き進んできましたが、簡単にSparkの説明を。
端的に言ってしまえば、複数台のマシンに跨った処理でも、さほど意識せずに、DataFramesを通じて処理の記述が可能、というのが一つの大きな特徴になります(今回はK8sで仮想的に複数台を実行してるような感じです・・・実際は下まわりを意識するのが必要な時も結構あって、それがまた大変なこともあるのですが)。
http://localhost:4040へとアクセスするとSpark WebUIが閲覧でき、処理の詳細についてある程度把握が可能です。(どの処理がどの画面に対応し、というのが慣れるまでわかりづらいのはちとネックですが、色々クリックしてみてください)
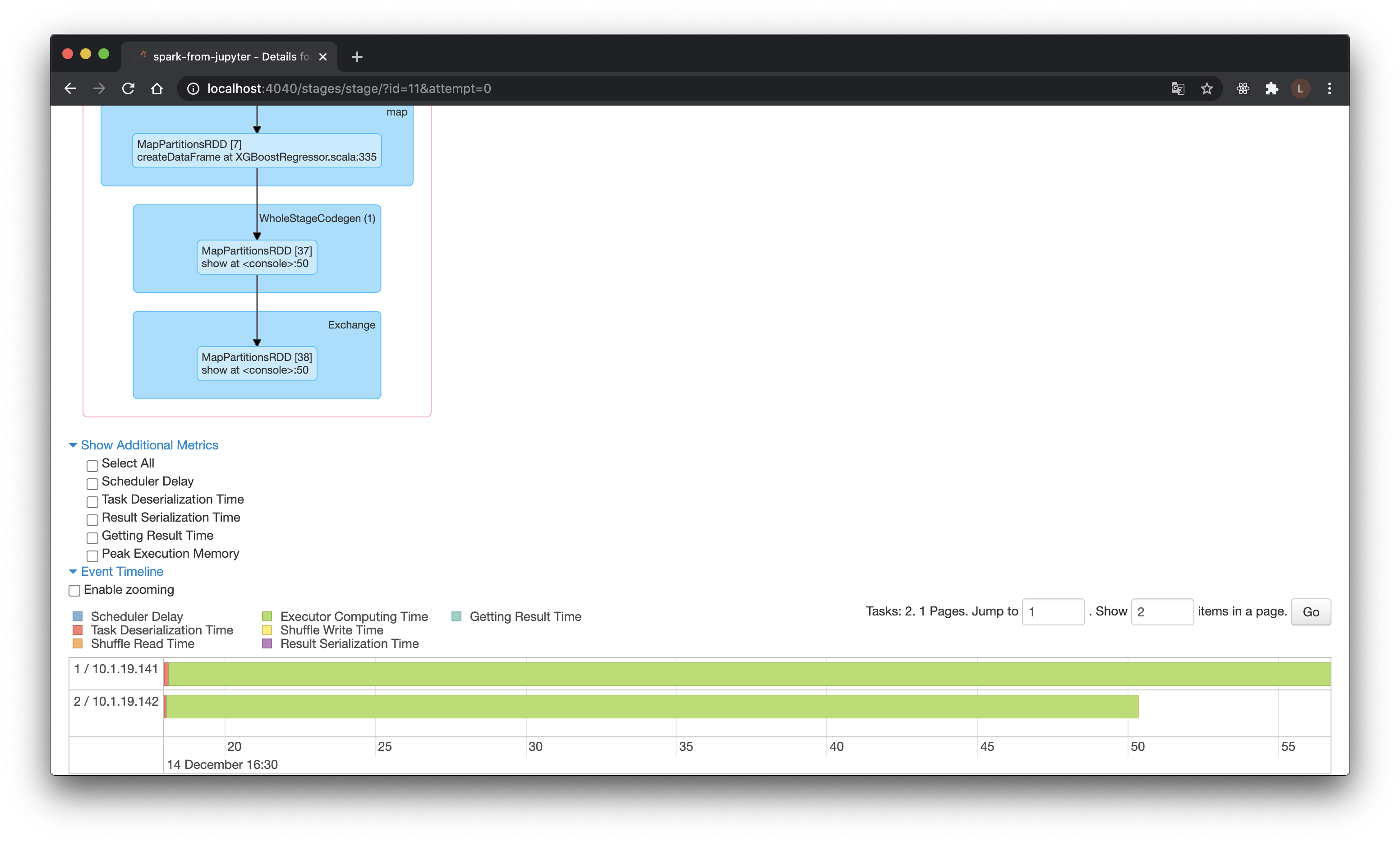
↑XGBで推論した際のStageのキャプチャになるのですが、2つに分割されて処理がなされているのがみて取れるかと思います。例えばデータが巨大になった場合でも、マシンを複数用意してやれば、データを分割して、高速に処理することも可能…というわけです。
細かな詳細はまた次回、実際に複数のマシン上で動かした時にでも。さしあたりは難しい処理でも割と簡単に記述できる、ということだけ分かれば十分かなと。
3.6. 最後に
駆け足でしたが、エッセンスは詰め込めたんじゃないのかなーと思います。あとは適宜ググって調べつつ、気長に次回をお待ちください。
-
担当内、私含めて4人が、未経験からVIP(オンライン対戦Top 5%以内)入りしました。世界戦闘力の身に付く非上場優良企業なので学生さんはぜひ見にきてください。 ↩
-
魔界だと思ってたら五条先生ことAWSが領域展開(EMR on EKS)で颯爽と上書いていきました。はよ東京に来て。 ↩
-
いわゆる異動。前はReact/ReduxでWebアプリ組んでたんですがどうしてこうなった。 ↩
-
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.20.md#deprecation
まずはDocker Desktop for Macを、https://docs.docker.com/docker-for-mac/install/ を参考に、DockerHubからダウンロードしインストール、起動しましょう。 ↩ -
おそらくmac内に複数Javaが存在することになるので「mac java バージョン 切り替え」などでググること。 ↩
-
?となった方はコンテナ未経験新人が学ぶコンテナ技術入門 を片手にそこらにいる先輩を捕まえること ↩
-
現時点での最新版(tag:
5cfa60996e84)がちょうど、Spark 3.0.1とJava11を使っているようでした。今後この記事見て試してみたい人は、Javaのバージョンだけは揃えた方が良いかもです。(他にもいろいろカスタムが必要になる場合は、Jupyterのドキュメントのように、GitHubにあるDockerfileからビルドすれば行けるようです。) ↩