はじめに
この記事は,ドコモアドベントカレンダー21日目の記事になります。
21日目のこの記事では,グラフデータベースに関する技術&Neptuneの体験について紹介します。
動機としては,業務でクラウドインフラに携わっているためAWSのサービスの知識を蓄えたいというのとニッチな技術に興味があったからです。
グラフデータベースとは?
分類
データベースの分類的には,NoSQLのグラフ型に分類され,代表格としてはオープンソースのグラフデータベースである「Neo4j」やObjectivity社のグラフデータベースである「InfiniteGraph」があります。

特徴
ざっくりグラフデータベースの特徴をまとめてみます。
- 点(ノード)と辺(エッジ,リレーションシップ)からなるグラフ構造でデータの関係性に着目している
- プロパティグラフ,トリプルグラフに対応している(グラフの表現の仕方が2種類あります)
- ノード間の関係性をやつながりをエッジ,リレーションシップで表現
- リレーションシップには方向性を持たせることができる
- ノードやリレーションシップにラベルやプロパティを設定することで情報を付加できる
- DBの操作にはグラフデータベース専用のクエリ言語ある
- ソーシャルグラフ分析,最短経路検索,ネットワークやクレジットカードの不正検知などの強みを発揮するユースケースがある

データにつながりがあるかどうかやデータベースでの作業などでRDBとの技術選択が必要になりそうだと感じました。
リレーションシップに対してクエリを実行するユースケースでは威力を発揮するらしく,データ量が多くなってもパフォーマンスを落とすことなく結果を返すことが可能なようです。
AmazonNeptuneで初体験
初体験する前にざっくりとしたNeptuneの特徴を調べてみました。(AWSの公式ページから抜粋)
特徴
- 高パフォーマンスなグラフデータベースエンジン
- プロパティグラフとW3C の Resource Description Frameworkをサポート
RDFとは
ウェブ上にある「リソース」を記述するための統一された枠組み
プロパティグラフとは
- 対応するクエリ言語は,Apache TinkerPop Gremlin と SPARQLをサポート
- フルマネージドサービス
- VPC内で動作し,データの暗号化も可能
- 利用できるリージョンはバージニア北部,オレゴン,オハイオ
やはりAWSのサービスとあってフルマネージドという部分は運用者としては嬉しいですね。また,データ暗号化など高セキュリティが必要とされる環境にも適用できるけど,東京リージョンがGAされていないのがちょっと残念という感じですね(笑)
これでいざ初体験と思ったが,料金体系を先に抑えておくことにします。(AWSの公式ページからの抜粋)
上司にNeptuneの使用を相談したら「使用料金を宣言せよ」とのお達しがでましたので、、
料金体系
オンデマンド
プライマリインスタンスとレプリカの両方に適用されるようです。
マルチAZ配置で冗長化構成を取っている場合,プライマリインスタンスの料金に加えてレプリカの料金も加わります。
以下は,今回建てようとしているオハイオでの料金になります。

1$=112.82円(2018/11/18現在)のため,r4.largeの1ヶ月の使用料は約3万でr4.8xlargeだと約45万ほどかかることが判明。また,データストレージおよびIOにも以下の表で課金されます。

ということで,上長からのNeptuneの使用条件が月10万までだったためクリアできそうであるため、いざ実践。
インスタンス立ち上げ
一番小さいクラスのインスタンスを指定。

次の画面で設定するVPCには,異なるアベイラベリティゾーンのsubnetを設置しておくことに注意してください。
Create Databaseをすると2つのインスタンスが生成されます。

Neptuneに接続!!
EC2をたてる
公式ドキュメント通りにNeptuneを作成したVPCにEC2を立てます。
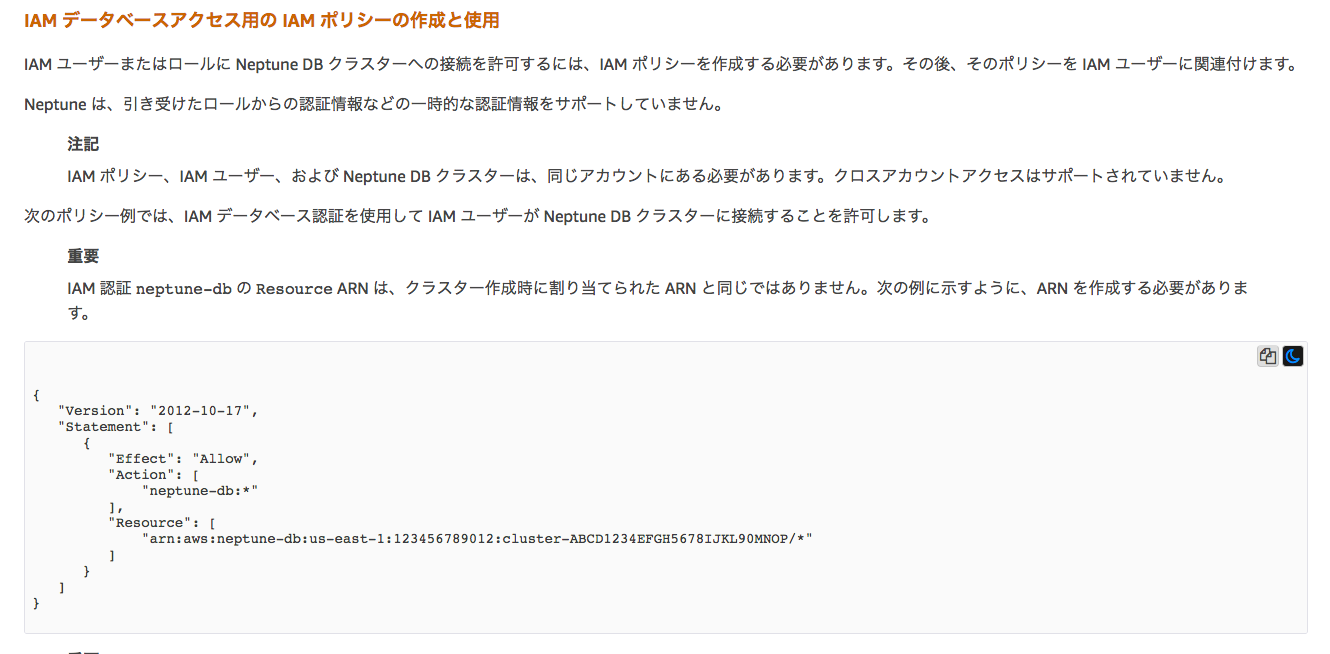
ここで注意なのが,IAM認証を適用している場合,以下に書いてある通りEC2からNeptuneに接続するにあたってロールを加える必要があります。
これを読み飛ばして大変だった。いつまでたってもレスポンスを返してくれませんでした。
Gremlinの導入
Gremlingとは
グラフデータベースを操作するためのクエリ言語になります。
CypherQuery,SPARQLというもクエリ言語として有名なようです。
TinkerPopというApacheプロジェクトで多種多様なグラフDBをラッピングするツールが開発されており、そのプロジェクトの中のツールの1つとして
GremlinというグラフDBの操作を統一的に行えるようにする仕組みが提供されています。
Gremlinは上の表にも書いた通り幅広いグラフDBで対応されているようなのでかなり幅広く活用できるものとなっているのではないでしょうか。
引用:グラフデータベースのNeo4jをCypherではなくGremlinで操作

以下を参照して,クエリ言語であるGremlinが使えるようにします。
Gremlin コンソールを使用して Neptune DB インスタンスに接続する
GremlinでNeptuneを操作
bin/gremlin.shでGremlinを起動します。
そして,Neptune用のconfigファイルであるneptune-remote.yamlでneptuneにリモート接続できます。

:remote consoleでコンソールのコマンドをリモート転送してくれます。
ノードの作成
以下の画像通りに作ってみることにします。
まず,personノードを作成。
gremlin> g.addV('person').property('name', 'Alice').property(id, '1')
==> v[1]
gremlin> g.addV('person').property('name', 'Bob').property(id, '2')
==> v[2]
gremlin> g.addV('person').property('name', 'Ken').property(id, '3')
==> v[3]
これで青丸のpersonノードが作れました。
ノードの作成の確認は以下のコマンドで。
gremlin>g.V().valueMap()
==>{name=[Alice]}
==>{name=[Bob]}
==>{name=[Ken]}
作成したノードに情報を追加してみます。この情報をプロパティと呼びます。
特定のノードを指定するためには,hasを使います。プロパティを追加するため指定したノードに .property() を使用します。
gremlin> g.addV().has('name', 'Alice').property('age', '15')
==>v[1]
もう一度,確認。
gremlin>g.V().has('name', 'Alice').valueMap()
==>{name=[Alice], age=[15]}
gremlin>g.V('1').valueMap()
==>{name=[Alice], age=[15]}
次に,緑丸のblogノードの作成。
gremlin> g.addV('blog').property('genre', 'CameraBlog').property(id, '4')
==> v[4]
gremlin> g.addV('blog').property('genre', 'TravelBlog').property(id, '5')
==> v[5]
gremlin> g.addV('blog').property('genre', 'GourmetBlog').property(id, '6')
==> v[6]
ノードのラベルごとの確認もできます。
gremlin>g.V().groupCount().by(label)
==>{person=3, blog=3}
エッジの作成
続いて,リレーションを表すエッジをつくっていきます。
色々なサイトを見るとノードを変数に代入できるような記載が見られるのだけど,今回は.as()を用いながらエッジを追加できるaddE()を使っていきます。
まずは,友人関係を追加していきます。
AliceとBobの関係から。.as()を使うことで特定のノードのエイリアスを作ることできます。
また,エッジには方向性があるため,to()でどのノードがどのノードにどんな関係性を持っているかを指定します。
gremlin>g.V('2').as('Bob').V('1').addE('Knows').property(id, '11').to('Bob')
==>v[2]
addE().property()でエッジのプロパティを作成することできます。続いて,AliceとKen。
gremlin>g.V('1').as('Alice').V('2').addE('Knows').property(id, '12').to('Alice')
==>v[1]
gremlin>g.V('3').as('Ken').V('1').addE('Knows').property(id, '13').to('Ken')
==>v[3]
エッジに関しても同様に確認できます。エッジ類の確認は,g.E()を使います。
gremlin>g.E().count()
==>3
gremlin>g.E().groupCount().by(label)
==>{Knows=3}
gremlin>g.E().valueMap()
==>{}
==>{}
==>{}
g.E().valueMap()で何も出力されていないのはid以外のプロパティが設定されていないからです。
図にプロパティはないけど,試しに5段階の親密度を表すClosenessを追加してみます。
gremlin>g.E("11").property("Closeness", 4)
==>e[11][1->Closeness->2]
gremlin>g.E("12").property("Closeness", 5)
==>e[12][2->Closeness->1]
gremlin>g.E("13").property("Closeness", 1)
==>e[13][1->Closeness->3]
もう一度出力してみると,,
gremlin>g.E().valueMap()
==>{Closeness=4}
==>{Closeness=5}
==>{Closeness=1}
gremlin>g.E("11").valueMap()
==>{Closeness=4}
このようにノードとエッジを追加していくことで,グラフを作成します。
図のSubscribeに関しても同様なため,割愛します。
探索
上記でやった出力のコマンドを使いつつ単一ノードの情報だけでなく,エッジを辿った先の情報を出力してみます。
まずは,Aliceの知人を探索。
特定のノードの後に.outE()でエッジのidと方向が出力され,.out()でエッジの先のノードidが出力されます。
gremlin>g.V("1").outE("Knows")
==>e[11][1->Closeness->2]
==>e[11][1->Closeness->3]
gremlin>g.V("1").out("Knows")
==>v[2]
==>v[3]
gremlin>g.V("1").out("Knows").count()
==>2
.outE()は出力を見て通り,エッジに関しての情報出力しています。そのため,.valueMap()によって,エッジのプロパティを出力できます。同様に.out()ではエッジの先のノードに関しての情報が出力されているため,valueMap()によって,エッジの先のノードのプロパティを出力できます。
次にAliceの知人が所有しているブログの探索。
gremlin>g.V("1").out("Knows").out("Own")
==>v[4]
==>v[5]
gremlin>g.V("1").out("Knows").out("Own").values("genre")
==>CameraBlog
==>TravelBlog
以上で,最低限の操作のまとめとします。
おわりに
AmazonNeptuneを触ることでグラフデータベースを体験できました。
グラフ言語であるGremlinに関する資料が上手く見つからず手探りだっため大変だったのですが,一度書式を理解できればかなり直感的な操作ができると感じました。
また,プログラミング言語から操作ができるライブラリも開発されているため,言語から操作できるとなお使いやすいかもしれません。
あと気になる点としては,リレーショナルなデータベースと速度がどれくらい違うかという点ですね。
今後時間があるときに2つのレスポンス速度について調べてみようと思います。
re:Invent2018でNeptuneに関するセッション(https://www.youtube.com/watch?v=VGxYE4-pors) があったのですが、聴講者によると「どんなユースケースがあるのか」という質問に対して、あまりクリティカルな返答がなかったのだとか、、
やはり運用してるサービスの扱うデータによってRDBなのかGDBなのかを検証して、必要とする情報をより安定して早く引き出せる選択するというのがベターなのかなと思いました。
以上になります。
引用
AWS公式:グラフデータとは?
グラフデータベースとは何か
グラフデータベース入門
グラフデータベースのNeo4jをCypherではなくGremlinで操作