実務でモデルフリー強化学習を活用しようとして勉強したことを書きます
ドコモの先進技術研究所1年目の勝見と申します。今回は先輩から誘われて、アドベントカレンダーの記事の12日目を担当することになりました。本来は現在行っているデータ分析周りの業務になにか絡めて書けると良いのですが、残念ながらまだオープンにできるようなネタはありませんので、私が業務での実タスクに応用しようと検討を行っている強化学習(モデルフリー)の初学者向けの記事を自身のためのまとめも兼ねて、学習の過程で個人的に面白いなと感じたポイントを織り交ぜながら書こうと思います。
マルコフ決定過程 (Markov decision process)
このあたりは多くの記事でも取り上げられているため今更感がありますが、強化学習をタスクに適用するために必要となる定式化について説明しておきます。
強化学習では取り扱う問題を、エージェントが起こした行動 (action) によって状態 (State) が変化し、そこから報酬 (reward) が計算できるような「環境 (environment)」としてマルコフ決定過程を用いて定義することから始まります。将棋を指す強化学習エージェントを例に考えると、状態は現在の将棋の盤面 (とエージェントの持ち駒)、行動はエージェントの指す手、報酬はエージェントの勝ち負け、というように捉える事ができます。なお、ここでは、任意の時刻$t$における環境の状態を $s^{t} \in S$、エージェントがとる行動を$a^{t} \in A(s^{t})$というように表記します。このとき、エージェントが置かれるマルコフ決定過程で定義される環境は下記のように表現されます。
-
- 状態集合: $ S=\{ s_{1}, s_{2}, s_{3}, ..., s_{N} \}$
-
- 行動集合: $ A(s)=\{a_{1}, a_{2}, a_{3}, ..., a_{M}\} $
-
- 状態遷移確率: $P(s^{t+1}|s^{t}, a^{t})$
-
- 報酬 : $r^{t+1}=r(s^{t}, a^{t}, s^{t+1})$
ここで、行動集合 $A(s)$ は状態を引数にとることに留意する必要があります。実際に将棋の例においても、現在の盤面に応じて次に打つことのできる手は異なります。
また、例えば、(4)の報酬の式は、将棋では勝ち負けに相当し、
r(s^{t}, a^{t}, s^{t+1}) = \begin{cases}
1 & (s_{t+1} =「エージェントが勝った」) \\
0 & (otherwise)
\end{cases}
のように定義することができます。ここで、(3)の状態遷移確率について、例えば将棋では、局面$s^{t}$で$a^{t}$という手を打てば、次の局面$s^{t+1}$は一意に決まるのではないか?という点について違和感を感じられるかもしれません。こうした環境は特にdeterministic environmentと呼ばれ、状態遷移確率は
P(s^{t+1}|s^{t}, a^{t}) = \begin{cases}
1 & (s^{t+1} = s_{i}) \\
0 & (otherwise)
\end{cases}
のように表現することができますが、もちろん同一の定式化で扱うことができます。
モデルフリー強化学習におけるゴールは与えられた状況において最適な行動を取ることのできるエージェントを得ることです。エージェントが取る戦略$\pi$は、
\pi=P(a|s)
として確率的に表現することができます。そして、強化学習においては、この戦略$\pi$に従うエージェントを、このエージェントが現在の戦略をとり続けた際に将来得ることのできる報酬の和の期待値を用いて評価します。具体的には、
E^{\pi}[r^{t+1} + \gamma r^{t+2} + \gamma^{2} r^{t+3} + ...] \tag{1}
として評価します。なお、$0<\gamma \leq 1$となるような割引率$\gamma$を用いることで、直近の報酬をより優先して最大化するようなエージェントをより高く評価するような評価関数になっています。また、例えば、将棋では、ある数百回~数千回も行動を続けていけば最終的に勝敗が決定してゲーム自体が終了しますが、一方で、対話エージェントがユーザと会話を行うような場合は延々と会話が続くような場合が想定されるため、割引率 $\gamma$ には $0<\gamma < 1$ を用いて現在からあまりにも遠い未来の報酬については0に収束させるようになっています。多くの実装では、$\gamma=0.95$といった$1$に近い値が用いられることが多いような気がします。
なお、上記の定式化やエージェントと環境の実装はChainerRLのお陰で超!簡単に実装が可能になっています。
# Now create an agent that will interact with the environment.
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
replay_start_size=500, update_interval=1,
target_update_interval=100, phi=phi)
n_episodes = 200
max_episode_len = 200
for i in range(1, n_episodes + 1):
obs = env.reset()
reward = 0
done = False
R = 0 # return (sum of rewards)
t = 0 # time step
while not done and t < max_episode_len:
# Uncomment to watch the behaviour
# env.render()
action = agent.act_and_train(obs, reward)
obs, reward, done, _ = env.step(action)
R += reward
t += 1
if i % 10 == 0:
print('episode:', i,
'R:', R,
'statistics:', agent.get_statistics())
agent.stop_episode_and_train(obs, reward, done)
print('Finished.')
上記のwhileの箇所がエージェントchainerrl.agents.DoubleDQNが環境とインタラクションを行っている部分で、agentは環境の状態obs (と、戦略の更新に用いるreward) を受け取って次のactionをagent.act_and_trainメソッドによって選択し、環境の状態はenv.stepによって次の状態obsに変化し、rewardが算出されます(doneはエピソードの終了判定フラグ) 。これを状態が終了状態に達する、もしくは、ある程度の時間が経過して打ち切りになるまでwhileによって繰り返します。したがって、実装において登場するのは
- マルコフ決定過程にもとづく環境
env - 環境の状態
obsを受け取ってactionを返すようなエージェント
の2つのみとなります。実際に実装を行う際は、上記の挙動を満たすようなenvとobsを実装するだけです。
さて、モデルフリー強化学習においては、エージェントが取ることのできる数ある戦略$\pi$のうち、最も最適なものを得ること、すなわち式(1)を最大化するような最適戦略$\pi^{*}$を獲得することがゴールとなります。ここで、モデルフリー強化学習は式(1)を最大化するような$\pi$を求める際に用いる手法によって大きくvalue-based reinforcement learningとpolicy-based reinforcement learningと呼ばれる2つに分類されます。
Value-based reinforcement learning
前者のvalue-based RLでは、直接的に戦略$\pi=P(s,a)$を学習せず、まず式(1)の戦略の評価を
Q^{\pi}(s, a) = E^{\pi}[r^{t+1} + \gamma r^{t+2} + \gamma^{2} r^{t+3} + ...|s^{t}=s, a^{t}=a] \tag{1}
という、状態$s$と行動$a$を引数に取り、「状態 $s^{t}$ における行動 $a^{t}$ の良さ」を返すようなQ関数と解釈します。そして、最適戦略 $ \pi^{*} $ は
{\rm argmax}_{a} Q^{\pi^{*}}(s^{t}, a)
に従って行動するとして、直接 ${\pi}^{*}$ を求める代わりに最適Q関数 $ Q^{*} $ を求めるというアプローチを取ります。なお、$\pi$の添字$i$は、$i$回目のイテレーションにQ関数 $Q^{\pi^{i}}$ が使用されて$Q^{\pi^{i+1}}$に更新されることを表現するために敢えて記載しています。この、最適関数を求める基礎的な手法にSARSAとQ-learningがあります。前者のSARSAでは、最適Q関数を求めるため、次のような更新式を用います。
Q(s, a)^{\pi^{i+1}} \leftarrow (1-\alpha) Q(s, a)^{\pi^{i}} +
\alpha(r(s, a, s^{'}) + \gamma Q(s^{'}, a^{'})^{\pi^{i}} )
\tag{2}
SARSAではQ関数が収束するまで上記を繰り返します。一方で、後者のQ-learningでは、
Q(s, a)^{\pi^{i+1}} \leftarrow (1-\alpha) Q(s, a)^{\pi^{i}} +
\alpha(r(s, a, s^{'}) + \gamma {\rm max_{b}}Q(s^{'}, b)^{\pi^{i}} )
\tag{3}
という更新式を用いてQ関数を収束させます。なお、上記では現在の状態$s$から行動$a$によって遷移した状態を$s^{'}$というように表記し、$r(s, a, s^{'}) = r$としています。ここでは上記の更新式の導出は記載しませんので、初めてこの2式を見た際はイメージが付きづらいかもしれませんが、注目すべきポイントは下記の2点です。
-
- 上記の更新式にはマルコフ決定過程の状態遷移関数が登場しないこと。
-
- SARSAでは更新式に$\{s, a, r, s^{'}, a\}$、Q-learningでは更新に$\{s, a, r, s^{'}\}$のみが用いられること。
まず1つめに、冒頭で強化学習を適用するには、タスクをマルコフ決定過程で定式化する必要があるという紹介をしましたが、上記の式にはマルコフ決定過程で定義した状態遷移関数は明示的には登場しません。例えば将棋の指すようなSARSAのエージェントを学習させるとき、実際にQ関数の更新の際に行うのは、現在のエージェントを使って$s$で$a$という手を打ってみると盤面が$s^{'}$に変化し、、というようにして$\{s, a, r, s^{'}, a^{'}\}$の4つ組を収集し、それを用いてQ関数の更新を行う、というのを繰り返すだけです。
2つめの点について、くどいようですがQ-learningの更新には $\{s, a, r, s^{'}\}$ のみを必要とし、$s^{'}$ の次の行動 $a^{'}$ をQ関数の更新に用いていません。SARSAでは、Q関数に$\{s, a, r, s^{'}\}$だけでなく、その次の行動$a'$を用いています。Q-learningの更新式(3)に登場する状態$s$において現在の戦略$\pi^{i}$によって選択される行動$a$は${\rm argmax}_{a} Q^{\pi^{i}}(s, a)$に確率的にノイズを加えた $\epsilon$-greedy法によって選択されます。

一方でSARSAの更新式に用いる $\{s, a, r, s^{'}, a^{'}\}$ は「状態$s$において行動$a$をとったら報酬$r$が得られて、次の状態$s^{`}$に遷移した」という後、さらにその次の行動$a^{'}$までを含んでいますがが、$a$と$a'$の両者が更新前の戦略に依存した${\rm argmax}_{a} Q^{\pi^{i}}(s, a)$にノイズを加えた$\epsilon$-greedy方によって選択されています。

一般的に、Q-learningのように更新に用いる戦略$\pi^{i}$と更新後に次の行動$a'$を選択する戦略$\pi^{i+1}$が異なる学習手法ををoff-policy learning、SARSAのように更新に用いる戦略$\pi^{i}$と更新後に次の行動$a'$を選択する戦略$\pi^{i}$が同一であるような学習方法をon-policy learningと呼びます。
ちなみに、もうお気づきかもしれませんが、アルゴリズム名「SARSA」はQ関数の更新に用いる4つ組 $\{s, a, r, s', a'\}$ からつけられたものです。
Policy-based reinforcement learning
後者のpolicy-based RLには代表的なものにREINFORCEやactor-criticがあります。先程のvalue-based reinforcement learningでは、最適戦略$\pi^{*}$を直接学習するのではなく、将来得られる割引報酬和の期待値を与えるようなQ関数を更新式を用いて間接的に最適化することで、最適戦略を学習していました。
Q^{\pi}(s, a) = E^{\pi}[r^{t+1} + \gamma r^{t+2} + \gamma^{2} r^{t+3} + ...|s^{t}=s, a^{t}=a] \tag{1}
一方で、policy-based reinforcement learningでは何らかの仮定をおいて戦略$\pi(\theta)$をパラメータ$\theta$を持つような関数でモデリングし、パラメータ$\theta$を勾配降下法を用いて直接最適化します。すなわち、$\pi(\theta)$の評価関数$J(\theta)$を想定し、
\theta^{i+1} \leftarrow \theta^{i} + \alpha \nabla_{\theta} J(\theta^{i})
として$\pi(\theta)$を学習します。主に戦略$\pi(\theta)$の評価関数$J(\theta)$には、value-based RLと同様に割引報酬和の期待値が用いられ、その勾配は方策勾配定理によって次のように変形できることが知られています。
J(\theta) = E^{\pi(\theta)}[r^{t+1} + \gamma r^{t+2} + \gamma^{2} r^{t+3} + ...] \\
\\
\nabla_{\theta} J(\theta) = E^{\pi(\theta)}[\nabla_{\theta} {\rm log} P(a|s;\pi(\theta)) Q^{\pi(\theta)}(s, a)]
しかし、実際に上記の勾配を解析的に求めることはできません。そこでpolicy-based RLの一つであるREINFORCEアルゴリズムでは、
- $Q(s, a)$を直近の報酬$r(s, a, r, s')$で近似する
- サンプリングによって実際に右辺のサンプルを収集することで期待値を推定する
という工夫によって戦略$\pi(\theta)$を学習します。
\nabla_{\theta} J(\theta) = \frac{1}{|\mathcal{D}|} (\nabla_{\theta} {\rm log} P(a|s;\pi(\theta)) r(s, a, s'))
すなわち、実際に戦略$\pi(\theta)$に従って行動して見た時に得られた$r(s, a, s')$と戦略$\pi$によって出力される$P(a|s;\pi(\theta))$を集めたサンプル$\mathcal{D}$を用いて期待値を推定します。ただし、Chainerを始めとしたニューラルネットワークのフレームワークを用いた実装上は、lossを計算して勾配グラフを構築してからそれを元に勾配を計算する必要があるため、上式をMLEとみなして擬似的なlossを計算することで重みの更新を行います。
強化学習を実際のタスクに適用する際のポイント
- 即時的な報酬だけでなく、長期的な報酬を最適化するような問題設定を扱いやすい。
- 手法によっては、オフラインで収集されたバッチのみから学習が可能である。
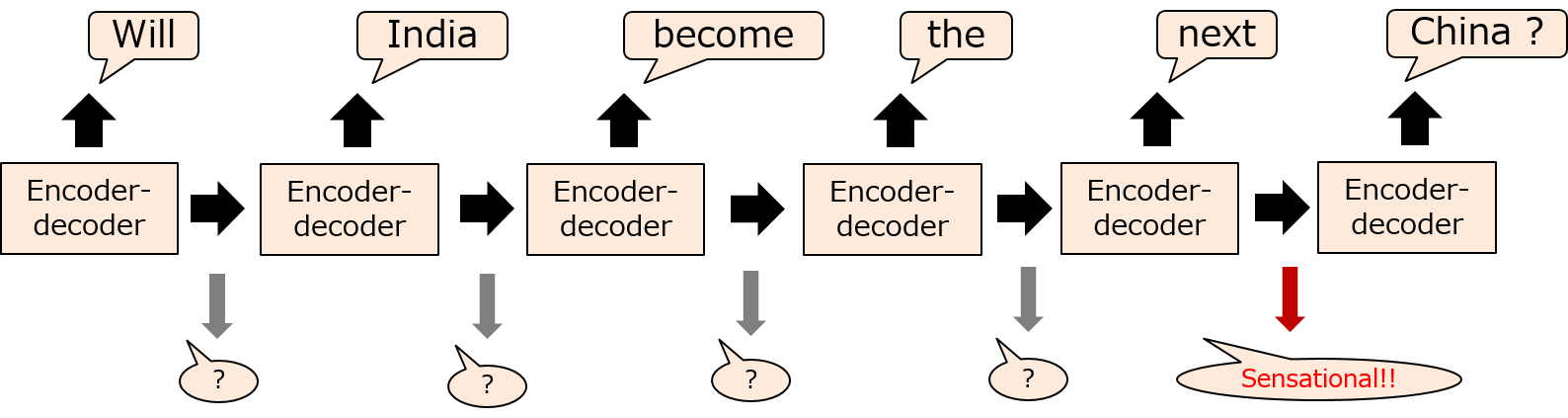
モデルフリー強化学習を実際のタスクに適用する際、個人的に上記の2つが頭に入っていると理解が楽になるように思いました。前者については、実際に現実世界のタスクに強化学習を適用した直近の例のひとつに Xuら(2019)の Clickbait? Sensational Headline Generation with Auto-tuned Reinforcement Learning があります。既存のニュース記事などを入力として受け取ってタイトルを生成するencoder-decoderモデルの一つに、Seeら(2017)の Get To The Point: Summarization with Pointer-Generator Networks で提案されているPointer-generatorモデルがあります。こうしたモデルは生成された単語列とターゲットの単語列にMLEを適用することで学習を行います。Xuらはここに、強化学習の割引報酬和の期待値最大化の枠組みを追加することで、ターゲットに近いタイトルを生成するだけでなく、よりインプレッションを稼ぐことのできそうなタイトルを生成することを可能にしました。具体的には、記事を入力し、encoder-decoderモデルによって各ステップで生成される単語を行動$a$、生成された単語列を状態$s$、現在のencoder-decoderを戦略$\pi$とし、最終的に数ステップで生成された単語列によって生成されたタイトルが「どれだけインプレッションを稼ぐことができそうか?」という度合い (sensationalism score) を報酬として定義します。これはencoder-decoderが各ステップで単語を出力しても、すぐにはその時点でそのタイトルのsensationalism score は encoder-decoder が全て単語列を出力仕切るまでは計算しようがないという点をカバーしています。学習はではencoder-decoderモデルを、一般的なMLEによる重みの更新と、sensationalism score の割引報酬和の期待値をREINFORCEを用いて最適化する形での重みの更新の2つをバランスしながら行われます。
後者はモデルフリー強化学習では用いる手法によっては取り扱う環境の状態遷移を直接必要とせずに学習が可能になるという点を指しています。
これまでにOn-policy learningとoff-policy learningの違いについて触れましたが、Q-learningの更新には4つ組$\{ s, a, r, s' \}$のみが用いられることを強調しました。ここで、4つ組$\{ s, a, r, s' \}$は、「状態$s$において行動$a$を取ったとき、報酬$r$が得られて状態$s'$に遷移した」というマルコフ決定過程の
-
- 状態遷移確率: $P(s^{t+1}|s^{t}, a^{t})$
-
- 報酬 : $r^{t+1}=r(s^{t}, a^{t}, s^{t+1})$
から得られるものです。一方でSARSAに用いられる$\{s, a, r, s', a'\}$はマルコフ決定過程の状態遷移確率と報酬だけでなく、その時点での戦略$\pi$に大きく依存します。すなわち、SARSAにおいては、各イテレーションで$\{s, a, r, s', a'\}$を更新に用いた後、Q関数が更新されて戦略$\pi$も更新されてしまうため、同じ$\{s, a, r, s', a'\}$が使い回しづらくなります。
こうしたQ-learningの特性を活かし、現在の戦略$\pi$を用いてひたすら $\{s^{t}, a^{t}, r^{t}, s^{t+1}\}$ を集めてバッチを作り、そのバッチを用いてQ関数を収束させる Neural Fitted Q Iteration が提案されています。

(Riedmiller, 2005, Neural fitted Q iteration–first experiences with a data efficient neural reinforcement learning method より)
ただし、実際には収集されたバッチに含まれた$\{s, a, r, s'\}$ (上記のアルゴリズムでは $\{s, u, c, s'\}$ )のみを用いてイテレーションを繰り返すだけで、理想的な最適戦略に収束するためには万遍なく$\{s, a, r, s'\}$が収集されている必要があります。これは、例えば、素人レベルのエージェントが将棋を指した過程で収集された状態行動対$\{s, a, r, s'\}$のみを用いてエージェンの戦略を最適化する、と例えると、この手法で必ずしも最適戦略を獲得できるとは限らないというのが想像しやすいかもしれません。
この点について言及したものの一つには、最近の例を挙げるとFujimotoら(2019)による Off-Policy Deep Reinforcement Learning without Exploration があります。

(Fujimoto+, 2019, Off-Policy Deep Reinforcement Learning without Exploration より)
本論文では収集済みの$\{s, a, r, s'\}$からVAEを用いてサンプルされていない状態行動対をバッチに追加して、パラメータの更新に利用するという Batch-Constrained deep Q-learning (BCQ) を提案しています。
さいごに
本記事では、モデルフリー強化学習の基礎に始まり、比較的新しめの論文を挙げながら理解の助けになるようなポイントを数点挙げました。難しい取り組みではありますが、実務で取り組んでいるタスクの方でもこうしたモデルフリー強化学習を取り入れて成果が出せるようこれからも試行錯誤を続けて行きたいと思っています。