こんにちはodasatoshiです。
この記事はNTTドコモ サービスイノベーション部 Advent Calendar 2019の幻の26日目の記事です。
2019年も年の瀬です。毎日とても寒いですね。寒さで手がかじかむときは手元のGPUをフル稼働させて暖を取る日々です。
本日は、プロジェクションマッピングを支える技術、と題しましてプロジェクションにおける色の補償(Compensation)について紹介します。
背景
まずはこちらの写真をご覧ください。

普通の風景写真ですね。ディスプレイで表示しているならばそのディスプレイの設定に合わせてこの写真が表示されているはずです。
では、これをプロジェクタを用いて壁に映写するとどうでしょうか?

こんな壁あるか?という心の声はさておき、壁の模様がくっきりと見えてしまっていますね。プロジェクションマッピングは、映写対象の形状や色などを生かした映像表現を行うので、壁の模様を生かした映像を作れば問題は解決です・・・が、多くの場合そうも行きません。既存の映像を使いまわしたいこともありますし、商標やロゴなどそもそも色味が指定されていて、勝手に変えると問題になることもあります。
これらの問題を解決するにはどうしたらいいでしょうか?こういった問題は古くから検討されており、色補正(color compensation)で行います。
基本となる技術
本題に入る前に、理科の授業の復習をしましょう。りんごはなぜ赤く見えるのでしょうか?
りんごは自発光していません。そのため、周辺に光がない真っ暗闇ではりんごは見えません。
我々が一般的にりんごを見るとき、それは太陽光、蛍光灯、LEDなど様々な光の反射光を観測しています。
光の三原色を思い出していただければわかるとおり、すべての色が含まれている光は白く見えます。その光を当てたときに、特定の色を特定量吸収してそれ以外を反射することで物体には色が現れます。
白い光をあてて赤く見えたとすると、それはその物体がそれ以外の緑と青の光の成分を吸収した、ということになります。
では問題を分かりやすくするために、左半分がピンクで右半分が黄色い紙に、丸を映写してみます。
まずは、薄いピンクと薄い黄色の紙を用意してそこに、(0.292, 0.434, 0.434)の灰色っぽい円を描画します。

はい、写した円は均一の色をしているのですが、円が中央で分割されているように見えます。
左右の色が違うと気持ち悪いので右側を別の色に変えて補正しようと思います。
40分かかって手動でチューニングした成果がこちらです。

やっているとだんだん目の感覚がおかしくなって境目が見えなくなったような気がしたのですが
改めて写真に撮ってみるとまだまだものすごくずれていますね。RGB(0.322, 0.257, 1.000)の色を出しています。
課題
これを任意の壁面、任意の映像に対する変換を作ることは非常に難しいです。
この問題を定式化すると、以下のようになります。
\begin{align}
\hat{x} &: 表示される色 \\
x &: プロジェクタに入力される色 \\
\pi_c &: カメラが入力として受け取って解釈した色を表す関数 \\
\pi_p &: プロジェクタが実際に出力する色を表す関数 \\
g &: 周辺の環境光による影響 \\
s &: 映写対象の物体の反射係数 \\
\pi_s &: 物体による色の変化の仕方の関数\\
\end{align}
とすると
\hat{x} = \pi_c(\pi_s(\pi_p(x), g, s))
となります。つまりこれの逆関数を求めれば、当初の目的を達成することができそうです。当然ですがこれらそれぞれの変換式は単純な線形関数では表すことができません。プロジェクタの出力も、人が色を感じる感じ方も、材質による反射率も、すべて線形ではないからです。おや…?どこかでよく聞いたことがあるような話ですね。そうです。ディープラーニングの出番です。
CompenNet
BingyaoらによるEnd-To-End Projector Photometric Compensation(CVPR2019 oral)[1]という発表があります。
この論文の趣旨は、プロジェクタの出力をinputにカメラの入力をoutputとするconvolutional nural networkを用いてこの関数を計算し、その変換をオンラインに与えて上げることで、結果的に補正されたあとの映像が見えるような絵を作り出す技術です。
基本的なアイデアは、次のようになります。
まず、最終的に行いたいことは、

のようなシステムを構成することです。
プロジェクタで映し出されたことでいろいろな影響を受けて、その結果もともと想定していた映像が映し出されるように元の画像を調整することができればこれを実現することができます。
そのため、映像出力システムとしては$\Pi$の逆関数である$\Pi^{-1}$を作り、もともとの映像をその関数に通した出力をもともとの映像として利用できればいいことになります。
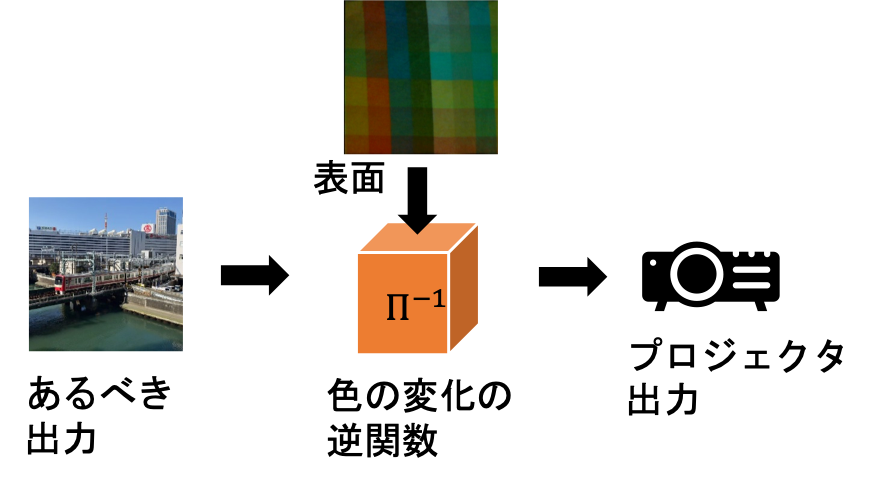
このあるべき出力とプロジェクタに入力するデータの関係は、実は出力結果(を観測したデータ)ともともとの入力したデータの関係と同じです。つまり、映し出された(映像をカメラで観測した)画像と壁の表面画像を入力として、元々の画像を出力するような関数 $\Pi^{-1}$を作ることができれば、その関数を通した映像をプロジェクタに入力することで、補償済みの画像を得ることができます。
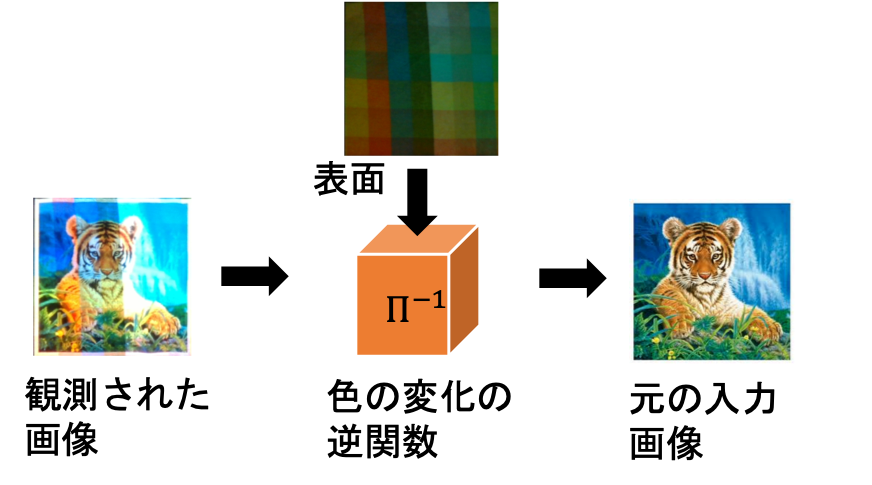
この一連の実装が公開されており、githubから参照することが可能です。
それでは、

のような布に映写してみましょう。近所の手芸店で買ってきました。
プロジェクションするもとの映像は

を利用します。これは、[1]のテストデータです。
まずは、プロジェクタとカメラの系を用意します。
ここで重要なのは、カメラの設定です。まず自動露光の機能と自動ホワイトバランス調整の機能をOFFにしましょう。この設定をしておかないと画像が切り替わるたびにカメラの設定が変わってしまって何を学習しているのかわからなくなってしまいます。(こういうものを体験するたびに人の目の有能さに気付かされます)
多くのWebカメラが専用アプリケーションから設定することができます。OpenCVでも、
cam.set(cv2.CAP_PROP_EXPOSURE, CAMERA_EXPOSURE)
こういったオプションから参照できるのですが、CAMERA_XPOSUREの値がカメラによって値域が異なるようで、実際の露出を見ながら調整します。exposureとホワイトバランスの設定は、真っ白な画面を表示すると白飛び限界のところに。真っ黒な画面を表示すると真っ黒な画面が出るところに合わせます。
これでカメラが観測したデータは、

になります。
カメラとプロジェクタの画角やサイズがあっていないので、射影変換をかけてもともとの256×256に補正します。
当初パースペクティブ変換ではなくアフィン変換をかけていたため、なかなか学習が収束せずかつボケボケになっていたのは秘密です。
カメラとプロジェクタの位置があっていればアフィン変換で十分なはずですが、物理的に同じところから発光しながら観測することは困難なのでおとなしく射影変換しましょう。
src = np.array([[252.0,74.0],[529.0, 114.0], [258.0, 352.0], [580.0,326.0]], np.float32)
dst = np.array([[0.0,0.0],[256.0, 0.0], [0.0, 256.0], [256.0,256.0]], np.float32)
af = cv2.getPerspectiveTransform(src, dst)
converted = cv2.warpPerspective(img, af, (256,256))
これが、このプロジェクタでこの壁面に映写したときの教師データになります。
並べておきます。左が入力画像、右がカメラが観測した画像です。

なお、映写する面が平面ではない場合は、単純な線形変換ではできません。
これらをさらにディープラーニングで学習し補正する層を加えたものがCompenNet++で、こちらもCompenNet++などで実装が公開されています。
実験
CompenNetはpytorchで実装されており、学習の進み具合はvisdomで確認することができます。
最初の方は、ほんわかと輪郭が浮かび上がっているだけです。

なおこの図は、一番上がカメラで取得した画像を適切なサイズに切り貼りしたもの。真ん中がネットワークが元画像はこれであると推定しているもの。一番下が正解データ。推定画像と正解データとの差分を減らすようにネットワークが更新されていくのですね。
イテレーションを1000回ほど回してみました。もう少し頑張れば精度があがる雰囲気は持っていますが、一旦ここで学習を打ち切ります。
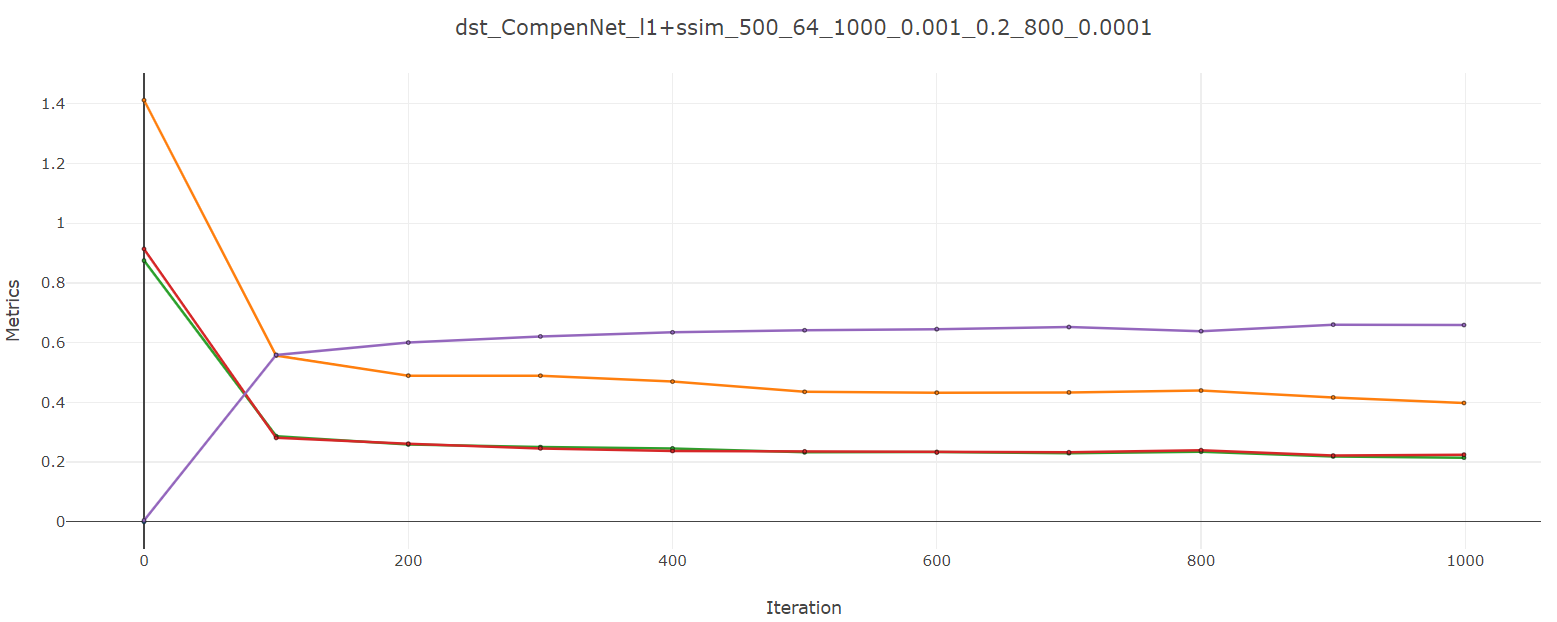
最終的に出力されるようになったのは、

です。繰り返しになりますが、一番上がプロジェクタを介して出力された映像を観測したデータで、
真ん中がそこから推測した$\Pi^{-1}$を利用して出た出力です。一番下が正解データです。
真ん中と一番下が似ていれば似ているほど正しく$\Pi^{-1}$を推測できていることになります。
なお、最初にデータセットを作るときに、白飛びしすぎていると白以外のデータも白と区別がつかないぐらい発光してしまうことがあります。(逆に暗すぎるとみんな黒になってしまいます)
その場合、ピントがボケたように正しく再現できなくなりますのでデータセットの作成は重要です。
結果
左の画像を右の壁面に映写しました。

そうしたところ、左のような映像になってしまったため、右のような補償を行い、

観測できた映像が

になります。
いかがでしたでしょうか?
ということで、NTTドコモサービスイノベーション部アドベントカレンダー幻の26日目は、プロジェクションマッピングを支える技術、と題しまして深層学習を使った色補償の手法を紹介しました。こんなところにまで深層学習が入り込んでいるんですね。それではみなさん、良いお年をお迎えください。