グラフDBには様々な種類があり、各グラフDB毎にクエリ言語の種類が異なります。
例えば、
| グラフDB | クエリ言語 |
|---|---|
| Neo4j | Cypher Query, Gremlin |
| OrientDB | SQL, Gremlin |
| Dgraph | GraphQLライク |
| Amazon Neptune | SPARQL, Gremlin |
| Azure Cosmos DB | Gremlin |
各クエリ言語で書き方がかなり異なるので、Neo4jを使っていたけど、Amazon Neptuneに移行したいといった時にアプリケーションのコード内のクエリの記述部分を書き換えないといけないため不便です。
そんな課題に対して、TinkerPopというApacheプロジェクトで多種多様なグラフDBをラッピングするツールが開発されており、そのプロジェクトの中のツールの1つとして
GremlinというグラフDBの操作を統一的に行えるようにする仕組みが提供されています。
Gremlinは上の表にも書いた通り幅広いグラフDBで対応されているようなのでかなり幅広く活用できるものとなっているのではないでしょうか。
今回はこのGremlinを用いてNeo4jの操作を行う方法について紹介します。
Neo4jの導入とCypherクエリの実行
まずTinkerPop、Gremlinの話に入る前に素のNeo4j、Cypherクエリについてです。
Neo4j導入
今回はMacOS上にインストールします。
Neo4jを動かすにはJavaが必要なのでJDKを導入しておきます。
homebrewで簡単にインストール可能です。
$ brew install neo4j
$ export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_65.jdk/Contents/Home"
$ neo4j start
http://localhost:7474にアクセスすると、最初にパスワードの設定が求められるのでneo4jユーザに対してパスワード設定して完了です。
Cypherクエリで操作
Cypherクエリのフォーマットの詳細はこの辺りを参考にしてください。
例えばTaroさんはJiroさんのことを知っている(Know)という関係を作る場合には以下のように実行します。
CREATE (:Person {name: "Taro"})-[:Know]->(:Person {name: "Jiro"})
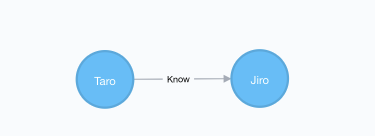
この記述方式を見てわかるように、かなり独特な記法となり、他のSQL、SparQL、GrapQL等と全然異なります。
TinkerPop Gremlin Serverの導入
では、ここからがTinkerPop Gremlinの登場です。
Gremlinで操作するには、Neo4jへの操作をGremlin Serverで仲介してあげる必要があります。
なので、まずはGremlin Serverを導入します。
今回は、Neo4jのグラフDBのファイルを直接Gremlin Serverが読み込んで操作できるようにするため、Neo4jを導入した環境(MacOS)上にインストールします。
$ curl -L -O http://ftp.jaist.ac.jp/pub/apache/tinkerpop/3.3.2/apache-tinkerpop-gremlin-server-3.3.2-bin.zip
$ unzip apache-tinkerpop-gremlin-server-3.3.2-bin.zip
$ cd apache-tinkerpop-gremlin-server-3.3.2
$ bin/gremlin-server.sh conf/gremlin-server-rest-modern.yaml
最後の1コマンドがGremlin Serverの起動コマンドになります。
ダウンロードしてきたファイルを展開すると標準でconf以下に様々なタイプでGremlin Serverを起動させるためのyaml設定ファイルが配置されています。
上記は、REST APIでグラフDBを操作するための設定サンプル(gremlin-server-rest-modern.yaml)を用いて起動している例です。
これで8182ポートでRESTでGremlinのクエリ実行が可能になります。
ただし、この状態だと、Neo4jとは特に関係なく、Gremlin Serverのデフォルトの場所にデータベースファイルを作成して操作ができるようになります。
REST API経由で操作できるようになっているので以下のような感じで登録されているノードを取得できます。g.V().toList()の部分がGremlinのクエリです。
curl -X POST -d "{\"gremlin\":\"g.V().toList()\", \"language\":\"gremlin-groovy\", \"bindings\":{\"x\":1}}" "http://localhost:8182"
pythonから操作できるようにGremlin serverを設定
この状態だとpythonからのソケット通信には対応できていないようなので一旦gremlin serverを停止後、以下を実行します。
$ bin/gremlin-server.sh install org.apache.tinkerpop gremlin-python 3.3.2
これでgremlin serverにPythonの処理に依存するライブラリ関連が組み込まれ、Pythonからの操作ができるようになります。
なお、上記コマンドを実行した際に、以下のようなダウンロードに失敗してインストールできないようなメッセージが出た場合
java.lang.RuntimeException: Error grabbing Grapes -- [download failed:・・・・
この辺りの記事を確認してください。
~/.groovy/の直下にgrapeConfig.xmlのファイルを以下の内容で配置すればインストールできました。
<ivysettings>
<settings defaultResolver="downloadGrapes"/>
<resolvers>
<chain name="downloadGrapes" returnFirst="true">
<filesystem name="cachedGrapes">
<ivy pattern="${user.home}/.groovy/grapes/[organisation]/[module]/ivy-[revision].xml"/>
<artifact pattern="${user.home}/.groovy/grapes/[organisation]/[module]/[type]s/[artifact]-[revision](-[classifier]).[ext]"/>
</filesystem>
<ibiblio name="localm2" root="file:${user.home}/.m2/repository/" checkmodified="true" changingPattern=".*" changingMatcher="regexp" m2compatible="true"/>
<!-- todo add 'endorsed groovy extensions' resolver here -->
<ibiblio name="jcenter" root="https://jcenter.bintray.com/" m2compatible="true"/>
<ibiblio name="ibiblio" m2compatible="true"/>
</chain>
</resolvers>
</ivysettings>
では、ここまで事前準備ができれば設定ファイルをconf/gremlin-server-modern-py.yamlに変更してgremlin serverを再起動してみます。
$ bin/gremlin-server.sh conf/gremlin-server-modern-py.yaml
Pythonからgremlin serverにつないで操作
Pythonから操作する場合、gremlinpythonというライブラリを使って操作します。
$ pip install gremlinpython
先程起動させたGremlin serverに接続して実行してみます。
コードは以下です。
from gremlin_python import statics
from gremlin_python.structure.graph import Graph
from gremlin_python.process.graph_traversal import __
from gremlin_python.process.strategies import *
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
graph = Graph()
g = graph.traversal().withRemote(DriverRemoteConnection('ws://localhost:8182/gremlin','g'))
g.addV('gremlin1').property('name', 'gremlin1').toSet()
print(g.V().valueMap().toList())
localhostの8182ポートにwebsocket接続し、gremlin1というノードを1つ追加して、登録されたリストをtoListで取得して表示する例です。
$ python gremlin-sample.py
[{'name': ['marko'], 'age': [29]}, {'name': ['vadas'], 'age': [27]}, {'name': ['lop'], 'lang': ['java']}, {'name': ['josh'], 'age': [32]}, {'name': ['ripple'], 'lang': ['java']}, {'name': ['peter'], 'age': [35]}, {'name': ['gremlin1']}]
もともとデフォルトで登録されているデータに加えてgremlin1という名前のノードが追加されているのがわかります。
Neo4jにアクセスできるようにする
では、ここからが本題です。
Neo4jのドライバーを登録してGremlin serverを立ち上げ直し、PythonからGremlin経由でNeo4jのDBにアクセスできるようにしてみます。
以下はGremlin serverが直接Neo4jのデータファイルを読み込んで起動する方法(embedded mode)で試しましたが、他にもNeo4jに対してboltプロトコル経由で繋いでアクセスする方法(HA mode)とかあるようです。
先程のPythonのときと同じくGremlin serverにneo4j用のライブラリを組み込みます。
$ bin/gremlin-server.sh -i org.apache.tinkerpop neo4j-gremlin 3.3.2
次に、neo4jのデータが存在するディレクトリをconf/neo4j-empty.propertiesに指定します。
デフォルトでは/tmp/neo4jとなっているので、自環境内の状況にあわせて設定します。
Macにbrewでインストールした場合はおそらく以下のようなパスになっていると思います。
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph
# gremlin.neo4j.directory=/tmp/neo4j
gremlin.neo4j.directory=/usr/local/Cellar/neo4j/3.3.0/libexec/data/databases/graph.db
gremlin.neo4j.conf.dbms.auto_index.nodes.enabled=true
gremlin.neo4j.conf.dbms.auto_index.relationships.enabled=true
ここまで事前準備ができれば、設定ファイルをgremlin-server-neo4j.yamlに変更してgremlin serverを起動します。
$ bin/gremlin-server.sh conf/gremlin-server-neo4j.yaml
これで8182ポートにアクセスして操作すれば元のNeo4jのデータにアクセスが可能になっています。
以下のPythonのコードで先程Cypherクエリで登録したデータにアクセスしてみます。
from gremlin_python import statics
from gremlin_python.structure.graph import Graph
from gremlin_python.process.graph_traversal import __
from gremlin_python.process.strategies import *
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
graph = Graph()
g = graph.traversal().withRemote(DriverRemoteConnection('ws://localhost:8182/gremlin','g'))
print(g.V().hasLabel("Person").valueMap().toList())
実行すると先程登録したTaroさんとJiroさんの情報が取得できていることがわかります。
$ python gremlin-sample-neo4j.py
[{'name': ['Taro']}, {'name': ['Jiro']}]
補足
gremlin-server-neo4j.yamlを使って起動する際にエラーが出て動かない場合、以下の辺りを疑って見てください。
- Neo4j serverがすでに起動していないか
- embedded modeだと、Neo4j serverとGremlin Serverの同時起動はNGのようです。
- Neo4jの既存のデータ内にindexが異なるtypeで作られていないか
2つ目の件について、neo4jのgraph.db配下にあるdebug.logに以下のエラーが出力されます。
Tried to get index provider for an
existing index with provider {key=lucene+native, version=1.0} whereas the default and only supported provider in this session is {key=lucene, version=1.0}
index providerがlucenで作成されているのにlucene+nativeで取得しにいこうとしているといったエラーです。
作成時の指定なのか、Neo4jのバージョンなのかわからないですが、この場合にはindexを一度削除する等対処が必要です。
indexの削除方法
neo4jのデータベースのindexの一覧を確認
CALL db.indexes
unique制約がかかっているものは自動的にindexが貼られているのでunique制約を解除することでindexを削除
> CALL db.constraints
"CONSTRAINT ON ( a:User ) ASSERT a.name IS UNIQUE"
> DROP CONSTRAINT ON (a:User) ASSERT a.name IS UNIQUE
まとめ
いろいろなグラフDB実装が出て来る中、「まずはオンプレでちょっと試しつつ、ゆくゆくはマネージドなクラウドサービスに」といったことを検討する際に気になる移植性の側面についてTinkerpop、Gremlinでうまく対処できるようになるのではないでしょうか。Gremlinでどこまでの処理がカバーできるかは確認しきれていないので実際に使っているとはまりどころも出てきそうですが。