NTTドコモサービスイノベーション部AdventCalendar2019の8日目の記事です。
今回は、構造化された知識ベースのひとつであるWikidataのデータを、グラフDBのひとつであるNeo4jを使って可視化してみます。
グラフDBとは
簡単にいえば、グラフ構造を扱えるデータベースのことです。一般によく普及しているRDBと比べて、データ間の関係を扱うためにデザインされたデータベースと言えます1。ちなみに、グラフとは折れ線グラフや棒グラフのことではなく、ノード(接点)とエッジ(枝)の集合で表される、下図のようなデータ構造を指します(Wikipediaより引用)。
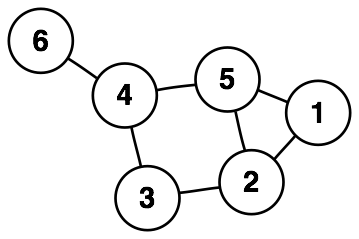
この図だけ見ると何の役に立つのかイマイチ分かりませんが、グラフ構造は現実世界の様々なモノゴトを表現するのに大変便利です。例えば、駅をノード、線路をエッジとみれば路線図もグラフで表現できますし、都市をノード、道路をエッジとみれば輸送問題も表現できるでしょう。また、アカウントをノード、アカウント間の関係をエッジとみればSNSもグラフで表現できます。実応用的なところでいえば、購買履歴をグラフ構造で表現して商品の推薦にも利用できるようです2。
| 表現できるモノゴト | ノード | エッジ |
|---|---|---|
| 路線図 | 駅 | 線路 |
| 物流 | 都市 | 道路 |
| SNS | アカウント | アカウント間の関係 |
| 社内人事 | 社員 | 社員同士の関係 |
| Wikipedia | ページ | ページ間のリンク |
最近は言語処理界隈でもグラフ構造への注目が高まっているようで、例えば、自然言語処理のトップ国際会議であるACLでは、GCN (Graph Convolutional Netowrk) 関連論文の投稿件数が、昨年は3件だったのが今年は11件と大きく増加しています。
このグラフDBを使って、ある事実とある事実の間の関係を可視化してみます。
Wikidataからの情報抽出
可視化するためには可視化するデータが必要ですが、イチから人手でデータを作成するのは大変です。
そこで今回は、あらかじめ構造化されている知識ベースであるWikidata3のダンプを利用して、グラフDBにインポートするデータを作成します。「構造化」というのは、「計算機で扱いやすくなっている」くらいの意味です。
Wikidataは共同編集型の知識ベースで、Wikipediaと同じウィキメディア・プロジェクトのひとつです。
Wikidataでは、例えば「ジョン・レノンの国籍はイギリスである」という「知識」を(ジョン・レノン, 国籍, イギリス)のような3つ組で表現します。このような(エンティティ1, プロパティ, エンティティ2)の形式を関係トリプルと呼びます。ここでいうエンティティは、Wikipediaにあるページのタイトルだとおもってもらってかまいません。それぞれのエンティティには"Q"から始まるWikidata固有の識別子がふられています(例えば、Q5は「ヒト」を指します)。同様に、プロパティには"P"から始まるWikidata固有の識別子がふられています。
Wikidataの全データは毎週水曜日頃にJSON形式でダンプされているので、これをグラフDBにインポートするデータとして使いましょう。ここから、latest-all.json.bz2かlatest-all.json.gzのいずれかをダウンロードしてください。
中身のJSONの構造については、ここが詳しいです。
とりあえず、下に示すようなPythonスクリプトを実行すれば、ダンプからエンティティやプロパティの情報、ないし関係トリプルを抽出できます(それなりに時間とメモリを消費する気がするので注意してください)。
サンプルスクリプト
# !/usr/bin/env python
# coding: utf-8
import bz2
import json
import codecs
triples = []
qs = []
with bz2.BZ2File('latest-all.json.bz2', 'r') as rf, \
codecs.open('rdf.tsv', 'w', 'utf-8') as rdff, \
codecs.open('q_id.tsv', 'w', 'utf-8') as qf:
next(rf) # 1行目を飛ばす
for i, line in enumerate(rf, 1):
try:
line = json.loads(line[:-2])
except json.decoder.JSONDecodeError:
print(i)
rdff.write('\n'.join(['\t'.join(x) for x in triples]) + '\n')
qf.write('\n'.join(['\t'.join(x) for x in qs]) + '\n')
triples = []
qs = []
continue
try:
ett_id = line['id']
except KeyError:
ett_id = None
try:
ett_name = line['labels']['ja']['value']
except KeyError:
ett_name = None
if ett_id is not None and ett_name is not None:
qs.append((ett_id, ett_name))
triple = []
for _, props in line['claims'].items():
for prop in props:
p_id = prop['mainsnak']['property']
try:
id_ = prop['mainsnak']['datavalue']['value']['id']
except Exception as e:
# print(ett_id, p_id, e)
continue
triple.append((ett_id, p_id, id_))
triples.extend(triple)
triple = []
if i % 10000000 == 0:
print(i)
rdff.write('\n'.join(['\t'.join(x) for x in triples]) + '\n')
qf.write('\n'.join(['\t'.join(x) for x in qs]) + '\n')
rdff.write('\n'.join(['\t'.join(x) for x in triples]) + '\n')
qf.write('\n'.join(['\t'.join(x) for x in qs]) + '\n')
q_id.tsvは下表のようなタブ区切りのファイルです(このファイルにはQ IDだけではなくP IDも含まれます)。
| Q ID | エンティティ名 |
|---|---|
| Q31 | ベルギー |
| Q8 | 幸福 |
| Q23 | ジョージ・ワシントン |
| Q24 | ジャック・バウアー |
| Q42 | ダグラス・アダムズ |
また、rdf.tsvは下表のようなタブ区切りのデータです。
| エンティティ1 | プロパティ | エンティティ2 |
|---|---|---|
| Q31 | P1344 | Q1088364 |
| Q31 | P1151 | Q3247091 |
| Q31 | P1546 | Q1308013 |
| Q31 | P5125 | Q7112200 |
| Q31 | P38 | Q4916 |
上記2ファイルを組み合わせて、2種類のファイルを作ります。
まずは、q_id.tsvにヘッダを加えて、下表のようなタブ区切りのデータnodes.tsvを作成し保存しましょう(3列目の:LABELはあってもなくてもかまわないので、実はファイル名をrenameするだけでもよかったりします)。
| id:ID | name | :LABEL |
|---|---|---|
| Q31 | ベルギー | Entity |
| Q8 | 幸福 | Entity |
| Q23 | ジョージ・ワシントン | Entity |
| Q24 | ジャック・バウアー | Entity |
| Q42 | ダグラス・アダムズ | Entity |
併せて、エンティティ間のプロパティも、下表のようなタブ区切りのデータrelationships.tsvとして保存します。rdf.tsvにヘッダをつけて、2列目の:TYPEをq_id.tsvを参照して"P000"から文字列に置換するだけです(実はこちらもわざわざ置換する必要性はないので、ファイル名をrenameするだけでよかったりします)。
| :START_ID | :TYPE | :END_ID |
|---|---|---|
| Q23 | 配偶者 | Q191789 |
| Q23 | 父親 | Q768342 |
| Q23 | 母親 | Q458119 |
| Q23 | 兄弟姉妹 | Q850421 |
| Q23 | 兄弟姉妹 | Q7412891 |
プロパティには「国籍」や「配偶者」、「出生地」、「誕生日」など様々な種類があるのですが、このままでは数が多すぎるので、今回の可視化では、人と人の間に定義付けられるプロパティにしぼりました。例えば「親族」や「父親」「母親」「師匠」「弟子」などです。また、エンティティも日本語名のあるエンティティに限定しています。
Neo4jを使ってみる
グラフDBにはいろいろな種類があるのですが、ここでは比較的ポピュラーなNeo4j4を紹介します。
Neo4jの他には例えばAmazon Neptuneが有名だと思います(名前がかっこいい)5。
インストール
macOSの場合はHomebrewでインストールするのがオススメです。
$ brew cask install homebrew/cask-versions/adoptopenjdk8 # Javaが入っていない場合
$ brew install neo4j
Javaのバージョンが違うと
neo4j: Java 1.8 is required to install this formula.
Install AdoptOpenJDK 8 with Homebrew Cask:
brew cask install homebrew/cask-versions/adoptopenjdk8
Error: An unsatisfied requirement failed this build.
と怒られるので注意してください。
$ which neo4jと入力して/usr/local/bin/neo4jのように表示されればインストール完了です。
データのインポート
先ほど作成したnodes.tsvとrelationships.tsvをNeo4jにインポートします。データのインポートは下記のようなコマンドを叩きます。
$ neo4j-admin import --nodes ./Downloads/nodes.tsv --relationships ./Downloads/relationships.tsv --delimiter="\t"
インポートがうまくいけば、
IMPORT DONE in 9s 735ms.
Imported:
2269484 nodes
201763 relationships
6808452 properties
Peak memory usage: 1.05 GB
のように表示されます。
Neo4jサーバの起動や停止は下記コマンドで行います。
$ neo4j start # サーバを起動するとき
$ neo4j stop # サーバを停止するとき
サーバを起動させたらhttp://localhost:7474にアクセスしてみてください。初めてアクセスしたときはログインを求められると思いますので、ユーザー名とパスワードにそれぞれ"neo4j"と入力してください。その後、パスワードの変更を求められますので、任意のパスワードに変更してください。
Cypherでデータを処理する
これで準備は整いました。早速Neo4jを使ってみましょう。Neo4jではクエリとして、Cypherと呼ばれる、SQLライクな言語を使います(以下、CypherをCQLと記載します)。なお、本記事ではCQLの詳説はいたしませんのでご了承ください。
この記事が投稿される12月8日はジョン・レノンの命日ですので、ジョン・レノンを題材に取り上げましょう。余談ですが、僕は"Jealous Guy"がいちばん好きです。
n-hop探索
例えば、「ジョン・レノン」に紐づくエンティティを見たいときは、次のようなCQLを発行します。このCQLは、「ジョン・レノン」ノードから3-hopまで先にある全てのEntityノードを返却します。
match p=((:Entity{name:"ジョン・レノン"})-[*1..3]-()) return p
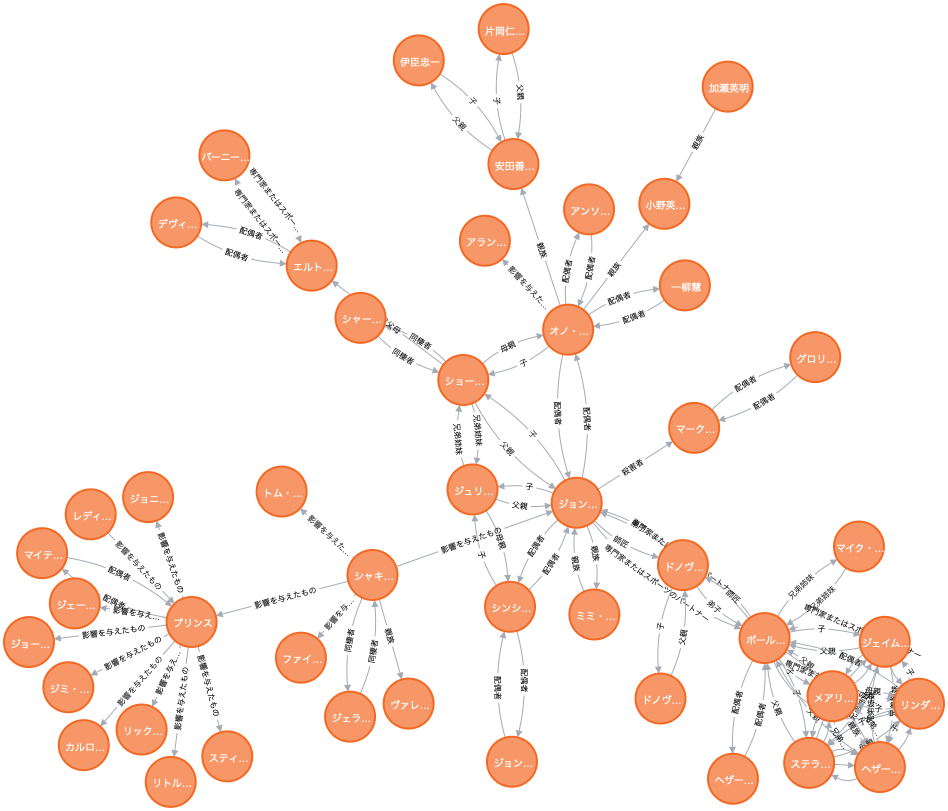
やや分かりづらいですが、中央から少し左下にある「ジョン...」が「ジョン・レノン」ノードです。例えば「ジョン・レノン」から上に向かって「オノ・ヨーコ」(1)→「安田善三郎」(2)→「片岡仁左衛門」(3)と3-hop先まで関係が伸びているのが分かります。右下のかたまりは、おなじみポール・マッカートニーとその家族です。
残念ながらこのグラフ中に、ザ・ビートルズのメンバーだったリンゴ・スターやジョージ・ハリソンの名前はありません。
最短経路探索
Neo4jでは最短経路を探索することができ、これが目玉機能のひとつだそうです。
試みに、明治時代を代表する文豪である「夏目漱石」と「森鴎外」の間の最短経路を探索してみましょう。12月8日はぜんぜん関係ありません。余談ですが、僕は『虞美人草』がいちばん好きです。
次のようなCQLを発行します。「『夏目漱石』と『森鴎外』の間にある全てのノードを返却する」というCQLをshortestpathでくくるだけです。
match p=shortestpath((:Entity{name:"夏目漱石"})-[*]-(:Entity{name:"森鴎外"})) return p
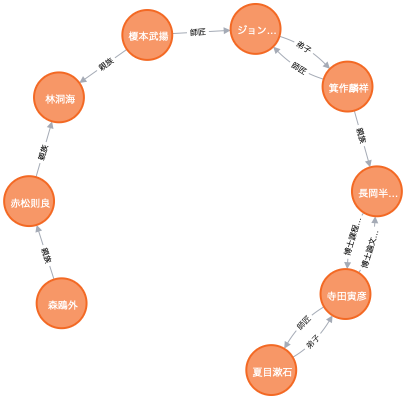
上の方に出ている「ジョン...」はジョン・レノンではなくて「ジョン万次郎」です。
同時代に生きたふたりですが、Wikidataの知識に基づけば、その関係は意外にも遠いことが分かります。史実によってみても、お互いに顔見知り程度で交流らしい交流はなかったそうです。
それでは、一見関係のなさそうな「ジョン・レノン」と「夏目漱石」の間にはどんな最短経路があるでしょうか。
match p=shortestpath((:Entity{name:"夏目漱石"})-[*]-(:Entity{name:"ジョン・レノン"})) return p
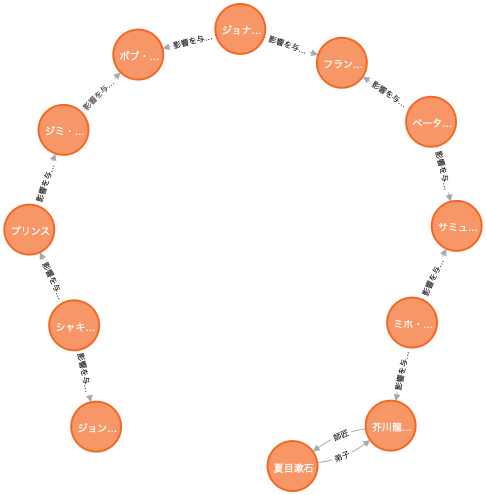
「夏目漱石」から「芥川龍之介」、「サミュエル・ベケット」(戯曲『ゴドーを待ちながら』の作者)などを経て、「ボブ・ディラン」("Like a Rolling Stone"で有名、ノーベル文学賞受賞者)で文学と音楽の橋が渡された後、「ジミ・ヘンドリックス」、「プリンス」、「シャキーラ」、そして「ジョン・レノン」へとたどり着くようです。正直、少々唐突で迂遠な感じが否めません6。
Wikidataはそれなりに大規模な構造化データですが、知識ベースとしてすぐに使うには多少不十分だと考えられます。例えば関係抽出を使って知識ベースを拡充する必要があるでしょう。関係抽出とは、例えば「『坊つちやん』の作者である夏目漱石は~」という文から(夏目漱石, 作者, 『坊つちやん』)という関係トリプルを抽出する技術です。
まとめ
Neo4jを使ってWikidataの知識を可視化してみました。
Neo4jで描画したグラフはブラウザ上でうねうね動かせて楽しいのでぜひご自身で実践して触ってみてください。
-
昨年の弊社アドベントカレンダーで林さんが記事を書いてくれています→ https://qiita.com/dcm_hayashi/items/9b2536b6fbffa0118fad ↩
-
「夏目漱石」の一高時代からの親友である「中村是公」は、満鉄総裁や東京市長を歴任した「後藤新平」の腹心のひとりとして知られています。その後藤が提唱した都市計画に賛同したのが「安田善次郎」でした(ちなみにこのとき建てられたのが日比谷公会堂です)。そして、安田のひ孫はご存知「オノ・ヨーコ」で彼女の配偶者は「ジョン・レノン」です、という具合に辿ったほうがWikidataの結果よりもだいぶ短縮できます。 ↩