テレテキストと言われても何のことかわからんって方はとりあえずこの動画を見てみてほしい。
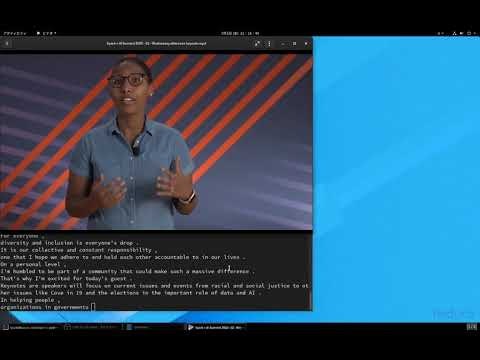
こんな感じに動画にほぼ同期して文字起こしが表示されると、ネイティブ並みのヒアリング能力がなくてもスピーチの把握がやりやすい。CNNとかで時々やってたりする。Youtubeだと自動文字起こしをやってくれるのだが、それ以外の方法で動画が配信されているとかなりしんどい。最近やってる海外のバーチャルイベントとか。
そこでAmazon Transcribeというサービスで似たようなことをやってみた。
Transcribeで文字起こしを取得する
まずAmazon Transcribeに与える音声データをS3にアップロードする。Transcribeにかけると文字起こしのデータが得られる。抜粋するとこんな感じのJSONになっている。
transcribed.json
{
"jobName": "aaabbbccc",
"accountId": "123456789012",
"isRedacted": true,
"results": {
"transcripts": [
{
"transcript": "XXXXXXXXXXXXXXXXXXXX"
}
],
"items": [
{
"start_time": "193.92",
"end_time": "199.55",
"alternatives": [
{
"confidence": "0.2774",
"content": "thing"
}
],
"type": "pronunciation"
},
(中略)
]
},
"status": "COMPLETED"
}
itemsのところに発音した時間と、発音内容、信頼度が出ている。あとはこれを時間に従って表示すればいい。
テレテキストっぽく表示する
こんな感じにpythonスクリプトを書く。特にコメントは書いていないが短いので何をやっているかはわかると思う。
teletext.py
import sys
import json
from datetime import datetime, timedelta
jsonobj = None
with open(sys.argv[1]) as fh:
try:
jsonobj = json.load(fh)
except:
raise
jsonobj = jsonobj["results"]["items"]
idx = int(0)
ntime = float(0.0)
jsonlength = len(jsonobj)
n1 = datetime.now()
while True:
if "start_time" in jsonobj[idx]:
if float(jsonobj[idx]["start_time"]) < ntime:
print(jsonobj[idx]["alternatives"][0]["content"], end=' ')
idx += 1
if idx >= jsonlength:
break
else:
print(jsonobj[idx]["alternatives"][0]["content"])
idx += 1
if idx >= jsonlength:
break
d = datetime.now() - n1
ntime = float(d.total_seconds())
実行はこんな感じにする。
$ python3 -u teletext.py transcribed.json
さいごに
30分で作ったにしては結構役立つなあ、と
もう少し丁寧にしたやつをGitHubに上げといた https://github.com/mkiuchi/transcribe-teletext